







写在最后
在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。
需要完整版PDF学习资源私我
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
加固过程原函数的代码逻辑替换为 native 方法,同时对 Custom VM 进行初始化,原函数 native 方法负责将参数传入到 Custom VM 中,Custom VM 解释执行原代码的等价指令。
实现 DEX-VMP 总体来说需要两步:
1、对原 dex 处理,找到要保护的方法,将原指令翻译成等价指令,加密存储,并将原指令替换为 VMP 入口指令
2、实现 VM,解释执行存储的等价指令
3.6 加固方案对比
可以看到,加固技术是不断攻防升级的过程,下面我们将以上加固技术分为五代进行对比:
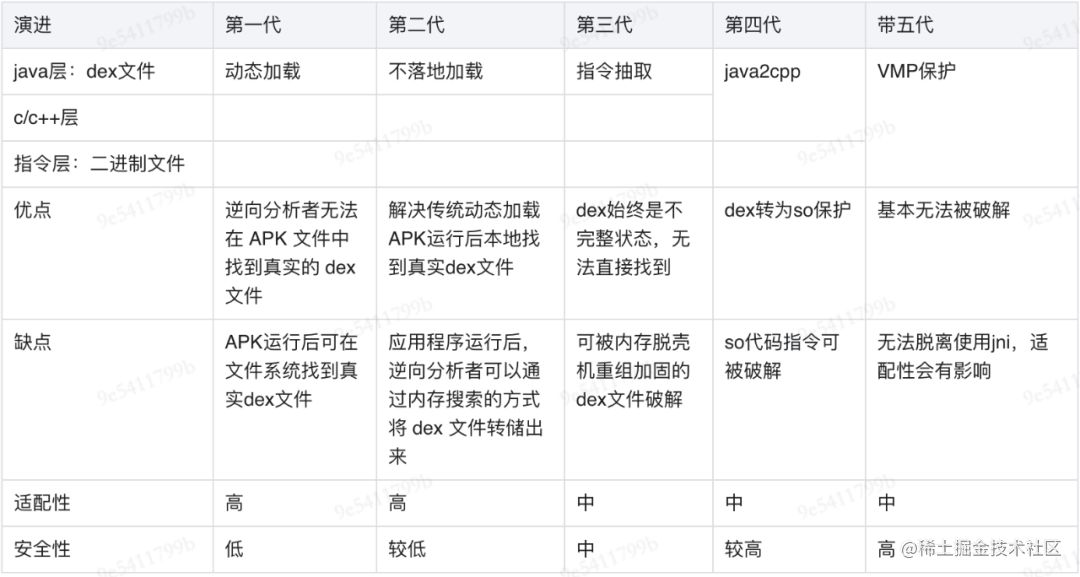
由以上对比我们可以看出,在加固技术演进过程中,VMP方案是发展到目前,加固安全度最高的方式,本着安全性角度出发,我们选择VMP方案重点介绍与分析,以下是对于项目中VMP加固的分析过程。
04 DEX-VMP加固落地实现
以下是我们要保护的一段示例代码:
package com.vmp.mylibrary;
public class HelleVMP3 {
public int compute(int a, int b) {
int c = a + a;
int d = a * b;
int e = a - b;
int f = a / b;
int result = c + d + e + f;
return result;
}
}
4.1 dex 文件预处理
dex 预处理主要做两方面工作:
1、保护方法的原指令拷贝出来并存储
2、保护方法的原指令替换成 VMP 入口方法
将要保护的 java 代码编译成 dex 文件,放入 010editor 中可以查看 compute 方法对应的指令数据:

可以看到蓝色区域包含的方法所需要的寄存器数,内部参数,外部参数及指令长度。这些都是 VM 需要的关键信息,需要存储起来。然后将指令替换为 DEX-VMP 的 native 入口指令。
有一些工具可以帮我们实现以上操作,比如 dexlib2,使用该工具可以对指定方法构造 dalvik 指令,或获取方法的指令数据。该工具的具体使用方法大家可以自定搜索。
4.2 寄存器结构设计
通过dexdump 命令查看,原方法二进制结构内容如下:
Virtual methods -
#0 : (in Lcom/vmp/mylibrary/HelloVMP3;)
name : 'compute'
registers : 6
ins : 3
outs : 0
insns size : 11 16-bit code units
28e588: |[28e588] com.vmp.mylibrary.HelloVMP3.compute:(II)I
28e598: 9000 0404 |0000: add-int v0, v4, v4
28e59c: 9201 0405 |0002: mul-int v1, v4, v5
28e5a0: 9102 0405 |0004: sub-int v2, v4, v5
28e5a4: b354 |0006: div-int/2addr v4, v5
28e5a6: b010 |0007: add-int/2addr v0, v1
28e5a8: b020 |0008: add-int/2addr v0, v2
28e5aa: b040 |0009: add-int/2addr v0, v4
28e5ac: 0f00 |000a: return v0
从示例 compute 方法的一些 hex 数据中,可以得到一些关键信息:
compute 方法在执行过程中需要使用到 6 个寄存器,传入参数 3 个, 没有使用 try 结构,指令数据为 16 个字。
Dalvik 寄存器最大长度为 32bit,我们可以直接申请一段内存来表示寄存器:
regptr_t regs[6];
regs[0] = 0;
regs[1] = 0;
regs[2] = 0;
regs[3] = 0;
regs[4] = 0;
regs[5] = 0;
regs[3] = (regptr_t) thiz;
regs[4] = p1;
regs[5] = p2;
u1 reg_flags[6];
reg_flags[0] = 0;
reg_flags[1] = 0;
reg_flags[2] = 0;
reg_flags[3] = 0;
reg_flags[4] = 0;
reg_flags[5] = 0;
reg_flags[3] = 1;
regs 表示寄存器,4 个寄存器分别为 regs [0], regs [1], regs [2], regs [3]。regs_bits_obj 表示对应寄存器是否是 Object,比如 regs [3] 是 Object,则 regs_bits_obj [3] = 1,非 object 的情况均为 0;
每一个保护方法在进入 VM 后,我们就像示例这样创建好这样的寄存器单元,供 VM 在解释执行阶段使用,执行完毕销毁即可。
注意这个过程的专业的加固工具会在 dex 预处理过程中识别二进制结构内容进行执行,无需每保护一个方法单独开发。
4.3 虚拟机实现
我们就以示例 compute 方法中的 add-int, mul-int, sub-int, div-int 这几条指令来实现一个简易的解释器
介绍一下这几条指令的作用:add-int、mul-int、sub-int、div-int 对两个源寄存器执行已确定的二元运算,并将结果存储到目标寄存器中。
首先定义自定义虚拟机需要执行的vmCode结构:
typedef struct {
const u2 *insns; // 指令
const u4 insnsSize; // 指令大小
regptr_t *regs; // 寄存器
u1 *reg_flags; // 寄存器数据类型标记,主要标记是否为对象
const u1 *triesHandlers; // 异常表
} vmCode;
自定义Opcode:
enum Opcode {
OP_ADD_INT = 0x3a,
OP_MUL_INT = 0xe4,
OP_SUB_INT = 0x77,
OP_DIV_INT_2ADDR = 0x6c,
OP_ADD_INT_2ADDR = 0xcf,
OP_RETURN = 0xde,
};
目标方法转化的 native 方法:
static jint Java_com_vmp_mylibrary_HelloVMP3_compute__II_I(JNIEnv *env, jobject thiz , jint p1, jint p2) {
regptr_t regs[6];
regs[0] = 0;
regs[1] = 0;
regs[2] = 0;
regs[3] = 0;
regs[4] = 0;
regs[5] = 0;
regs[3] = (regptr_t) thiz;
regs[4] = p1;
regs[5] = p2;
u1 reg_flags[6];
reg_flags[0] = 0;
reg_flags[1] = 0;
reg_flags[2] = 0;
reg_flags[3] = 0;
reg_flags[4] = 0;
reg_flags[5] = 0;
reg_flags[3] = 1;
static const u2 insns[] = {
0x00b3, 0x0404, 0x0120, 0x0504, 0x02ee, 0x0504, 0x546c, 0x10a9, 0x20a9, 0x40a9,
0x00ad,
};
const u1 *tries = NULL;
const vmCode code = {
.insns=insns,
.insnsSize=11,
.regs=regs,
.reg_flags=reg_flags,
.triesHandlers=tries
};
jvalue value = vmInterpret(env,
&code,
&dvmResolver);
return value.i;
}
执行指令处理逻辑:
#define OP_END
#define INST_AA(_inst) ((_inst) >> 8)
#define FETCH(_offset) (pc[(_offset)])
#define SET_REGISTER(_idx, _val) \
DELETE_LOCAL_REF(_idx); \
(fp[(_idx)] =(u4) (_val)); \
SET_REGISTER_FLAGS(_idx, 0)
#define HANDLE_OP_X_INT(_opcode, _opname, _op, _chkdiv)
HANDLE_OPCODE(_opcode /*vAA, vBB, vCC*/)
{
u2 srcRegs;
vdst = INST_AA(inst);
srcRegs = FETCH(1);
vsrc1 = srcRegs & 0xff;
vsrc2 = srcRegs >> 8;
ILOGV("|%s-int v%d,v%d", (_opname), vdst, vsrc1);
......
}
FINISH(2);
#define HANDLE_OP_X_INT(_opcode, _opname, _op, _chkdiv) \
HANDLE_OPCODE(_opcode /*vAA, vBB, vCC*/) \
{ \
u2 srcRegs; \
vdst = INST_AA(inst); \
srcRegs = FETCH(1); \
vsrc1 = srcRegs & 0xff; \
vsrc2 = srcRegs >> 8; \
ILOGV("|%s-int v%d,v%d", (_opname), vdst, vsrc1); \
if (_chkdiv != 0) { \
s4 firstVal, secondVal, result; \
firstVal = GET_REGISTER(vsrc1); \
secondVal = GET_REGISTER(vsrc2); \
if (secondVal == 0) { \
dvmThrowArithmeticException(env,"divide by zero"); \
GOTO_exceptionThrown(); \
} \
if ((u4)firstVal == 0x80000000 && secondVal == -1) { \
if (_chkdiv == 1) \
result = firstVal; /* division */ \
else \
result = 0; /* remainder */ \
} else { \
result = firstVal _op secondVal; \
} \
SET_REGISTER(vdst, result); \
} else { \
/* non-div/rem case */ \
SET_REGISTER(vdst, (s4) GET_REGISTER(vsrc1) _op (s4) GET_REGISTER(vsrc2)); \
} \
} \
FINISH(2);
__attribute__((visibility("default")))
jvalue vmInterpret(JNIEnv *env, const vmCode *code, const vmResolver *dvmResolver) {
jvalue args_tmp[5]; // 方法调用时参数传递(参数数量小于等于5)
jvalue retval;
regptr_t *fp = code->regs; // 寄存器
u1 *fp_flags = code->reg_flags; // 寄存器类型标识
const u2 *pc = code->insns;
......
/* File: c/OP_ADD_INT.cpp */
HANDLE_OP_X_INT(OP_ADD_INT, "add", +, 0)
OP_END
/* File: c/OP_SUB_INT.cpp */
HANDLE_OP_X_INT(OP_SUB_INT, "sub", -, 0)
OP_END
/* File: c/OP_MUL_INT.cpp */
HANDLE_OP_X_INT(OP_MUL_INT, "mul", *, 0)
OP_END
/* File: c/OP_DIV_INT.cpp */
HANDLE_OP_X_INT(OP_DIV_INT, "div", /, 1)
OP_END
/* File: c/OP_REM_INT.cpp */
HANDLE_OP_X_INT(OP_REM_INT, "rem", %, 2)
OP_END
end:
return 0;
}
上面是一个解析自定义 opcode 的解释器,大家可以从其中看到解释器就是 while switch 的程序结构,执行到 return 指令时退出循环。
4.4 总结
通过以上实现,可以发现虚拟机加固核心自定义一套opcode用于对保护方法的指令替换,同时还需要对替换后的指令识别后,如果对Java函数的调用交给DVM进行处理,如果是原函数指令则创建寄存器交给机器处理。整个加固过程中分为编译器+解释器两部分。
其中编译器负责对打包的AAR或者APK进行加固,加固过程则是将要保护的方法转换为JNI调用,同时C++部分根据原方法指令生成需要的寄存器与opcode;而解释器则是在运行过程,当执行到JNI调用时,能够对创建的opcode进行识别,转化原指令与寄存器交由真正的DVM进行执行。
05 兼容与性能
5.1 兼容性风险
兼容风险:
- 加固方案主要的兼容问题在于无法脱离JNI实现,而 VM 中 JNI 实现细节不尽相同。比如 Android 5.0 某个小版本中 JNI 实现会存在一个隐含的 jobject(local reference)忘记 delete 掉,当多次调用该 JNI 函数时,内存溢出不可避免。这个BUG 在之后的 Android 版本中更正过来,也就是说每个 Android 版本出来之后,我们都要看看 VMP 会不会存在 JNI 兼容性方面的 BUG。
规避建议:
- 每个Android 版本更新需要重点关注JNI实现的变化,是否存在 JNI 兼容性方面问题。
5.2 性能问题
产生性能消耗的主要有两点:
给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网络安全面试题
绿盟护网行动
还有大家最喜欢的黑客技术
网络安全源码合集+工具包

所有资料共282G,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 5869
5869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









