







- 明确我们要改进的产品/策略。
2 选择检验指标
2.1 选择一类指标
一类指标:不能容忍变差的指标;
二类指标:目标提升的指标。
如何确定一类指标?
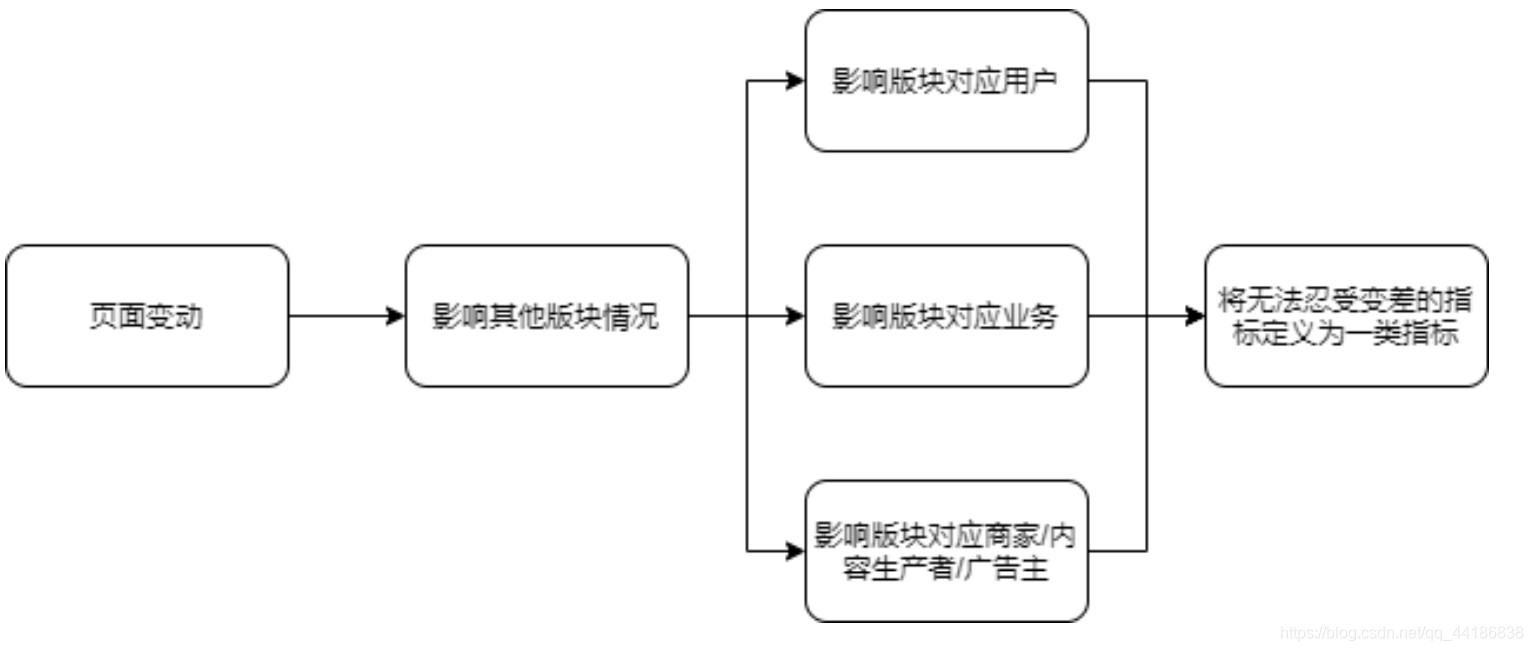
如图,比方说我们现在想要在原本的页面增加一个搜索框,那对应的可能会导致用户的体验感收到影响,原本页面可以提供8个子链接可能就变成了6个子链接(即影响板块对应业务),可以展示的广告也会收到影响。这也就是图中的三大影响(即人货场:分析平台类的产品,我们要将消费者、平台方、供给方分开讨论),最终选择哪些是我们无法忍受变差的指标,将其定义为一类指标。当然,你可以考虑给对应的指标设定阈值。
场景举例:

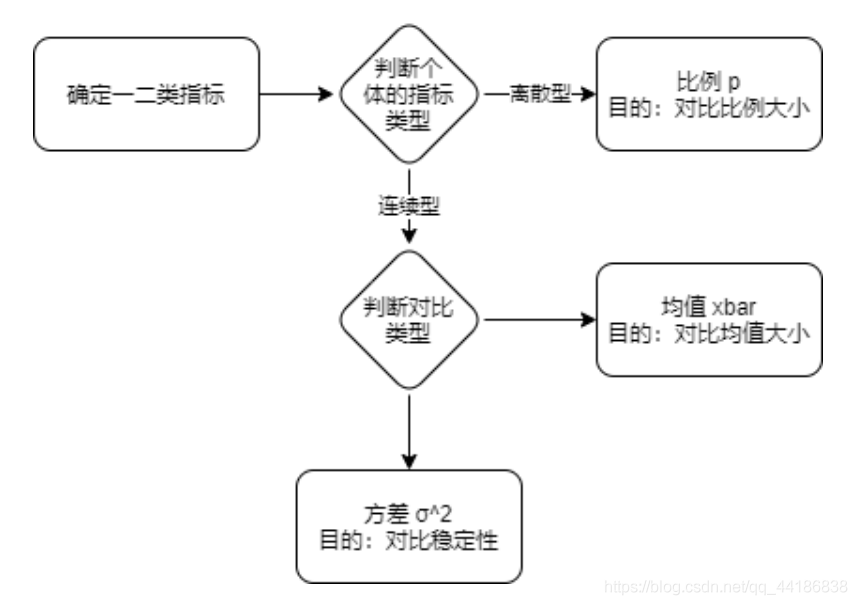
2.2 选择统计量
3 确定原假设与备择假设
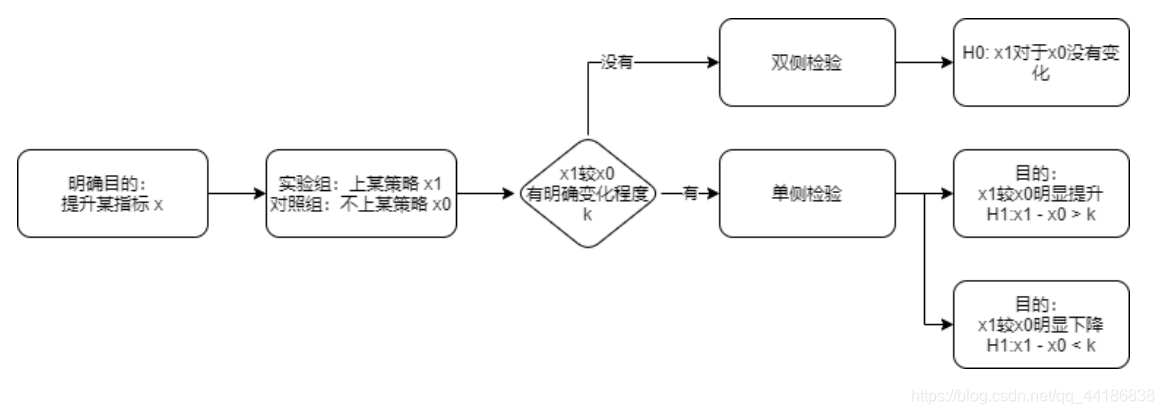
这里的x1是上策略后的水平,x0是原水平。
x1较x0有没有明确变化程度指的是定目标的时候,除了定指标定方向外,还有没有定优化程度。这里其实我在上篇博客讲到的就是说如果明确是要提升或者明确下降的话(有>或<),就是有,反之就是没有。而提升(<)就是左尾,提升(>)是右尾。也就是判断位于左拒绝域还是右拒绝域。
4 两类统计错误的防范
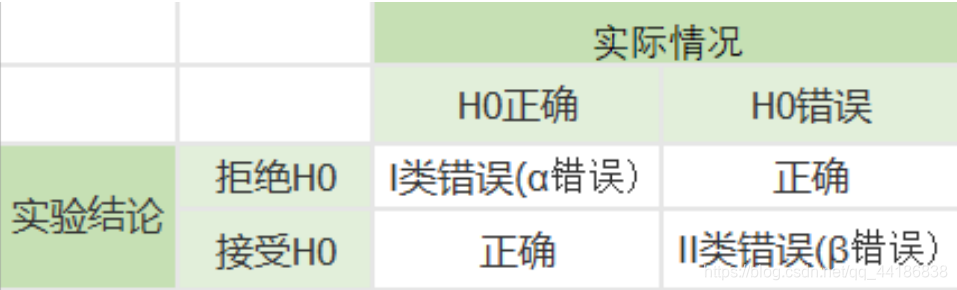
1、 α+β不一定等于1。
2、在样本容量确定的情况下,α与β不能同时增加或减少。
3、统计检验效力(1-β)当H0为假时,得出拒绝H0的正确结论的概率,被称做检验的效力
- I类错误防范 :
- 小概率α设置小些( 避免小概率的触发)
- 增加样本量(使异常数据的影响降低)
- II类错误防范:
- 调大α(增加小概率的触发) 但是接受I类错误的代价远比II类错误的代价要大,所以不予使用;
- II类错误概率只能在实验结束后才能计算发生二类错误的概率,这是一个事后值。所以在事前设计我们一般不考虑这个问题。默认二类错误的概率为20%。
5 样本量计算
统计学上根据统计量抽样分布和边际误差确定样本量。
样本量计算工具:https://www.evanmiller.org/ab-testing/sample-size.html
业务层面是以一类错误临界值二类错误临界值计算。
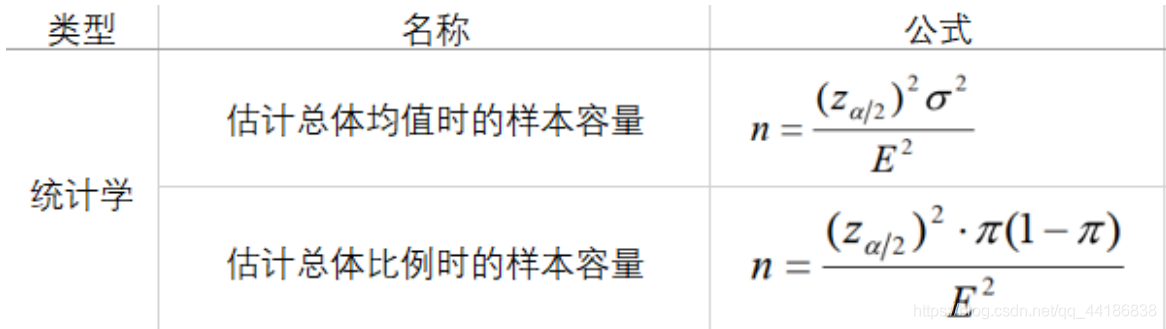
其中,区间估计算式
E
2
E^2
E2为:
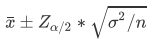
z
α
/
2
z_{\alpha/2}
zα/2可用EXCEL中的NORM.INV算出。
不过真实业务一般是下面的情况:
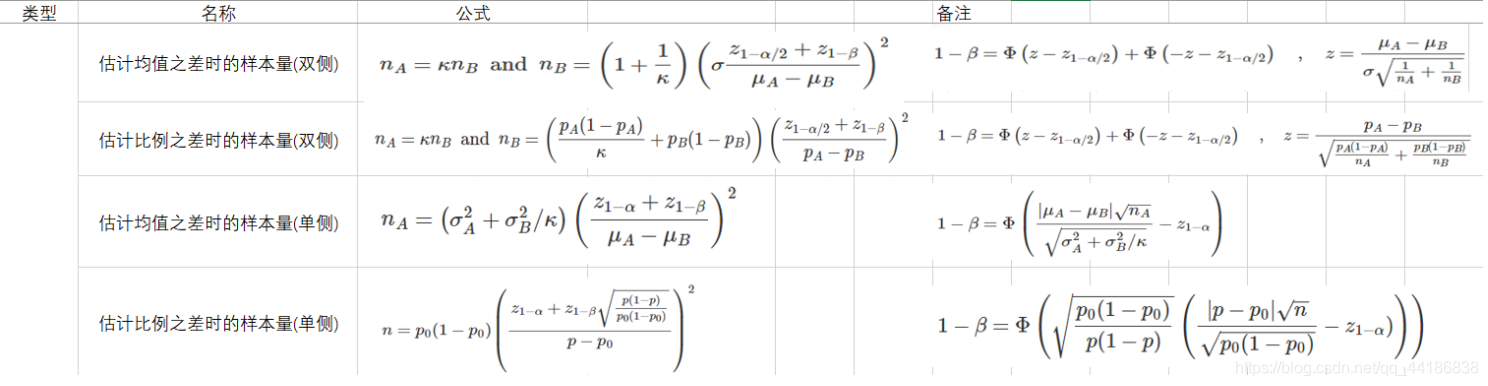
这里的
k
k
k指的是a组样本量与b组样本量之比,
μ
A
−
μ
B
\mu_A-\mu_B
μA−μB是提高/降低的目标。
当没有做抽样,不知道实验组总体方差时,可以用现有总体的方差代替。
6 检验策略选择、设计分组策略
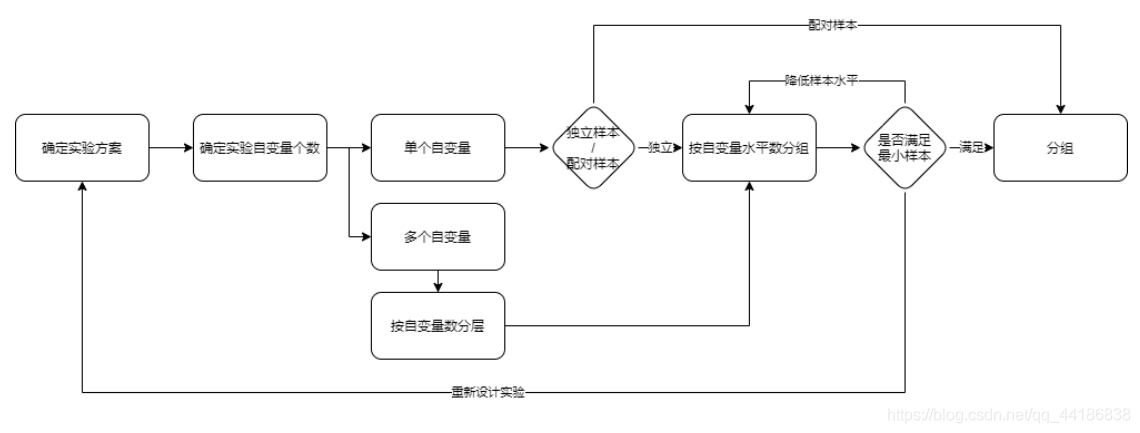
实验自变量个数指的是我们采用策略的个数,比方说我们策略1是改变字体大小,策略2是改变字体颜色,那么此时实验自变量个数就是2。而自变量水平数指的是策略中的几种方案,比方改变颜色这个策略中我选择改成红蓝绿三种颜色,那么策略2的自变量水平数就是3+1个原水平,也就是4。
通常情况下我们都算采用独立样本,那么什么时候会选择配对样本呢?
- 实验对象十分特殊,都有某种特点;
- 实验对象的状态持续时间比较长;
- 实验对象数量较少。
举个例子,我想出了一个治疗罕见疾病的方法,想做ABTest,可病人实在太少了,那这个时候就可以考虑配对样本。(例子随便举的)
7 当企业没有AB测试的条件的时候,如何解决问题?
可以大致分为3中情况:
给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 7893
7893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









