






本文作者介绍:苑爱泉,阿里本地生活-高级算法专家,负责本地生活的AI算法团队。团队工作涉及搜索、认知图谱、LLM大模型、图片视频等方向,过往几年,发表过多个专利,多篇论文入选WSDM、CIKM、ICASSP等顶级会议。
文章推荐
“人工智能教母”李飞飞创立的公司现估值10亿美元!字节将于明日首次公布视频大模型进展?|AI日报
没想到你是这样的AI!AI漫画合集大赏,直击灵魂的雷点...等你来看!
一、业界有哪些新鲜事儿?
上半年可以说是各大厂商轮番上台秀肌肉,我们先回顾下上半年部分的业界大会,以及几个重点会议都发布了啥:
- 3月18日,英伟达·GTC大会
- 3月23-24日,上海.GDC全球开发者先锋大会
- 4月9日,Cloud Next 2024
- 4月11-13日,Qcon24,北京
- 4月15日,斯坦福AI Index Report
- 4月16日,百度AI大会
- 4月17日,量子位.中国AIGC产业峰会
- 5月13日,OpenAI春季发布会:GPT-4o
- 5月14日,Google I/O大会
- 5月15日,2024春季·火山引擎·FORCE原动力大会
- 5月17日,AICon'24
- 6月2日,台北·Computex2024·英伟达
- 6月10日,苹果WWDC24
- 6月14-15日,智源大会
- 7月4-6日,上海WAIC大会
……
5月13日,OpenAI「春季新品发布会」
OpenAI用一场临时准备的春季发布会,提前“狙击”了谷歌,GPT-4o实时、带有情感的交互模式令人震撼。o是omni的缩写,大而全万能的意思,足见其野心。我们公众号也第一时间对GPT-4o做了测评。然而,2个月过去了,最令人期待的实时交互能力还是没有上线。

5月14日,Google I/O大会
有了GPT-4o珠玉在前,Google I/O大会上的发布似乎都“黯然失色”了,不过,仔细整理下还是有点东西的。

1)Gemini系列:
- Gemini 1.5 Pro,
- 到2M tokens;1.5 Pro其实在2.15已经发布,此次是从1M tokens->2M tokens;
- 可以看出,Gemini在短期内,还是在1.5这个代际上;2代何时发布,翘首以盼。
- Gemini 1.5 Flash:本次新发布,低延迟、低成本
- Gemini Nano:根植于Android操作系统里的
- 现场演示了一个case,是通话自动分析危险和提醒
- 多模态的,可以提供语音、视觉等交互;自动理解对话并提供建议
2)Gemma系列
宣称,Gemma2即将发布
- 发布了PaliGemma;模型大小是3B;能做哪些任务呢?
- Fine-tuning on single tasks 对单个任务进行微调
- Image question answering and captioning 图像问答和字幕
- Video question answering and captioning 视频问答和字幕
- Segmentation 分割
- 以及
- 24.2,Gemma-7B发布,是基于Gemini的
- 24.4,Gemma的两种结构变体发布:CodeGemma | RecurrentGemma
- 24.4,Gemma 1.1发布
3)发布Imagen-3
本次新发布了Imagen-3,2023年12月发布Imagen-2,2022年5月发布Imagen-1。
4)Veo,视频生成
可以创建高质量、逼真的1080p 视频片段。同时,支持文本到视频、视频到视频以及图像到视频的转换。
5)AI应用
智能搜索、Gemini Advanced Assistant等
6月2日,英伟达·Computex 2024
6月2日,在2024台北国际电脑展(Computex 2024)的keynote上,英伟达联合创始人兼CEO黄仁勋发布了英伟达最新的AI技术和未来的战略布局。
- AI Factory
- NIM,在线推理微服务
- 数字人/ACE
- 新一代GPU:B系列
还有那句名言:The more you buy, the more you save...



- Blackwell新架构:
- 一块BlackWell包含两块B200芯片。B200是到目前为止,世界上最强大的单芯片
- Blackwell GPU的单芯片AI性能高达20 PetaFLOPS,比上代Hopper H100提升4倍。
- 配备192GB HBM3e内存,带宽高达8TB/s;
- Blackwell GPU的AI推理性能比上一代提升了30倍;
- 两者之间互联,速度可达到10TB/s
- 配备第五代 NVLink,提供 1.8TB/s 双向带宽,支持多 GPU 无缝通信。
- 支持高达 10 万亿参数的大型语言模型。(10万亿,即10000B,即10T)
……老黄在介绍Blackwell的时候不小心泄露了某代GPT的参数情况?1.8T,即1800B,即18000亿参数。

另外,整理了下英伟达历年GPU系列:

6月10日,苹果WWDC 2024
这次发布会重新定义了苹果版的“AI”,是“Apple Intelligence”。库克站到了屋顶上,挺安全的?其他人在苹果环中间的会议室,但没有观众:

1)苹果版AI
五个关键词:
- Powerful:强大高效,在A17、M1/2/3/4等Apple Silicon芯片上都可运行
- Intuitive:直接交互操作,不麻烦
- Intergrated:整合了多个应用,可以跨应用执行Action
- Personal:有效捕获个人上下文
- Private:本地device上的端侧大模型;即使有云计算,也会严格保密

深度定制的AI Native:可以跨应用执行

端云结合:
1、在设备上进行处理,保护个人隐私(端侧大模型),同时提供强大的智能功能。
2、私有云计算使Apple Intelligence能够扩展计算能力,同时保护用户隐私,确保数据不被存储或访问。
2)Siri重生
Siri到现在有十几年了,我自己用下来,能对话,但谈不上智能。自然感、拟人感、惊喜感,更谈不上。这次通过Apple Intelligence,Siri将变得更加自然、与上下文相关和个性化,还能支持更多功能和操作。
4月15日,斯坦福AI Index Report
斯坦福AI报告官网:https://aiindex.stanford.edu/report/
1)Top10 Takeawayes
1. 人工智能在某些任务上击败了人类,但不是在所有任务上。人工智能在几个方面已经超越了人类的表现基准,包括图像分类、视觉推理和英语理解方面的一些基准。然而,它在更复杂的任务上落后了,比如竞赛级的数学、视觉常识推理和规划。
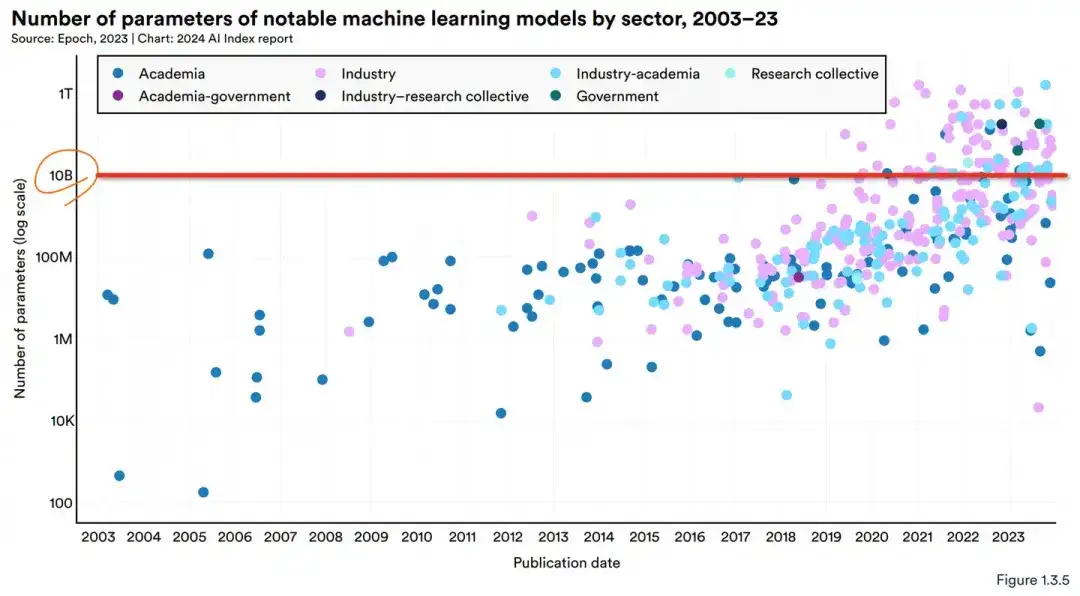
2. 工业继续主导前沿人工智能研究。2023 年,工业界产生了 51 个值得注意的机器学习模型,而学术界只贡献了15个。2023年,产学合作的知名车型也创下了21个新高。
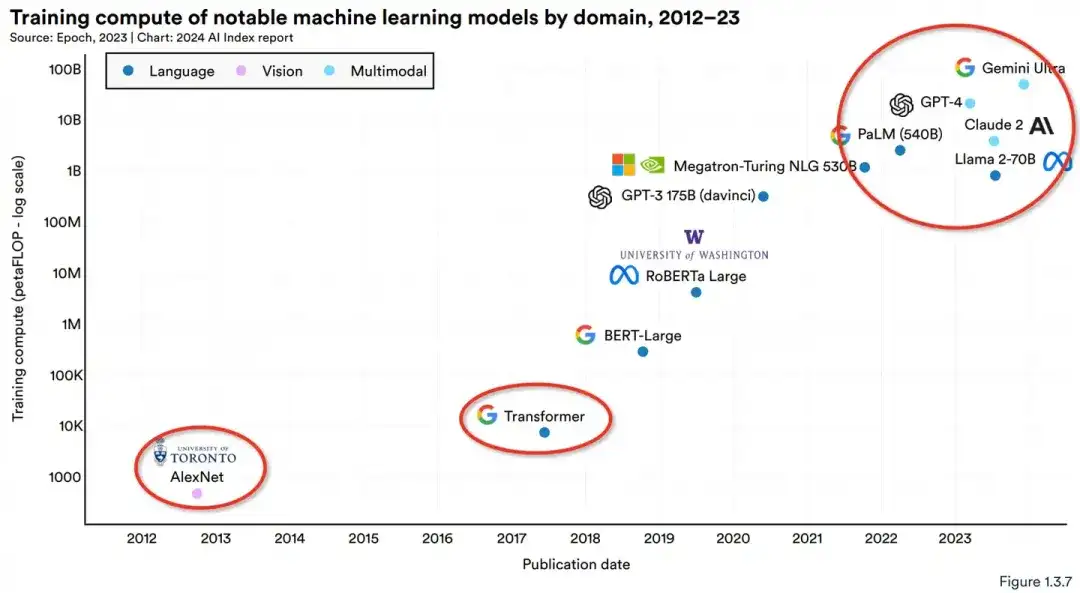
3. Frontier 模型变得更加昂贵。根据AI Index的估算,培训成本最先进的人工智能模型已经达到了前所未有的水平。例如,OpenAI的GPT-4使用估计价值7800万美元的计算来训练,而谷歌的 Gemini Ultra 的计算成本为 1.91 亿美元。
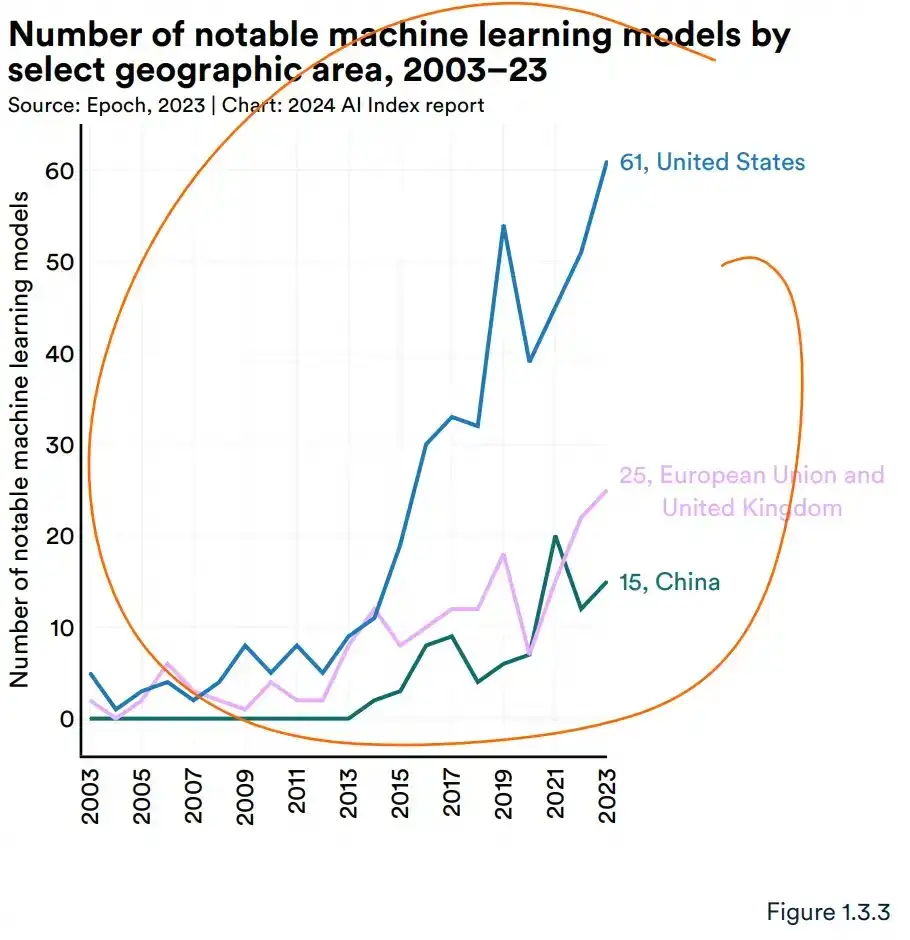
4.美国领先中国、欧盟和英国,成为顶级人工智能的主要来源模型。2023 年,有 61 个著名的 AI 模型来自美国机构,远远超过欧洲联盟有21个,中国有15个。
5. 严重缺乏对LLM责任的有力和标准化的评估。Responxible AI:人工智能指数(AI Index)的最新研究表明,负责任的人工智能报告严重缺乏标准化。包括 OpenAI、Google 和 Anthropic 在内的领先开发人员主要针对不同的负责任的 AI 基准测试他们的模型。这种做法使系统地比较顶级人工智能模型的风险和局限性的努力变得复杂。
6. 生成式人工智能投资猛增。尽管整体人工智能私人投资有所下降年,生成式人工智能的资金激增,比 2022 年增长了近八倍,达到 252 亿美元。生成式人工智能领域的主要参与者,包括 OpenAI、Anthropic、Hugging Face 和 Inflection,都报告了大量的融资轮次。
7.数据在人工智能使工人更有效率,并带来更高质量的工作。在2023 年,几项研究评估了人工智能对劳动力的影响,表明人工智能使工人能够更快地完成任务并提高他们的产出质量。这些研究还证明了人工智能在弥合低技能工人和高技能工人之间技能差距方面的潜力。尽管如此,其他研究警告说,在没有适当监督的情况下使用人工智能会导致性能下降。
8. 多亏了人工智能,科学进步进一步加速。比如Google AlphaFole 3.2022年,人工智能开始帮助科学发现。然而,2023 年推出了更重要的与科学相关的 AI 应用程序——从提高算法分拣效率的 AlphaDev 到促进材料发现过程的 GNoME。
9. 美国人工智能法规的数量急剧增加。AI美国的相关法规在过去一年和过去五年中大幅增加。2023 年,有 25 项与人工智能相关的法规,而 2016 年只有一项。仅去年一年,与人工智能相关的法规总数就增长了56.3%。
10. 全球各地的人们都更加意识到人工智能的潜在影响,也更加紧张。益普索(Ipsos)的一项调查显示,在过去的一年里,认为人工智能将在未来三到五年内极大地影响他们生活的比例从60%上升到66%。此外,52%的人表示对人工智能产品和服务感到紧张,比2022年上升了13个百分点。在美国,皮尤数据显示,52%的美国人表示对人工智能的担忧多于兴奋,高于2022年的37%。
2)一些Slide
3)AI对Economy的影响
1. 生成式人工智能投资猛增。尽管去年整体人工智能私人投资有所下降,生成式人工智能的资金激增,比 2022 年增长了近八倍,达到 252 亿美元。生成式人工智能领域的主要参与者,包括 OpenAI、Anthropic、Hugging Face 和 Inflection,都报告了大量的融资轮次。
2. 美国已经处于领先地位,在人工智能私人投资方面走得更远。2023 年,美国的人工智能投资达到 672 亿美元,是第二大投资国中国的近 8.7 倍。自 2022 年以来,中国和欧盟(包括英国)的私人人工智能投资分别下降了 44.2% 和 14.1%,而美国在同一时期经历了 22.1% 的显着增长。
3. 美国和全球的人工智能工作岗位减少。2022 年,人工智能相关职位占美国所有职位发布的 2.0%,这一数字在 2023 年降至 1.6%。人工智能职位列表的下降归因于,领先的人工智能公司的职位减少以及这些公司中技术职位的比例下降。
4. 人工智能降低成本,增加收入。麦肯锡的一项新调查显示,42%的受访者组织报告说,实施人工智能(包括生成式人工智能)降低了成本,59%的组织报告了收入增加。与上一年相比,报告成本下降的受访者增加了 10 个百分点,这表明人工智能正在推动业务效率的显着提高。
5、VC:人工智能私人投资总额再次下降,而新融资的人工智能公司数量增加。全球私人人工智能投资已连续第二年下降,但幅度不大从 2021 年到 2022 年急剧下降。新融资的人工智能公司数量激增至1,812家,比上年增长40.6%。
6. 人工智能组织的采用率上升。麦肯锡 2023 年的一份报告显示,现在有 55% 的组织在至少一个业务部门或职能中使用人工智能(包括生成式人工智能),高于 2022 年的 50% 和 2017 年的 20%。7+8. 中国在工业机器人领域占据主导地位。
- 自 2013 年超越日本成为领先的安装商以来在工业机器人方面,中国已经大大拉大了与最接近的竞争对手国家的差距。
2013年,中国的装机量占全球总量的20.8%,到2022年这一比例上升到52.4%。机器人安装更加多样化。
2017年,协作机器人仅占总数的2.8%新的工业机器人安装量,到 2022 年,这一数字攀升至 9.9%。同样,2022 年,除医疗机器人外,所有应用类别的服务机器人安装量都有所增加。这一趋势不仅表明机器人安装的整体增加,而且越来越重视部署机器人来扮演面向人类的角色。9. 财富 500 强公司开始大量谈论人工智能,尤其是生成式人工智能。2023年,在394次财报电话会议上提到了人工智能(占所有财富500强公司的近80%),比2022年的266次有显著增加。自 2018 年以来,《财富》500 强企业财报电话会议中提及人工智能的次数几乎翻了一番。在所有财报电话会议中,最常被提及的主题是生成式人工智能,占所有财报电话会议的19.7%。
二、新出现了哪些大模型?
2.1 榜单:Chat Arena
伯克利·大模型竞技场Arena:https://chat.lmsys.org/?leaderboard这里就不放结果了,大家可以自行复制链接去看。
1)首创对战模式
伯克利LMSYS组织的Chatbot Arena,至今依然是比较知名的大模型排行榜之一。采用大模型两两对战的形式,成千上万的网友,打开页面,左右对话,给出评分。https://arena.lmsys.org/
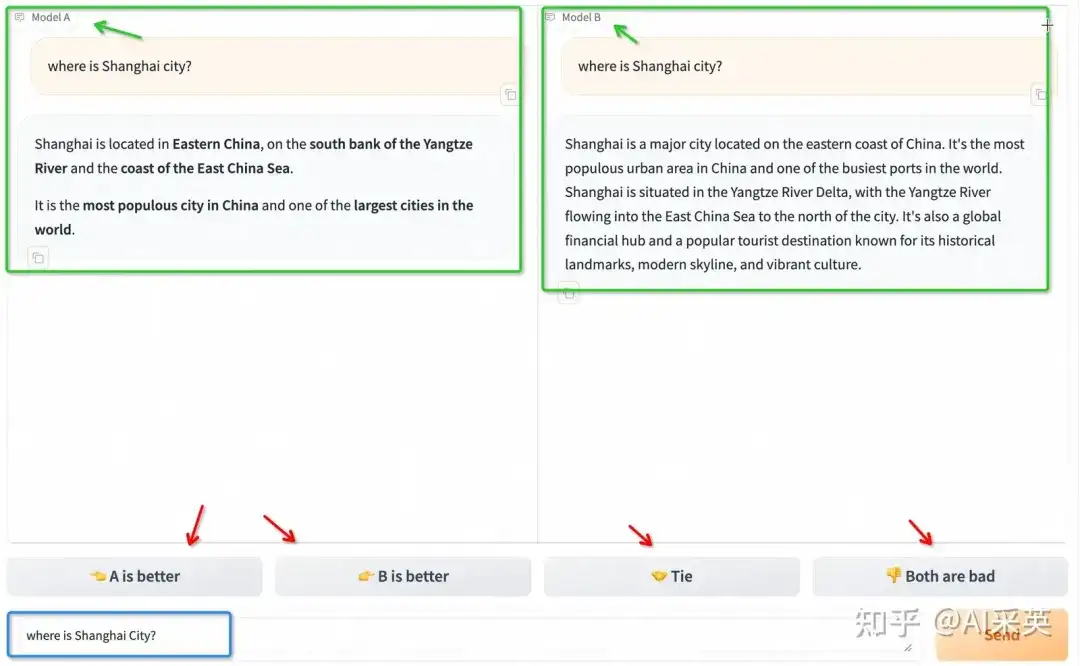
如上截图,在底部蓝框,输入prompt后;左右两个模型,同时response,绿框部分。用户点击四个按钮进行打分:A更好、B更好、两者打平、两者都不好。在每场战斗中,都会对两个匿名模型进行采样。为了鼓励数据多样性,不会在网站上预设任何输入提示。用户可以自由输入两个模型的任何提示。
它还可以帮助我们收集代表实际使用情况的各种输入。在模型提供答案后,用户将它们并排比较并投票选出首选答案。如果用户在第一回合无法选择,则用户可以继续聊天,直到确定获胜者。对于那些不确定的人,我们还提供了两个按钮,“领带”或“两者都不好”。
2)LMSYS组织
伯克利的LMSYS组织,从2023年在大模型研发、评测,有一定的影响力,做了几件事:
Timelines:
[2024/03] 发布 Chatbot Arena的技术报告
[2023/09] 发布 LMSYS-Chat-1M,一百万真实对话数据,来自于竞技场平台
[2023/08] 发布 Vicuna v1.5:基于Llama 2,上下文长度为4k/16k
[2023/07] 发布 Chatbot Arena Conversations,数据集,含有33k对话数据
[2023/08] 发布 LongChat v1.5,基于Llama 2,for 32K context lengths
[2023/06] 发布MT-bench,并发布Vicuna-1.3,有7B/33B两个版本
[2023/06] 发布 LongChat,针对LLM长上下文的Eval Tool;LongChat针对长上下文的LM评测MT-Bench评测集准,在后来的InternLM2里还用到了该评测
[2023/05] 发布Chatbot Arena,进行模型对战模式,并发布了对话dataset,从最开始的33k到1M
[2023/03] 发布Vicuna1.0(羊驼),13B,基于LLaMA-训练得到;同期,斯坦福有Alpaca
在此看下,Vicuna、Alpaca 和 LLaMA 三者,以下来自GPT-4o:
1. LLaMA
- 全称:Large Language Model Meta AI
- 开发者:Meta(原Facebook)
- 特点:LLaMA 是一个由 Meta 开发的大型语言模型,旨在提供高效和高性能的文本生成和理解能力。它是这三者中最基础的模型,为其他模型提供了基础架构和预训练数据。
2. Alpaca
- 基础:基于 LLaMA 模型
- 开发者:斯坦福大学的研究团队
- 特点:Alpaca 是在 LLaMA 模型的基础上进行了进一步微调和优化的语言模型。它通过大量的对话数据和特定任务数据进行训练,旨在提升对话系统和任务处理的性能。Alpaca 模型对一些特定的对话任务有更好的理解和生成能力。
3. Vicuna
- 基础:基于 LLaMA 和 Alpaca 模型
- 开发者:来自 UC 伯克利、卡内基梅隆大学和斯坦福大学的研究人员
- 特点:Vicuna 是在 LLaMA 和 Alpaca 模型的基础上进一步发展和优化的对话语言模型。它专注于提升对话生成任务的表现,通过优化模型结构和使用更丰富的训练数据来提高对话的流畅度和上下文理解能力。
最后总结:
- Vicuna:在 LLaMA 和 Alpaca 的基础上进一步优化,专注对话生成。
- Alpaca:基于 LLaMA 进行微调,特别针对对话系统进行优化。
- LLaMA:最基础的大型语言模型,为其他两个模型提供了基础架构和预训练模型。
总体来说,LLaMA 是基础,Alpaca 在其基础上进行了优化,Vicuna 则在前两者的基础上进行了更深度的优化和特定领域的提升。
2.2 视频生成大火
1)Sora:OpenAI
Sora炼成记-32篇Ref
这里就不展开叙述了,大家可以去看官方技术报告:https://openai.com/research/video-generation-models-as-world-simulators
Sora火了后,一大堆复现Sora

2)Open-Sora:
关键词:16秒、720p、任意宽高比伸缩性:variousdurations/resolutions/aspectratios/framerates不同宽高比:


图生视频

->

- 预训练数据:970 万视频 + 260 万图像
- 微调数据:560k 视频 + 160 万图像
Open-Sora采用多阶段训练方法,每个阶段根据前一阶段的权重继续训练。在64 个 H800 GPU 上大约 9 天。这里就不详细展开技术细节了,感兴趣的可以复制下面的链接看:
- 官方Blog:https://hpc-ai.com/blog/open-soras-comprehensive-upgrade-unveiled-embracing-16-second-video-generation-and-720p-resolution-in-open-source
- 技术报告:https://github.com/hpcaitech/Open-Sora/blob/main/docs/report_02.md
3)Vidu:清华
Vidu:(We Do) Together5月7日消息,生数科技的Vidu,登顶央视新闻联播。生数科技联合清华大学最新发布的原创自研视频大模型Vidu获得央视《新闻联播》《东方时空》《新闻30分》等多个栏目的报道,其中CCTV13《东方时空》更是对Vidu及背后研发团队进行了长达12分钟的专题介绍。Vidu生成的视频达到了16秒,并且做到了画面连续流畅,且有细节、逻辑连贯。其核心架构,是2022年9月生数科技发表的paper,提到的U-ViT架构。
技术脉络:2022年9月/U-ViT(核心架构) + 2023年3月/UniDiffuser(多模态多任务统一&U-ViT大规模验证) -> Vidu
2.3 LongCtx:更长的上下文
1)Kimi率先“卷”
在2024年3月18日,月之暗面宣布Kimi智能助手已支持200万字的超长无损上下文输入。这一突破使得Kimi成为全球首个支持如此长上下文的大模型,并且在短短五个月内从最初的20万字提升到了200万字。
可以看到上图的paper,是2022年4月OpenAI的DALL·E-2,大约27页。像这样的上传pdf做总结,单词对话内能10~20次,才会超出对话长度(200万字)。还可以单次对话内上传多个文件,跨文件间问答。
2)Gemini 1.5 Pro:1000万?
不同输入下的“大海捞针”测试:
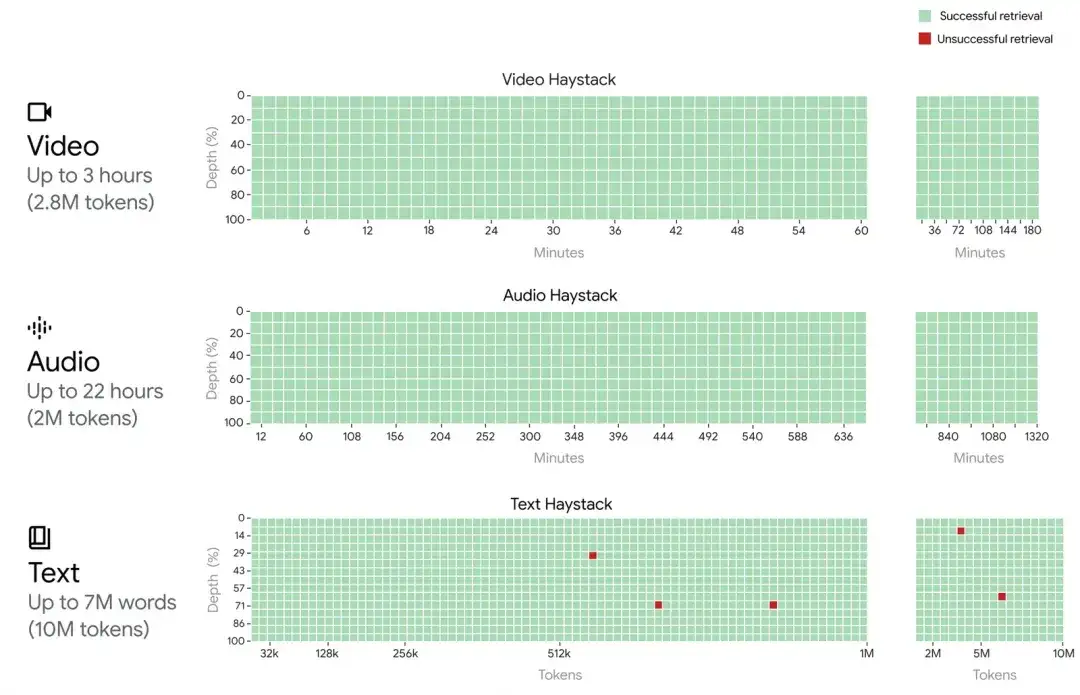
在Text输入里,实际输入的是7M,理论上到10M都基本全绿;2M的Audio,大约22hours,是全绿;2.8M的Video,大约3hours,是全绿;可以到1M,最长到10M。10M是个什么水准的长度呢?Paper里做了打比方:

3)其它模型
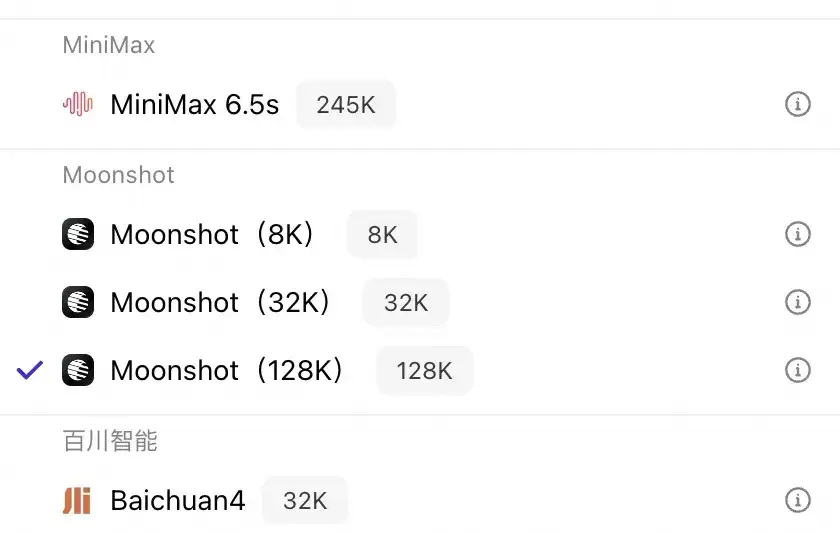
下图截自豆包Coze应用开发平台;“xx k”不代表,该模型最长上下文的模型版本,仅供参考。

2.4 MoE:多任务训练
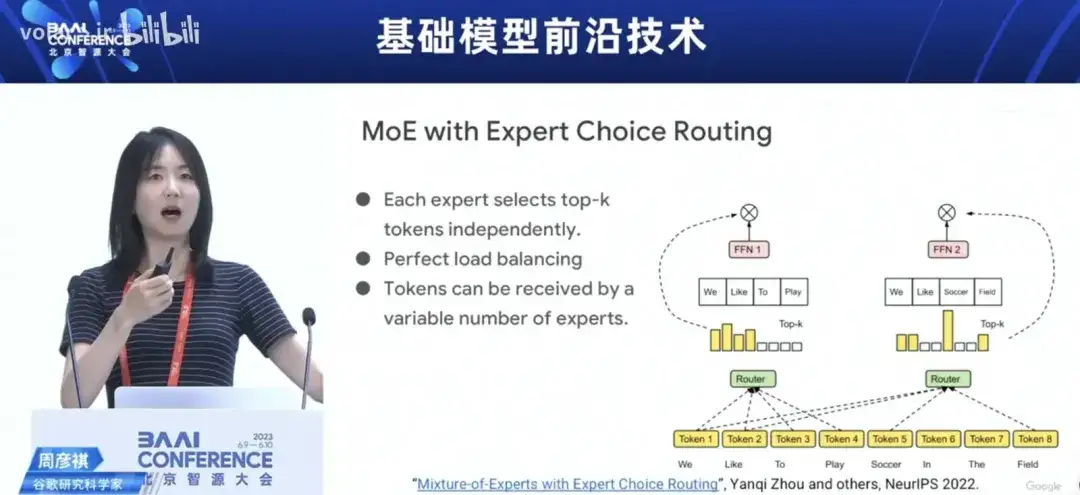
2023年6月,智源大会上,Google科学家周彦祺(T5大模型的作者,上交大毕业生),公布自己的工作方向,是大模型+多任务/MOE
2023年9月,法国AI公司Mistral,率先采用MoE架构,训练大模型

这里面的Mistral 8x7B,在infer时仅有7B的参数,打败了70B的LlaMA。2024年2月,Google发布Gemini 1.5 Pro,是个MoE模型随后,马斯克的xAI也公开宣布采用了MoE:

随后,阿里Qwen等业界诸多公司,都采用了MoE:

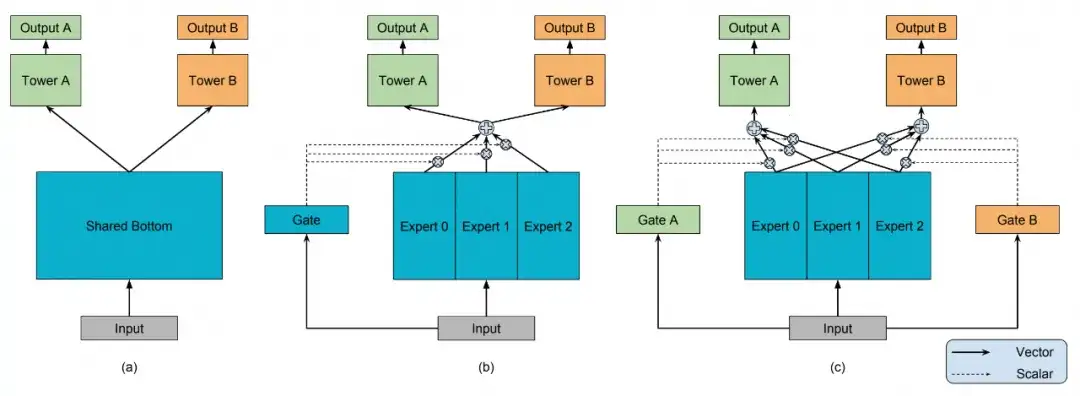
MoE训练大模型,逐渐成了一种“范式”。此外,2018年Google提出来MMoE,如下图,成为一代经典模型,在排序推荐中用到很多。阿里后来有ESMM。
2.5 合成数据
比如,微软的Phi系列。Phi黄金分割奇妙之处,在于其比例与其倒数是一样的。例如:1.618的倒数是0.618,而1.618:1与1:0.618是一样的。
- 2024年4月22日,Phi-3,有技术报告/paper
- 2023年12月,Phi-2,2.7B,1.4Ttoken,无RLHF,无paper
- 2023年9月,phi-1.5,1.3B,有技术报告
- 2023年6月,phi-1,1.3B/350M两个size,有paper
整个微软·Phi系列,一直在围绕核心命题,是:不贸然追求 size 和 data 的“参数量/数量”,而是“小而美”如何用 mini size + high quaility data,去做优秀的LLM所以微软自己宣称,做的不是“LLM”(Large LM),而是 “SLM”(Small LM)。特别是在phi-2的技术报告里,高频出现 SLM从phi-1->phi-1.5->phi-2->phi-3,核心发展趋势是:
- 数据量在指数级增长,从phi-1的7B,到phi-3的4.8T,都在高保质量
- model size在很克制地增长,但不到一个数量级,最最初的0.35B、到phi-3里的14B
还有条发展子线,就是在数据线下面,一直在倡导,合成数据synthetic data;基于人工先验知识,采用GPT-3.5/4等既有LLM,来自动化批量生成。从Phi-1到Phi-1.5里,都验证了合成数据的重要性;
Phi-1里的1B code data是合成的,Phi-1.5的20B (常识推理、NLP理解等)是合成的,都起到了第一重要。
还有个点是,phi一直是“基础”模型,即 pretrain 后的raw model;没有instruction tuning,也没有RLHF式的强行Alignment这一点,官方宣称是,为了给开源社区,更好的二次起点(更“古朴”的model开源出来,让大家发挥的空间更大)但也暗含了一个理念就是:基于TextBooks般高质的、合成的数据,已经沁入了人类专家的诸多先验知识,Pre-Train本身就完成了指令、对齐的目的,那无需再搞一个Post-Train的。
2.6 Ferret:端侧模型在崛起
苹果有个模型系列,叫雪貂,即Ferret

Timelines:
- 2024年4月23日,OpenELM:270M/450M/1.1B/3B
- 2024年4月11日,提交Ferret-v2的paper
- 2024年4月8日, 提交Ferret-UI的paper:将Ferret用于移动设备UI交互
- 2024年3月29日,ReALM:80M/250M/1B/3B,在智能设备上的对屏幕的理解和用户的响应
- 2024年3月26日,基于LLM在端侧设备上进行ASR
- 2024年3月14日,MM1大模型,30B
- 2023年12月,技术研究:LLM在DRAM有限的设备如何运行
- 2023年12月,发布Ferret的checkpoint:7B, 13B
- 2023年10月,提交ferret的code,发布Ferret-Bench.
- 2023年10月,提交Ferret Paper,即v1版:将 referring+grounding 任务融入多模态大模型中
Ferret-UI:示意图
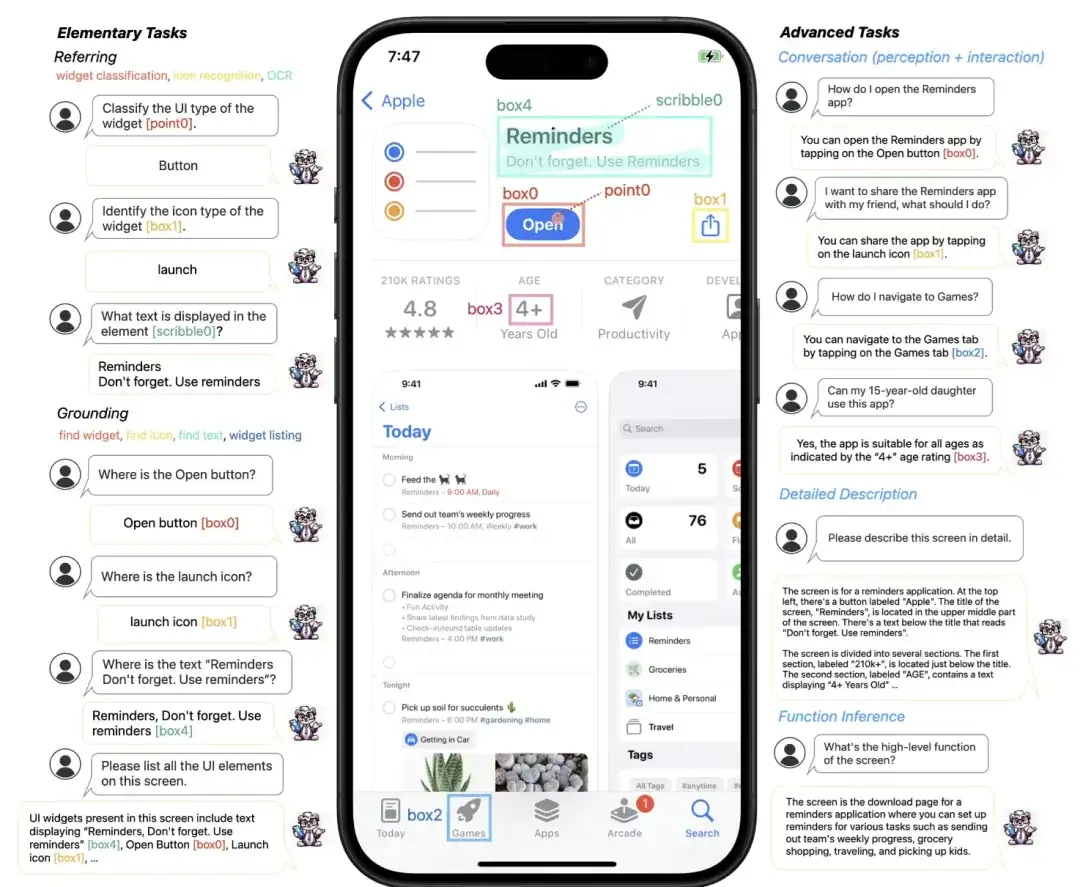
Ferret-UI能够在移动 UI 屏幕上:
- 使用灵活的输入格式(点、框、涂鸦)
- 使用grounding task(例如,查找小部件、查找图标、查找文本、小部件列表)
- 来执行referring task(例如,小部件分类、图标识别、OCR)。
这些基本任务为模型提供了丰富的视觉和空间知识,使其能够在粗略和精细级别(例如各种图标或文本元素之间)区分 UI 类型。
这些基础知识对于执行更高级的任务至关重要。
具体来说,该模型不仅能够在详细描述和感知对话中讨论视觉元素,还可以在交互对话中提出面向目标的动作,并通过功能推理推断出屏幕的整体功能。
Ferret-UI:模型结构

Ferret-UI-anyres 包含额外的细粒度图像功能。
1、预训练的图像编码器和投影层为整个屏幕生成图像特征。
2、对于基于原始图像长宽比获得的每个子图像,都会生成额外的图像特征。
3、对于具有区域参考的文本,视觉采样器会生成相应的区域连续要素。该LLM使用全图像表示、子图像表示、区域要素和文本嵌入来生成响应。
2.7 国内代码模型有点猛
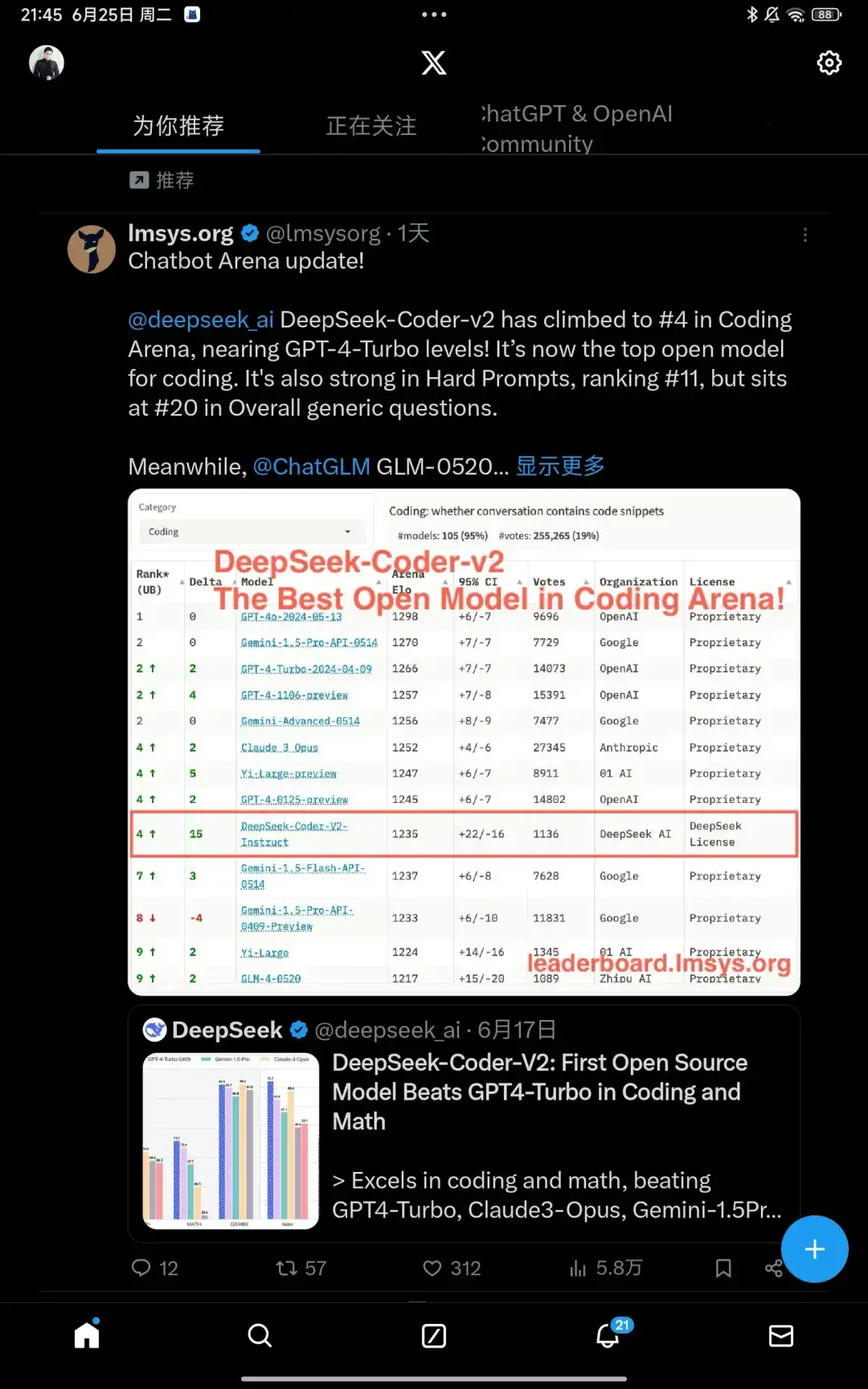
来看DeepSeek-Code-V2:
- 开源Mixture-of-Experts (MoE)模型:通过进一步预训练,达到了与闭源模型(如GPT4-Turbo)在代码特定任务上相当的性能。
- 从DeepSeek-V2的中间检查点开始,额外预训练了6万亿个token(就是6T),增强了DeepSeek-V2在编码和数学推理方面的能力,同时保持了在通用语言任务上的性能。
- 支持多种编程语言:对编程语言的支持,从86种增加到338种,这大大扩展了模型的适用范围。
- 上下文长度从16K扩展到128K,使得模型能够处理更复杂和广泛的编码任务。
- 标准基准测试中的优越性能:在编码和数学基准测试中,DeepSeek-Coder-V2展示了比闭源模型更优越的性能。
- 数据集构建:数据集包括60%的源代码、10%的数学语料库和30%的自然语言语料库,这些数据集经过精心筛选和清洗。
Timelines:

另, 其它代码模型简介如下:
- Meta的LLaMA系:
- CodeLlama:基于 Llama2 的代码语言模型组成,并在 500 至 10000 亿个代码token的数据集上继续进行预训练。这些型号有四种尺寸:7B、13B、34B 和 70B。
- BigCode出品,(BigCode社区是由ServiceNow和HuggingFace共同管理)
- StarCoder:一个可公开访问的模型,拥有 150 亿个参数。它经过精心策划的 Stack 数据集子集的专门训练,涵盖 86 种编程语言。
- StarCoder2:由 3B、7B 和 15B 参数模型组成,这些模型在 Stack2 数据集的 3.3 至 4.3 万亿个token上进行训练,涵盖 619 种编程语言。
- 幻方量化出品:
- DeepSeek-Coder:包含一系列代码语言模型,参数范围从 10 亿到 330 亿不等。每个模型都在 2 万亿个 token 上从头开始训练,其中 87% 是代码,13% 是英文和中文的自然语言。这些模型使用 16K 窗口大小和额外的填空任务在项目级代码语料库上进行预训练,从而支持项目级代码补全和填充。
- Mistral出品:
- Codestral:22B 参数模型。它接受了超过 80 种编程语言的多样化数据集的训练,包括 Python、Java 和 JavaScript 等流行语言,以及 Swift 和 Fortran 等更专业的语言。官博在这里:https://mistral.ai/news/codestral/
……
2.8 通义千问超越GPT-4
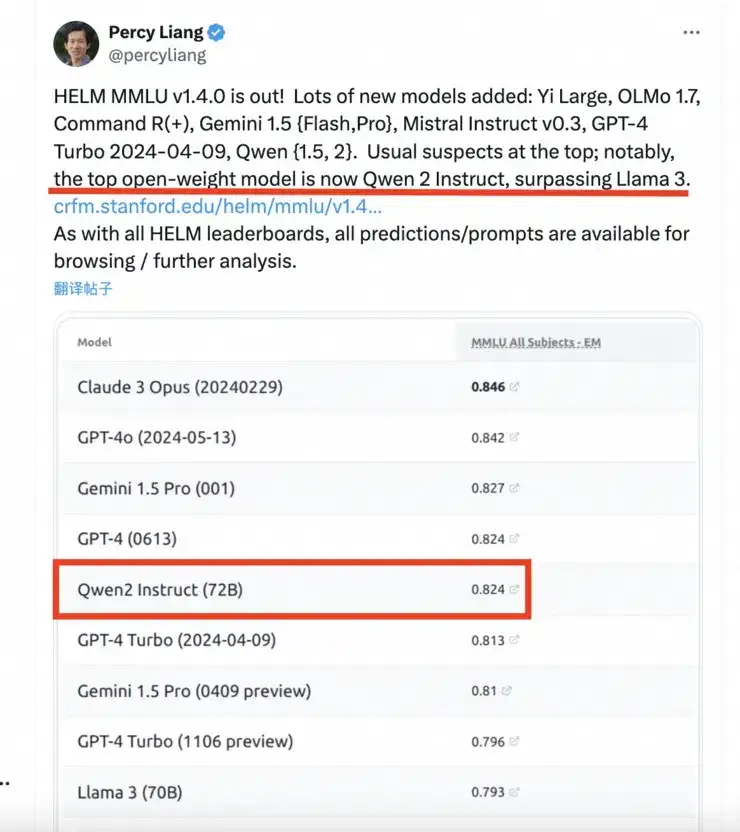
6月20日,斯坦福大学的大模型测评榜单HELM MMLU发布最新结果,斯坦福大学基础模型研究中心主任Percy Liang发文表示,阿里通义千问Qwen2-72B模型成为排名最高的开源大模型,性能超越Llama3-70B模型。
2.9 国内大模型价格战
5月,Deepseek、智谱、豆包通义千问、百度等纷纷降价,大模型价格战进入白热化阶段!降价后,1块钱就能让大模型写1万条350个字的小红书,或者读三本《三国演义》,还有开发者表示送的token都用不完,充50块钱能用好几年。只要模型质量不降低,降价对于用户来说还是非常利好的,还能带动新一波的AI应用创业。
三、应用一瞥
3.1 应用开发:AI Studio
1)字节·扣子Coze
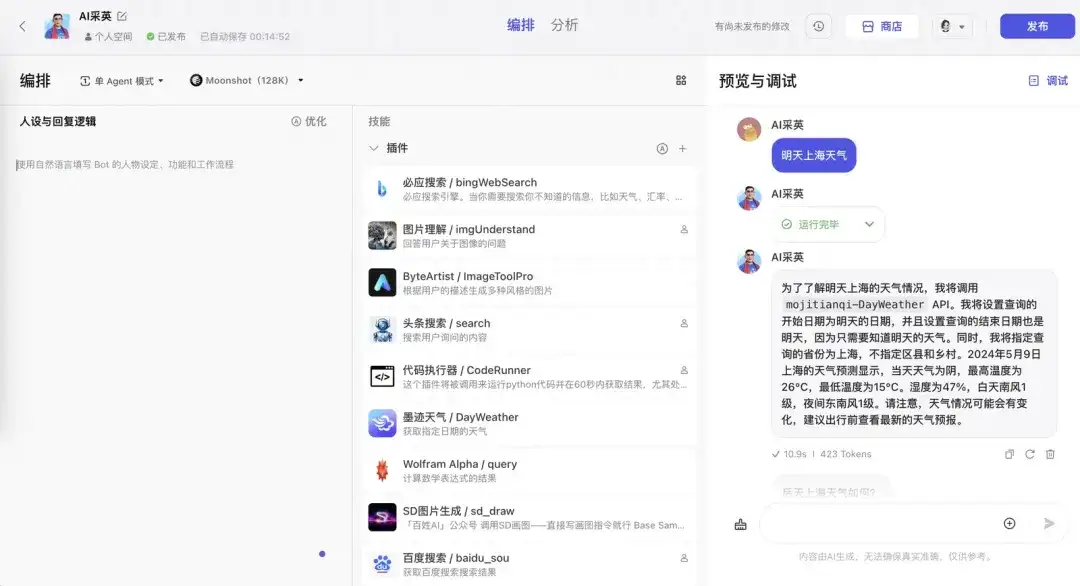
2)Goole AI Studio
https://aistudio.google.com/app/prompts/new_chat
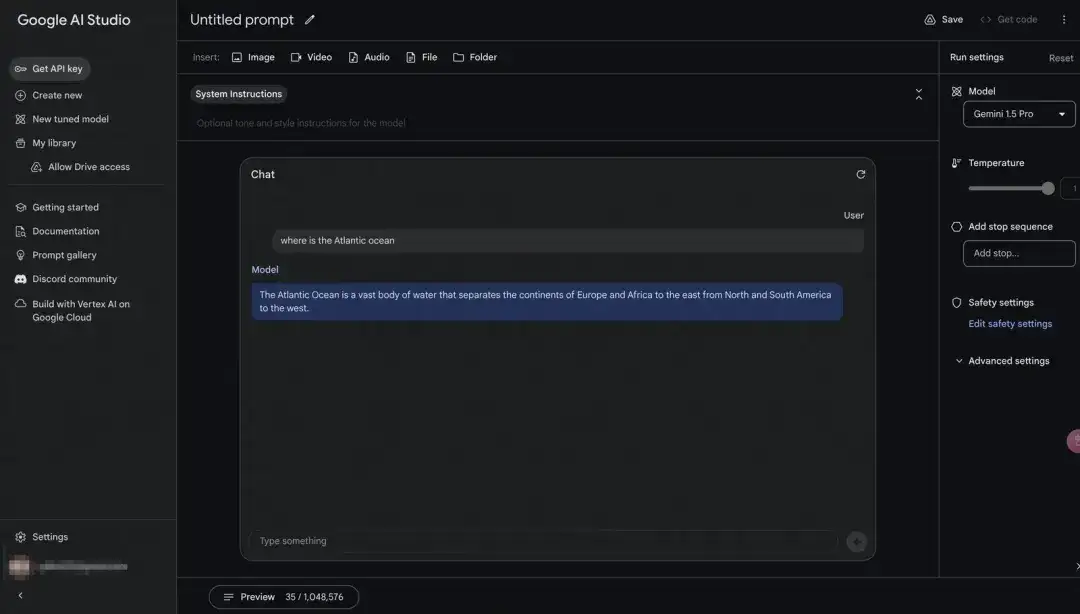
3)微软Azure Studio
这有篇ATA教程:https://grow.alibaba-inc.com/course/4800016717248449官网:https://azure.microsoft.com/en-us/products/ai-studio
3.2 典型AI Demo
部分AI APP示意

PC端web playground
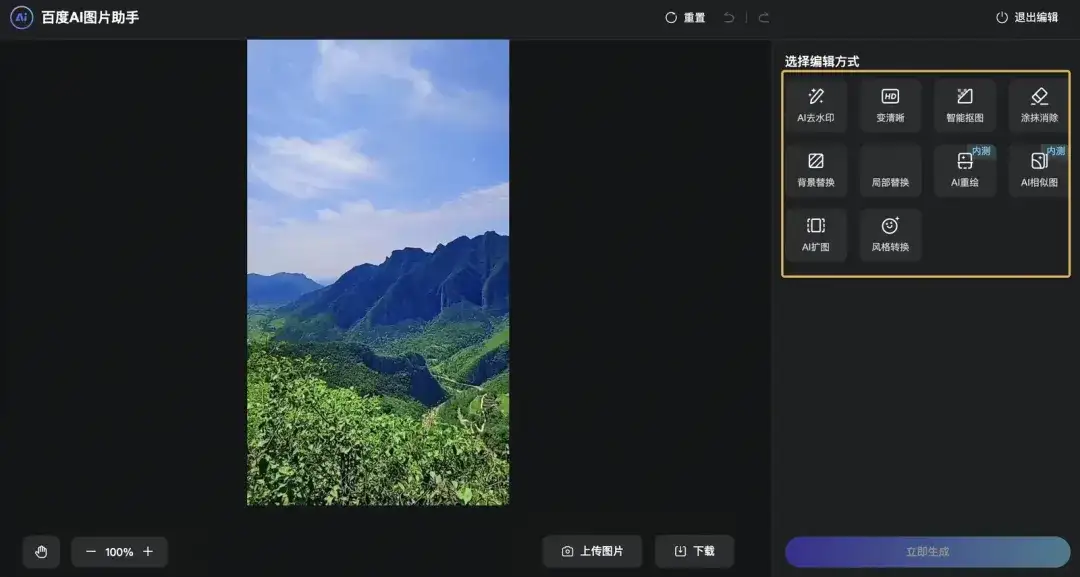
百度AI图片助手
Kimi & 腾讯元宝
Kimi:号称一次性可以读200万字至1,000万字的文章
元宝:可支持单文档最长1000万字的超长文处理,能够一次性解析最多50个文件(单个文件<=100M)
AI手机
Vivo在2023年11月发布了蓝心大模型,Apple iOS18后,Macbook上,都会有端模型。
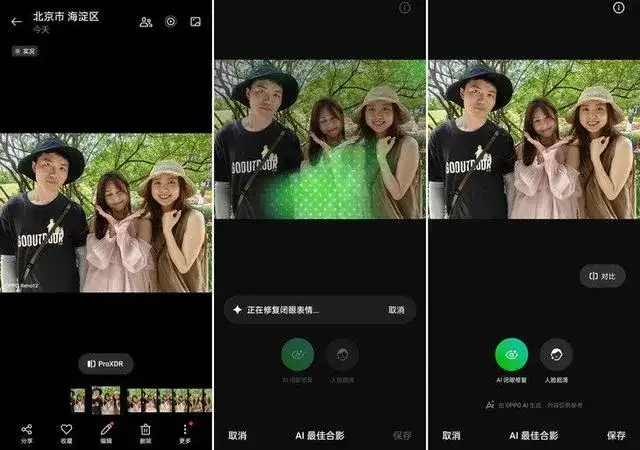
OPPO Reno12:
闭眼修复:
小布助手:
图/文生视频·可灵大模型
6月,可灵大模型的文生视频功能在快影App开启内测,后续又上线图生视频和视频续写功能,不仅在国内掀起一波试用的热潮,还「馋哭」了一众外国网友。
延伸讨论
4.1 Sora能代表物理世界吗?
1)对Sora的质疑
首先,Sora定位自视很高,原标题是:“Video generation models as world simulators”但是,Yann LeCun是不信的,顺便介绍了一波Meta自己的JEPA联合表征架构;JEPA自己不是视频生成;
weibo 张俊林 大神于2.27日的文章,进行了更深度的讨论:
https://weibo.com/ttarticle/x/m/show/id/2309405005949600661553
另,如果Sora的数据中,采用游戏仿真器,进行了数据生成,并基于它们进行了训练,那么,这是间接地具备了一定的模拟能力。未来有一定可能性,或许可以通过结合不同技术,如GPT-4和Sora,来互补各自的能力,共同构建出一个世界模型。
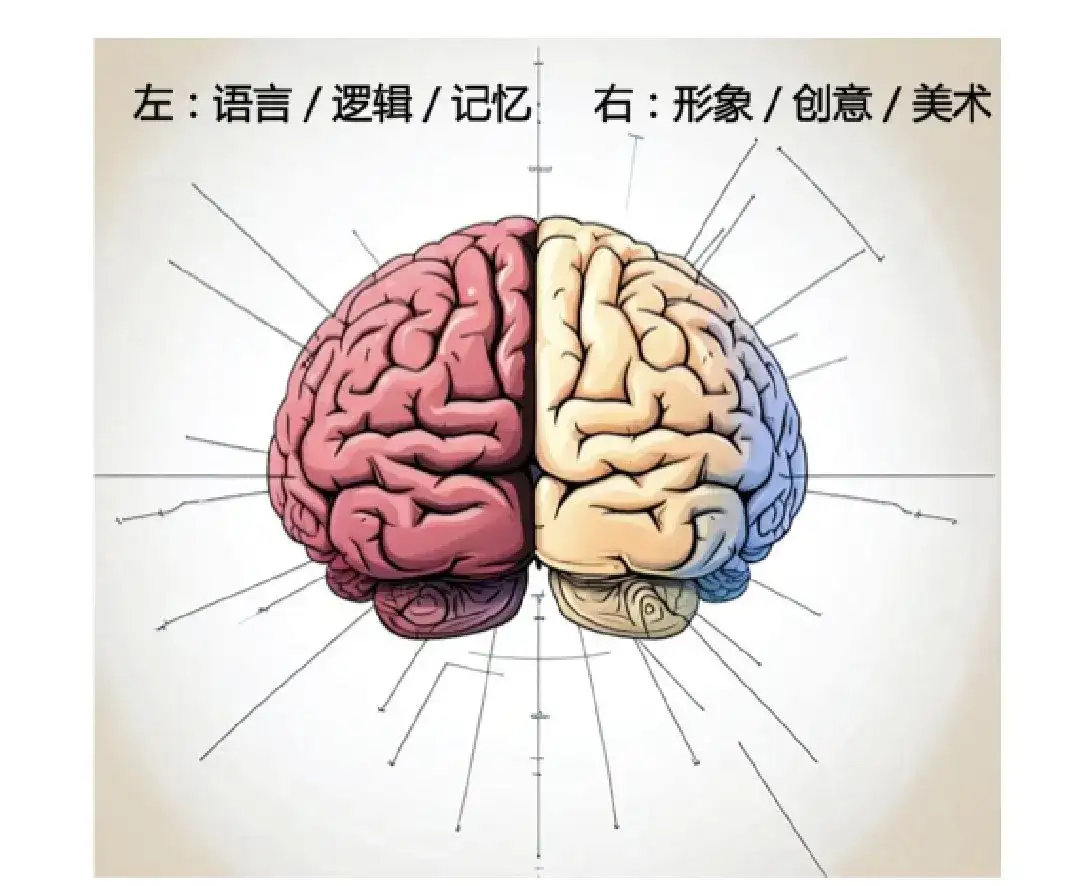
例如,Apple Vision Pro加上GPT-4和Sora的组合可能会创造出一个用户可以自由体验不同世界的系统。图片/视频模型和LLM像是大脑的右脑和左脑,分别负责形象思维和抽象思考。共同实现对复杂世界的共同理解和生成。如下图:
2)Genie:“建模世界”的一种探索
另外,Google发布的Genie也一定程度佐证了未来“物理世界模拟器”实现的可能性。

模型结构:
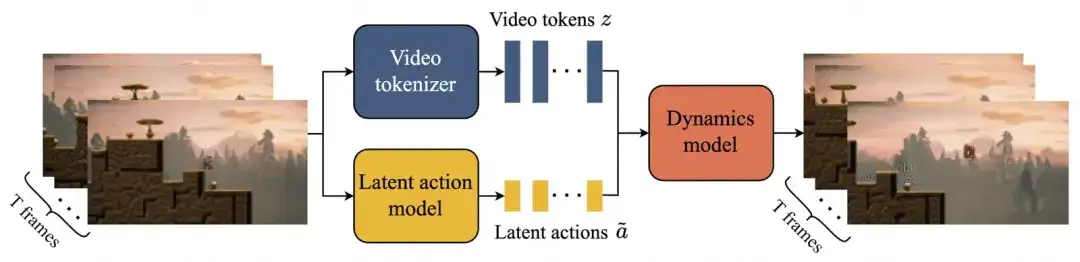
由三部分组成:1、Video Tokenizer:将原始视频帧转换为离散标记
2、Latent Action Model:用于推断每对帧之间的潜在动作
3、Dynamics Model:根据潜在动作和过去的帧标记,预测视频的下一帧
4.2 大模型为啥不善于做数学题?
几个原因如下:
1)早期Tokenizer对数字切分粒度问题
经常把连续的若干数字切在一起形成一个Token,比如“13579”,可能被切成三个Token ,“13”是一个,“57”是一个,“9”是一个Token从LLama-1开始,对数字做最细粒度的切分了,原文是这么说的:
2)输入LLM时,数字高低位顺序问题
数字计算,是从低位计算,逐步向高位进位计算的。这会产生两个问题:
a. 计算难度增加
但输入LLM,通常是高位在前、低位在后;倒不是说这样不行,而是,增加了LLM做计算题的难度如果你按照“13579+24680=”顺序输入给LLM,Next Token就要求先输出计算结果的最高位,这意味着LLM必须在内部把完全正确的加法结果38259算完,而且得找地方存起来,然后再先输出高位3,再输出次高位8(这种类似想好了再说)….
b. 计算效率也不高
参考:https://www.zhihu.com/question/605567747/answer/3441552623以56*123=6888为例,每一次模型迭代,等同于10次小的迭代的相加:可以看出,前5次迭代,对于得到 6888 这个结果而言,没有直接帮助。那是否可以跳过这几次infer呢?跳过后,速度是变快了,但依然不会助于,提高计算复杂数学题的准度。
3)对应数位难以准确对齐
LLM在做数学运算的时候,经常对不齐相应位置的数字,比如“13579+24680”,3本来应该对齐4,但是LLM经常把3对到4附近的数字,解决办法是:
1、加入位置提示(Hint)比如“13579+24680”,每个位置加入提示字符,形成“a1b3c5d7e9+a2b4c6d8e0”这种输入形式,相同位置数字有个共同的提示字符,这很可能利用了Induction Head的作用(我猜的),可以有效帮助LLM对齐数字。
2、对每个数字Chunk单独引入新的位置编码(Abacus Embedding)对于每个数字块,第一个字符引入位置编码1,后续数字依次递增。这样,因为相同位的数字有相同的位置编码,所以有利于解决LLM数字对不齐的问题。如下图:
4)数字较长时,LLM外推差
数学计算的特点是:
1、逻辑缜密,没有模糊的空间,答案是标准化的;这意味着,数理逻辑,不同于人们的 自然语言逻辑和惯性,所以LLM面对数学计算,泛化性会有边界,
2、问题空间&解的空间,是天文数量级的;而人类语料(目前GPT训练语料,大多是人们日常活动/行为产生的语料),不可能覆盖到所有的长度、计算问题。由上,产生了一个子问题是:经由短序列数字训练的GPT,不容易直接泛化到长序列的数字计算。
说人话就是:我们在训练LLM的时候,LLM见过的最长的数字串长度是10位,但实际使用的时候,若给出20位长度的数字要求做加法,就容易算错俊林大神提到了FIRE和abacus emb两种位置编码,大致原理是:如果训练语料,只能是较短的数字,那么,我们位置编码,可以不从1开始呀。。。我从51、67、98开始,递增编码就是了,这样,我的位置编码的取值空间,是可以突破训练样本的限制的,至少能自己骗自己一把。这几种位置编码,下文详读。
5)大模型幻觉
GPT生成自然语言,还有幻觉/错误率呢,更何况要求贼精确的数字?而且,生成自然语言,幻觉其实不易发现;但计算数学题,生成数值型答案,正确vs错误之间,没有模糊的空间。所以,模型生成错了,一眼就看出来了,进而得出“大模型不擅长数学题”的结论。简而言之,大模型算数学题,错就是错了,躲无可躲,就会给人留下差印象。
4.3 展望AG
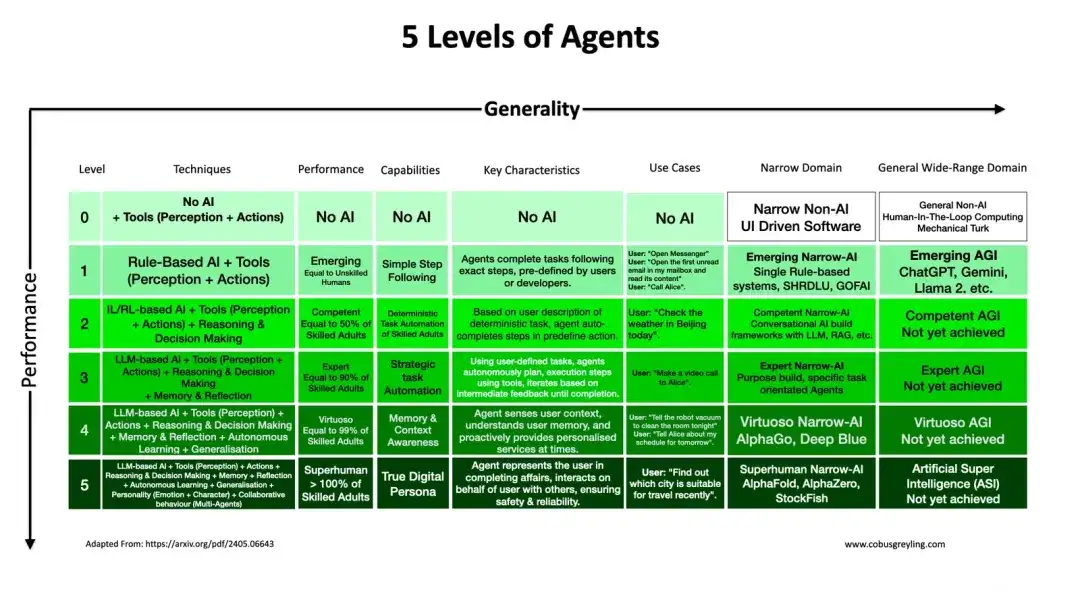
1)AI Agent的5个层次
原文:https://cobusgreyling.substack.com/p/five-levels-of-ai-agents

2)对AGI审视
原文:UIUC的综述:https://arxiv.org/pdf/2405.10313对AGI Internal的期待:
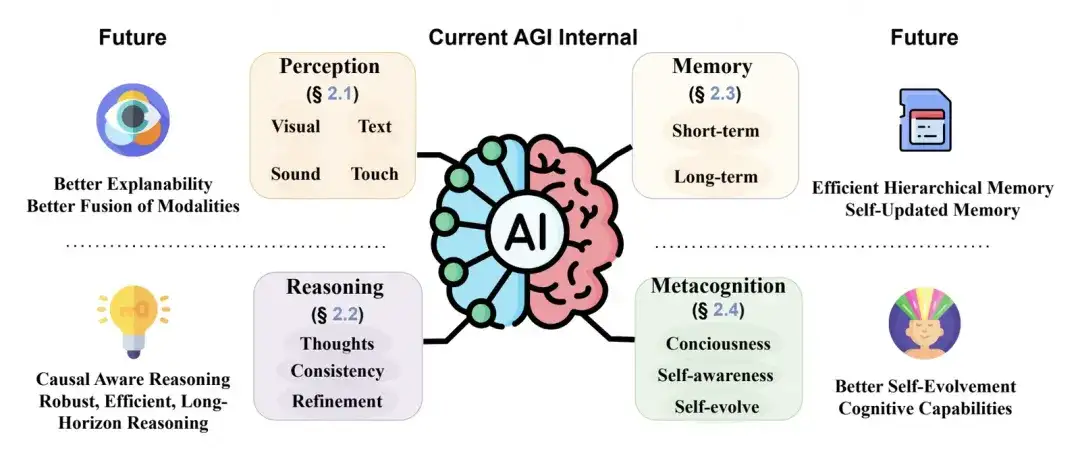
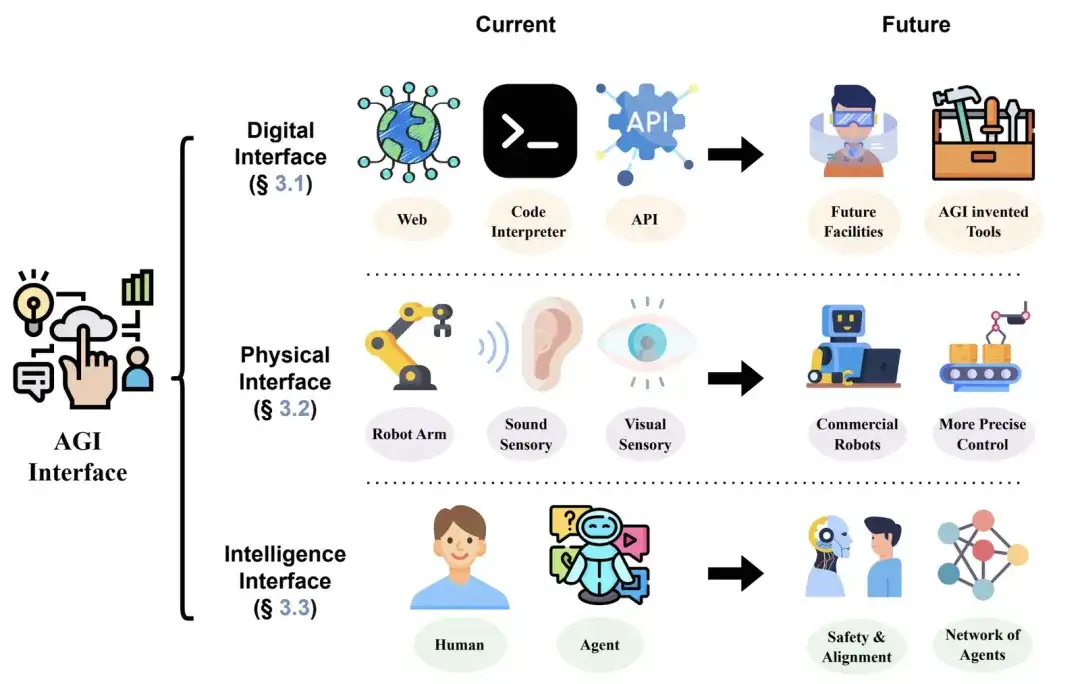
AGI与外部物理世界的连接姿势:
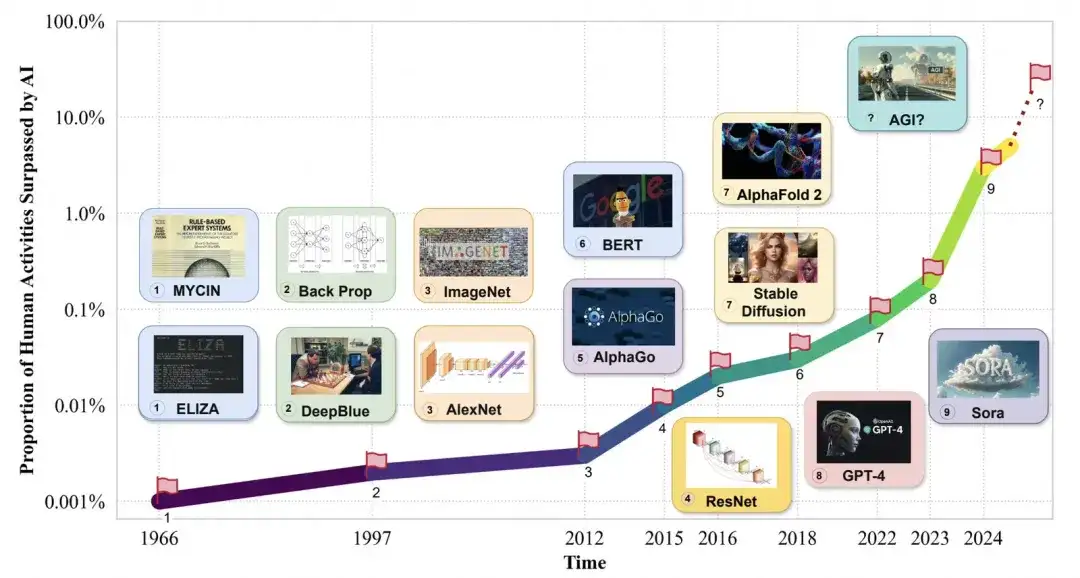
AGI在逐渐赶超人类:
五、AI应用之我见
命题很大,我没有很体系化的思考,就几个碎片,暂抛出来:
1、AI和搜索
有篇文章,不是取代的关系,未来会持续并存;而且,短期内,搜索占比依然是大头。纯Online应用中,目前看来,除了AIGC/多模,那GPT跟搜索的关系,是最近的。这里有篇,讲述了两者相互渗透的关系:https://arxiv.org/abs/2407.001281、Search-for-LLM
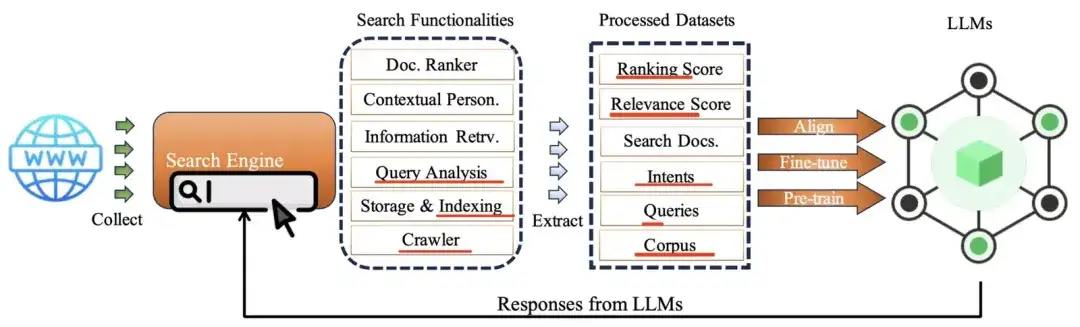
2、LLM-for-Search
2、具身智能
具身智能,目前被Robot行业深度绑定一方面,中国是世界工业机器人装机量top1,远超美国和日本,这体现了工业制造的实力;另一方面,很多具身智能是被“人形机器人”用的较多,LLM作为Robot的大脑,发挥大模型规划推理的能力。上海WAIC大会上,也有很多机器人展台。如下图是Tesla Optimus:

但坦白讲,人形机器人的使用价值,还没那么大;产业还在技术研发阶段。
3、AI+业务流程
现有业务框架内,本身有很多SOP(Standard Operation Procedure)业务流程,直接把LLM嵌入到里面来,是比较现实的方案。一方面,LLM/AIGC大模型,本身只是一个“点”,另一方面,不用大幅度改造太多原有的流程,风险最小。如果不是这样,而是为了LLM,去创新新的架构、流程,那难度大得多,属于“以点带线/面”。大模型作为“点”,可以涌现井喷式的出现,但新架构出现不是一日之功。
4、Chat对话,人机交互新模式
LLM大模型的next-token输出形式,天然是有利于对话的。以至于,Chat深深地跟大模型绑定,很多大模型底座,都会同时发布xx-chat版本。从传统的搜推来看,用户的交互轮数比较少,推荐是用户被动式的,搜索时用户虽然主动,但多次搜索之间用户没有上下文连贯感。
从互动交互的视角来看,大模型当做前置的意图理解、推理规划、多轮上下文融合,是solid的,毋庸置疑。如果落地没有收益,不是这几个技术定位有问题,而是在上层整理、场景选择层面不够准确,甚至只是缺少打磨而已。毕竟,我们做一个产品,急着要产出,耐心很少的。
5、手机AI化/端模型
类比原有的Compute发展,有超大的计算机/计算中心,也有较小的计算机,比如手机/PC等。我个人觉得,LLM model size,也会走向两个阶段,反而不存在中间态。具体来讲,100B以上的模型、10B以下模型,会成为主流。10B以下的模型,依然会需要:1、它们并不弱,具体请见微软Phi系列model2、它们很被需要,比如端侧。LLM走向手机端,更AI Native,这本就是去年就有的概念,目前很多业界,手机厂商,已经在大肆AI化中。这里多说一嘴,手机端AI,去年有很多,是AIGC,即针对拍照照片,进行美化处理,此不赘述。那从今年开始,会出现很多,AI Native的应用,这里面GPT主导,结合多模态理解。纯UI的模型,比如苹果的Ferret系列,已经有了。
6、内容生成
这里指的是,图片、视频、语音等,狭义的AIGC。其实广义的AIGC,是包括GPT文本生成的。回到这几种模态,我个人觉得,他们不同于LLM:LLM生成的本质,是“序列/组织”AIGC生成的本质,就是“内容”,字面意思。虽然它们序列、二维、多维,但是内容。两者是两回事儿,分开看,就清晰多了。
AIGC生成图片视频,在业务场景比较solid,基本上是需求驱动,或者产出后可以直接落地,取得经济收益。做的工作,适合项目制,逐个项目、逐个需求、逐个场景。当然,在技术层面,很多技术栈是通用共用的。但从顶层看,我觉得未必强制用“一盘棋”去看,而是用“百花齐放”去看更合理些。每朵花的差异性,大于共性。也不是一个model能搞定的。
“可信 AI 进展 “ 公众号致力于最新可信人工智能技术的传播和开源技术的培育,覆盖大规模图学习,因果推理,知识图谱,大模型等技术领域,欢迎扫码关注,解锁更多 AI 资讯~


















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









