







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Golang全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

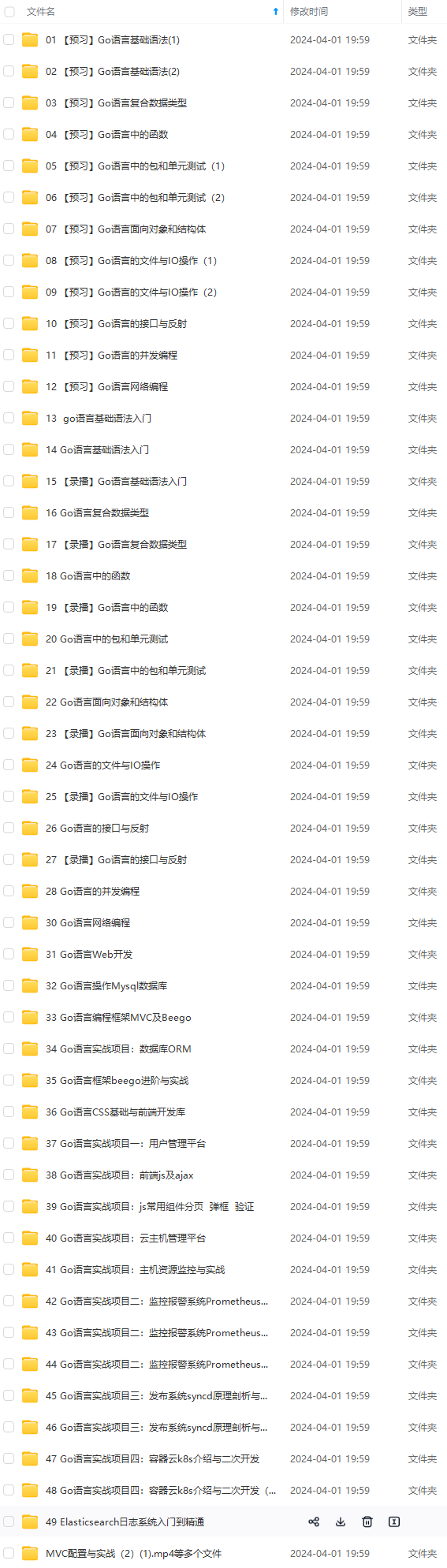
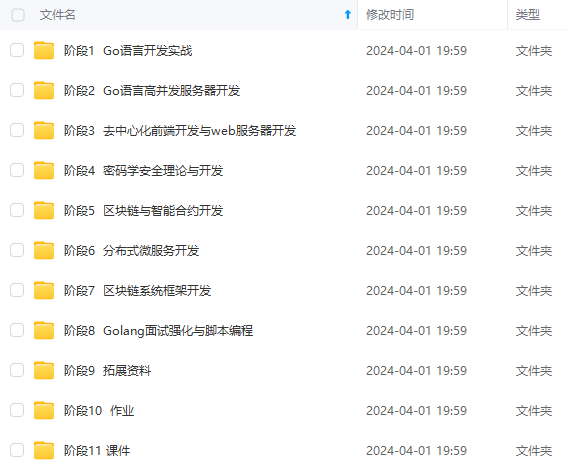
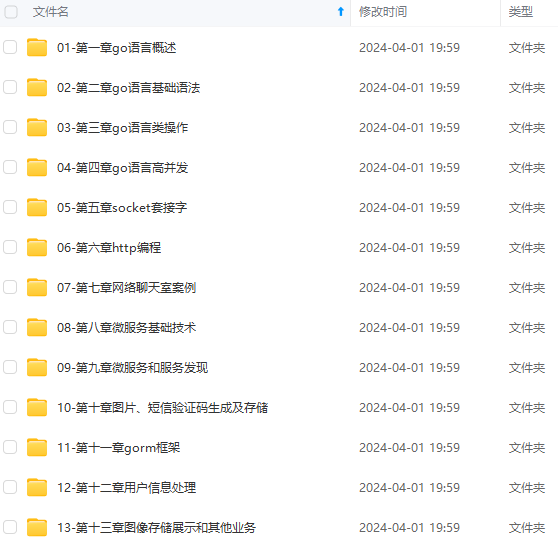
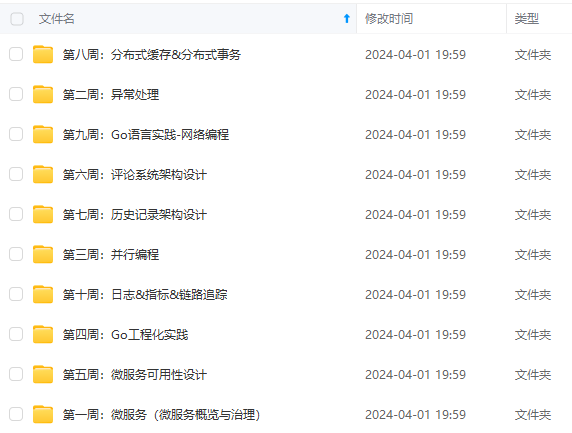
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注go)

正文
//对 [first, last) 区域内的元素做默认的升序排序
void sort (RandomAccessIterator first, RandomAccessIterator last);
//按照指定的 comp 排序规则,对 [first, last) 区域内的元素进行排序
void sort (RandomAccessIterator first, RandomAccessIterator last, Compare comp);
其中,first 和 last 都为随机访问迭代器,它们的组合 [first, last) 用来指定要排序的目标区域;另外在第 2 种格式中,comp 可以是 C++ STL 标准库提供的排序规则(比如 std::greater),也可以是自定义的排序规则。
关于如何自定义一个排序规则,除了《C++ STL关联式容器自定义排序规则》一节介绍的 2 种方式外,还可以直接定义一个具有 2 个参数并返回 bool 类型值的函数作为排序规则。
举个例子:
#include // std::cout
#include // std::sort
#include // std::vector
//以普通函数的方式实现自定义排序规则
bool mycomp(int i, int j) {
return (i < j);
}
//以函数对象的方式实现自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i < j);
}
};
int main() {
std::vector myvector{ 32, 71, 12, 45, 26, 80, 53, 33 };
//调用第一种语法格式,对 32、71、12、45 进行排序
std::sort(myvector.begin(), myvector.begin() + 4); //(12 32 45 71) 26 80 53 33
//调用第二种语法格式,利用STL标准库提供的其它比较规则(比如 greater)进行排序
std::sort(myvector.begin(), myvector.begin() + 4, std::greater()); //(71 45 32 12) 26 80 53 33
//调用第二种语法格式,通过自定义比较规则进行排序
std::sort(myvector.begin(), myvector.end(), mycomp2());//12 26 32 33 45 53 71 80
//输出 myvector 容器中的元素
for (std::vector::iterator it = myvector.begin(); it != myvector.end(); ++it) {
std::cout << *it << ’ ';
}
return 0;
}
程序执行结果为:
12 26 32 33 45 53 71 80
可以看到,程序中分别以函数和函数对象的方式自定义了具有相同功能的 mycomp 和 mycomp2 升序排序规则。需要注意的是,和为关联式容器设定排序规则不同,给 sort() 函数指定排序规则时,需要为其传入一个函数名(例如 mycomp )或者函数对象(例如 std::greater() 或者 mycomp2())。
那么,sort() 函数的效率怎么样吗?该函数实现排序的平均时间复杂度为N*log2N(其中 N 为指定区域 [first, last) 中 last 和 first 的距离)。
C++ stable_sort()用法详解
通过阅读《C++ sort()排序函数》一节,读者已经了解了 sort() 函数的功能和用法。值得一提的是,当指定范围内包含多个相等的元素时,sort() 排序函数无法保证不改变它们的相对位置。那么,如果既要完成排序又要保证相等元素的相对位置,该怎么办呢?可以使用 stable_sort() 函数。
有些场景是需要保证相等元素的相对位置的。例如对于一个保存某种事务(比如银行账户)的容器,在处理这些事务之前,为了能够有序更新这些账户,需要按照账号对它们进行排序。而这时就很有可能出现相等的账号(即同一账号在某段时间做多次的存取钱操作),它们的相对顺序意味着添加到容器的时间顺序,此顺序不能修改,否则很可能出现账户透支的情况。
值得一提的是,stable_sort() 函数完全可以看作是 sort() 函数在功能方面的升级版。换句话说,stable_sort() 和 sort() 具有相同的使用场景,就连语法格式也是相同的(后续会讲),只不过前者在功能上除了可以实现排序,还可以保证不改变相等元素的相对位置。
注意,关于 stable_sort() 函数的使用场景,《C++ sort() 排序函数》一节已经做了详细的介绍,这里不再赘述。另外,stable_sort() 函数是基于归并排序实现的,关于此排序算法的具体实现过程,感兴趣的读者可阅读《归并排序算法》一文。
和 sort() 函数一样,实现 stable_sort() 的函数模板也位于<algorithm>头文件中,因此在使用该函数前,程序也应包含如下语句:
#include
并且,table_sort() 函数的用法也有 2 种,其语法格式和 sort() 函数完全相同(仅函数名不同):
//对 [first, last) 区域内的元素做默认的升序排序
void stable_sort ( RandomAccessIterator first, RandomAccessIterator last );
//按照指定的 comp 排序规则,对 [first, last) 区域内的元素进行排序
void stable_sort ( RandomAccessIterator first, RandomAccessIterator last, Compare comp );
其中,first 和 last 都为随机访问迭代器,它们的组合 [first, last) 用来指定要排序的目标区域;另外在第 2 种格式中,comp 可以是 C++ STL 标准库提供的排序规则(比如 std::greater),也可以是自定义的排序规则。
举个例子:
#include // std::cout
#include // std::stable_sort
#include // std::vector
//以普通函数的方式实现自定义排序规则
bool mycomp(int i, int j) {
return (i < j);
}
//以函数对象的方式实现自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i < j);
}
};
int main() {
std::vector myvector{ 32, 71, 12, 45, 26, 80, 53, 33 };
//调用第一种语法格式,对 32、71、12、45 进行排序
std::stable_sort(myvector.begin(), myvector.begin() + 4); //(12 32 45 71) 26 80 53 33
//调用第二种语法格式,利用STL标准库提供的其它比较规则(比如 greater)进行排序
std::stable_sort(myvector.begin(), myvector.begin() + 4, std::greater()); //(71 45 32 12) 26 80 53 33
//调用第二种语法格式,通过自定义比较规则进行排序,这里也可以换成 mycomp2()
std::stable_sort(myvector.begin(), myvector.end(), mycomp);//12 26 32 33 45 53 71 80
//输出 myvector 容器中的元素
for (std::vector::iterator it = myvector.begin(); it != myvector.end(); ++it) {
std::cout << *it << ’ ';
}
return 0;
}
程序执行结果为:
12 26 32 33 45 53 71 80
那么,stable_sort() 函数的效率怎么样呢?当可用空间足够的情况下,该函数的时间复杂度可达到O(N*log2(N));反之,时间复杂度为O(N*log2(N)2),其中 N 为指定区域 [first, last) 中 last 和 first 的距离。
C++ partial_sort()函数详解
假设这样一种情境,有一个存有 100 万个元素的容器,但我们只想从中提取出值最小的 10 个元素,该如何实现呢?
通过前面的学习,读者可能会想到使用 sort() 或者 stable_sort() 排序函数,即通过对容器中存储的 100 万个元素进行排序,就可以成功筛选出最小的 10 个元素。但仅仅为了提取 10 个元素,却要先对 100 万个元素进行排序,可想而知这种实现方式的效率是非常低的。
对于解决类似的问题,C++ STL 标准库提供了更高效的解决方案,即使用 partial_sort() 或者 partial_sort_copy() 函数,本节就对这 2 个排序函数的功能和用法做详细的讲解。
首先需要说明的是,partial_sort() 和 partial_sort_copy() 函数都位于 头文件中,因此在使用这 2 个函数之前,程序中应引入此头文件:
#include
C++ partial_sort()排序函数
要知道,一个函数的功能往往可以从它的函数名中体现出来,以 partial_sort() 函数为例,partial sort 可直译为“部分排序”。partial_sort() 函数的功能确是如此,即该函数可以从指定区域中提取出部分数据,并对它们进行排序。
但“部分排序”仅仅是对 partial_sort() 函数功能的一个概括,如果想彻底搞清楚它的功能,需要结合该函数的语法格式。partial_sort() 函数有 2 种用法,其语法格式分别为:
//按照默认的升序排序规则,对 [first, last) 范围的数据进行筛选并排序
void partial_sort (RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last);
//按照 comp 排序规则,对 [first, last) 范围的数据进行筛选并排序
void partial_sort (RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last,
Compare comp);
其中,first、middle 和 last 都是随机访问迭代器,comp 参数用于自定义排序规则。
partial_sort() 函数会以交换元素存储位置的方式实现部分排序的。具体来说,partial_sort() 会将 [first, last) 范围内最小(或最大)的 middle-first 个元素移动到 [first, middle) 区域中,并对这部分元素做升序(或降序)排序。
需要注意的是,partial_sort() 函数受到底层实现方式的限制,它仅适用于普通数组和部分类型的容器。换句话说,只有普通数组和具备以下条件的容器,才能使用 partial_sort() 函数:
- 容器支持的迭代器类型必须为随机访问迭代器。这意味着,partial_sort() 函数只适用于 array、vector、deque 这 3 个容器。
- 当选用默认的升序排序规则时,容器中存储的元素类型必须支持 <小于运算符;同样,如果选用标准库提供的其它排序规则,元素类型也必须支持该规则底层实现所用的比较运算符;
- partial_sort() 函数在实现过程中,需要交换某些元素的存储位置。因此,如果容器中存储的是自定义的类对象,则该类的内部必须提供移动构造函数和移动赋值运算符。
举个例子:
#include // std::cout
#include // std::partial_sort
#include // std::vector
using namespace std;
//以普通函数的方式自定义排序规则
bool mycomp1(int i, int j) {
return (i > j);
}
//以函数对象的方式自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i > j);
}
};
int main() {
std::vector myvector{ 3,2,5,4,1,6,9,7};
//以默认的升序排序作为排序规则,将 myvector 中最小的 4 个元素移动到开头位置并排好序
std::partial_sort(myvector.begin(), myvector.begin() + 4, myvector.end());
cout << “第一次排序:\n”;
for (std::vector::iterator it = myvector.begin(); it != myvector.end(); ++it)
std::cout << *it << ’ ';
cout << “\n第二次排序:\n”;
// 以指定的 mycomp2 作为排序规则,将 myvector 中最大的 4 个元素移动到开头位置并排好序
std::partial_sort(myvector.begin(), myvector.begin() + 4, myvector.end(), mycomp2());
for (std::vector::iterator it = myvector.begin(); it != myvector.end(); ++it)
std::cout << *it << ’ ';
return 0;
}
程序执行结果为:
第一次排序:
1 2 3 4 5 6 9 7
第二次排序:
9 7 6 5 1 2 3 4
值得一提的是,partial_sort() 函数实现排序的平均时间复杂度为N*log(M),其中 N 指的是 [first, last) 范围的长度,M 指的是 [first, middle) 范围的长度。
C++ partial_sort_copy()排序函数
partial_sort_copy() 函数的功能和 partial_sort() 类似,唯一的区别在于,前者不会对原有数据做任何变动,而是先将选定的部分元素拷贝到另外指定的数组或容器中,然后再对这部分元素进行排序。
partial_sort_copy() 函数也有 2 种语法格式,分别为:
//默认以升序规则进行部分排序
RandomAccessIterator partial_sort_copy (
InputIterator first,
InputIterator last,
RandomAccessIterator result_first,
RandomAccessIterator result_last);
//以 comp 规则进行部分排序
RandomAccessIterator partial_sort_copy (
InputIterator first,
InputIterator last,
RandomAccessIterator result_first,
RandomAccessIterator result_last,
Compare comp);
其中,first 和 last 为输入迭代器;result_first 和 result_last 为随机访问迭代器;comp 用于自定义排序规则。
partial_sort_copy() 函数会将 [first, last) 范围内最小(或最大)的 result_last-result_first 个元素复制到 [result_first, result_last) 区域中,并对该区域的元素做升序(或降序)排序。
值得一提的是,[first, last] 中的这 2 个迭代器类型仅限定为输入迭代器,这意味着相比 partial_sort() 函数,partial_sort_copy() 函数放宽了对存储原有数据的容器类型的限制。换句话说,partial_sort_copy() 函数还支持对 list 容器或者 forward_list 容器中存储的元素进行“部分排序”,而 partial_sort() 函数不行。
但是,介于 result_first 和 result_last 仍为随机访问迭代器,因此 [result_first, result_last) 指定的区域仍仅限于普通数组和部分类型的容器,这和 partial_sort() 函数对容器的要求是一样的。
举个例子:
#include // std::cout
#include // std::partial_sort_copy
#include // std::list
using namespace std;
bool mycomp1(int i, int j) {
return (i > j);
}
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i > j);
}
};
int main() {
int myints[5] = { 0 };
std::list mylist{ 3,2,5,4,1,6,9,7 };
//按照默认的排序规则进行部分排序
std::partial_sort_copy(mylist.begin(), mylist.end(), myints, myints + 5);
cout << “第一次排序:\n”;
for (int i = 0; i < 5; i++) {
cout << myints[i] << " ";
}
//以自定义的 mycomp2 作为排序规则,进行部分排序
std::partial_sort_copy(mylist.begin(), mylist.end(), myints, myints + 5, mycomp2());
cout << “\n第二次排序:\n”;
for (int i = 0; i < 5; i++) {
cout << myints[i] << " ";
}
return 0;
}
程序执行结果为:
第一次排序:
1 2 3 4 5
第二次排序:
9 7 6 5 4
可以看到,程序中调用了 2 次 partial_sort_copy() 函数,其作用分别是:
- 第 20 行:采用默认的升序排序规则,在 mylist 容器中筛选出最小的 5 个元素,然后将它们复制到 myints[5] 数组中,并对这部分元素进行升序排序;
- 第 27 行:采用自定义的 mycomp2 降序排序规则,从 mylist 容器筛选出最大的 5 个元素,同样将它们复制到 myints[5] 数组中,并对这部分元素进行降序排序;
值得一提的是,partial_sort_copy() 函数实现排序的平均时间复杂度为N*log(min(N,M)),其中 N 指的是 [first, last) 范围的长度,M 指的是 [result_first, result_last) 范围的长度。
C++ STL标准库这么多排序函数,该如何选择?
通过前面的学习我们知道,C++ STL 标准库共提供了 4 种排序函数,这里先带大家回顾一下,如表 1 所示。
| 排序函数 | 功能 |
|---|---|
| sort() | 对指定范围内所有的数据进行排序,排序后各个元素的相对位置很可能发生改变。 |
| stable_sort() | 对指定范围内所有的数据进行排序,并确保排序后各个元素的相对位置不发生改变。 |
| partial_sort() | 对指定范围内最大或最小的 n 个元素进行排序。 |
| nth_element() | 调整指定范围内元素的存储位置,实现位于位置 n 的元素正好是全排序情况下的第 n 个元素,并且按照全排序规则排在位置 n 之前的元素都在该位置之前,按照全排序规则排在位置 n 之后的元素都在该位置之后。 |
关于以上 4 种排序函数各自的用法,读者可阅读之前的文章,这里不再过多赘述。
值得一提的是,以上 4 种排序函数在使用时,都要求传入随机访问迭代器,因此这些函数都只适用于 array、vector、deque 以及普通数组。
当操作对象为 list 或者 forward_list 序列式容器时,其容器模板类中都提供有 sort() 排序方法,借助此方法即可实现对容器内部元素进行排序。其次,对关联式容器(包括哈希容器)进行排序是没有实际意义的,因为这类容器会根据既定的比较函数(和哈希函数)维护内部元素的存储位置。
那么,当需要对普通数组或者 array、vector 或者 deque 容器中的元素进行排序时,怎样选择最合适(效率最高)的排序函数呢?这里为大家总结了以下几点:
- 如果需要对所有元素进行排序,则选择 sort() 或者 stable_sort() 函数;
- 如果需要保持排序后各元素的相对位置不发生改变,就只能选择 stable_sort() 函数,而另外 3 个排序函数都无法保证这一点;
- 如果需要对最大(或最小)的 n 个元素进行排序,则优先选择 partial_sort() 函数;
- 如果只需要找到最大或最小的 n 个元素,但不要求对这 n 个元素进行排序,则优先选择 nth_element() 函数。
除此之外,很多读者都关心这些排序函数的性能。总的来说,函数功能越复杂,做的工作越多,它的性能就越低(主要体现在时间复杂度上)。对于以上 4 种排序函数,综合考虑它们的时间和空间效率,其性能之间的比较如下所示:
nth_element() > partial_sort() > sort() > stable_sort() <–从左到右,性能由高到低
建议大家,在实际选择排序函数时,应更多从所需要完成的功能这一角度去考虑,而不是一味地追求函数的性能。换句话说,如果你选择的算法更有利于实现所需要的功能,不仅会使整个代码的逻辑更加清晰,还会达到事半功倍的效果。
自定义STL算法规则,应优先使用函数对象!
作为一门面向对象的编程语言,使用 C++ 编写程序有一个缺点,即随着代码面向对象程度的提高,其执行效率反而会降低。例如,经实验证明几乎在所有情况下,直接操作一个 double 类型变量的执行效率,要比操作一个含 double 类型成员属性的类对象更高。
对于大多数读者来说,以上所说是很容易想通的,因为它符合我们对高级编程语言的认知。但本节要介绍的内容,一定程序上会打破这个认知。
前面章节中,我们学习了 STL 标准库中所有的排序算法,比如 sort()、stable_sort() 以及 nth_element() 等。不知读者有没有发现,这些排序算法都单独提供了带有 comp 参数的语法格式,借助此参数,我们可以自定义排序规则。
以 sort() 排序函数为例,其语法格式有以下 2 种:
//无 comp 参数
void sort (RandomAccessIterator first, RandomAccessIterator last);
//有 comp 参数
void sort (RandomAccessIterator first, RandomAccessIterator last, Compare comp);
显然仅从使用语法上看,它们唯一的区别在于,第 2 种多了一个 comp 参数。
事实上,对于 STL 标准库中的每个算法,只要用户需要自定义规则,该算法都会提供有带 comp 参数的语法格式。
本质上讲,comp 参数用于接收用户自定义的函数,其定义的方式有 2 种,既可以是普通函数,也可以是函数对象。例如:
#include // std::cout
#include // std::sort
#include // std::vector
//以普通函数的方式实现自定义排序规则
inline bool mycomp(int i, int j) {
return (i < j);
}
//以函数对象的方式实现自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i < j);
}
};
int main() {
std::vector myvector{ 32, 71, 12, 45, 26, 80, 53, 33 };
//调用普通函数定义的排序规则
std::sort(myvector.begin(), myvector.end(), mycomp);
//调用函数对象定义的排序规则
//std::sort(myvector.begin(), myvector.end(), mycomp2());
for (std::vector::iterator it = myvector.begin(); it != myvector.end(); ++it) {
std::cout << *it << ’ ';
}
return 0;
}
程序执行结果为:
12 26 32 33 45 53 71 80
注意,为了提高执行效率,其函数都定义为内联函数(在类内部定义的函数本身就是内联函数)。至于为什么内联函数比普通函数的执行效率高,可阅读《C++ inline内联函数》一文。
要知道,函数对象可以理解为伪装成函数的对象,根据以往的认知,函数对象的执行效率应该不如普通函数。但事实恰恰相反,即便如上面程序那样,将普通函数定义为更高效的内联函数,其执行效率也无法和函数对象相比。
通过在 4 个不同的 STL 平台上,对包含 100 万个 double 类型数据的 vector 容器进行排序,最差情况下使用函数对象的执行效率要比普通内联函数高 50%,最好情况下则高 160%。
那么,是什么原因导致了它们执行效率上的差异呢?以 mycomp2() 函数对象为例,其 mycomp2::operator() 也是一个内联函数,编译器在对 sort() 函数进行实例化时会将该函数直接展开,这也就意味着,展开后的 sort() 函数内部不包含任何函数调用。
而如果使用 mycomp 作为参数来调用 sort() 函数,情形则大不相同。要知道,C++ 并不能真正地将一个函数作为参数传递给另一个函数,换句话说,如果我们试图将一个函数作为参数进行传递,编译器会隐式地将它转换成一个指向该函数的指针,并将该指针传递过去。
也就是说,上面程序中的如下代码:
std::sort(myvector.begin(), myvector.end(), mycomp);
并不是真正地将 mycomp 传递给 sort() 函数,它传递的仅是一个指向 mycomp() 函数的指针。当 sort() 函数被实例化时,编译器生成的函数声明如下所示:
std::sort(vector::iterator first,
vector::iterator last,
bool (*comp)(int, int));
可以看到,参数 comp 只是一个指向函数的指针,所以 sort() 函数内部每次调用 comp 时,编译器都会通过指针产生一个间接的函数调用。
也正是基于这个原因,C++ sort() 函数要比 C 语言 qsort() 函数的执行效率更高。读者可能会问,程序中 comp() 函数也是内联函数,为什么 C++ 不像函数对象那样去处理呢?具体原因我们无从得知,事实上也没必要关心,也许是编译器开发者觉得这种优化不值得去做。
除了效率上的优势之外,相比普通函数,以函数对象的方式自定义规则还有很多隐藏的优势。例如在某些特殊情况下,以普通函数的形式编写的代码看似非常合理,但就是无法通过编译,这也许是由于 STL 标准库的原因,也许是编译器缺陷所至,甚至两者都有可能。而使用函数对象的方式,则可以有效避开这些“坑”,而且还大大提升的代码的执行效率。
总之,以函数对象的方式为 STL 算法自定义规则,具有效率在内的诸多优势。当调用带有 comp 参数的 STL 算法时,除非调用 STL 标准库自带的比较函数,否则应优先以函数对象的方式自定义规则。
C++ merge()和inplace_merge()函数用法(详解版)
有些场景中,我们需要将 2 个有序序列合并为 1 个有序序列,这时就可以借助 merge() 或者 inplace_merge() 函数实现。
值得一提的是,merge() 和 inplace_merge() 函数都定义在<algorithm>头文件中,因此在使用它们之前,程序中必须提前引入该头文件:
#include
C++ merge()函数
merge() 函数用于将 2 个有序序列合并为 1 个有序序列,前提是这 2 个有序序列的排序规则相同(要么都是升序,要么都是降序)。并且最终借助该函数获得的新有序序列,其排序规则也和这 2 个有序序列相同。
举个例子,假设有 2 个序列,分别为5,10,15,20,25和7,14,21,28,35,42,显然它们不仅有序,而且都是升序序列。因此借助 merge() 函数,我们就可以轻松获得如下这个有序序列:
5 7 10 15 17 20 25 27 37 47 57
可以看到,该序列不仅包含以上 2 个序列中所有的元素,并且其本身也是一个升序序列。
值得一提的是,C++ STL 标准库的开发人员考虑到用户可能需要自定义排序规则,因此为 merge() 函数设计了以下 2 种语法格式:
//以默认的升序排序作为排序规则
OutputIterator merge (InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result);
//以自定义的 comp 规则作为排序规则
OutputIterator merge (InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result, Compare comp);
可以看到,first1、last1、first2 以及 last2 都为输入迭代器,[first1, last1) 和 [first2, last2) 各用来指定一个有序序列;result 为输出迭代器,用于为最终生成的新有序序列指定存储位置;comp 用于自定义排序规则。同时,该函数会返回一个输出迭代器,其指向的是新有序序列中最后一个元素之后的位置。
注意,当采用第一种语法格式时,[first1, last1) 和 [first2, last2) 指定区域内的元素必须支持 < 小于运算符;同样当采用第二种语法格式时,[first1, last1) 和 [first2, last2) 指定区域内的元素必须支持 comp 排序规则内的比较运算符。
举个例子:
#include // std::cout
#include // std::merge
#include // std::vector
using namespace std;
int main() {
//first 和 second 数组中各存有 1 个有序序列
int first[] = { 5,10,15,20,25 };
int second[] = { 7,17,27,37,47,57 };
//用于存储新的有序序列
vector myvector(11);
//将 [first,first+5) 和 [second,second+6) 合并为 1 个有序序列,并存储到 myvector 容器中。
merge(first, first + 5, second, second + 6, myvector.begin());
//输出 myvector 容器中存储的元素
for (vector::iterator it = myvector.begin(); it != myvector.end(); ++it) {
cout << *it << ’ ';
}
return 0;
}
程序执行结果为:
5 7 10 15 17 20 25 27 37 47 57
可以看到,first 数组和 second 数组中各存有 1 个升序序列,通过借助 merge() 函数,我们成功地将它们合并成了一个有序序列,并存储到 myvector 容器中。
注意,merge() 函数底层是通过拷贝的方式实现合并操作的。换句话说,上面程序在采用 merge() 函数实现合并操作的同时,并不会对 first 和 second 数组有任何影响。有关该函数的具体实现过程,可查看 C++ STL merge() 官网。
实际上,对于 2 个有序序列是各自存储(像 first 和 second 这样)还是存储到一起,merge() 函数并不关心,只需要给它传入恰当的迭代器(或指针),该函数就可以正常工作。因此,我们还可以将上面程序改写为:
//该数组中存储有 2 个有序序列
int first[] = { 5,10,15,20,25,7,17,27,37,47,57 };
//用于存储新的有序序列
vector myvector(11);
//将 [first,first+5) 和 [first+5,first+11) 合并为 1 个有序序列,并存储到 myvector 容器中。
merge(first, first + 5, first + 5, first +11 , myvector.begin());
可以看到,2 个有序序列全部存储到了 first 数组中,但只要给 merge() 函数传入正确的指针,仍可以将它们合并为 1 个有序序列。
感兴趣的读者,可自行验证这段程序,其最终会得到和上面程序相同的 myvector 容器。
C++ inplace_merge()函数
事实上,当 2 个有序序列存储在同一个数组或容器中时,如果想将它们合并为 1 个有序序列,除了使用 merge() 函数,更推荐使用 inplace_merge() 函数。
和 merge() 函数相比,inplace_merge() 函数的语法格式要简单很多:
//默认采用升序的排序规则
void inplace_merge (BidirectionalIterator first, BidirectionalIterator middle,
BidirectionalIterator last);
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
begin());
可以看到,2 个有序序列全部存储到了 first 数组中,但只要给 merge() 函数传入正确的指针,仍可以将它们合并为 1 个有序序列。
感兴趣的读者,可自行验证这段程序,其最终会得到和上面程序相同的 myvector 容器。
C++ inplace_merge()函数
事实上,当 2 个有序序列存储在同一个数组或容器中时,如果想将它们合并为 1 个有序序列,除了使用 merge() 函数,更推荐使用 inplace_merge() 函数。
和 merge() 函数相比,inplace_merge() 函数的语法格式要简单很多:
//默认采用升序的排序规则
void inplace_merge (BidirectionalIterator first, BidirectionalIterator middle,
BidirectionalIterator last);
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)
[外链图片转存中…(img-Fkk40Q1d-1713433661238)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 4023
4023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









