







kvm Tool to trace/measure kvm guest os 用来追踪测试运行在KVM虚拟机上的Guest OS。
list List all symbolic event types 列出当前系统支持的所有性能事件。包括硬件性能事件、软件性能事件以及检查点。
lock Analyze lock events 列出当前系统支持的所有性能事件。包括硬件性能事件、软件性能事件以及检查点。
mem Profile memory accesses 内存存取情况
record Run a command and record its profile into perf.data 收集采样信息,并将其记录在perf.data数据文件中。随后可通过其它工具对数据文件进行分析。
report Read perf.data (created by perf record) and display the profile 读取perf record创建的数据文件,并给出热点分析结果。
sched Tool to trace/measure scheduler properties (latencies) 针对调度器子系统的分析工具
script Read perf.data (created by perf record) and display trace output
stat Run a command and gather performance counter statistics 执行某个命令,收集特定进程的性能概况,包括CPI、Cache丢失率等
test Runs sanity tests.perf对当前软硬件平台进行健全性测试,可用此工具测试当前的软硬件平台是否能支持perf的所有功能。
timechart Tool to visualize total system behavior during a workload 针对测试期间系统行为进行可视化的工具
top System profiling tool. 类似于linux的top命令,对系统性能进行实时分析。
version display the version of perf binary
probe Define new dynamic tracepoints 用于定义动态检查点。
trace strace inspired tool 关于syscall的工具。
See ‘perf help COMMAND’ for more information on a specific command.
►►► 对系统性能进行实时分析
perf top
perf top -h
Usage: perf top []
-a, --all-cpus system-wide collection from all CPUs
-b, --branch-any sample any taken branches
-c, --count event period to sample
-C, --cpu list of cpus to monitor
-d, --delay number of seconds to delay between refreshes
-D, --dump-symtab dump the symbol table used for profiling
-E, --entries display this many functions
-e, --event event selector. use ‘perf list’ to list available events
-f, --count-filter
only display functions with more events than this
-F, --freq <freq or ‘max’>
profile at this frequency
-g enables call-graph recording and display
-i, --no-inherit child tasks do not inherit counters
-j, --branch-filter
branch stack filter modes
-K, --hide_kernel_symbols
hide kernel symbols
-k, --vmlinux vmlinux pathname
-M, --disassembler-style
Specify disassembler style (e.g. -M intel for intel syntax)
-m, --mmap-pages
number of mmap data pages
-n, --show-nr-samples
Show a column with the number of samples
-p, --pid profile events on existing process id
-r, --realtime collect data with this RT SCHED_FIFO priority
-s, --sort <key[,key2…]>
sort by key(s): pid, comm, dso, symbol, parent, cpu, srcline, … Please refer the man page for the complete list.
-t, --tid profile events on existing thread id
-U, --hide_user_symbols
hide user symbols
-u, --uid user to profile
-v, --verbose be more verbose (show counter open errors, etc)
-w, --column-widths <width[,width…]>
don’t try to adjust column width, use these fixed values
-z, --zero zero history across updates
–asm-raw Display raw encoding of assembly instructions (default)
–call-graph <record_mode[,record_size],print_type,threshold[,print_limit],order,sort_key[,branch]>
setup and enables call-graph (stack chain/backtrace):
record_mode: call graph recording mode (fp|dwarf|lbr)
record_size: if record_mode is ‘dwarf’, max size of stack recording ()
default: 8192 (bytes)
print_type: call graph printing style (graph|flat|fractal|folded|none)
threshold: minimum call graph inclusion threshold ()
print_limit: maximum number of call graph entry ()
order: call graph order (caller|callee)
sort_key: call graph sort key (function|address)
branch: include last branch info to call graph (branch)
value: call graph value (percent|period|count)
Default: fp,graph,0.5,caller,function
–children Accumulate callchains of children and show total overhead as well
–comms <comm[,comm…]>
only consider symbols in these comms
–demangle-kernel
Enable kernel symbol demangling
–dsos <dso[,dso…]>
only consider symbols in these dsos
–fields <key[,keys…]>
output field(s): overhead, period, sample plus all of sort keys
–force don’t complain, do it
–group put the counters into a counter group
–hierarchy Show entries in a hierarchy
–ignore-callees
ignore callees of these functions in call graphs
–ignore-vmlinux don’t load vmlinux even if found
–max-stack Set the maximum stack depth when parsing the callchain. Default: kernel.perf_event_max_stack or 127
–num-thread-synthesize
number of thread to run event synthesize
–objdump
–overwrite Use a backward ring buffer, default: no
–percent-limit
Don’t show entries under that percent
–percentage <relative|absolute>
How to display percentage of filtered entries
–proc-map-timeout
per thread proc mmap processing timeout in ms
–raw-trace Show raw trace event output (do not use print fmt or plugins)
–show-total-period
Show a column with the sum of periods
–source Interleave source code with assembly code (default)
–stdio Use the stdio interface
–sym-annotate
symbol to annotate
–symbols <symbol[,symbol…]>
only consider these symbols
–tui Use the TUI interface
[root@centos7 ~]# perf top -a
Samples: 646K of event ‘cpu-clock’, 4000 Hz, Event count (approx.): 12702138322 lost: 0/0 drop: 0/0
Overhead Shared Object Symbol
29.70% php-fpm [.] 0x00000000006250c2
Samples:采集cpu时钟事件的总样本数, 可以在命令中跟上 -e 事件 参数来指定跟踪的事件,perf list 命令,列出所有可跟踪的事件。
Event count:事件总数量
Overhead:符号引起的性能事件在总采样本中的百分比
Shared Object :符号所在的DSO(Dynamic Shared Object),一般是应用程序、内核、动态连接库、模块
[.]表示此符号属于用户态的ELF文件,包括可执行文件与动态连接库;[k]表述此符号属于内核或模块。
Symbol:符号名或函数名,未知时,用十六进制显示
perf top 常用的扩展参数有
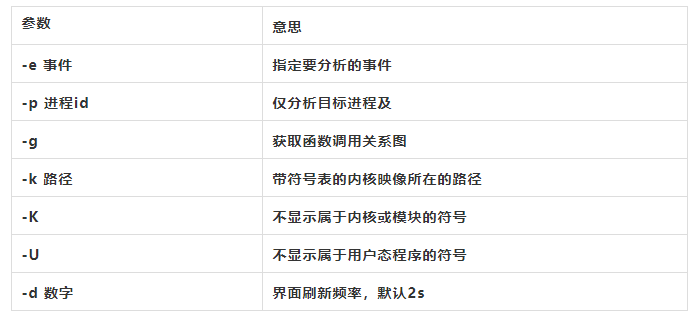
[root@centos7 ~]# perf list
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
msr/tsc/ [Kernel PMU event]
rNNN [Raw hardware event descriptor]
cpu/t1=v1[,t2=v2,t3 …]/modifier [Raw hardware event descriptor]
(see ‘man perf-list’ on how to encode it)
mem:[/len][:access] [Hardware breakpoint]
block:block_bio_backmerge [Tracepoint event]
block:block_bio_bounce [Tracepoint event]
block:block_bio_complete [Tracepoint event]
block:block_bio_frontmerge [Tracepoint event]
Software 是软件事件
Hardware\cache\Kernel PMU 都是硬件事件
Tracepoint是基于内核的ftrace
指定跟踪的事件 perf top -e block:block_rq_issue Samples: 11 of event ‘block:block_rq_issue’, 1 Hz, Event count (approx.): 1 lost: 0/0 drop: 1/8 Overhead
100.00%
14.29% 0,0 R 8 (4a 01 00 00 10 00 00 00 08 00) 0 + 0 [kworker/1:0]
跟踪某个进程的事件情况
[root@centos7 ~]# perf top -p 2087
Samples: 2K of event ‘cpu-clock’, 4000 Hz, Event count (approx.): 520562500 lost: 0/0 drop: 0/0
Overhead Shared Object Symbol
29.87% php-fpm [.] 0x00000000006250c2
►►► 具体跟踪某一个进程
perf record -g p pid
[root@centos7 ~]# perf record -g -p 2181
收集一段较长时间后,ctrl+c 停止
执行命令之后,会在当前路径下生成一个 perf.data文件
►►► 分析perf.data文件
在有perf.data文件的路径下,执行 perf report
[root@centos7 ~]# perf report
Samples: 142K of event ‘cpu-clock’, Event count (approx.): 35597750000, Thread: php-fpm
Children Self Command Shared Object Symbol
- 31.44% 0.00% php-fpm php-fpm [.] 0x000056149fda70c2 ◆
- 30.78% 30.78% php-fpm php-fpm [.] 0x00000000006250c2
看到里面的+号的行,可以回车,逐级往下定位
►►► 查看某个进程在一段时间内
调用CPU情况 perf stat
perf stat -p 进程id
执行一段时间后,ctrl+c停止
[root@centos7 ~]# perf stat -p 2399
^C
Performance counter stats for process id ‘2399’:
93,774.02 msec task-clock # 0.399 CPUs utilized
21,295 context-switches # 0.227 K/sec
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数软件测试工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上软件测试开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注软件测试)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
%以上软件测试开发知识点,真正体系化!**
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注软件测试)
[外链图片转存中…(img-XwYANykC-1712855773423)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 982
982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









