







排序算法 sort
默认将数组进行从小到大排序
Sort(数组名+n1,数组名+n2) 将数组下标为[n1,n2)的元素进行排序,注意左闭右开
Sort(数组名+n1,数组名+n2,greater< T >()); 将数据类型为基本数据类型为T的数组从大到小进行排序
Sort(数组名+n1,数组名+n2,排序规则结构名()); 用自定义的排序规则,对任何类型T的数组排序
有些时候不需要写成结构形式,直接写一个函数就行
排序规则结构:
Struct 结构名
{
bool operator() (const T&a1,const T&a2) const{
若a1应该在a2前面,则返回true。否则返回false;
};
}
struct Stu
{
string name;
int grades;
};
//自定义排序规则,以分数从小到大对学生进行排序
struct Rule{
bool operator()(const Stu & a1,const Stu &a2)const
{
if(a1.grades<a2.grades) return true;
}
};
//也可以直接写函数
/*
bool Rule(const Stu & a1,const Stu &a2)
{
if(a1.grades<a2.grades) return true;
}
调用方式:sort(stu,stu+4,Rule);Rule后面不加括号了
*/
int main()
{
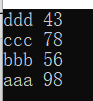
Stu stu[4]={{"aaa",98},{"bbb",56},{"ccc",78},{"ddd",43}};
sort(stu,stu+4,Rule());
for(int i=0;i<4;i++)
{
cout<<stu[i].name<<" ";
cout<<stu[i].grades<<endl;
}
运行结果:
将整个数组进行排序: sort(数组名,数组名+sizeof(数组名)/sizeof(T));
对容器进行排序: sort(a.begin(),a.end());
二分查找算法
二分查找算法binary_search
(1)在从小到大排好序的基本类型数组上进行二分查找
binary_search(数组名+n1,数组名+n2,值) —n可以为变量,查找下标为[n1,n2)的元素
返回值为true(找到)或false(没找到)
“等于”的含义:a<b和a>b都不成立--------对于基本数据类型来说就是等于
int array[10]={3,6,8,2,9,34,76,16,98,25};
cout<<binary_search(array,array+10,3);
//输出:1(true)存在
(2)用自定义排序规则排好序的、元素为任意的T类型的数组中进行二分查找
binary_search(数组名+n1,数组名+n2,值,排序规则结构名());
查找时的排序规则必须和排序时的规则一致
“等于”的含义:a必须在b前面和b必须在a前面都不成立
struct Rule
{
bool operator()(const int &a1,const int &a2)const
{
return a1%10<a2%10; //以个位数从小到大进行排序
}
};
int main()
{
int array[5]={23,65,74,87,89};
sort(array,array+5,Rule());
cout<<65<<" :"<<binary_search(array,array+5,65,Rule())<<endl;
cout<<7<<" :"<<binary_search(array,array+5,7,Rule())<<endl; //排序sort的相等不是==而是a与b谁在前谁在后无所谓,与排序规则有关
//在用二分查找算法之前必须保证数组已经排好序了
//查找时的排序算法必须与数组实际排序算法一致,如果此时的数组排序规则与二分查找指定的不一样,查找就
//没有意义,甚至会出现不能成功查找到的情况,不指定规则对基本数据类型来说就是从小到大的规则
cout<<74<<" :"<<binary_search(array,array+5,74)<<endl; //输出不存在,array此时的排序为自定义类型
return 0;
}
二分查找下界lower_bound
(1)在对元素类型为T的从小到大排好序的基本类型的数组中进行查找
T * lower_bound(数组名+n1,数组名+n2,值);
返回一个指针T *p;
*p是查找区间里下标最小的,大于等于“值”的元素。如果找不到,p指向下标为n2的元素,即数组最后一个元素,如果找到即指向被找到的元素
(2)自定义排序规则
T* lower_bound(数组名+n1,数组名+n2,值,排序规则结构名()); 与基本数据类型的相似用法,注意事项与binary_search相同 查找可用排在值后面的元素
二分查找上界upper_bound
(1)T * upper_bound(数组名+n1,数组名+n2,值);
返回一个指针T *p; *p是查找区间里下标最小的,大于“值”的元素。
(2) T* upper_bound(数组名+n1,数组名+n2,值,Rule()); 查找必须排在值后面的元素
用法几乎和lower_bound相似,只有一点不同:lower_bound取到了相等,upper_bound没有取到,一个连续重复多次的数所在的区间下界是能取到的,上界是取不到的,即重复多次的数所在的区间为[lower_bound,upper_bound)














 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









