







下面是生成测试数据的代码,我们随机生成具有数字和分类特征的数据集。数值特征取自标准正态分布。分类特征以基数为C的uuid4随机字符串生成,其中2 <= C <= max_cat_size。
def generate_dataset(n_rows, num_count, cat_count, max_nan=0.1, max_cat_size=100):
dataset, types = {}, {}
def generate_categories():
from uuid import uuid4
category_size = np.random.randint(2, max_cat_size)
return [str(uuid4()) for _ in range(category_size)]
for col in range(num_count):
name = f'n{col}'
values = np.random.normal(0, 1, n_rows)
nan_cnt = np.random.randint(1, int(max_nan*n_rows))
index = np.random.choice(n_rows, nan_cnt, replace=False)
values[index] = np.nan
dataset[name] = values
types[name] = 'float32'
for col in range(cat_count):
name = f'c{col}'
cats = generate_categories()
values = np.array(np.random.choice(cats, n_rows, replace=True), dtype=object)
nan_cnt = np.random.randint(1, int(max_nan*n_rows))
index = np.random.choice(n_rows, nan_cnt, replace=False)
values[index] = np.nan
dataset[name] = values
types[name] = 'object'
return pd.DataFrame(dataset), types
现在我们以CSV文件保存和加载的性能作为基准。将五个随机生成的具有百万个观测值的数据集转储到CSV中,然后读回内存以获取平均指标。并且针对具有相同行数的20个随机生成的数据集测试了每种二进制格式。
同时使用两种方法进行对比:
- 1.将生成的分类变量保留为字符串
- 2.在执行任何I/O之前将其转换为pandas.Categorical数据类型
1.以字符串作为分类特征
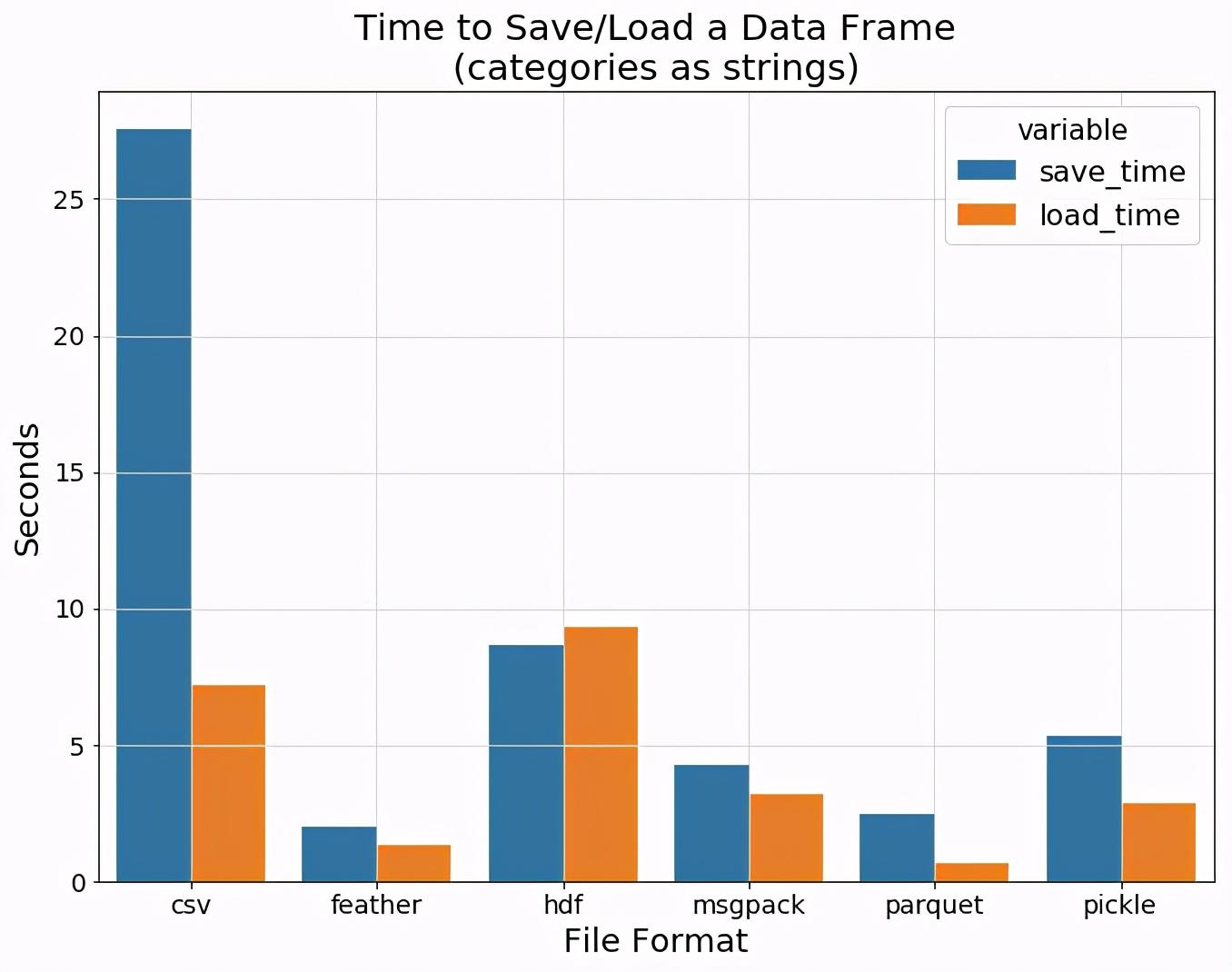
下图显示了每种数据格式的平均I/O时间。这里有趣的发现是hdf的加载速度比csv更低,而其他二进制格式的性能明显更好,而feather和parquet则表现的非常好
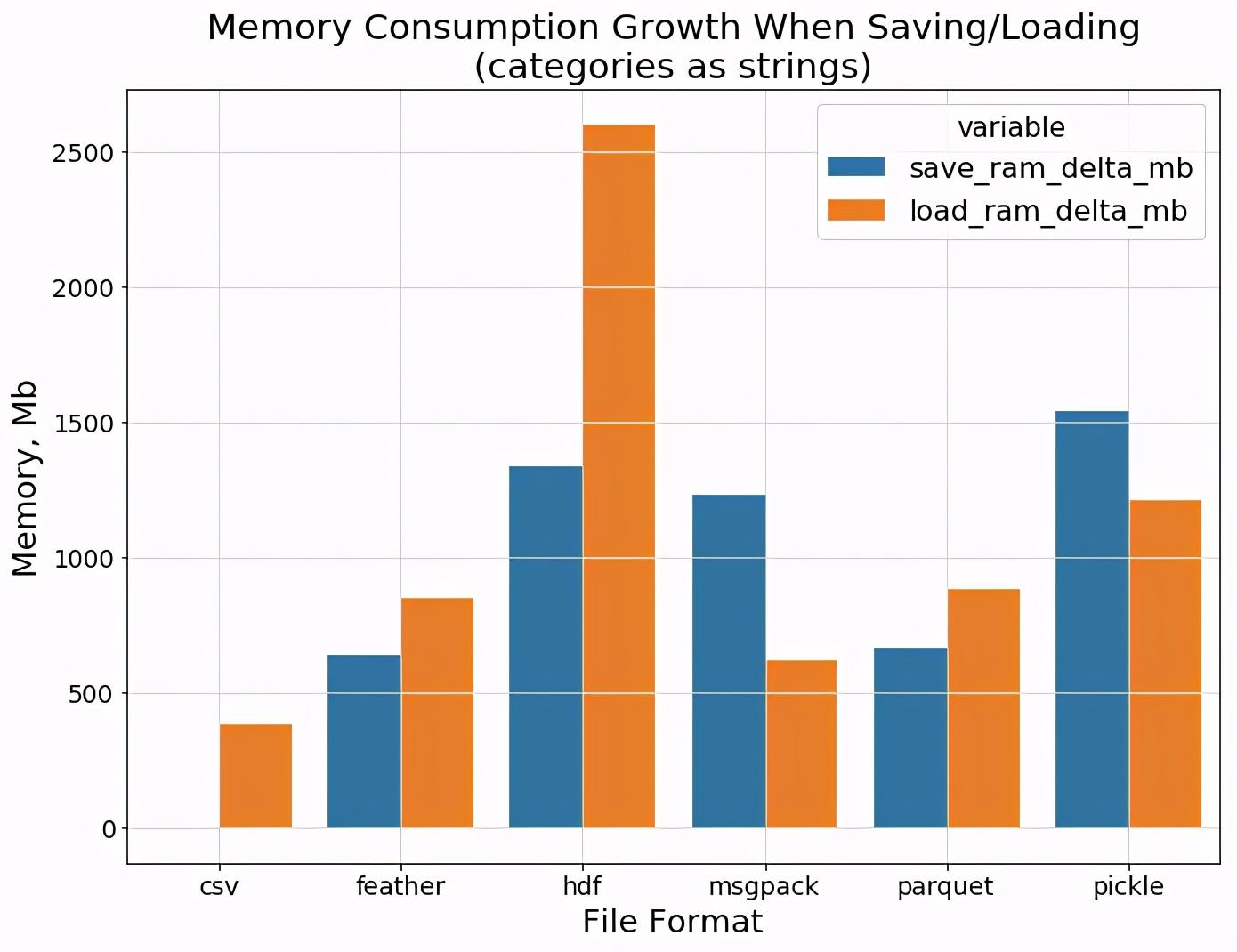
保存数据并从磁盘读取数据时的内存消耗如何?下一张图片向我们展示了hdf的性能再次不那么好。但可以肯定的是,csv不需要太多额外的内存来保存/加载纯文本字符串,而feather和parquet则非常接近
最后,让我们看一下文件大小的对比。这次parquet显示出非常好的结果,考虑到这种格式是为有效存储大量数据而开发的,也是理所当然

2.对特征进行转换
在上一节中,我们没有尝试有效地存储分类特征,而是使用纯字符串,接下来我们使用专用的pandas.Categorical类型再次进行比较。

从上图可以看到,与纯文本csv相比,所有二进制格式都可以显示其真强大功能,效率远超过csv,因此我们将其删除以更清楚地看到各种二进制格式之间的差异。
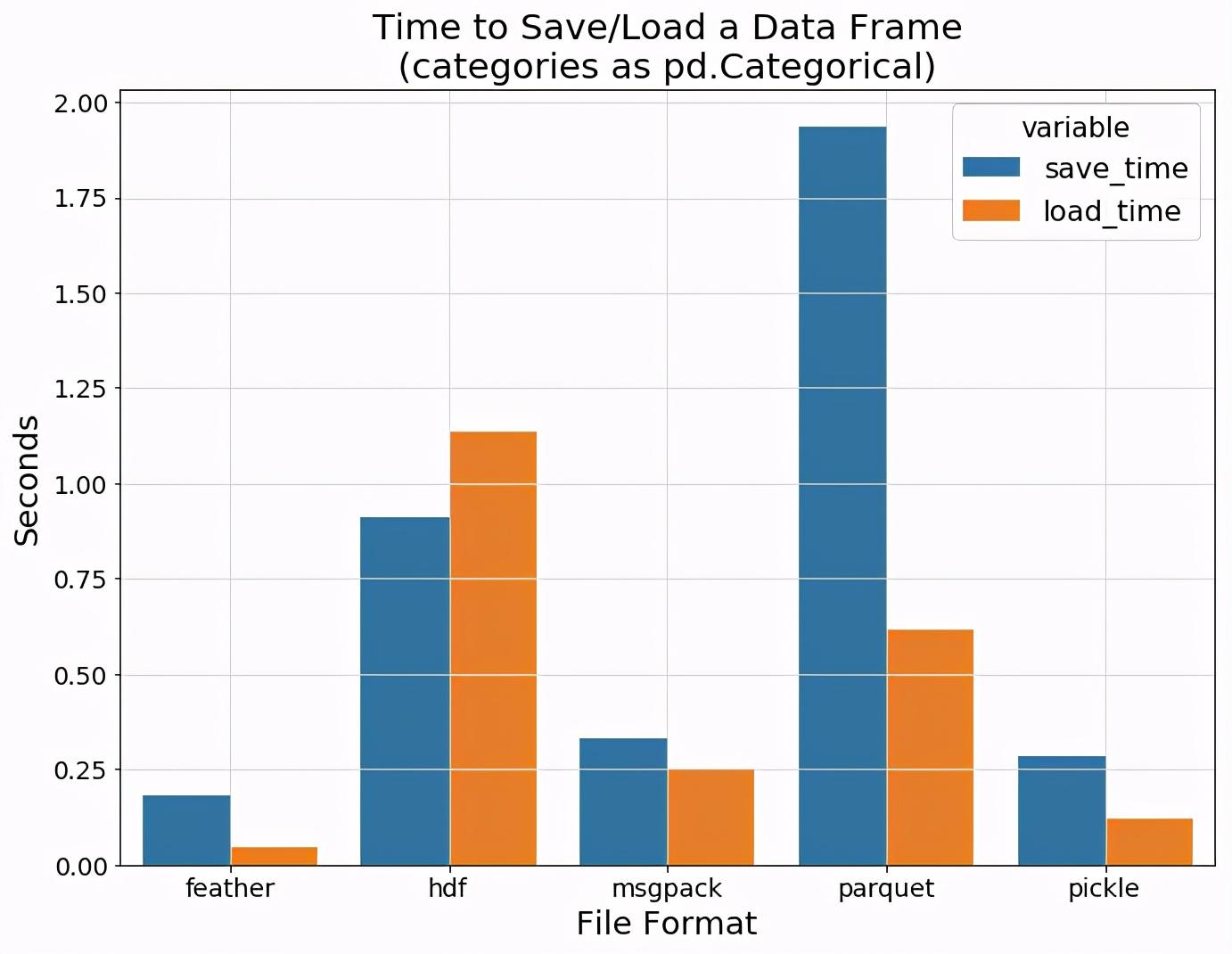
可以看到feather和pickle拥有最快的I/O速度,接下来该比较数据加载过程中的内存消耗了。下面的条形图显示了我们之前提到的有关parquet格式的情况

为什么parquet内存消耗这么高?因为只要在磁盘上占用一点空间,就需要额外的资源才能将数据解压缩回数据帧。即使文件在持久性存储磁盘上需要适度的容量,也可能无法将其加载到内存中。
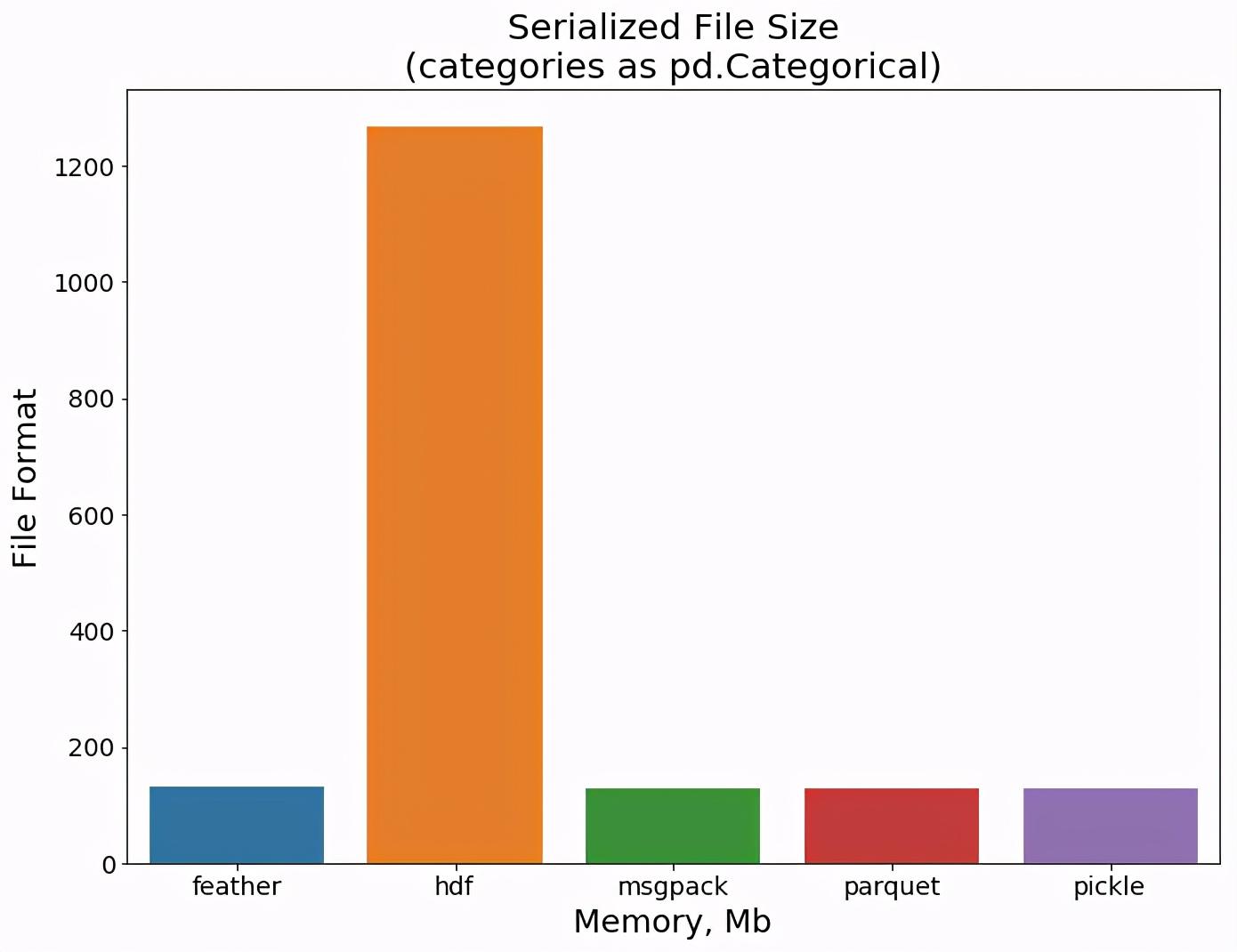
最后我们看下不同格式的文件大小比较。所有格式都显示出良好的效果,除了hdf仍然需要比其他格式更多的空间。
给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1153
1153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









