







 本文探讨了AI系统中的安全问题,包括基于模型输出的隐私泄露风险,分布式训练中的梯度窃取,以及对抗样本攻击的原理与应用,如对抗训练和生成对抗网络(GAN)。文章还强调了网络安全的重要性,提供了学习资源和成长路线指导。
本文探讨了AI系统中的安全问题,包括基于模型输出的隐私泄露风险,分布式训练中的梯度窃取,以及对抗样本攻击的原理与应用,如对抗训练和生成对抗网络(GAN)。文章还强调了网络安全的重要性,提供了学习资源和成长路线指导。
1)基于模型的输出结果,模型的输出结果隐含着训练/测试数据的相关属性。
2)基于模型训练产生的梯度(参数),该问题主要存在于模型的分布式训练中,多个模型训练方之间交换的模型参数的梯度也可被用于窃取训练数据。
三、ai系统安全
承载 AI 技术的应用系统主要包括 AI 技术使用的基础**物理设备和软件架构(pytorch等),**是 AI 模型中数据收集存储、执行算法、上线运行等所有功能的基础。
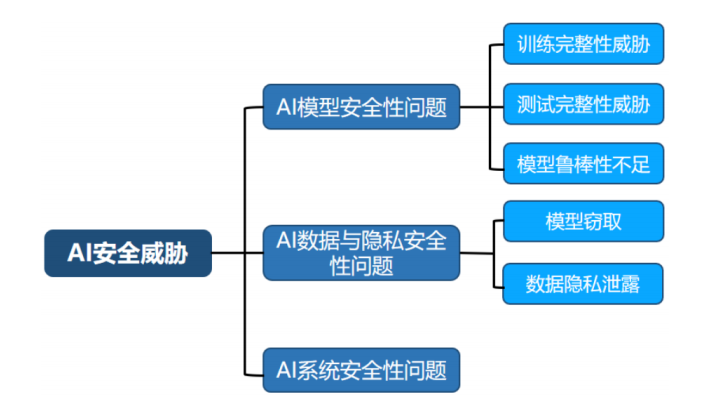
对抗样本攻击
研究者还发现在输入数据上添加少量精心构造的人类无法识别的**“扰动”,可以使 AI 模型输出错误的预测结果。这种添加扰动的输入数据通常被称为对抗样本(Adversarial Example)**。在许多安全相关的应用场景中,对抗样本攻击会引起严重的安全隐患。属于ai模型安全。
以自动驾驶为例,攻击者可以在路牌上粘贴对抗样本扰动图案,使得自动驾驶系统错误地将“停止”路牌识别为“限速”路牌 。这类攻击可以成功地欺骗特斯拉等自动驾驶车辆中的路标识别系统,使其作出错误的驾驶决策判断,导致严重的交通事故。
隐私泄露
研究者发现 AI 技术在使用过程中产生的计算信息可能会造成隐私数据泄露,例如攻击者可以在不接触隐私数据的情况下利用模型输出结果、模型梯度更新等信息来间接获取用户隐私数据。在实际应用中,这类信息窃取威胁会导致严重的隐私泄露。属于ai数据安全。
例如:生物核身识别模型**(如人脸识别)返回的结果向量可以被用于训练生成模型**,从而恢复如用户头像等训练数据中的敏感信息(原始输入数据)。攻击者甚至还可以通过输出结果窃取 AI 模型的参数,对模型拥有者造成严重的经济损害。在这种情况下,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









