







给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

2.1 KNN的优缺点
1️⃣K-最近邻算法(KNN)的优点:
简单易懂:KNN算法的原理和实现都非常简单,容易理解和掌握。
非参数化:KNN是一种非参数化算法,不需要对数据分布做任何假设。
对异常值不敏感:KNN能够有效处理包含异常值的数据。
多用途:适用于分类和回归问题。
高维数据处理:可以处理高维特征空间的数据。
非线性问题处理:能够适应非线性的数据分布。
高度可解释性:结果直观,易于解释。
2️⃣KNN算法的缺点:
效率低:在大型数据集上计算距离时效率较低,尤其是在高维数据中。
对噪声敏感:训练数据中的噪声可能影响最近邻的选择,导致预测结果不准确。
K值选择:K值的选择对算法性能有很大影响,需要通过实验来确定最佳值。
距离度量:选择合适的距离度量方法对算法性能至关重要。
特征缩放敏感:需要对特征进行归一化或标准化,否则可能导致某些特征过于主导。
缺失值处理:处理缺失值较为困难,需要采取特定策略来应对。
解释性差:由于是基于实例的预测,相对于其他模型来说解释性较差。
三·实例演示
3.1电影分类
1.导入数据分析三剑客
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.导入KNN算法
# 谷歌的机器学习库
from sklearn.neighbors import KNeighborsClassifier
3.导入warnings模块,并设置警告过滤器为忽略所有警告
import warnings
warnings.filterwarnings(action='ignore')
4.使用电影数据
movies = pd.read_excel('../data/movies.xlsx',sheet_name=1)
movies

# 有标签的:有监督学习
# 训练数据
# x\_train,y\_train
# 测试数据
# x\_test,y\_test
# data : x特征数据
# target :y标签数据
data = movies[['武打镜头','接吻镜头']]
data # 二维
target = movies.分类情况
target # 一维

KNN模型
1.创建模型
# n\_neighbors=5, k值 k = 5
# p = 2 距离算法,p=2表示欧氏距离 ,p = 1 表示曼哈顿距离
#
knn = KNeighborsClassifier(n_neighbors=5,p=2)
2.训练
knn.fit(data,target)
3.预测
# 自己提供测试数据,训练数据和测试数据列得相同,行可以不同
x_test=np.array([[20,1],[0,20],[10,10],[33,2],[2,13]])
x_test = pd.DataFrame(x_test,columns= data.columns)
y_test = np.array(['动作片','爱情片','爱情片','动作片','爱情片'])
y_pred = knn.predict(x_test)
y_pred

4.得分 ,准确率

3.2使用KNN算法预测 鸢(yuan)尾花 的种类

1.导入数据分析三剑客
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.导入KNN算法
# 谷歌的机器学习库
from sklearn.neighbors import KNeighborsClassifier
3.导入warnings模块,并设置警告过滤器为忽略所有警告
import warnings
warnings.filterwarnings(action='ignore')
4.得到鸢尾花数据
from sklearn.datasets import load_iris
# return\_X\_y=True 只返回data和target
# data,target = load\_iris(return\_X\_y=True)
5.使用sklearn库中的load_iris()函数加载鸢尾花数据集,并将数据集分为数据(data)、目标(target)、目标名称(target_names)、特征名称(feature_names)四个部分。
iris = load_iris()
data = iris['data']
target = iris['target']
target_names = iris['target\_names']
feature_names = iris['feature\_names']
df = pd.DataFrame(data,columns=feature_names)
df

6.拆分数据集
把data和target取一部分作为测试数据,剩下的作为训练数据
从sklearn库的model_selection模块中导入train_test_split函数,该函数用于将数据集划分为训练集和测试集。
from sklearn.model_selection import train_test_split
# test\_size
# 整数:测试数据的数量
# 小数:测试数据的占比,一般比较小,0.2,0.3
x_train, x_test, y_train, y_test = train_test_split(data,
target,
test_size=0.2)
x_train.shape, x_test.shape
# y\_test 表示测试数据的真实结果
# y\_pred:表示测试数据的预测结果
7.使用KNN算法
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
knn.score(x_test,y_test)
#0.33
#0.7以上:得分正常
#0.8以上:比较好
#0.9以上:非常好

3.3 预测年收入是否大于50K美元
1.导入数据分析三剑客
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
## 学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
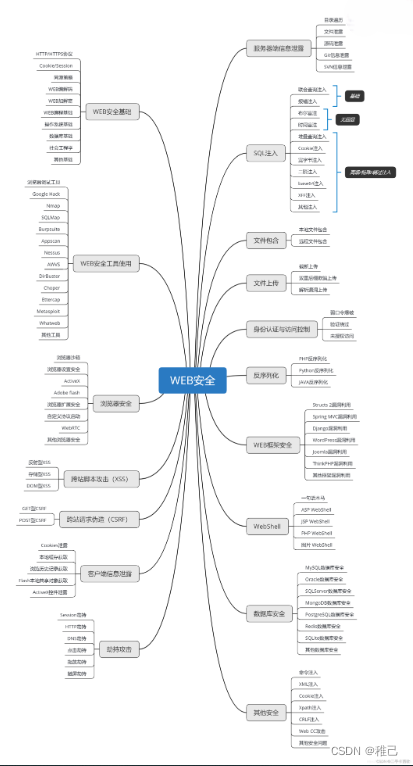
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









