







高可用机制解析
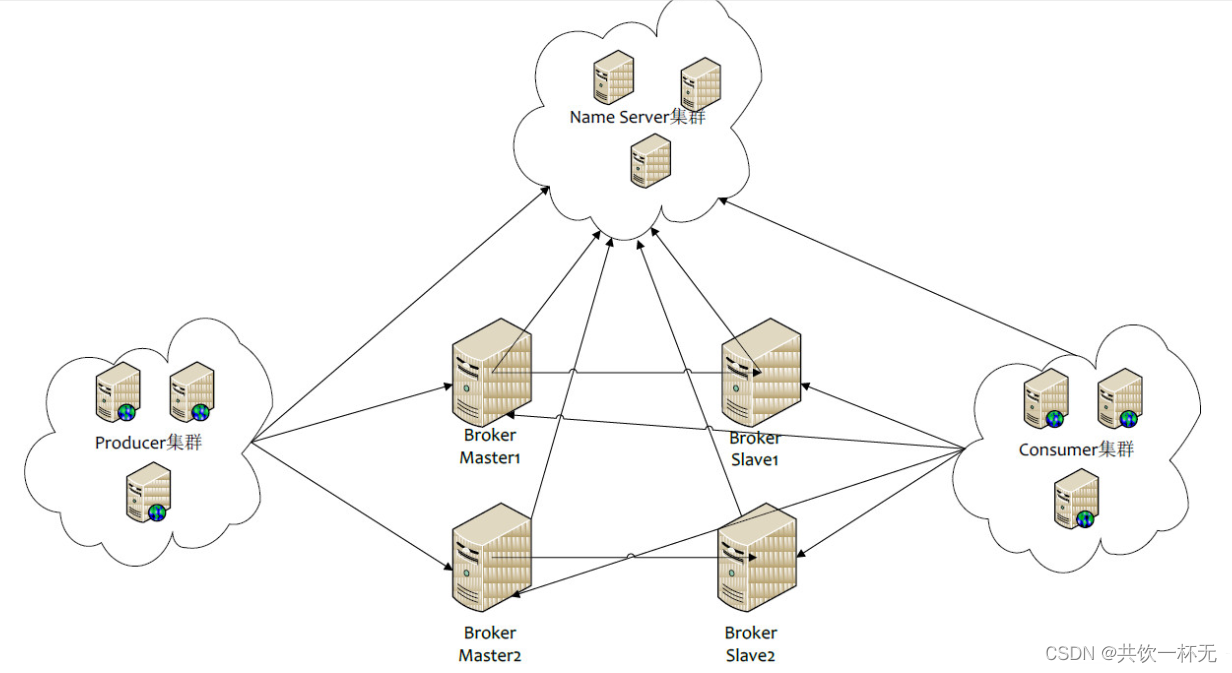
RocketMQ分布式集群是通过Master和Slave的配合达到高可用性的。
Master和Slave的区别:
- 在Broker的配置文件中,参数brokerId的值为0表明这个Broker是Master,大于0表明这个Broker是Slave,brokerRole参数也说明这个Broker是Master还是Slave。(SYNC_MASTER/ASYNC_MASTER/SALVE)
- Master角色的Broker支持读和写,Slave角色的Broker仅支持读。
- Consumer可以连接Master角色的Broker,也可以连接Slave角色的Broker来读取消息。
消息消费高可用
在Consumer的配置文件中,并不需要设置是从Master读还是从Slave 读,当Master不可用或者繁忙的时候,Consumer会被自动切换到从Slave 读。
有了自动切换Consumer这种机制,当一个Master角色的机器出现故障后,Consumer仍然可以从Slave读取消息,不影响Consumer程序。这就达到了消费端的高可用性
消息发送高可用
如何达到发送端的高可用性呢?
在创建Topic的时候,把Topic的多个Message Queue创建在多个Broker组上(相同Broker名称,不同brokerId的机器组成一个Broker组),这样既可以在性能方面具有扩展性,也可以降低主节点故障对整体上带来的影响,而且当一个Broker组的Master不可用后,其他组的Master仍然可用,Producer仍然可以发送消息的。
RocketMQ目前还不支持把Slave自动转成Master,如果机器资源不足,需要把Slave转成Master。可以按照如下步骤操作:
- 手动停止Slave角色的Broker。
- 更改配置文件。
- 用新的配置文件启动Broker
NameServer协调者解析
NameServer基本概念和功能
对于一个消息队列集群来说,系统由很多机器组成,每个机器的角色、IP地址都不相同,而且这些信息是变动的(如在某些情况下,会有新的Producer或Consumer加入)。
NameServer的存在主要是为了解决这类问题,由NameServer维护这些配置信息、状态信息,其他角色都通过NameServer来协同执行。
NameServer是整个消息队列中的状态服务器,集群的各个组件通过它来了解全局的信息。各个角色的机器要定时向NameServer上报自己的状态,如果超时未上报,NameServer会认为某个机器出故障不可用了,其他的组件会把这个机器从可用列表中删除。
NameServer可以部署多个,相互之间独立,其他角色同时向多个NameServer上报状态信息,从而达到热备份的目的。NameServer本身是无状态的,也就是说NameServer中的Broker、Topic等信息都不会持久化,都是由各个角色定时上报并存储到内存中的(NameServer支持参数的持久化,一般用不到)。
集群状态的存储结构
在nameserver模块下的RouteInfoManager可以看到有五个HashMap变量保存了集群的信息。
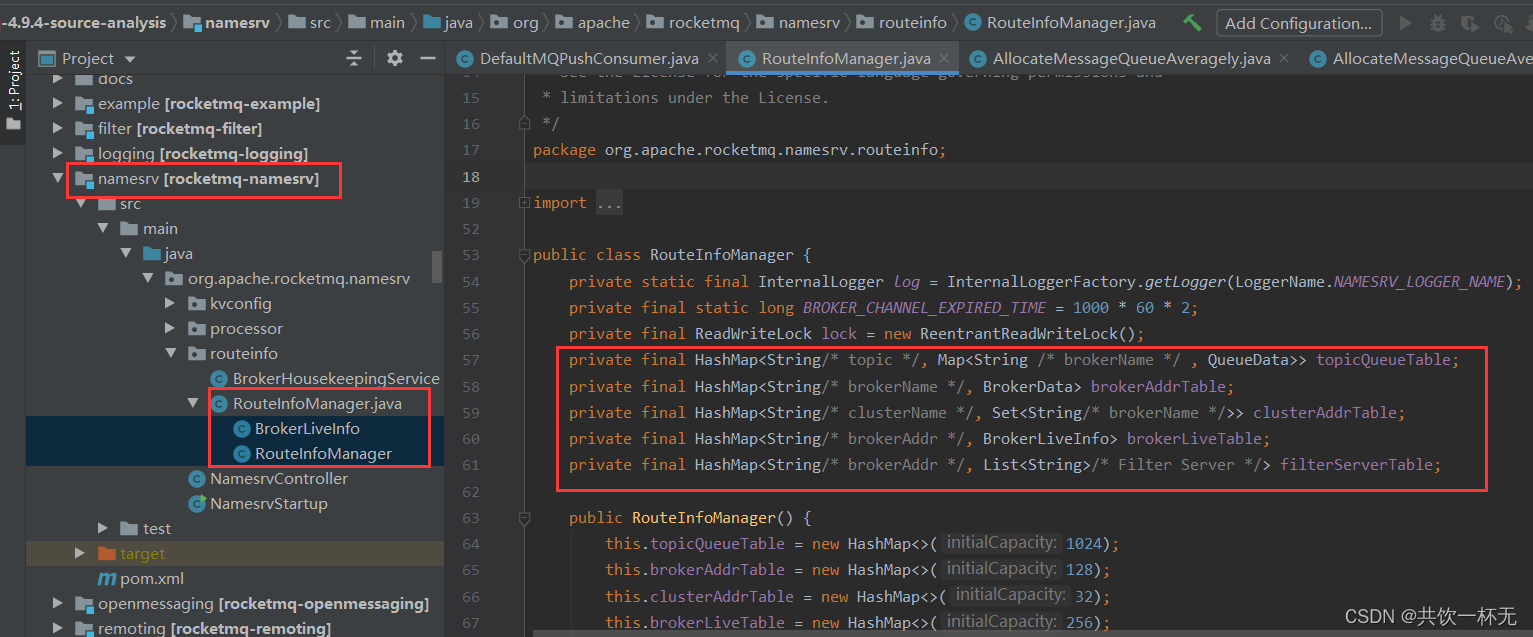
/\*\*
\* 存储所有Topic与Broker关联的属性信息
\*/
private final HashMap<String/\* topic \*/, Map<String /\* brokerName \*/ , QueueData>> topicQueueTable;
/\*\*
\* 存储BrokerName对应的属性信息
\*/
private final HashMap<String/\* brokerName \*/, BrokerData> brokerAddrTable;
/\*\*
\* 存储集群的信息
\*/
private final HashMap<String/\* clusterName \*/, Set<String/\* brokerName \*/>> clusterAddrTable;
/\*\*
\* 存储Broker机器的实时状态
\*/
private final HashMap<String/\* brokerAddr \*/, BrokerLiveInfo> brokerLiveTable;
/\*\*
\* 存储过滤服务器信息
\*/
private final HashMap<String/\* brokerAddr \*/, List<String>/\* Filter Server \*/> filterServerTable;
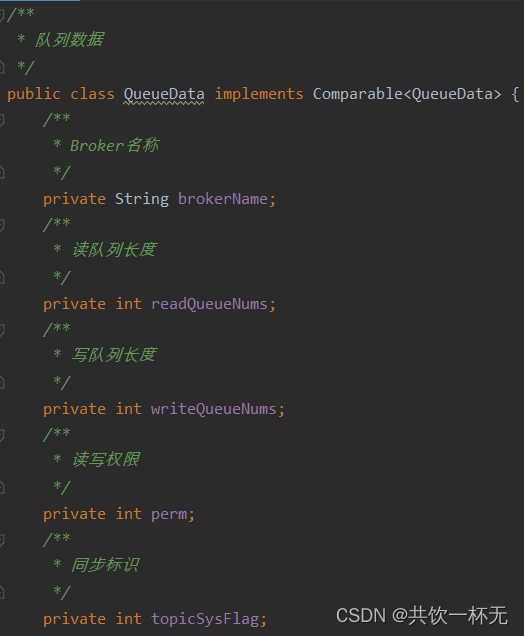
topicQueueTable
HashMap<String/\* topic \*/, Map<String /\* brokerName \*/ , QueueData>> topicQueueTable;
key:Topic的名称。
value:value是个一个Map集合,集合中存的brokerName与QueueData(队列数据)的关联信息。QueueData存储着Broker的名称,读写Queue的数量、同步标识等。
brokerAddrTable
HashMap<String/\* brokerName \*/, BrokerData> brokerAddrTable;
key:brokerName
value:BrokerData里面存了broker相关数据信息。

clusterAddrTable
HashMap<String/\* clusterName \*/, Set<String/\* brokerName \*/>> clusterAddrTable;
key:cluster(集群)的名称
value:Broker Name组成的集合。
即一个cluster名称对应的一个BrokerName的集合。
brokerLiveTable
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
n.net/topics/618545628)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









