







在本文中,你将学到:
0 复习数据预处理及可视化
1 了解分类的基本概念
2 使用多种分类器来对比模型精度
3 掌握使用分类器列表的方式来批处理不同模型
4 将机器学习分类模型部署为Web应用
提出问题
本文我们所用的数据集是亚洲美食数据集,其包括了亚洲5个国家的美食食谱与所属的国家。我们构建模型的目的是解决:
如何根据美食所用食材判断其所属国家
即以美食食材为可训练特征,所属国家为预测标签构建机器学习分类模型。
一、介绍
1.分类简介
分类是经典机器学习的基本重点,也是监督学习的一种形式,与回归技术有很多共同之处。其通常分为两类:二元分类和多元分类。本文中,我将使用亚洲美食数据集贯穿本次学习。
还记得我在之前文章中提到的:
0 线性回归可帮助我们预测变量之间的关系,并准确预测新数据点相对于该线的位置。因此,例如,预测南瓜在9月与12月的价格。
1 Logistic回归帮助我们发现“二元类别”:在这个价格点上,这是橙子还是非橙子?
分类也是机器学习人员和数据科学家的基本工作之一。从二分类(判断邮件是否是垃圾邮件),到使用计算机视觉的复杂分类和分割,其在很多领域都有着很大的作用。
以更科学的方式陈述该过程:
我们所使用的分类方法创建了一个预测模型,这个模型使我们能够将输入变量之间的关系映射到输出变量。
分类使用各种算法来确定数据点的标签或类别。我们以亚洲美食数据集为例,看看通过输入一组特征样本,我们是否可以确定其菜肴所属的国家。
以下是经典机器学习常用的分类方法。
0 逻辑回归
1 决策树分类(ID3、C4.5、CART)
2 基于规则分类
3 K-近邻算法(K-NN)
4 贝叶斯分类
5 支持向量机(SVM)
6 随机森林(Random Forest)
2.imblearn的安装
在开始本文学习之前,我们第一个任务是清理和调整数据集以获得更好的分析结果。我们需要安装的是imblearn库。这是一个基于Python的Scikit-learn软件包,它可以让我们更好地平衡数据。
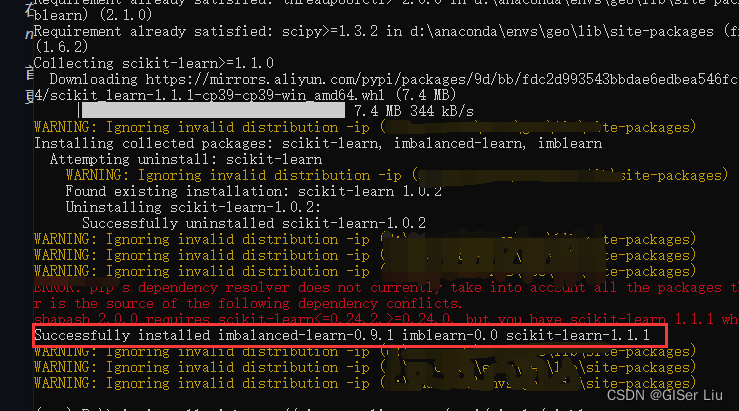
在命令行中输入以下代码,使用阿里的镜像来安装 imblearn :
pip install -i https://mirrors.aliyun.com/pypi/simple/ imblearn
看到如下图所示代表安装成功。
二、数据加载及预处理
1.加载并查看数据
①导入Python第三方库
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
from imblearn.over_sampling import SMOTE
②调用并查看数据
df = pd.read_csv(‘cuisines.csv’)
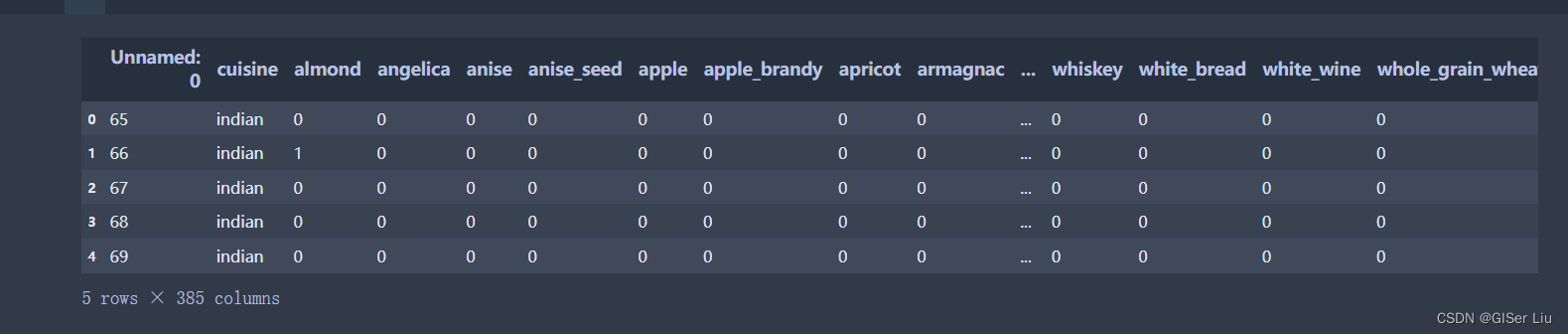
df.head()
前5行数据如下图所示:
查看数据结构:
df.info()
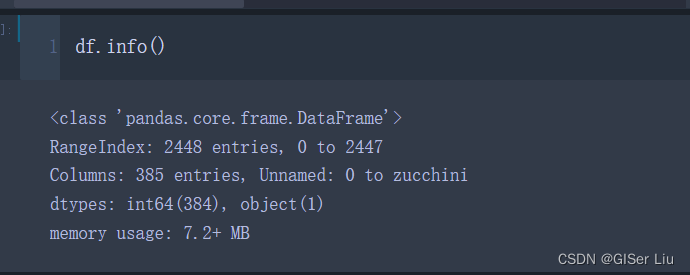
通过查看数据与其组织结构,我们可以发现数据有2448行,385列,其中有大量的无效数据。
2.查看数据分布
我们可以对数据进行可视化来发现数据集中的数据分布。
①各国样本分布直方图
通过调用barh()函数将数据绘制为柱状图。
df.cuisine.value_counts().plot.barh() #根据不同国家对数据集进行划分
结果如下:
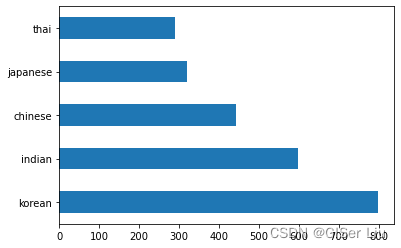
我们可以看到,数据集中以韩国料理样本最多,泰国样本最少。美食的数量有限,但数据的分布是不均匀的。我们可以解决这个问题!在此之前,请进一步探索。
②各国样本划分
了解各国美食有多少可用数据并将其打印输出。输入以下代码,从结果中我们可以看到不同国家美食的可用数据:
thai_df = df[(df.cuisine == “thai”)]#提取泰国美食
japanese_df = df[(df.cuisine == “japanese”)]#提取日本美食
chinese_df = df[(df.cuisine == “chinese”)]#提取中国美食
indian_df = df[(df.cuisine == “indian”)]#提取印度美食
kor
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7948
7948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









