







2.6、可靠性
事件在每个agent的channel中短暂存储,,之后事件被发送到下一个agent或者最终存储中。时间只有在存储在下一个agent或最终存储后才会从当前channel中删除。
flume使用事务的办法来保证事件的可靠传递。source和sink分别被封装到事务中,事务一般有channel提供,从而保证数据传输的可靠。在多个agent(多跳)中,上一跳的sink和下一跳的source都运行事务来保证数据的可靠性。
3、安装、使用(1.9.0版本)
下载地址:https://flume.apache.org/download.html
文档地址:https://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
解压后删除lib目录下的guava-11.0.2.jar,防止和hadoop不兼容。
3.1、监听数据
步骤:
- 通过netcat向55555端口发送数据
- flume监控55555端口并通过source读取数据
- flume将读取到的数据通过sink写到控制台
操作:
- 安装netcat
sudo yum install -y nc
- 查看端口占用
netstat -nlp|grep 55555
- 新建job文件夹,编写flume-netcat-logger.conf文件
[root@hadoop101 apache-flume-1.11.0-bin]# mkdir job
[root@hadoop101 apache-flume-1.11.0-bin]# mkdir job
vim flume-netcat-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 55555
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000#channel总容量
a1.channels.c1.transactionCapacity = 100#单次事务的容量
# Bind the source and sink to the channel
a1.sources.r1.channels = c1#source可以绑定多个channel
a1.sinks.k1.channel = c1#一个sink只能绑定一个channel
执行命令
[root@hadoop101 apache-flume-1.9.0-bin] bin/flume-ng agent -n a1 -c conf/ -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
在控制台查看消息日志

3.2、监控单个文件
步骤:
- 创建flume配置文件
- 执行配置文件并开启监控
- 开启Hive生成日志
- 查看HDFS上数据
操作:
- 创建conf文件flume-file-hdfs.conf
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /tmp/root/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop100:8020/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否对时间戳取整
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
注意: a2.sources.r2.command中hive的日志路径和 a2.sinks.k2.hdfs.path要根据自己的环境来写,查看路径是否正确使用命令。
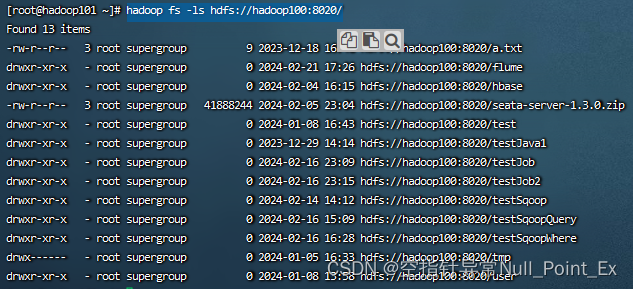
hadoop fs -ls hdfs://hadoop100:8020/
如果能看到HDFS的目录说明没问题,如下图。
2. 运行命令
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf
- 启动Hive,可使用命令监控Hive日志 tail -F /tmp/root/hive.log
- 查看HDFS是否有flume目录

3.3、监控目录下的多个新文件
步骤:
- 创建符合条件的flume配置文件
- 执行配置文件开启监控
- 向监控目录中添加文件
- 查看HDFS检查文件是否上传成功
- 查看监控目录中的文件是否已被标记
操作:
- 创建conf文件flume-dir-hdfs.conf
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = spooldir
a2.sources.r2.spoolDir=/export/soft/apache-flume-1.9.0-bin/upload
a2.sources.r2.fileSuffix=.COMPLETED#上传完成后修改文件后缀名进行标记
a2.sources.r2.fileHeader=true
a2.sources.r2.ignorePattern=([^ ]*\.tmp)#忽略该类型文件
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop100:8020/flume/upload/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否对时间戳取整
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
- 创建upload文件夹
- 运行flume
bin/flume-ng agent -n a2 -c conf/ -f job/flume-dir-hdfs.conf
- 查看HDFS和文件标记
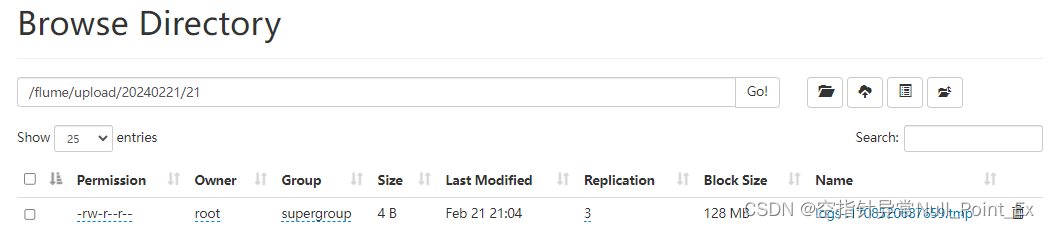

注意:上传的文件不能重名,flume会报错!虽然会上传成功,但重名文件无法进行标记。
3.4、监控目录下的多个追加的文件
Exec Source适合监控一个实时追加的文件,不能实现断点续传;Spooldir Source适合同步新文件,不适合对实时追加的日志进行监听和同步;而Taildir Source适合用于监听多个实时追加的文件并能实现断点续传。
步骤:
- 创建flume配置文件
- 执行配置文件开启监控
- 向监控文件中追加内容
- 查看HDFS上的数据是否同步追加
操作:
- 创建配置文件
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = TAILDIR
a2.sources.r2.positionFile=/export/soft/apache-flume-1.9.0-bin/job/tail_dir.json
a2.sources.r2.filegroups=f1 f2
a2.sources.r2.filegroups.f1=/export/soft/apache-flume-1.9.0-bin/job/f1/.*file.*
a2.sources.r2.filegroups.f2=/export/soft/apache-flume-1.9.0-bin/job/f2/.*log.*
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop100:8020/flume/upload2/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否对时间戳取整
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 20
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**





**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**

1712888596700)]
[外链图片转存中...(img-7r10iLMV-1712888596700)]
[外链图片转存中...(img-kibAjKCP-1712888596700)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**
[外链图片转存中...(img-oYypva87-1712888596700)]















 2005
2005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









