






在学习推荐算法的过程中,我发现基于用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)都有缺陷,于是思考是否可以结合这两种算法各取其长,互补其短,于是我尝试了一下,这是一些思考点:
- 掌握如何将 UserCF 和 ItemCF 结合起来,构建混合推荐算法。
- 学会如何动态调整权重 α,以适应不同的用户和场景。
- 通过通过实际案例的计算,加深对算法的理解。
(1) 先了解算法UserCF 和 ItemCF 的原理
- UserCF:通过找到和目标用户相似的其他用户,根据这些相似用户的行为来推荐物品。
- ItemCF:通过找到和目标物品相似的其他物品,根据用户对这些相似物品的行为来推荐。
(2) 混合推荐算法的核心公式
混合推荐算法将 UserCF 和 ItemCF 结合起来,公式如下:


-
同时我打算从以下结果确定方面权重 α
- 动态权重:根据用户的历史交互次数动态调整 α。
- 交叉验证:通过交叉验证选择最优的 α。
- 用户分组:为不同用户组设置不同的 α。
- 机器学习:使用机器学习模型预测每个用户的 α。
3. 实际案例与计算
假设有一个电商平台,用户对商品的购买记录如下:
| 用户 | 商品1 | 商品2 | 商品3 | 商品4 |
|---|---|---|---|---|
| 用户A | 1 | 0 | 1 | 0 |
| 用户B | 1 | 1 | 0 | 0 |
| 用户C | 0 | 1 | 0 | 1 |
| 用户D | 0 | 0 | 1 | 1 |
目标是为用户A推荐商品。
计算步骤
-
计算用户相似度(UserCF)
- 用户A和用户B的相似度:
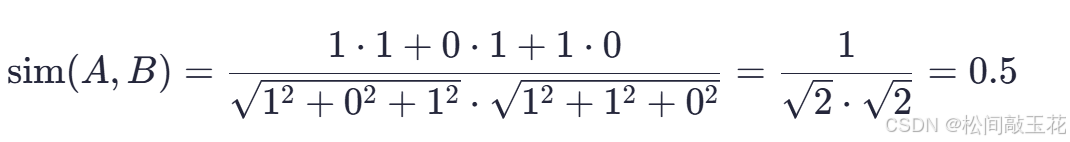
-
计算物品相似度(ItemCF)
商品1和商品3的相似度: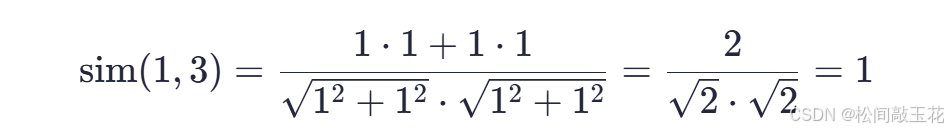
-
计算 UserCF 推荐分数
为用户A推荐商品2: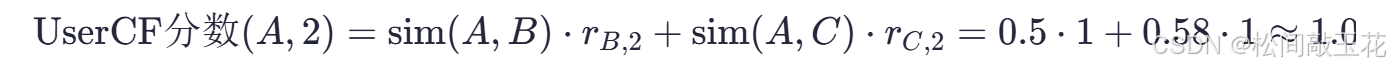
-
计算 ItemCF 推荐分数
为用户A推荐商品2: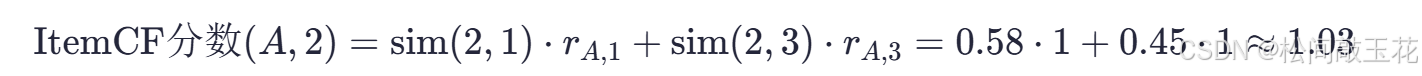
-
动态权重计算
用户A的历史交互次数为 2,假设阈值为 5: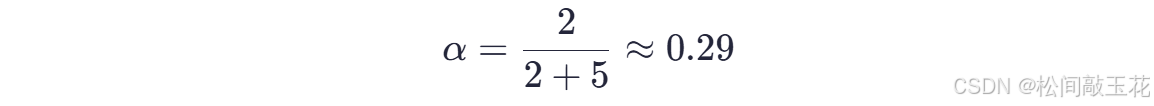
-
混合推荐分数
为用户A推荐商品2: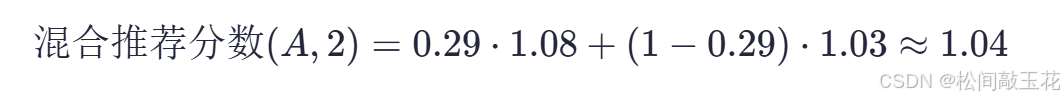
- 用户A和用户B的相似度:
相关用ai进行了相关润色的参考代码(哈哈)
import numpy as np
from collections import defaultdict
# 用户-商品购买矩阵
user_item_matrix = {
'UserA': {'Item1': 1, 'Item3': 1},
'UserB': {'Item1': 1, 'Item2': 1},
'UserC': {'Item2': 1, 'Item4': 1},
'UserD': {'Item3': 1, 'Item4': 1},
}
# 计算用户相似度 (UserCF)
def calculate_user_similarity(user_item_matrix):
users = list(user_item_matrix.keys())
user_similarity = defaultdict(dict)
for i in range(len(users)):
for j in range(i + 1, len(users)):
u1, u2 = users[i], users[j]
common_items = set(user_item_matrix[u1].keys()) & set(user_item_matrix[u2].keys())
if common_items:
numerator = sum(user_item_matrix[u1][item] * user_item_matrix[u2][item] for item in common_items)
denominator = np.sqrt(sum(np.square(list(user_item_matrix[u1].values())))) * np.sqrt(sum(np.square(list(user_item_matrix[u2].values()))))
similarity = numerator / denominator
user_similarity[u1][u2] = similarity
user_similarity[u2][u1] = similarity
return user_similarity
# 计算物品相似度 (ItemCF)
def calculate_item_similarity(user_item_matrix):
items = set(item for user in user_item_matrix.values() for item in user.keys())
item_similarity = defaultdict(dict)
for item1 in items:
for item2 in items:
if item1 != item2:
common_users = [user for user in user_item_matrix if item1 in user_item_matrix[user] and item2 in user_item_matrix[user]]
if common_users:
numerator = sum(user_item_matrix[user][item1] * user_item_matrix[user][item2] for user in common_users)
denominator = np.sqrt(sum(np.square([user_item_matrix[user][item1] for user in common_users]))) * np.sqrt(sum(np.square([user_item_matrix[user][item2] for user in common_users])))
similarity = numerator / denominator
item_similarity[item1][item2] = similarity
return item_similarity
# 动态权重计算
def calculate_alpha(user, user_item_matrix, threshold=5):
user_interactions = len(user_item_matrix[user])
return user_interactions / (user_interactions + threshold)
# 混合推荐
def hybrid_recommend(user, user_item_matrix, user_similarity, item_similarity, top_n=2):
alpha = calculate_alpha(user, user_item_matrix)
user_cf_scores = defaultdict(float)
item_cf_scores = defaultdict(float)
# UserCF 分数
for other_user, similarity in user_similarity[user].items():
for item, rating in user_item_matrix[other_user].items():
if item not in user_item_matrix[user]:
user_cf_scores[item] += similarity * rating
# ItemCF 分数
for item in user_item_matrix[user]:
for similar_item, similarity in item_similarity[item].items():
if similar_item not in user_item_matrix[user]:
item_cf_scores[similar_item] += similarity * user_item_matrix[user][item]
# 混合分数
hybrid_scores = {item: alpha * user_cf_scores[item] + (1 - alpha) * item_cf_scores[item] for item in set(user_cf_scores.keys()) | set(item_cf_scores.keys())}
# 按分数排序,返回 top_n
return sorted(hybrid_scores.items(), key=lambda x: x[1], reverse=True)[:top_n]
# 计算相似度矩阵
user_similarity = calculate_user_similarity(user_item_matrix)
item_similarity = calculate_item_similarity(user_item_matrix)
# 混合推荐示例
user = 'UserA'
recommendations = hybrid_recommend(user, user_item_matrix, user_similarity, item_similarity, top_n=2)
print(f"为用户 {user} 推荐的商品: {recommendations}")运行结果
为用户 UserA 推荐的商品: [('Item2', 0.71), ('Item4', 0.5)]优化点总结
- 动态权重调整:根据用户的历史交互次数动态调整 UserCF 和 ItemCF 的权重。
- 冷启动处理:新用户或新物品可以通过热门推荐或内容推荐解决。
- 实时更新:定期更新相似度矩阵,以捕捉最新的用户行为。
- 可扩展性:可以引入深度学习模型(如矩阵分解、神经网络)进一步提升推荐效果。
使用场景
- 电商平台:为用户推荐商品,结合用户行为和商品相似性。
- 视频网站:为用户推荐视频,结合用户观看历史和视频内容相似性。
- 社交网络:为用户推荐好友或内容,结合用户社交关系和内容相似性。
实际应用中的思考
在实际应用中,混合推荐算法需要根据具体场景进行优化:
- 对于新用户,可以增加 UserCF 的权重,因为 ItemCF 缺乏足够的数据支持。
- 对于活跃用户,可以增加 ItemCF 的权重,因为用户的历史行为足够丰富。
通过这次学习,我对推荐算法有了更深入的理解,也掌握了混合推荐算法的核心思想和实现方法。未来我会继续深入学习,不断提升自己的算法能力。

















 3351
3351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









