







 本文详细解析了Redis6.0引入多线程的原因,如何在Redis中实现list排序,以及Redis的五种基本类型底层原理。还探讨了缓存相关问题如穿透、击穿、雪崩,数据同步与一致性处理,包括双写一致性,数据持久化策略,过期与淘汰机制,以及如何通过Redisson实现分布式锁和保证数据一致性。
本文详细解析了Redis6.0引入多线程的原因,如何在Redis中实现list排序,以及Redis的五种基本类型底层原理。还探讨了缓存相关问题如穿透、击穿、雪崩,数据同步与一致性处理,包括双写一致性,数据持久化策略,过期与淘汰机制,以及如何通过Redisson实现分布式锁和保证数据一致性。
Redis相关
- Redis6.0为什么要用多线程?
- 在Redis中存一个list集合怎么实现排序?
- Redis的5大基本类型的底层原理?
- 缓存穿透?
- 缓存击穿?
- 缓存雪崩?
- redis做为缓存怎么保持和mysql数据进行同步?(双写一致性)
- redis做为缓存,数据的持久化是怎么做的?
- Redis的数据过期策略有哪些 ?
- Redis的数据淘汰策略有哪些 ?
- 数据库有1000万数据 ,Redis只能缓存20w数据, 如何保证Redis中的数据都是热点数据 ?
- Redis分布式锁如何实现 ?
- 如何控制Redis实现分布式锁有效时长呢?
- redisson实现的分布式锁是可重入的吗?
- redisson实现的分布式锁能解决主从一致性的问题吗?
- 如果业务非要保证数据的强一致性,这个该怎么解决呢?
- Redis集群有哪些方案?
- 什么是主从同步?
- 主从同步数据的流程
- 怎么保证Redis的高并发高可用?
- redis集群脑裂,该怎么解决呢?
- redis的分片集群有什么作用?
- Redis分片集群中数据是怎么存储和读取的?
- Redis是单线程的,但是为什么还那么快?
- 能解释一下I/O多路复用模型?

Redis6.0为什么要用多线程?
提高请求数,redis的瓶颈在于内存,使用分一个子线程去进行IO操作。
在Redis中存一个list集合怎么实现排序?
list类型中有一个sort命令可以排序。(sort key)
Redis的5大基本类型的底层原理?
Redis底层使用一个redisObject来表示所有的key和value
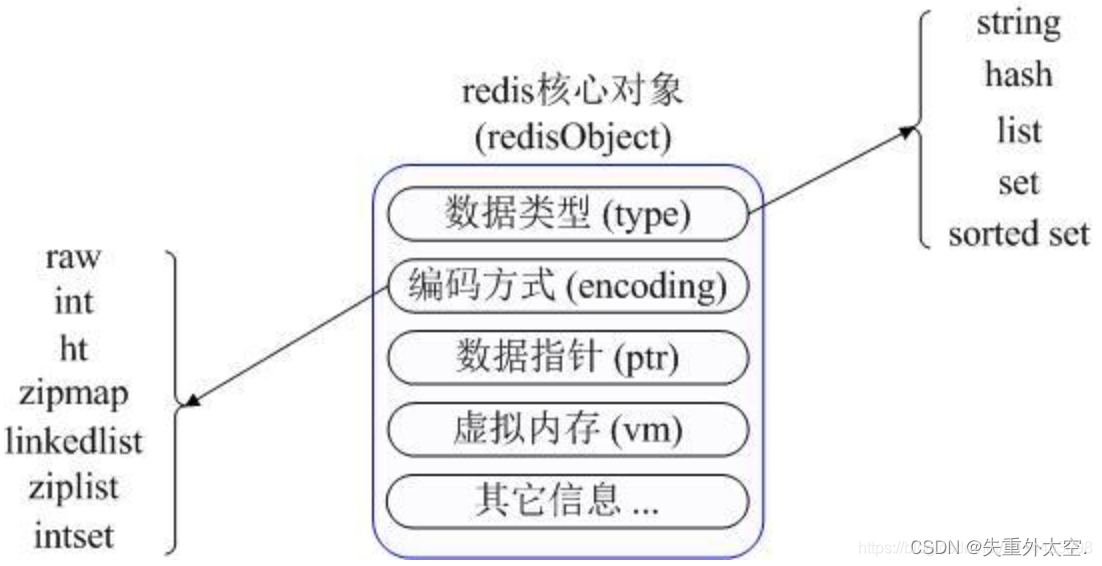
type:表示属于哪种基本类型;
encoding:表示底层使用数据结构;
ptr:指向底层数据结构的指针;
vm:虚拟内存,默认是关闭的;
- String:动态字符串SDS
- int:字符串类型的整型,底层使用int实现,比如set a 100;
- raw:动态字符串,大于39字节,分配两次;
- embstr:动态字符串,小于39字节,内存类型,只分配一次;
- List 类型:链表
- zipList:列表的长度小于512,元素的字节数小于64,使用ziplist,它进行了压缩;
- linkedList:不满足上面的条件就使用linkedlist,双向链表;
- set类型:intset或者hashtable
- intest:集合长度512且元素都是整数,使用intset;
- hashtble:hashtable底层使用字典结构(hash),键为字符串对象,value为null;
- hash类型:ziplist或者hashtable
- 键值对数量小于512,且所有键值对长度小于64字节,使用ziplist压缩;
- 键值对数量大于512,且其中有键值对长度大于64字节,使用hashtable;
- zset类型:ziplist或者skiplist
- 集合长度小于128,元素的字节数小于64使用ziplist压缩;
- 上面不满足使用skiplist,底层使用跳表实现;
缓存穿透?
查询到空数据,缓存中没有,数据库中也没有,当有大量的空数据访问,会造成数据库压力过大,容易宕机。
解决方法:
1.缓存空数据:查到数据库中也没有,在缓存中缓存一个空数据,下次访问直接从数据库中获取
2.布隆过滤器:用于检索一个数据是否存在于一个集合中,(底层主要是先去初始化一个比较大数组,里面存放的二进制0或1。在一开始都是0,当一个key来了之后经过3次hash计算,模于数组长度找到数据的下标然后把数组中原来的0改为1,这样的话,三个数组的位置就能标明一个key的存在。)访问时先判断布隆过滤器中是否有数据,没有则直接返回。不过存在误判问题。
缓存击穿?
对于设置了过期时间的数据,缓存在某个时间点过期,而恰好这个时间有大量的数据进行访问。
解决方法:
双重锁
互斥锁:在缓存中没有查询到时,先获取互斥锁,查询数据库重建缓存,然后释放锁。此时其他线程只能等待。
(强一致性,性能差)
逻辑过期:在缓存中没有查询到时,一个线程先获取到互斥锁,再开一个线程去查询数据库重建缓存,其他线程则返回过期的时间。(高可用,性能优)
缓存雪崩?
大量的缓存在同一时间失效,或者redis宕机,请求直接到数据库。
解决方法:
给key的过期时间设置一个随机值,
搭建redis集群,
给业务添加多级缓存,
给业务添加降级限流策略。
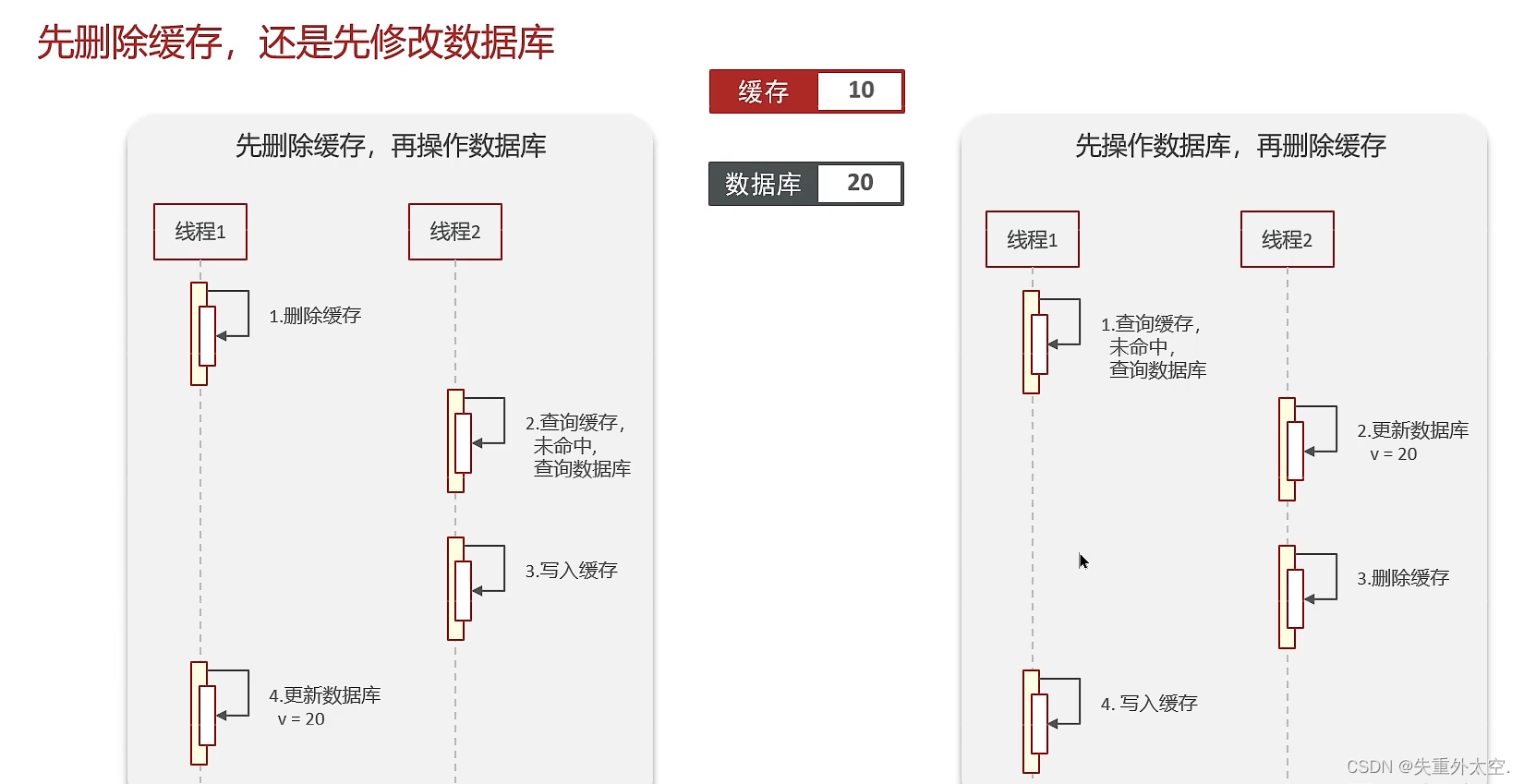
redis做为缓存怎么保持和mysql数据进行同步?(双写一致性)
存强一致性的
- redisson实现的读写锁,在读的时候添加共享锁,可以保证读读不互斥,读写互斥。当我们更新数据的时候,添加排他锁,它是读写,读读都互斥,这样就能保证在写数据的同时是不会让其他线程读数据的,避免了脏数据。这里面需要注意的是读方法和写方法上需要使用同一把锁才行。(强一致性)
允许延时一致的业务
- 写入数据库后,清空缓存。
- 设置过期时间来保证最终一致性。
- 使用canal同步(阿里的canal组件实现数据同步:不需要更改业务代码,部署一个canal服务。canal服务把自己伪装成mysql的一个从节点,当mysql数据更新以后,canal会读取binlog数据,然后在通过canal的客户端获取到数据,更新缓存即可。)
- 使用MQ中间中间件,更新数据之后,通知缓存删除。
先删除缓存或者删除数据库都会出现问题,所有需要延时双删。
redis做为缓存,数据的持久化是怎么做的?
redis的数据持久化有两种,RDB和AOF
RDB:是以快照的形式把redis存储在内存的数据转到磁盘上去,当redis宕机恢复后,再从快照文件中加载数据。(二进制文件,体积小,恢复快)
快照分为手动快照和自动快照:
手动快照分为前台快照(save)和后台快照(bgsave);
AOF:含义是追加文件,当redis操作写命令的时候,都会存储这个文件中,当redis实例宕机恢复数据的时候,会从这个文件中再次执行一遍命令来恢复数据,因为AOF文件中保存的都是命令,所以必然会出现重复的命令,Redis采用重写机制来解决这个问题,重写要解决的问题就是删除AOF文件中重复的命令,已经被删除或者过期的命令。(默认关闭)
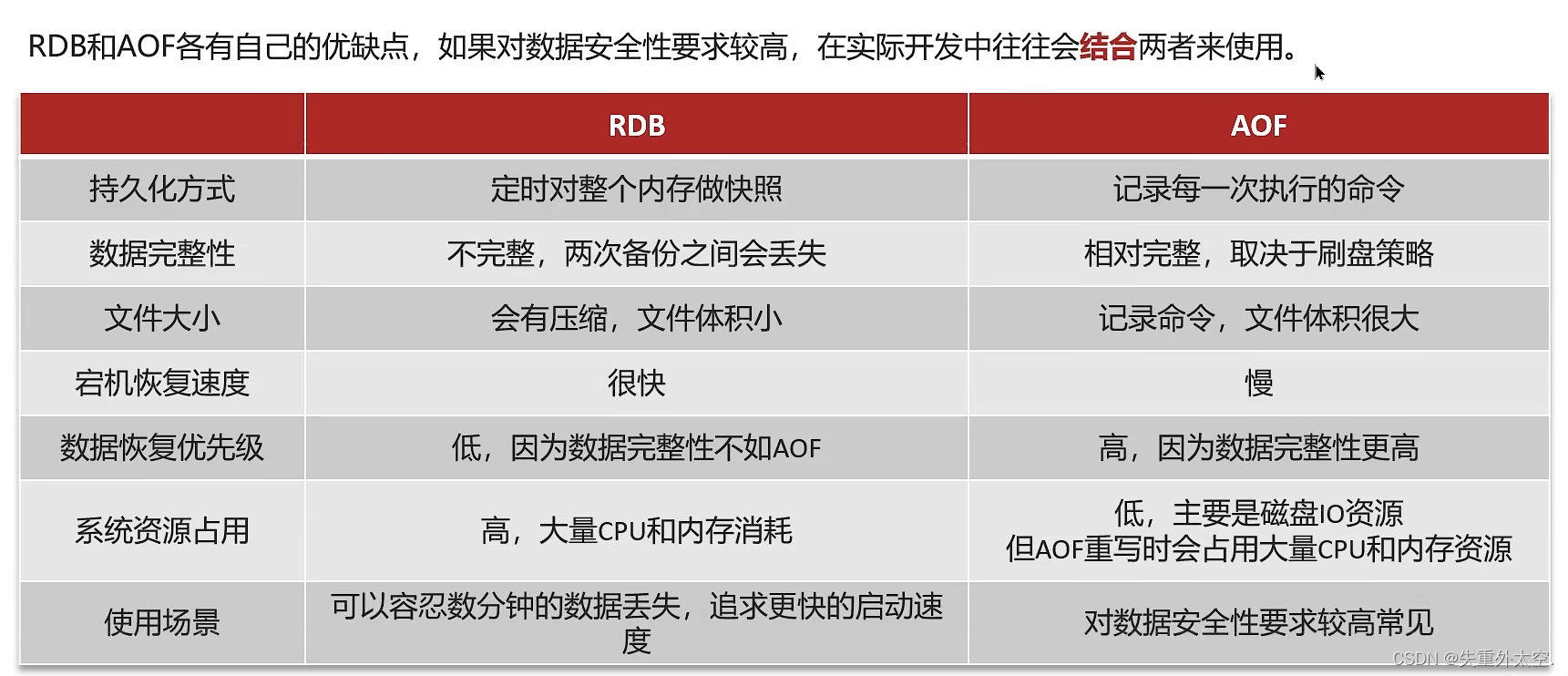
RDB缺点:容易丢失数据,耗时效率低;
RDB优点:适用于数据备份,方便传输,恢复大数据快,最大化redis性能(后台快照)
AOF优点:数据更加耐久(一旦出现故障最多丢失一秒数据),只进行追加的日志文件,体积过大会进行重写,容易读懂;
AOF缺点:体积大,速度低;
实际是两个一起用;
Redis的数据过期策略有哪些 ?
惰性删除和定期删除
惰性删除:当key过期时,只有当需要key时,去查询key判断是否过期,当过期就删除该key。
定期删除:每隔一段时间就对一些key检查,过期就删除。
Redis的数据淘汰策略有哪些 ?
这个在redis中提供了很多种,默认是noeviction,不删除任何数据,内存不足直接报错。
是可以在redis的配置文件中进行设置的,里面有两个非常重要的概念,一个是LRU,另外一个是LFU。
LRU的意思就是最少最近使用,用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
LFU的意思是最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
数据库有1000万数据 ,Redis只能缓存20w数据, 如何保证Redis中的数据都是热点数据 ?
可以使用 allkeys-lru (挑选最近最少使用的数据淘汰)淘汰策略,那留下来的都是经常访问的热点数据。
Redis分布式锁如何实现 ?
在redis中提供了一个命令setnx(SET if not exists)
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
需要这份系统化资料的朋友,可以点击这里获取
]
[外链图片转存中…(img-Oxm7Fihh-1714513563755)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 3952
3952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









