







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注软件测试)

正文
**网络带宽:**一般使用计数器Bytes Total/sec来度量,其表示为发送和接收字节的速率,包括帧字符在内;判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较;
2.3 应用指标
空闲线程数、数据库连接数、函数耗时等
2.4 前端指标
页面加载时间、网络时间(连接时间、传输时间等)
第三章 性能测试流程
按照业内目前的最佳实践,精简后的性能测试流程以及对应阶段的岗位职责,如下图:
3.1 需求阶段
3.1.1提出需求
1、有效的性能需求:
1) 明确的数据
2) 有凭有据,合理,有实际意义
3) 相关人员达成一致
2、如何获取有效的性能需求:
1) 客户方提出
2) 跟进历史数据来分析
3) 参考历史项目的数据
4) 参考其他类似行业应用的数据
5) 参考新闻或其他资料的数据
3、需求内容信息:
项目名称(立项留档、提高重视)
测试背景(为什么?充足的理由)
测试目的(容量评估、调优验证)
测试范围(什么业务?对应服务)
接口文档(哪些接口?对应地址)
调用关系(业务/系统/关系拓扑)
关键参数(线程池/连接数/JVM)
预期指标(性能指标、资源指标)
数据量级(线上数据、访问频次)
4、关于需求搜索的一些资料,仅供参考
业务选取:
系统中有很多业务,每种业务逻辑和业务量是不一样的,消耗的系统资源也不一样,因此业务种类、业务占比决定了系统的处理能力。
业务模型中的业务和占比选取不对,跟生产差异非常大,直接导致测试结果没有任何参考价值,并且容易误导对系统处理能力的判断,有些业务的业务量虽然占比很低,但一旦突变,对系统也是致命的。
所以系统中的典型业务选取一般情况下遵循的规则是选取业务量高的、经常使用的、有风险的、未来有增长趋势的业务作为系统的典型业务,已经上线的系统可以通过高峰时段历史业务量和生产问题性能来评估,对于即将上线的系统可以通过调研和单交易资源消耗的结果来评估
数据量:
数据量主要包括基础数据量(或者叫历史数据量、垫底数据量、数据库中已有的数据量)和参数化数据量,对于数据库中只有几条记录和有几亿记录里面查询,结果肯定相差非常大。
输入数据量不太同一数量级上,将会导致相关指标不真实,甚至导致测试结果没参考意义,如果参数化数据量过少,未考虑数据分布的情况的,测试结果会不太真实,没有参考意义,需要考虑数据准备的完整性,还有清理的逻辑需要完整。
如果测试环境和生产环境在同一数据量级上,那需要考虑未来三年的数据量增长趋势,如果增长过快需要在测试环境造非常多的数据;参数化数据量尽可能的多,参数化数据分布,如果业务有明显的地域分布特征,需要考虑数据分布的情况
测试结果中各业务TPS占比需跟生产上业务占比(业务模型)相一致,可以使用PTS特有的RPS模式(Request Per Second,直接测试吞吐能力)来保证一致。 例如:A和B两笔业务,占比为1:4,响应时间分别为1ms、100ms,那么只需要通过PTS给A和B两个接口按照1:4比例设置请求数(TPS)施压即可。如果使用传统的并发模式,A和B的并发需要经过换算确保比例是1:400,使得最终与生产上保持一致的业务模型
3.1.2需求评审
需要多方相关人员参与评审,从各自的角度给出意见,沟通达成一致,决定后续的要不要做?怎么做?以及谁来做什么事情!
3.1.3需求调研
需求调研阶段主要是对后续性能测试实施的一些必要信息进行更细致的沟通和确认,以及在职责、工时、排期、交付时间这几点上寻求平衡的可接受的点,并在各项信息确定后输入测试计划文档。
3.2 准备阶段
3.2.1 环境准备
压测环境需要尽量和生产环境配置一致,且尽量有一套独立的压测环境。当测试环境与实际生产环境差异较大时,性能测试结果往往不被接受,如果在性能测试实施过程中,无法搭建相对真实的测试环境,即可认为被测对象不具备性能的可测性。
测试环境搭建:
1) 测试环境与线上环境架构要相同
2) 机型尽量相同,云化的资源确保是同规格ECS或者容器
3) 软件版本相同:操作系统、中间件相关、数据库、应用等
4) 参数配置相同:操作系统参数、中间件参数、数据库参数、应用参数
5) 数据量需要在同一数量级上
6) 测试环境机器台数需要同比例缩小,而不能只减少某一层的机器台数
7) 测试环境等比配置是生产环境的1/2 、1/4
测试环境调研:
1) 系统架构:系统如何组成的,每一层功能是做什么的,与生产环境有多大差异,主 要为后面进行瓶颈分析服务和生产环境性能评估,这个很重要
2) 操作系统平台:操作系统是哪种平台,进行工具监控
3) 中间件:哪种中间件,进行工具监控和瓶颈定位
4) 数据库:哪种数据库,进行工具监控和瓶颈定位
5) 应用:启动多少个实例,启动参数是多少,进行问题查找和瓶颈定位
6) 可以配合APM工具进行中间件、数据库、应用层面的问题定位
3.2.2 应用部署
性能测试的被测应用必须是稳定的,需要是没有P2及以上缺陷或通过回归测试的版本包
3.2.3 数据准备
性能测试对数据的要求是很高的,无论是数据量级、精准度抑或是数据的多样性。一般分为如下几种数据类型:
**铺底数据:**最常见的准备方式为从生产拖库最新的最完整的基础数据来作为性能测试所用;
**测试数据:**比如性能测试场景需要读写大量的数据,而为了保证测试结果的准确性,一般通过从生产拉取同等量级或者至少未来一年的增长量级的脱敏数据;
**参数化数据:**不同类型的数据处理逻辑有差异时,需要通过测试数据的多样化来提高性能测试代码的覆盖率,而参数化是最常见的方式;
3.2.4 脚本开发
性能测试脚本需要针对业务模型转化后的测试模型以及采用的测试策略进行针对性的开发调试试运行。
3.3 实施阶段
3.3.1 压测执行
性能测试执行阶段,是需要执行很多轮次,且测试脚本也需要不断地调整修改,根据测试结果不断改进的,这样才能得到更为准确的测试结果。
3.3.2 服务监控
这个阶段称之为APM(Application Performance Management:对应用程序性能和可用性的监控管理)更合适。
狭义上的APM单指应用程序的监控,如应用的各接口性能和错误监控,分布式调用链路跟踪,以及其他各类用于诊断(内存,线程等)的监控信息等。
广义上的APM, 除了应用层的监控意外,还包括App端监控、页面端监控、容器、服务器监控,以及其他平台组件如中间件容器、数据库等层面的监控。
3.3.3 瓶颈定位
进行性能测试的目的,就是为了探测系统是否存在影响提供正常服务的性能瓶颈以及为上线提供容量评估。
如果系统性能表现未到达预期指标,则需要对日志、监控数据进行分析,定位其性能瓶颈并针对性的进行优化才可以。
3.3.4 优化验证
发现性能瓶颈并修改优化后,需要再次执行压测,以验证问题是否得到解决以及性能的提升能力,衡量的标准是需求评审和调研阶段确定的业务性能指标。
3.4 结束阶段
性能测试结束的标志,一般包括如下几点:涉及的测试场景均已测试完毕、测试过程中发现的问题已全部修复验证、测试结果达到了预期的性能指标、满足上线要求。
3.4.1 测试报告
在满足上面4个条件后,测试人员出具一份简洁但是明确的测试报告,说明本次性能测试的目的、范围、环境信息、测试结果、问题,并给出测试结论。
3.4.2 报告评审
参与本次性能测试各环节工作的各个角色都参与进行评审,大家对结果无异议,即可视为本次性能测试结束。
第四章 监控
4.1目的
监控的目的主要是为进行性能测试分析服务,完善会系统进行监控,针对瓶颈定位起到事半功倍的效果,一般需要针对操作系统、中间件、数据库、应用等进行监控,每种类型的监控尽量指标全面。
4.2 参数
**操作系统:**CPU(user、sys、wait、idle)利用率、内存利用率(包括SWAP)、磁盘I/O、网络I/O、内核参数等
中间件**:**线程池、JDBC连接池、JVM(GC/FULLGC/堆大小)
**数据库:**效率低下的SQL、锁、缓存、会话、进程数等
**应用:**方法耗时、同步与异步、缓冲、缓存
第五章 关于我们目前
1、测试性能的电脑,配置不能太低,可以分布式压测
2、我们目前测试环境,一台服务器上部署多个项目,做性能测试项目会有影响,压测的意义不大
3、我们目前最大的压力应该在MQTT上,主要是设备访问,是否可控制每秒的设备接入量,如,这一秒接入100请求,下一秒在接入100,就不用同秒去处理1000或更多,产生压力
查的资料:MQTT通讯使用TLS证书:性能上TCP 1G内存可维持5W的连接数,使用TLS 1G内存大约维持1.5W左右的连接数,
查询的他人结果:12W连接8G内存消耗
15W连接CPU维持利用率在100%–150%
25W连接12G内存消耗
每秒连接速度3000/S 4核剩余20%空闲
【压测工具介绍篇(wrk,ab。jmeter】
【ab】
全称:ApacheBench,用于 web 性能压力测试,ab 命令会创建很多的并发访问线程,模拟多个访问者同时对某一URL地址进行访问。
ab 命令对发出负载的计算机要求很低,不会占用很高CPU和内存,但却会给目标服务器造成巨大的负载。
ab 是 apache 服务器的附属工具,当然如果不需要 apache 也可以独立安装。
ubuntu
apt install -y apache2-utils
centos
yum install -y httpd-tools
帮助文档:
ab -h
Usage: ab [options] [http[s]😕/]hostname[:port]/path
Options are:
-n requests Number of requests to perform
-c concurrency Number of multiple requests to make at a time
-t timelimit Seconds to max. to spend on benchmarking
This implies -n 50000
-s timeout Seconds to max. wait for each response
Default is 30 seconds
-b windowsize Size of TCP send/receive buffer, in bytes
-B address Address to bind to when making outgoing connections
-p postfile File containing data to POST. Remember also to set -T
-u putfile File containing data to PUT. Remember also to set -T
-T content-type Content-type header to use for POST/PUT data, eg.
‘application/x-www-form-urlencoded’
Default is ‘text/plain’
-v verbosity How much troubleshooting info to print
-w Print out results in HTML tables
-i Use HEAD instead of GET
-x attributes String to insert as table attributes
-y attributes String to insert as tr attributes
-z attributes String to insert as td or th attributes
-C attribute Add cookie, eg. ‘Apache=1234’. (repeatable)
-H attribute Add Arbitrary header line, eg. ‘Accept-Encoding: gzip’
Inserted after all normal header lines. (repeatable)
-A attribute Add Basic WWW Authentication, the attributes
are a colon separated username and password.
-P attribute Add Basic Proxy Authentication, the attributes
are a colon separated username and password.
-X proxy:port Proxyserver and port number to use
-V Print version number and exit
-k Use HTTP KeepAlive feature
-d Do not show percentiles served table.
-S Do not show confidence estimators and warnings.
-q Do not show progress when doing more than 150 requests
-g filename Output collected data to gnuplot format file.
-e filename Output CSV file with percentages served
-r Don’t exit on socket receive errors.
-h Display usage information (this message)
-Z ciphersuite Specify SSL/TLS cipher suite (See openssl ciphers)
-f protocol Specify SSL/TLS protocol
(SSL3, TLS1, TLS1.1, TLS1.2 or ALL)
常用的参数:
-c线程数(并发数)-n请求数,总共要发送多少请求-pPOST请求使用文件-T请求类型,Content-Type, 可以用-H替代-H请求头
废话少说,上实例:
创建10个线程(模拟10个用户),累计向百度发送100个请求
ab -c 10 -n 100 https://www.baidu.com/
Server Software: BWS/1.1
Server Hostname: www.baidu.com
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES128-GCM-SHA256,2048,128
Document Path: /
Document Length: 227 bytes
Concurrency Level: 10
Time taken for tests: 0.711 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 111095 bytes
HTML transferred: 22700 bytes
Requests per second: 140.56 [#/sec] (mean)
Time per request: 71.144 [ms] (mean)
Time per request: 7.114 [ms] (mean, across all concurrent requests)
Transfer rate: 152.49 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 34 46 6.6 45 62
Processing: 12 16 3.5 16 41
Waiting: 12 16 3.4 15 41
Total: 48 62 8.4 62 86
Percentage of the requests served within a certain time (ms)
50% 62
66% 66
75% 68
80% 70
90% 73
95% 75
98% 83
99% 86
100% 86 (longest request)
POST请求,需创建参数文件
data.txt
a=1&b=2
ab -c 10 -n 100 -p data.txt -T ‘application/x-www-form-urlencoded’ https://www.baidu.com/
data.json
{“a”:1}
ab -c 10 -n 100 -p data.json -T ‘application/json’ https://www.baidu.com/
注: 线程数跟 ulimit 有关,centos 默认 ulimit=1024 最大不超过1024个线程,如需更多线程,可以调整 ulimit 值。
【wrk】
与 ab 的区别是 wrk 可以指定持续压测的时间(例如:持续打压30分钟)并且支持 lua 脚本的执行,支持多个URL的压测,更加具备扩展性和灵活性。
https://github.com/wg/wrk
https://github.com/wg/wrk/tree/master/scripts
centos安装wrk
yum install git -y
git clone https://github.com/wg/wrk.git wrk
yum install unzip -y
yum install gcc -y
make
cp wrk /usr/local/bin/
帮助文档:
wrk --help
Usage: wrk
Options:
-c, --connections Connections to keep open
-d, --duration Duration of test
-t, --threads Number of threads to use
-s, --script Load Lua script file
-H, --header Add header to request
–latency Print latency statistics
–timeout Socket/request timeout
-v, --version Print version details
Numeric arguments may include a SI unit (1k, 1M, 1G)
Time arguments may include a time unit (2s, 2m, 2h)
开2个线程,建立6个连接,持续请求百度5s
wrk -t 2 -c 6 -d 5s https://www.baidu.com
Running 5s test @ https://www.baidu.com
2 threads and 6 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 15.97ms 3.58ms 36.06ms 86.53%
Req/Sec 185.96 21.39 220.00 82.00%
1862 requests in 5.03s, 27.90MB read
Socket errors: connect 0, read 3, write 0, timeout 0
Requests/sec: 369.85
Transfer/sec: 5.54MB
原理示意图:
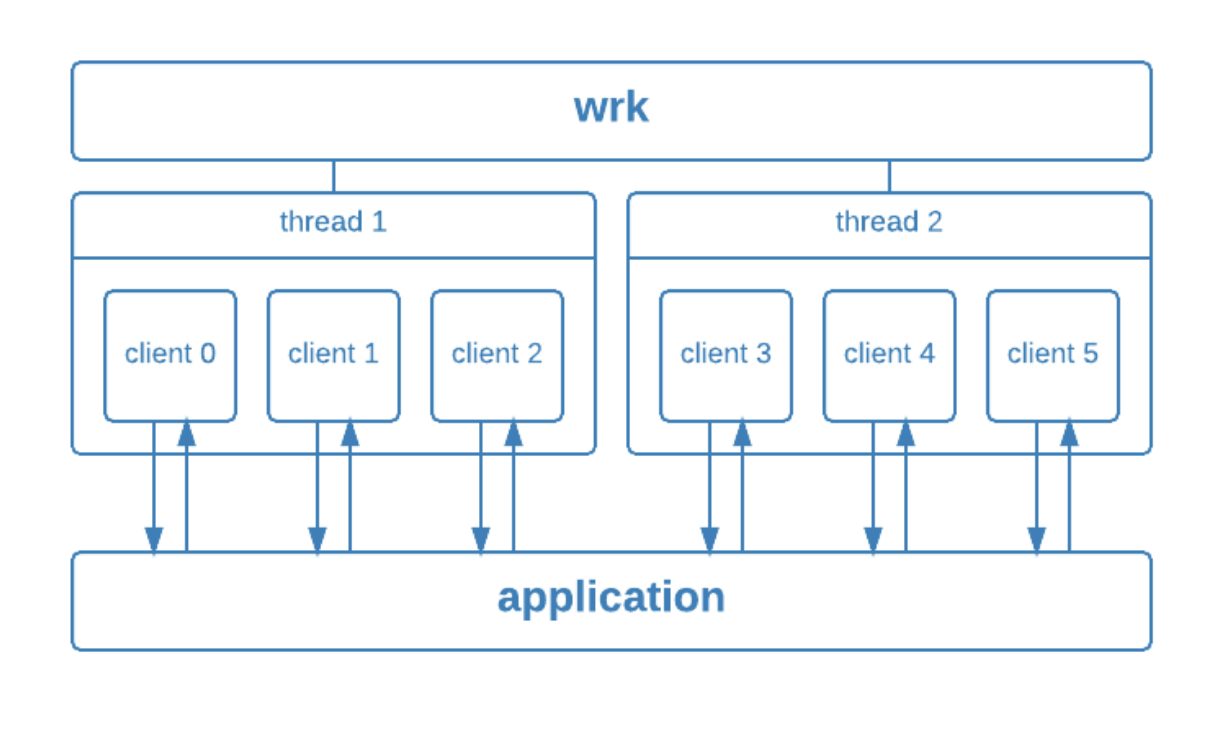
使用脚本发送表单请求
post.lua
wrk.method = “POST”
wrk.body = “login=sammy&password=test”
wrk.headers[“Content-Type”] = “application/x-www-form-urlencoded”
wrk -t 2 -c 6 -d 5s -s post.lua https://www.baidu.co
工具介绍
【LoadRunner】
安装
- 完整安装必须要在 windows 下
- windows 只支持专业版和旗舰版(家庭版无管理员权限)
- 浏览器: IE 8/9【只支持IE9以下的浏览器】
- linux 不支持完整安装 LoadRunner,只可以安装其中的一个功能 – Load Generator压力机
组成
- 三大组件
- VuGen(Virtual User Generator)虚拟用户发生器,编写脚本
- Controller 控制运行脚本
- Analysis 分析器
LoadRunner 三大组件
组件 – VuGen
Web Tours 默认的浏览器打开文件
默认用户名: jojo , 密码:bean
录制时的浏览器如果是64位的系统,一定要选择program file(x86)下面的 ie 浏览器
VuGen 的脚本分为三个部分:Vuser_init,Action,Vuser_end。其中Vuser_init和Vuser_end 都只能存在一个,而Action 可分成无数多个部分,可以通过点击旁边的[new]按钮来创建Action,在迭代执行测试脚本时,Vuser_init和Vuser_end 中的内容只会执行一次,迭代的是Action部分。
录制脚本不同级别的却别:
Options->Recording Options ->Recording
- HTML
- 第一个选项:
所有的连带请求都以一个函数的形式来处理,根据动作不同来区分。(按照页面内容来操作生成的脚本)
- 第二个选项:
相比第一个选项的函数数据内容会更多一点。(以接口请求数据来封装)
- URL
- 因为请求网址的时候会有很多连带接口请求
- URL的方式,会将每一个的接口请求的 URL ,都单独用函数的形式封装起来
组件 – Controller
Tools->Create Scenario
- Goal Oriented Scenario:目标场景
- Manual Scenario:手工场景
- Number of Vusers:虚拟用户数量
- Load Generator:压力机
- Group Name:脚本名称
- Result Directory:结果目录
打开 Controller 页面:
Design
Global Schedule:全局清单
- Initalize:初始化运行 脚本中的 vuser_init() 部分
- Start Vusers:
- EditAction 配置虚拟用户相关内容
- simultaneously:同时加载所有用户
- 每隔一段时间加载用户
- Duration: 持续运行 Action() 脚本时间
- Stop Vusers: 运行 vuser_end() 脚本部分
Run
开始—>停止—>Result 菜单—>Analyze Results
Start Scenario:开始运行场景
四张表
Running Vusers – whole scenario
Trans Response Time – whole scenario
Hits per Second – whole scenario
Windows Resources – Last 60 sec
Stop 停止后
组件 – Analyze Results – 分析器
Reports :报告
- summary report :概要报表
Graphs:图表
- Running Vusers:
- Hits per Second:每秒命中
- Throughput:吞吐量
- Transaction Summary:事务摘要
- Average Transaction Response Time:平均事务响应时间
action 与 Controller 中场景运行策略间的对应关系
案例分析
案例1:
如果性能测试只测试订票的过程的响应时间,如何开发脚本?
- 将登陆和退出的脚本放在init 和 end 当中,具体想要测试的放在Action 脚本中
案例2:
上面的订票过程我想把订票过程分别计时怎么办?
day2
Vuser菜单—>Runtime Settings:
- RunLogic: 迭代次数:Generate Run Logic
- Pacing 运行脚本的节奏控制时机:
- As soon as the previos iteration ends:一旦previos迭代结束
- After the previous iteration ends:在上一次迭代结束后
- provided that the previous iteration ends by that time:前提是上一次迭代在那个时候结束
- Log
- Send messages only when an error occurs :出错的时候才出现日志
- Always send messages: 总是有日志
- Extended Log :扩展日志
- Parameter substitution:将参数输出到日志中
- Data returned by server :服务器返回:将服务器返回给客户端的数据输出到日志文件中
- Advanced trace:高级:所有的虚拟用户信息和函数调用输出到日志文件中
- Think Time
- Ignore think time : 忽略等待时间
- Replay think time :
- As recorded 与录制时间一致
- Multiply recorded think time by :原有时间的倍数
- Use random percentage of recorded think time:使用录制时间的随机百分比范围
- Limit think time to xx seconds :具体设定
- 作用:更加真实的去模拟用户操作之间的延迟
- Preferences 参数选择
- checks:启用,关闭图片和文本检查
- Generate Web performance graphs:生成Web性能图
- Advanced 高级的
- Miscellaneous:多线程的
- Error Handling
- Multithreading
- 进程方式运行虚拟用户
- 进程独享一块内存,比较稳定,大约占用4M以上
- 内存资源浪费,可以模拟的虚拟用户少
- 线程方式虚拟用户
- 线程之间共享一块内存们可以模拟的虚拟用户多,大约占用1M~2M
- 线程之间容易发生资源竞争,出现进程阻塞不稳定
学习函数
web_url
- 作用:模拟浏览器发出 get 请求
- 用法:
- 步骤名称:”访问首页“
- 请求地址:”URL=http://www.baidu.com“ ,通过抓包或接口文档获取
- LAST);
web_submit_data()
- 作用:模拟浏览器发出 get/post 请求
- 用法:
- 步骤名称
- 请求地址:”Action=http://www.baidu.com“,
- 请求方法:“Method=POST” ,(只支持get 和post)
- 请求模式:“Mode=HTTP/HTML”,
- 表单数据Data: 抓包工具获取
- ITEMDATA,”Name=xxx“,“Value=xxx”,ENCITEM
- LAST);
在编写脚本时候点击菜单Insert -->New Step–>Add Step:提供了非常多的函数
web_custom_request() (重点)
- 作用:模拟浏览器HTTP 支持的任何方式的请求
- 比上面用法多了一个Body 请求正文
- 注意:函数中mode 为http时,Test-results 中看不到浏览器中的页面
IShop 案例 使用XAMPP Control Panel v3.2.1
参数化设置
如何让很多不同的用户名密码的用户进行登陆?
- 让脚本使用批量的变化的数据测试,实现模拟不同数据/用户的行为
自动化思想:数据和代码分离
Parameter List:
—>New—>
脚本中右键所需参数:–>Replace with a Parameter :选择参数名称
”Value={username}“
获取变量值lr_eval_string("{username}")
输出log取到的用户名的值:
lr_output_message(“获取到的值为:”,lr_eval_string(“{username}”))
双击选中函数按 F1 可以查看 API
多次操作才会取多个参数
- Select next row: 顺序
- Squential 顺序
- Random 随机
- Unique 唯一
- Same line as xxx
- **【A】**Update value on:
- Each iteration 每次迭代时。
- Each occurrence 每次发生时。(每次取值时)
- Once 每次都一样
- **【B】**When out of values:当超过值的最大数量时候
- Abort Vuser:中止 Vuser
- Continue in a cyclic manner:以循环方式继续
- Continue with last value:继续最后一个值
- Allocate Vuser values in the Controller:在控制器中分配Vuser值
例子:10个数据,2个用户平均最多5次
- Automatically allocate block size:自动分配块大小
- Allocate [xxx] values for each Vuser:为每个虚拟用户分配
- A1B1:每次迭代内取值不变,下一次迭代才换值
- A1B2:每次取值取下一个值
- A1B3:值不变
- A2B1:每次迭代才会取随机取值,一次迭代内的都是一样的值
- A2B2:每次取值都会随机取
- A2B3:每次发生随机取值,之后本次脚本执行内永远不变。下次执行脚本才改变
- A3B1:每次迭代,唯一取值,迭代内值不会重复
- A3B2:…见 思维导图
跨 Action 可共同使用参数,但不可共同使用变量
输入用户名和密码进行登陆:
- 需要实时的获取上一个请求的响应数据终得userSession 对应的值,放到登陆的请求数据中即可
- 实时取值的方式:关联
- 需要实时的获取上一个请求的响应数据中的userSession 对应的值,放到登陆的请求数据中即可
- 如果知道如何取值那么就可以实现登陆成功
- 实时取值的方式:【关联】
- 该关联函数:带有reg字样,凡是带有reg字样的函数我们都成为注册型函数
- 注册型函数的特点:哪一个请求响应数据中,有我们需要的数据,那么该函数就放在请求的前面,放在web_url() 请求函数的前面。中间不能有其他函数。
- web_reg_save_param() 关联函数,取匹配相关参数session
高级关联
高级关联使用时:将Instance:设置为all。取到的就是数组
lr_paramarr_idx(“fights”,4);
lr_paramarr_len()//获取值的数量
lr_paramarr_random()//获取数组中的随机一个元素
char * str;
str = lr_paramarr_idx(“fights”,4); //变量定义必须放在首行
//str 的值为字符串,而非参数,所以不能直接将字符串放入下面的代码中
lr_save_string(“helloworld”,“aaa”);//将helloworld放入参数 aaa 中
注意:关联和具体代码中间不能有代码
事务
duration:0.4678 Wasted Time:0.0077
实际事务时间=duration 持续时间 -waster time 浪费的时间
lr_end_transaction(“login”,LR_AUTO);//在这里LR_AUTO判断的是服务器的返回状态码,而并没有判断该业务是否成功
内部实现:
code = web_get_int_property(HTTP_INFO_RETURN_CODE)
//PASS:通过。FAIL:错误。
if(code==200){
lr_end_transaction(“login”,LR_PASS);
}else{
lr_end_transaction(“login”,LR_FAIL)
}
web_reg_find() 解决方案:
-
通过添加检查点的方式来验证业务是否成功,如果存在要检查的内容那么就给一个状态 LR_PASS,否则给 LR_FAIL。
-
检查点函数:web_reg_find()---->带有 reg 的为注册型函数—
-
特点:如果某一请求的响应数据中有想要的数据,就将该函数放在请求前面。
-
生成的检查点函数:
方法:
if(atoi(lr_eval_string(“{number}”))>0){//atoi字符串转证书
lr_end_transaction(“login”,LR_PASS);
}else{
lr_end_transaction(“login”,LR_FAIL);
}
- atoi()字符串转整数
- itoa()整数转字符串
Create Scenario 创建。多虚拟用户模拟数据
- Select Scenario TYpe
- Manual Scenario。
选择脚本
web_reg_find 函数和 web_find 普通函数的区别;
使用时,必须启用image and text checks图片和文本检查项
不建议使用。
web_find(“web_find”,"LeftOf=,“What=Welcome,jojo”,LAST)
思考时间
lr_think_time(秒数)
压力曲线分析图(重点)
纵轴:
- Utilization: 服务器资源 (内存,CPU)
- Throughput: 吞吐量
- Response:响应时间
横轴:
- 用户并发数
曲线图主要分三个区域:(不断加压的过程,看它的变化情况)
- light load:轻压力区。(用户数和纵轴资源等正比)
- 并发测试区
- 第一个拐点(最佳用户并发点)
- 最佳并发用户点
- 在这个点之前可以做并发测试
- 吞吐不再明显增加
- 请求数也不再变了
- heavy load:重压力区。
- 服务器处理不过来那么大量的请求,需要等待,但服务器还没挂
- 压力测试区
- 第二个拐点。(最大并发用户数点点)
- 逐步的加压
- 达到最大并发用户数
- 超过服务器就崩掉
- buckle load:(第二个拐点)
- 随着并发用户数增加,响应时间急剧增长,服务器已经无法处理。吞吐量降低,服务器崩溃。
通过 Controller 负载测试来找以上的各个拐点,前提脚本没有问题。
Controller 并发控制时
- Duration 和 Iteration 迭代次数都有值的情况下,按Duration 走
- Details–>Group Information
- View Script
- RUnTIme Setting
- Refresh
- 脚本
- 运行时设置
压力机查看:
- add 可添加新的压力机:
- Name: 192.xxxxx目标电脑机器 IP 地址。
- 如果目标地址有loadrunner 就能链接上
- 出现Failed原因:目标机器需要开启压力机代理:
- 开始菜单 :HP LoadRunner–> Advanced Settings --> LoadRunner Agent Process
Global Schedule :
- 增加:逐步增加并发用户(防止服务器崩溃)
- 结束:逐步减少并发用户
Day-05
New Scenario
Select Scenario Type
- Manual Scenario
- Manage your load test by specifying the bumber of virtual users to run
- Use the Percentage Mode to distribute the Vusers among the scripts
- Goal-Oriented Scenario
- Allow LoadRunner Controller to create a scenario based on the goals you specify
Controller 场景策略方案
联机负载
Scenario–> Convert Scenario to the Percentage Mode:转换场景到百分比模式
ctrl+H 替换
调整百分比模式后,可以多台机器压测服务
IP 欺骗
问:每一个虚拟用户的 IP 是多少?
有些网站不允许多用户同一个IP连续访问,所以需要 IP 欺骗.
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
数都有值的情况下,按Duration 走
- Details–>Group Information
- View Script
- RUnTIme Setting
- Refresh
- 脚本
- 运行时设置
压力机查看:
- add 可添加新的压力机:
- Name: 192.xxxxx目标电脑机器 IP 地址。
- 如果目标地址有loadrunner 就能链接上
- 出现Failed原因:目标机器需要开启压力机代理:
- 开始菜单 :HP LoadRunner–> Advanced Settings --> LoadRunner Agent Process
Global Schedule :
- 增加:逐步增加并发用户(防止服务器崩溃)
- 结束:逐步减少并发用户
Day-05
New Scenario
Select Scenario Type
- Manual Scenario
- Manage your load test by specifying the bumber of virtual users to run
- Use the Percentage Mode to distribute the Vusers among the scripts
- Goal-Oriented Scenario
- Allow LoadRunner Controller to create a scenario based on the goals you specify
Controller 场景策略方案
联机负载
Scenario–> Convert Scenario to the Percentage Mode:转换场景到百分比模式
ctrl+H 替换
调整百分比模式后,可以多台机器压测服务
IP 欺骗
问:每一个虚拟用户的 IP 是多少?
有些网站不允许多用户同一个IP连续访问,所以需要 IP 欺骗.
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)
[外链图片转存中…(img-9ivXEo9X-1713293864323)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









