







还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
93道网络安全面试题


需要体系化学习资料的朋友,可以加我V获取:vip204888 (备注网络安全)
内容实在太多,不一一截图了
黑客学习资源推荐
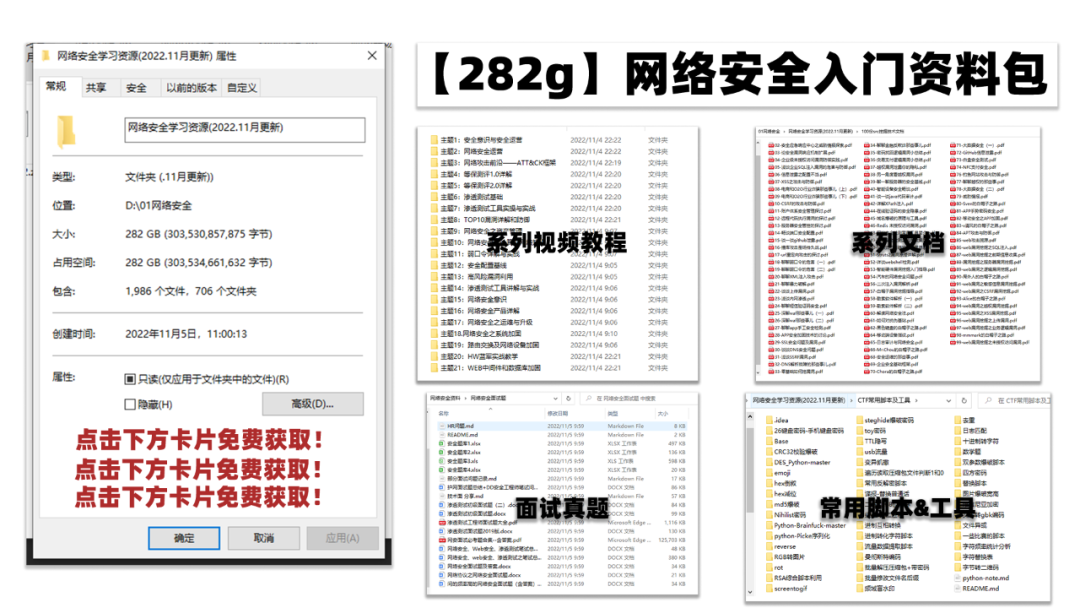
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
😝朋友们如果有需要的话,可以联系领取~
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

2️⃣视频配套工具&国内外网安书籍、文档
① 工具

② 视频
③ 书籍
资源较为敏感,未展示全面,需要的最下面获取

② 简历模板
因篇幅有限,资料较为敏感仅展示部分资料,添加上方即可获取👆
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
通过以下的图:
hadoop生态系统
我们可以可以总结如下常用的应用框架(图中没有的,我也列出了几个):
1,HDFS(hadoop分布式文件系统)
是hadoop体系中数据存储管理的基础。他是一个高度容错的系统,能检测和应对硬件故障。
client:切分文件,访问HDFS,与那么弄得交互,获取文件位置信息,与DataNode交互,读取和写入数据。
namenode:master节点,在hadoop1.x中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户 端请求。
DataNode:slave节点,存储实际的数据,汇报存储信息给namenode。
secondary namenode:辅助namenode,分担其工作量:定期合并fsimage和fsedits,推送给namenode;紧急情况下和辅助恢复namenode,但其并非namenode的热备。
2,mapreduce(分布式计算框架)
mapreduce是一种计算模型,用于处理大数据量的计算。其中map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
jobtracker:master节点,只有一个,管理所有作业,任务/作业的监控,错误处理等,将任务分解成一系列任务,并分派给tasktracker。
tacktracker:slave节点,运行 map task和reducetask;并与jobtracker交互,汇报任务状态。
map task:解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入到本地磁盘(如果为map—only作业,则直接写入HDFS)。
reduce task:从map 它深刻地执行结果中,远程读取输入数据,对数据进行排序,将数据分组传递给用户编写的reduce函数执行。
3, hive(基于hadoop的数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
4,hbase(分布式列存数据库)
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。和传统关系型数据库不同,hbase采用了bigtable的数据模型:增强了稀疏排序映射表(key/value)。其中,键由行关键字,列关键字和时间戳构成,hbase提供了对大规模数据的随机,实时读写访问,同时,hbase中保存的数据可以使用mapreduce来处理,它将数据存储和并行计算完美结合在一起。
5,zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
6,sqoop(数据同步工具)
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
7,pig(基于hadoop的数据流系统)
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。通常用于离线分析。
8,mahout(数据挖掘算法库)
mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建只能应用程序。mahout现在已经包含了聚类,分类,推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法是,mahout还包含了数据的输入/输出工具,与其他存储系统(如数据库,mongoDB或Cassandra)集成等数据挖掘支持架构。
9,flume(日志收集工具)
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。
10,资源管理器的简单介绍(YARN和mesos)
随着互联网的高速发展,基于数据 密集型应用 的计算框架不断出现,从支持离线处理的mapreduce,到支持在线处理的storm,从迭代式计算框架到 流式处理框架s4,…,在大部分互联网公司中,这几种框架可能都会采用,比如对于搜索引擎公司,可能的技术方法如下:网页建索引采用mapreduce框架,自然语言处理/数据挖掘采用spark,对性能要求到的数据挖掘算法用mpi等。公司一般将所有的这些框架部署到一个公共的集群中,让它们共享集群的资源,并对资源进行统一使用,这样便诞生了资源统一管理与调度平台,典型的代表是mesos和yarn。
11,其他的一些开源组件:
1)cloudrea impala:
一个开源的查询引擎。与hive相同的元数据,SQL语法,ODBC驱动程序和用户接口,可以直接在HDFS上提供快速,交互式SQL查询。impala不再使用缓慢的hive+mapreduce批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎。可以直接从HDFS或者Hbase中用select,join和统计函数查询数据,从而大大降低延迟。
2)spark:
spark是个开源的数据 分析集群计算框架,最初由加州大学伯克利分校AMPLab,建立于HDFS之上。spark与hadoop一样,用于构建大规模,延迟低的数据分析应用。spark采用Scala语言实现,使用Scala作为应用框架。
spark采用基于内存的分布式数据集,优化了迭代式的工作负载以及交互式查询。
与hadoop不同的是,spark与Scala紧密集成,Scala象管理本地collective对象那样管理分布式数据集。spark支持分布式数据集上的迭代式任务,实际上可以在hadoop文件系统上与hadoop一起运行(通过YARN,MESOS等实现)。
3)storm
storm是一个分布式的,容错的计算系统,storm属于流处理平台,多用于实时计算并更新数据库。storm也可被用于“连续计算”,对数据流做连续查询,在计算时将结果一流的形式输出给用户。他还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。
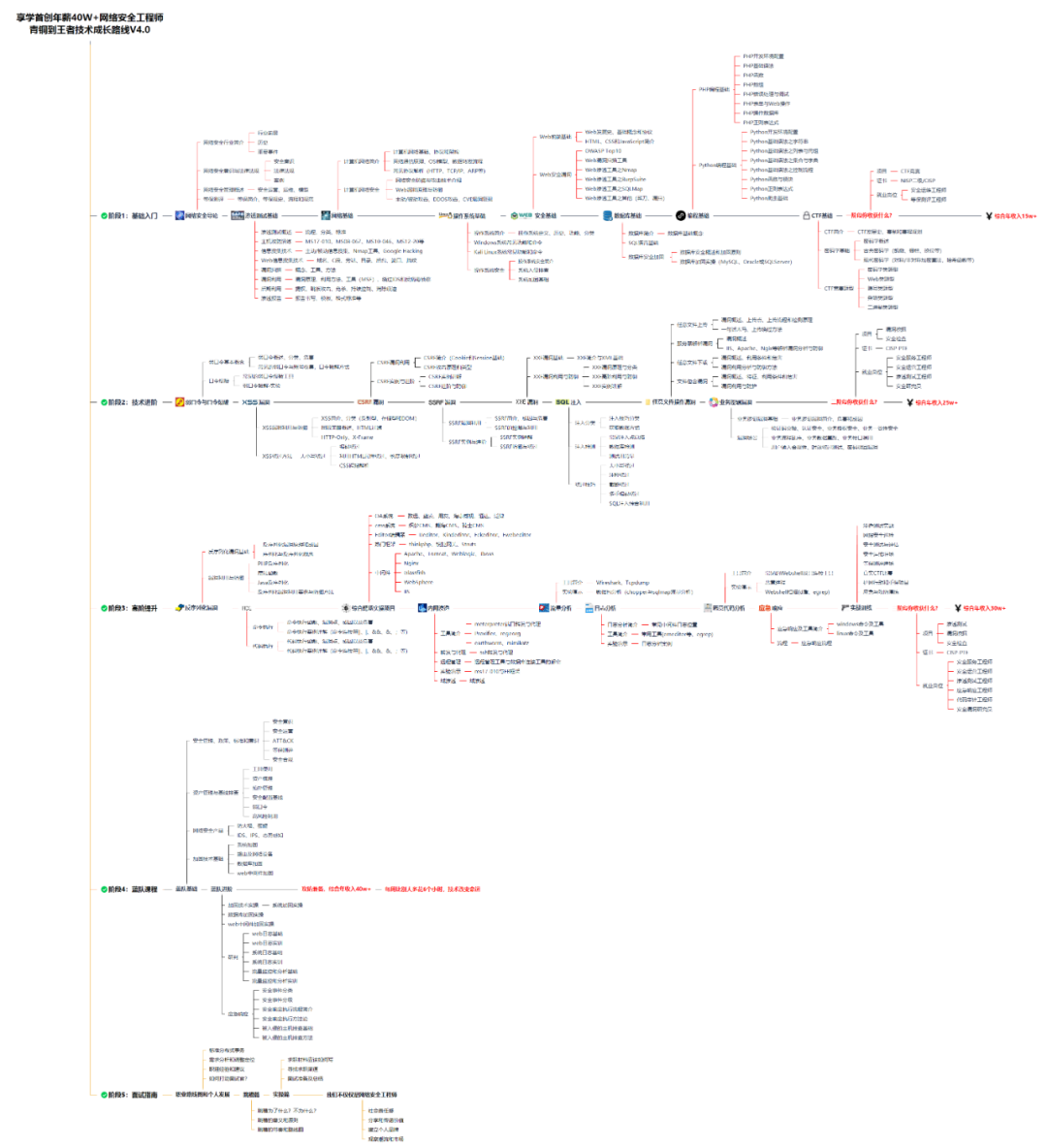
一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
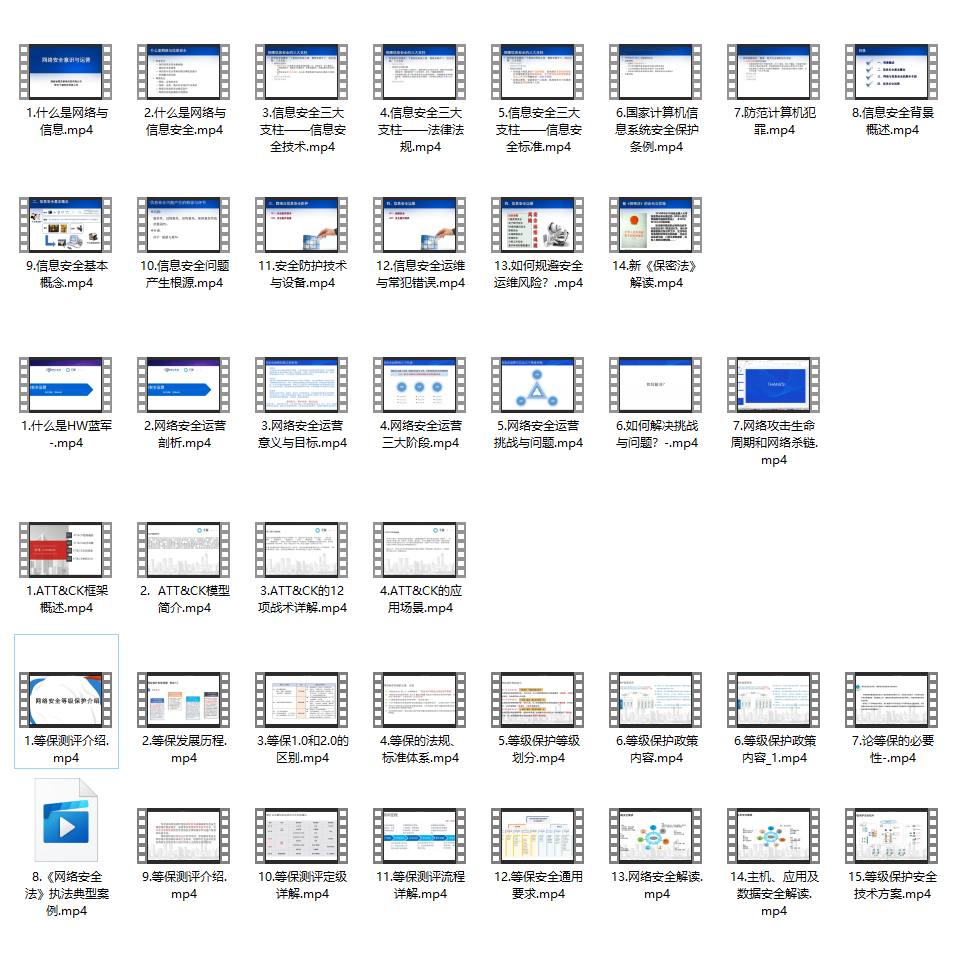
二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
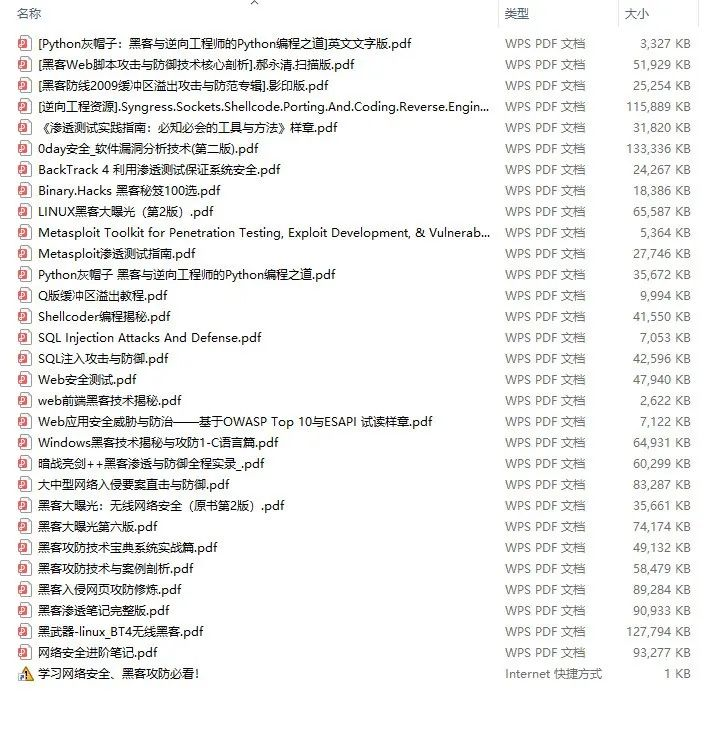
三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
需要体系化学习资料的朋友,可以加我V获取:vip204888 (备注网络安全)

五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2222
2222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









