






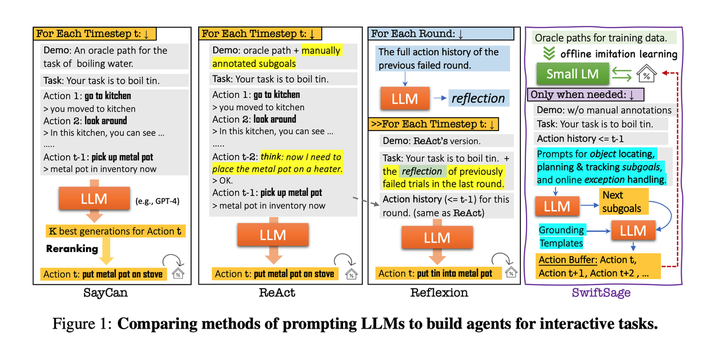
调研Agent核心思想,主要有metagpt、React、Reflexion、Toolformer、Swiftsage、Creator等等。Tiny Agent 实现,主要包括 构造大模型、构造工具、构造Agent、运行Agent等步骤。
Agent 核心思想
1. MetaGPT
METAGPT: META PROGRAMMING FOR A MULTI-AGENT COLLABORATIVE FRAMEWORK
代码:https://github.com/geekan/MetaGPT
论文:https://arxiv.org/abs/2308.00352
Agents之间的SOP流程,流程的规范化和评估化,保障结果的可靠性。
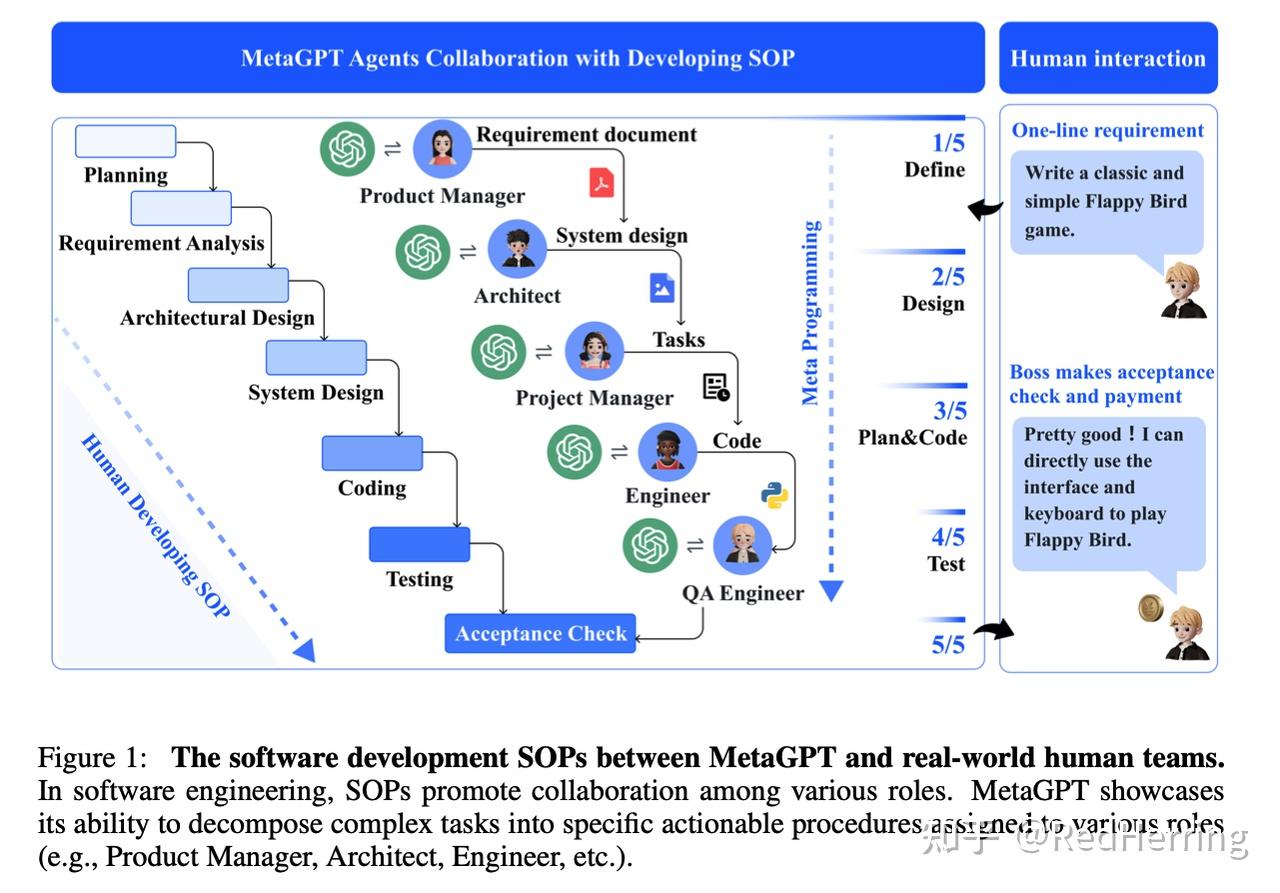
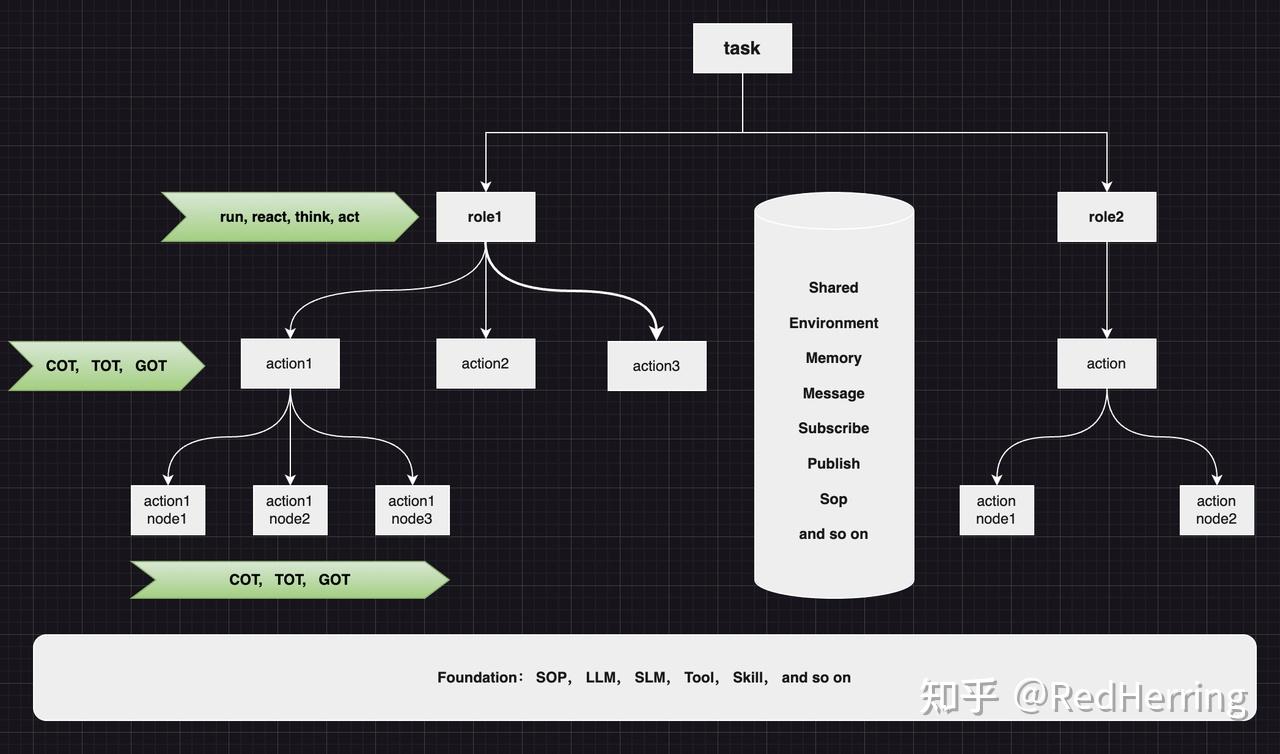
- 定义role和action,一个role,可以有多个action,根据最新版本代码,一个action,可以有多个action node
- 最重要的,我认为是shared message pool 和 subscription publish,类比于公司实际情况,各个部门沟通之后的信息共享和订阅发布,能有效消除信息差。
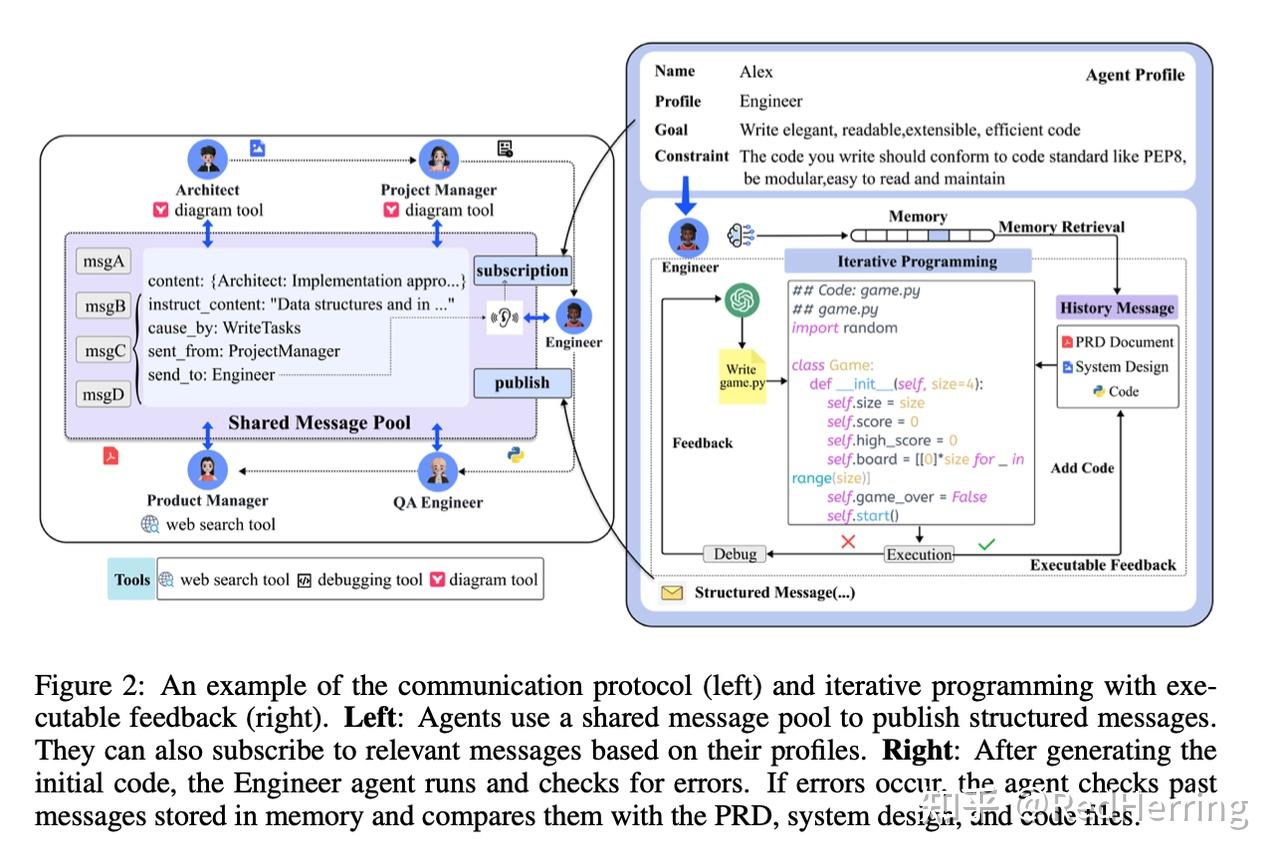
类比于公司实际情况,各个部门role的communication,需要遵循两个原则:
- 内容有据可依,不同的角色有不同的技能,不同的任务,output有据可依,有评估,有check,有流程。
- 结果共享周知,角色的memory,自身记忆,环境信息,可利用的资源任务等,这些都有利于优化下一步动作。
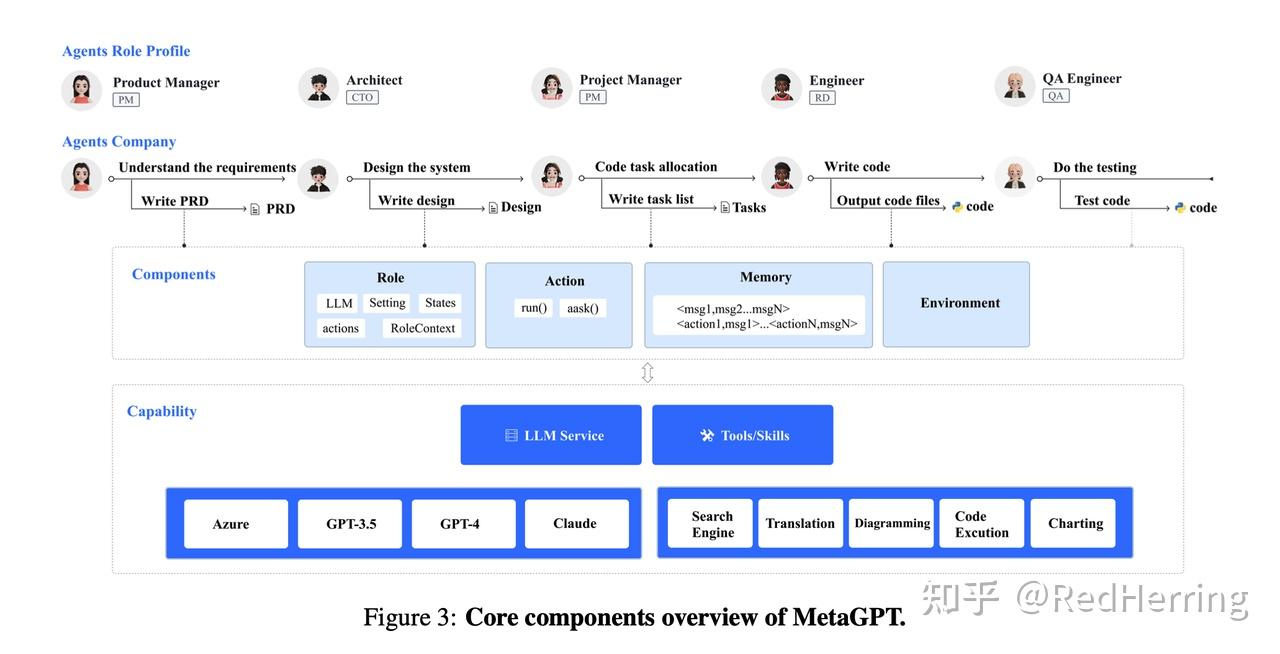
我理解的metaGPT核心,其本质类似于公司的组织架构,横向同一层级的工作模式,可能是COT、TOT、GOT,纵向深度有不同的层级,如role、action、action node等,其中role的 run、react、think、act是保障任务深度执行的关键。
生成的推荐系统结果展示:
2. React
ReAct论文解读:LLM ReAct范式,在大语言模型中结合推理和动作
ReAct: Synergizing Reasoning and Acting in Language Models
论文:https://arxiv.org/abs/2210.03629

通过显式推理,加上动作,LLM Agent自主找到了答案。整个过程感觉就像是个不是特别聪明的孩子,要把想法写出来,然后去综合所有想法和观察,接着再做出相应的动作。但显然这个方法很有效,它最终找到了答案。
也许将来,聪明的LLM Agent不需要显式推理,通过纯动作,即传统方法3,也能得到正确答案。但作为人类,我们还是会去使用ReAct范式,因为他具备了可解释性。我们可以知道Agent是怎么想的,尤其是在需要调试和人工介入的情况下。
此外,作者还提出了进一步提高ReAct准确率的方法,即微调finetuning,类似人类“内化”知识的过程,将上千条正确的推理动作轨迹输入进LLM进行finetuning,可以显著提高准确率。与其他三种方法同时finetuning后进行比较,ReAct的表现显著超越其他三种传统方法。
3. Reflexion
Reflexion: Language Agents with Verbal Reinforcement Learning
论文:https://arxiv.org/abs/2303.11366
提出 Reflexion,这是一种“语言”强化的新范式,它将策略参数化为代理的记忆编码,并配对参数选择LLM。
探索自我反思的这种涌现特性,LLMs并实证表明,自我反思对于在少数试验中学习复杂的任务非常有用。
介绍LeetcodeHardGym,这是一个代码生成 RL 健身房环境,由 19 种编程语言的 40 个具有挑战性的 Leetcode 问题(“硬级别”)组成。
表明Reflexion 在多个任务上实现了对强基线的改进,并在各种代码生成基准上取得了最先进的结果。
4. Toolformer
Toolformer: Language Models Can Teach Themselves to Use Tools
论文:https://arxiv.org/abs/2302.04761
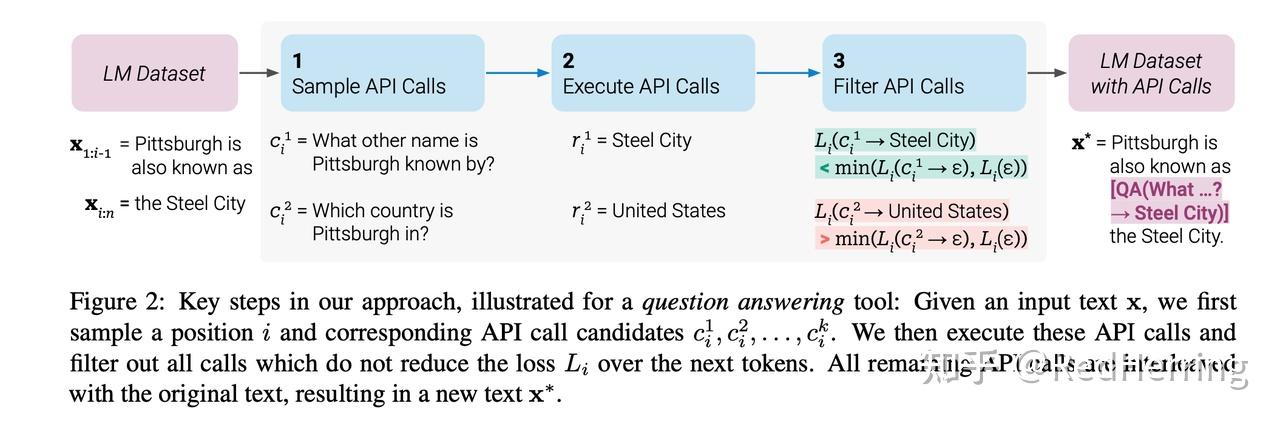
提出了 Toolformer,这是一种学习以新颖方式使用工具的模型,它满足以下目的:
工具的使用应该以自我监督的方式学习,而不需要大量的人工注释。这是不重要的——这不仅是因为与此类注释相关的成本,还因为人类认为有用的东西可能与模型认为有用的东西不同。
LM不应失去其任何通用性,并且应该能够自行决定何时以及如何使用哪种工具。与现有方法相比,这样可以更全面地使用与特定任务无关的工具。
目标是使语言模型 M 能够通过 API 调用使用不同的工具。我们要求每个 API 的输入和输出可以表示为文本序列。这允许将 API 调用无缝插入到任何给定文本中,使用特殊标记来标记每个此类调用的开始和结束。
5. Swiftsage
SwiftSage: A Generative Agent with Fast and Slow Thinking for Complex Interactive Tasks
基于大语言模型的Agent——SwiftSage: 一种拟人类的快慢思考方法
论文:https://arxiv.org/abs/2305.17390
小模型:SLM,快思考,简单任务
大模型:LLM,慢思考,复制任务
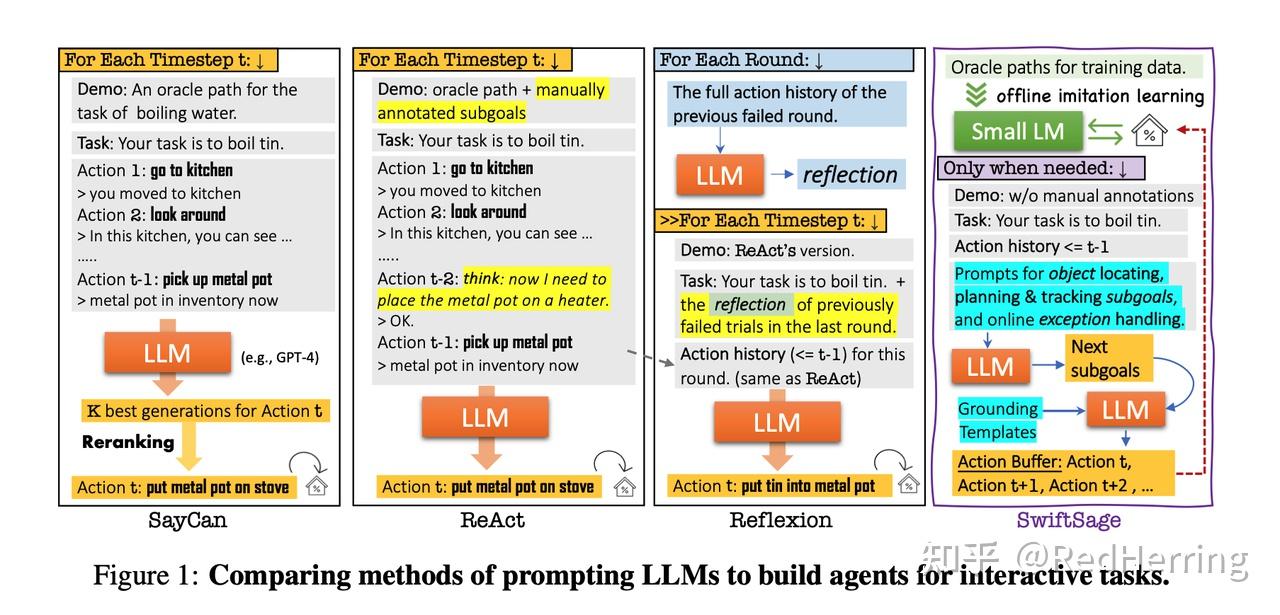
用一个小模型直接输出决策,当小模型不行时改用大模型通过复杂planning输出决策。这么做的好处自然是运行效率高,现有很多LLM-based agent方法虽然产生了不错的效果,但频繁调用大模型其实带来了巨大的开销,
这篇文章专门针对ScienceWorld环境,基于demonstration数据预训练了一个小模型,称为Swift,和一个大模型,称为Sage。小模型在简单问题上足够输出有效动作,但在复杂问题或未见问题上难以做出好的决策,这时需要调用大模型。这篇文章设计了各种规则,将两者结合起来了。
6. Creator
CREATOR: Tool Creation for Disentangling Abstract and Concrete Reasoning of Large Language Models
论文: https://arxiv.org/abs/2305.14318
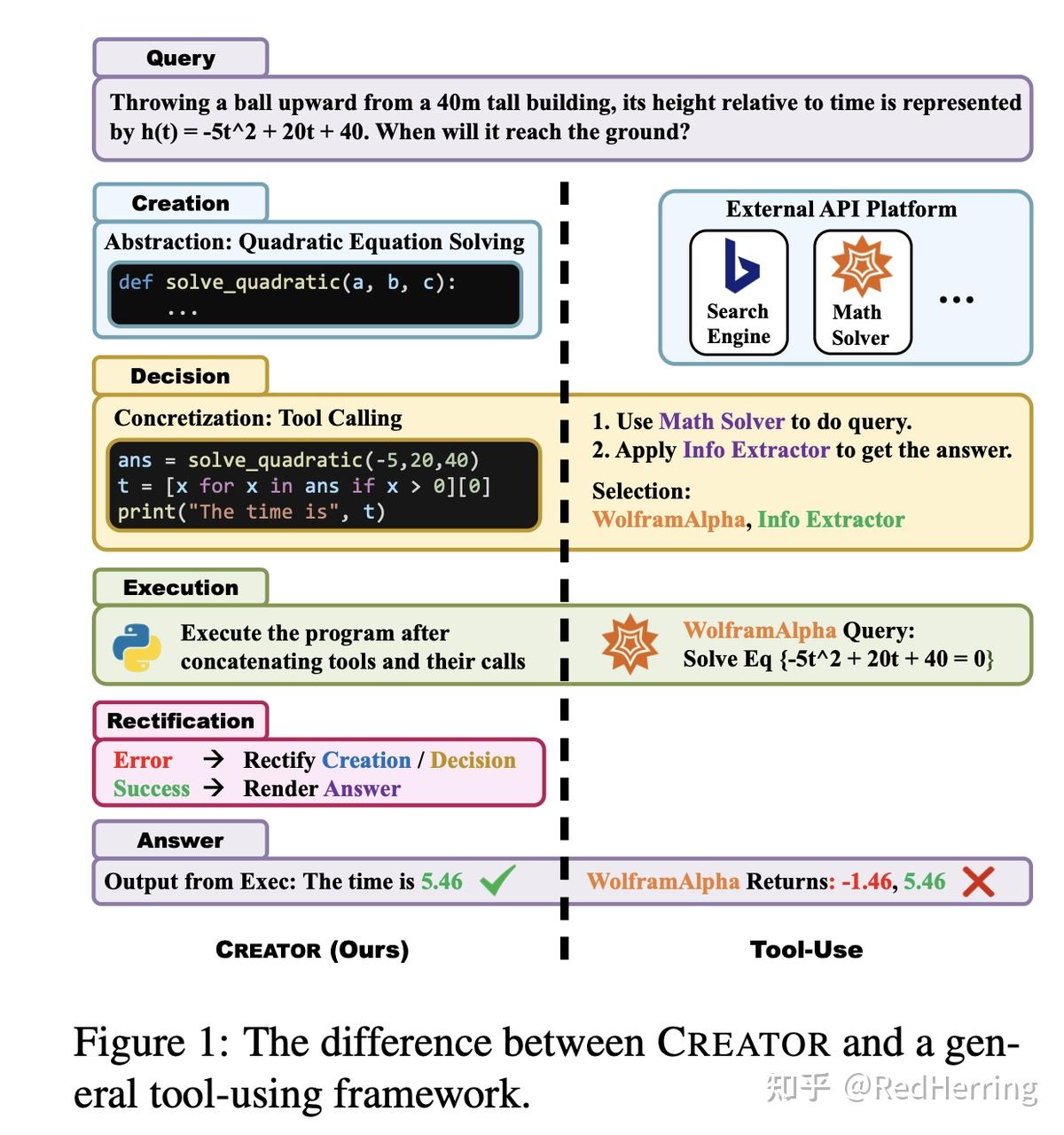
工具创建框架 CREATOR,它利用 LLMs' 根据手头的问题创建和修改工具的能力。上图片说明了 CREATOR 和通用工具使用框架之间的差异。虽然工具使用框架侧重于选择和规划 API 使用的推理,但我们的框架强调工具选择的多样化,解开抽象和具体的推理,以及提高鲁棒性和准确性。具体来说,CREATOR由四个阶段组成:
- 创建:创建具有文档的通用工具,并通过基于问题的抽象推理实现。
- 决策:使用可用的工具,决定何时以及如何使用它们来解决问题。
- 执行:执行程序,应用所选工具来解决问题。
- 整改:根据执行结果对工具和决策进行修改。
Tiny Agent 实现
在ChatGPT横空出世,夺走Bert的桂冠之后,大模型愈发的火热,国内各种模型层出不穷,史称“百模大战”。大模型的能力是毋庸置疑的,但大模型在一些实时的问题上,或是某些专有领域的问题上,可能会显得有些力不从心。因此,我们需要一些工具来为大模型赋能,给大模型一个抓手,让大模型和现实世界发生的事情对齐颗粒度,这样我们就获得了一个更好的用的大模型。
感谢DataWhale组织的大模型实战学习,对应的github链接 :tiny-universe
这里基于React的方式,我们手动制作了一个最小的Agent结构(其实更多的是调用工具)。
一步一步手写Agent,可以让我们对Agent的构成和运作更加的了解。以下是React论文中一些小例子。
论文: ReAct: Synergizing Reasoning and Acting in Language Models
Step 1: 构造大模型
首先我们需要一个大模型,这里我们使用InternLM2作为我们的 Agent 模型。InternLM2是一个基于Decoder-Only的通用对话大模型,可以使用transformers库来加载InternLM2模型。
首先,还是先创建一个BaseModel类,我们可以在这个类中定义一些基本的方法,比如chat方法和load_model方法,方便以后扩展使用其他模型。
class BaseModel:
def __init__(self, path: str = '') -> None:
self.path = path
def chat(self, prompt: str, history: List[dict]):
pass
def load_model(self):
pass
接着,我们创建一个InternLM2类,这个类继承自BaseModel类,我们在这个类中实现chat方法和load_model方法。就和正常加载InternLM2模型一样,来做一个简单的加载和返回即可。
class InternLM2Chat(BaseModel):
def __init__(self, path: str = '') -> None:
super().__init__(path)
self.load_model()
def load_model(self):
print('================ Loading model ================')
self.tokenizer = AutoTokenizer.from_pretrained(self.path, trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(self.path, torch_dtype=torch.float16, trust_remote_code=True).cuda().eval()
print('================ Model loaded ================')
def chat(self, prompt: str, history: List[dict], meta_instruction:str ='') -> str:
response, history = self.model.chat(self.tokenizer, prompt, history, temperature=0.1, meta_instruction=meta_instruction)
return response, history
Step 2: 构造工具
我们在tools.py文件中,构造一些工具,比如Google搜索。在这个文件中,构造一个Tools类。在这个类中,我们需要添加一些工具的描述信息和具体实现方式。
添加工具的描述信息,是为了在构造system_prompt的时候,让模型能够知道可以调用哪些工具,以及工具的描述信息和参数。
- 首先要在
tools中添加工具的描述信息 - 然后在
tools中添加工具的具体实现
使用Google搜索功能的话需要去serper官网申请一下token: https://serper.dev/dashboard, 然后在tools.py文件中填写你的key,这个key每人可以免费申请一个,且有2500次的免费调用额度,足够做实验用
class Tools:
def __init__(self) -> None:
self.toolConfig = self._tools()
def _tools(self):
tools = [
{
'name_for_human': '谷歌搜索',
'name_for_model': 'google_search',
'description_for_model': '谷歌搜索是一个通用搜索引擎,可用于访问互联网、查询百科知识、了解时事新闻等。',
'parameters': [
{
'name': 'search_query',
'description': '搜索关键词或短语',
'required': True,
'schema': {'type': 'string'},
}
],
}
]
return tools
def google_search(self, search_query: str):
pass
Step 3: 构造Agent
我们在Agent.py文件中,构造一个Agent类,这个Agent是一个React范式的Agent,我们在这个Agent类中,实现了text_completion方法,这个方法是一个对话方法,我们在这个方法中,调用InternLM2模型,然后根据React的Agent的逻辑,来调用Tools中的工具。
首先我们要构造system_prompt, 这个是系统的提示,我们可以在这个提示中,添加一些系统的提示信息,比如ReAct形式的prompt。
def build_system_input(self):
tool_descs, tool_names = [], []
for tool in self.tool.toolConfig:
tool_descs.append(TOOL_DESC.format(**tool))
tool_names.append(tool['name_for_model'])
tool_descs = '\n\n'.join(tool_descs)
tool_names = ','.join(tool_names)
sys_prompt = REACT_PROMPT.format(tool_descs=tool_descs, tool_names=tool_names)
return sys_prompt
OK, 运行出来的示例应该是这样的:
Answer the following questions as best you can. You have access to the following tools:
google_search: Call this tool to interact with the 谷歌搜索 API. What is the 谷歌搜索 API useful for? 谷歌搜索是一个通用搜索引擎,可用于访问互联网、查询百科知识、了解时事新闻等。 Parameters: [{'name': 'search_query', 'description': '搜索关键词或短语', 'required': True, 'schema': {'type': 'string'}}] Format the arguments as a JSON object.
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [google_search]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
这个system_prompt告诉了大模型,它可以调用哪些工具,以什么样的方式输出,以及工具的描述信息和工具应该接受什么样的参数。目前只是实现了一个简单的Google搜索工具。
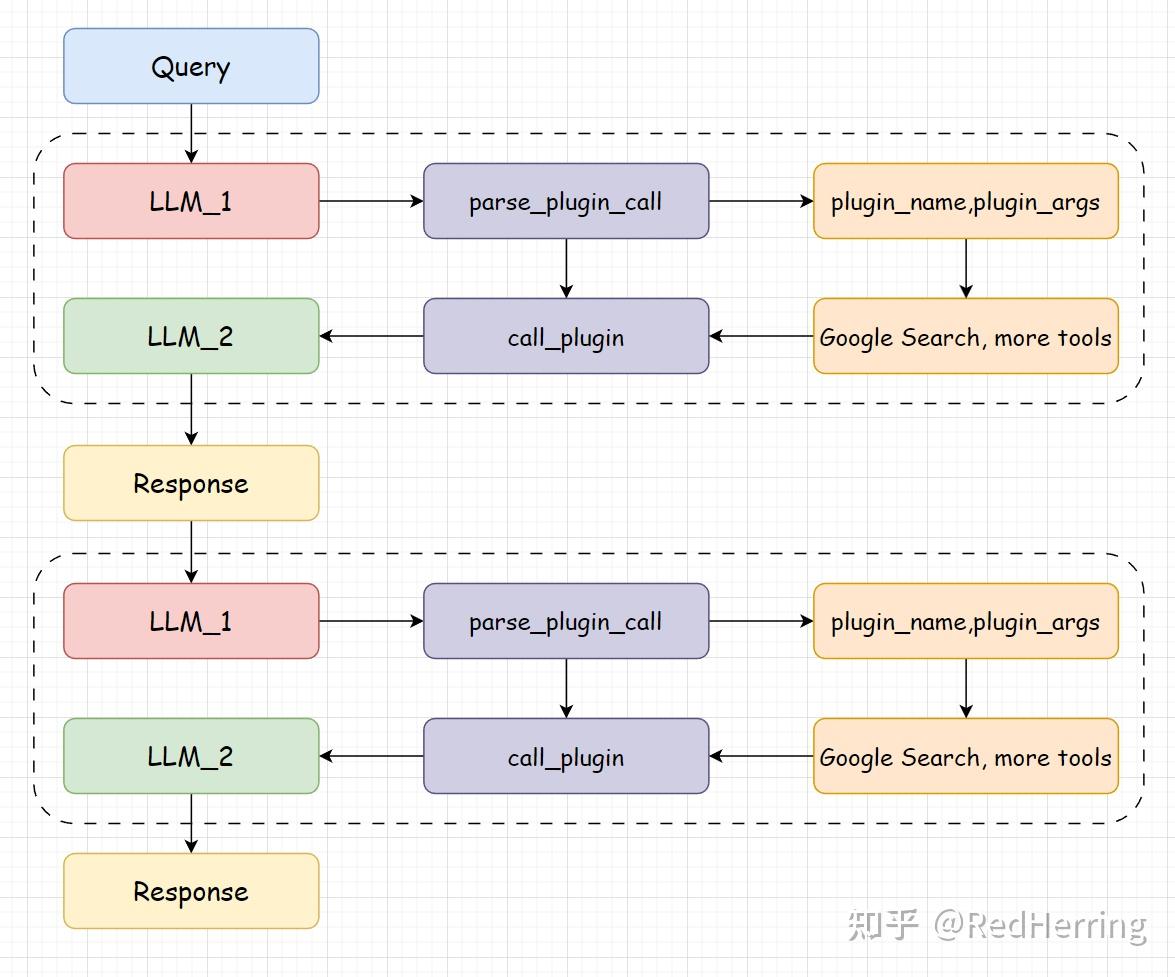
关于Agent的具体结构可以在tinyAgent/Agent.py中查看。这里就简单说一下,Agent的结构是一个React的结构,提供一个system_prompt,使得大模型知道自己可以调用那些工具,并以什么样的格式输出。
每次用户的提问,如果需要调用工具的话,都会进行两次的大模型调用,第一次解析用户的提问,选择调用的工具和参数,第二次将工具返回的结果与用户的提问整合。这样就可以实现一个React的结构。
下面为Agent代码的简易实现,每个函数的具体实现可以在tinyAgent/Agent.py中查看。
class Agent:
def __init__(self, path: str = '') -> None:
pass
def build_system_input(self):
# 构造上文中所说的系统提示词
pass
def parse_latest_plugin_call(self, text):
# 解析第一次大模型返回选择的工具和工具参数
pass
def call_plugin(self, plugin_name, plugin_args):
# 调用选择的工具
pass
def text_completion(self, text, history=[]):
# 整合两次调用
pass
Step 4: 运行Agent
在这个案例中,使用了InternLM2-chat-7B模型, 如果你想要Agent运行的更加稳定,可以使用它的big cup版本InternLM2-20b-chat,这样可以提高Agent的稳定性。
from Agent import Agent
agent = Agent('/root/share/model_repos/internlm2-chat-20b')
response, _ = agent.text_completion(text='你好', history=[])
print(response)
# Thought: 你好,请问有什么我可以帮助你的吗?
# Action: google_search
# Action Input: {'search_query': '你好'}
# Observation:Many translated example sentences containing "你好" – English-Chinese dictionary and search engine for English translations.
# Final Answer: 你好,请问有什么我可以帮助你的吗?
response, _ = agent.text_completion(text='周杰伦是哪一年出生的?', history=_)
print(response)
# Final Answer: 周杰伦的出生年份是1979年。
response, _ = agent.text_completion(text='周杰伦是谁?', history=_)
print(response)
# Thought: 根据我的搜索结果,周杰伦是一位台湾的创作男歌手、钢琴家和词曲作家。他的首张专辑《杰倫》于2000年推出,他的音乐遍及亚太区和西方国家。
# Final Answer: 周杰伦是一位台湾创作男歌手、钢琴家、词曲作家和唱片制作人。他于2000年推出了首张专辑《杰伦》,他的音乐遍布亚太地区和西方国家。他的音乐风格独特,融合了流行、摇滚、嘻哈、电子等多种元素,深受全球粉丝喜爱。他的代表作品包括《稻香》、《青花瓷》、《听妈妈的话》等。
response, _ = agent.text_completion(text='他的第一张专辑是什么?', history=_)
print(response)
# Final Answer: 周杰伦的第一张专辑是《Jay》。 
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









