







如何自学黑客&网络安全
黑客零基础入门学习路线&规划
初级黑客
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
8、超级黑客
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。
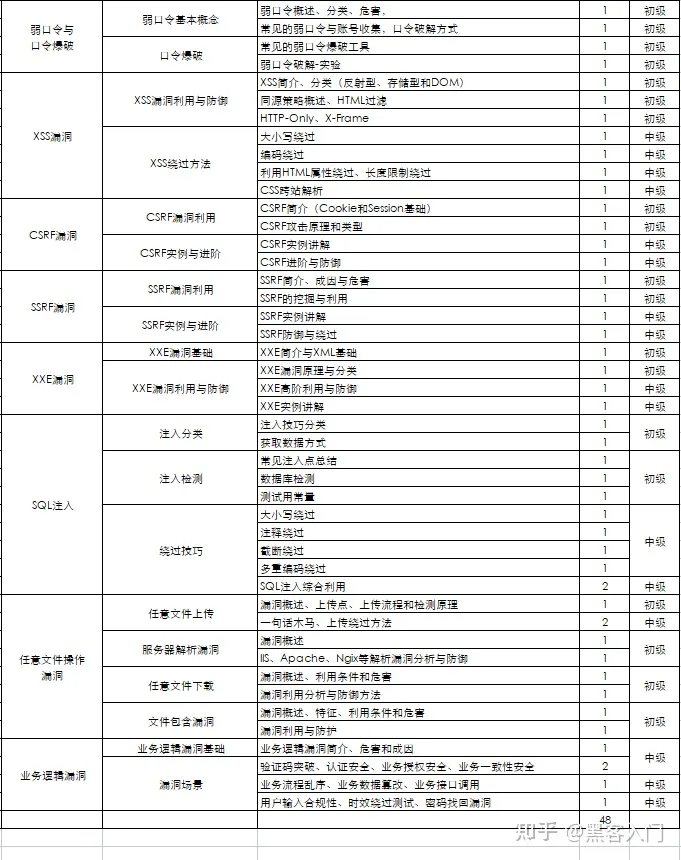
网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
{
"detector\_backend": "opencv",
"distance": 0.2260340280992379,
"facial\_areas": {
"img1": {
"h": 769,
"w": 769,
"x": 345,
"y": 211
},
"img2": {
"h": 779,
"w": 779,
"x": 318,
"y": 534
}
},
"model": "Facenet",
"similarity\_metric": "cosine",
"threshold": 0.4,
"time": 5.2,
"verified": True
}
由于使用的模型不同,结果跟图片中的不完全一致:

2.4 Face recognition
人脸识别需要多次进行人脸验证。在这里,deepface有一个开箱即用的查找函数来处理这个动作。它将在数据库路径中查找输入图像的身份它将返回pandas数据帧列表作为输出。同时,人脸数据库中的人脸嵌入被存储在pickle文件中,以便下次快速搜索。结果将是出现在源图像中的脸的大小。此外,数据库中的目标图像也可以有多个人脸。
dfs = DeepFace.find(img_path = "img1.jpg", db_path = "C:/workspace/my\_db")
# 使用源码里的测试图片
dfs = DeepFace.find(img_path="tests/dataset/img1.jpg", db_path="tests/dataset/", model_name="Facenet")
结果数据,facenet_cosine越小相似度越高:
[ identity source_x ... source_h Facenet_cosine
0 tests/dataset//img1.jpg 345 ... 769 0.000000
1 tests/dataset//img11.jpg 345 ... 769 0.184640
2 tests/dataset//img7.jpg 345 ... 769 0.193672
3 tests/dataset//img10.jpg 345 ... 769 0.221339
4 tests/dataset//couple.jpg 345 ... 769 0.226034
5 tests/dataset//img6.jpg 345 ... 769 0.230715
6 tests/dataset//img2.jpg 345 ... 769 0.242570
7 tests/dataset//img4.jpg 345 ... 769 0.246557
8 tests/dataset//img5.jpg 345 ... 769 0.259066
[9 rows x 6 columns]]

2.5 Embeddings
人脸识别模型基本上是将人脸图像表示为多维向量。有时候,你直接需要这些嵌入向量。DeepFace带有专门的表示函数。标识函数返回嵌入列表。结果将是出现在图像路径中的面的大小。
embedding_objs = DeepFace.represent(img_path = "tests/dataset/img1.jpg")
# 实际测试
embedding_objs = DeepFace.represent(img_path="tests/dataset/img1.jpg", model_name="Facenet")
结果数据,:
[
{
"embedding": [
0.8134615421295166,
1.0957121849060059,
1.477981686592102,
-1.6971195936203003,
0.49749791622161865,
-0.6081872582435608...[省略了一些数据]
],
"face\_confidence": 10.068783960014116,
"facial\_area": {
"h": 769,
"w": 769,
"x": 345,
"y": 211
}
}
]
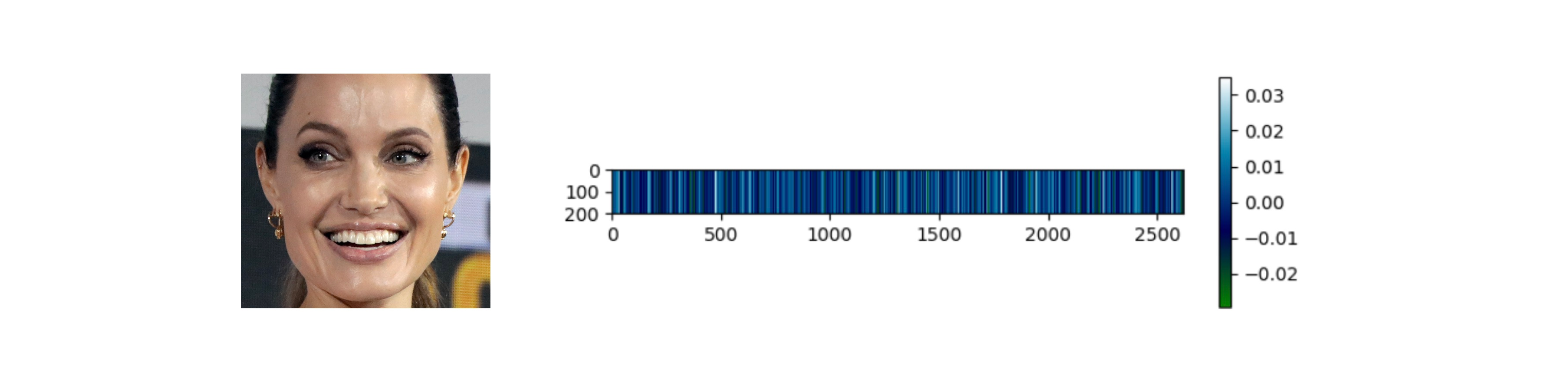
这个函数返回一个数组作为嵌入。嵌入数组的大小将根据模型名称而有所不同。例如,VGG-Face是默认模型,它将面部图像表示为2622维向量。
embedding = embedding_objs[0]["embedding"]
assert isinstance(embedding, list)
assert model_name = "VGG-Face" and len(embedding) == 2622
# 实际测试
embedding = embedding_objs[0]["embedding"]
assert isinstance(embedding, list)
assert len(embedding) == 128
在这里,嵌入也是用2622个槽水平绘制的。每个槽对应嵌入向量中的一个维度值,维度值在右侧的颜色条中进行说明。与2D条形码类似,垂直维度在插图中不存储任何信息。
2.6 Face recognition models
Deepface is a hybrid face recognition package. It currently wraps many state-of-the-art face recognition models: VGG-Face,Google FaceNet, OpenFace, Facebook DeepFace, DeepID, ArcFace, DlibandSFace. The default configuration uses VGG-Face model.
models = ["VGG-Face", "Facenet", "Facenet512", "OpenFace", "DeepFace", "DeepID", "ArcFace", "Dlib", "SFace"]
# face verification
result = DeepFace.verify(img1_path = "img1.jpg",
img2_path = "img2.jpg",
model_name = models[0]
)
# face recognition
dfs = DeepFace.find(img_path = "img1.jpg",
db_path = "C:/workspace/my\_db",
model_name = models[1]
)
# embeddings
embedding_objs = DeepFace.represent(img_path = "img.jpg",
model_name = models[2]
)
# 这些跟前边的一样 不再进行实测
FaceNet, VGG-Face, ArcFace and Dlib are overperforming ones based on experiments. You can find out the scores of those models below on both Labeled Faces in the Wild and YouTube Faces in the Wild data sets declared by its creators.
| Model | LFW Score | YTF Score |
|---|---|---|
| Facenet512 | 99.65% | - |
| SFace | 99.60% | - |
| ArcFace | 99.41% | - |
| Dlib | 99.38 % | - |
| Facenet | 99.20% | - |
| VGG-Face | 98.78% | 97.40% |
| Human-beings | 97.53% | - |
| OpenFace | 93.80% | - |
| DeepID | - | 97.05% |
LFW Score和YTF Score是两种用于评估人脸识别算法性能的指标,分别基于LFW和YTF两个数据集。LFW(Labeled Faces in the Wild)是一个包含超过13,000张带有人名标注的人脸图像的数据集,这些图像来自互联网上不同的人脸图库,涵盖了各种人种、姿态和表情。YTF(YouTube Faces)是一个包含3425个视频的人脸视频数据集,这些视频来自YouTube上1595个不同人的视频,涉及大量的姿态、表情、光照和遮挡变化。LFW Score和YTF Score分别使用LFW和YTF数据集中的匹配对和不匹配对来测试人脸识别算法是否能够正确判断两张人脸是否属于同一个人。一般来说,LFW Score和YTF Score越高,表示人脸识别算法越准确。
2.7 Similarity
人脸识别模型是正则卷积神经网络,它们负责将人脸表示为向量。我们认为同一个人的两张脸应该比不同人的两张脸更相似。相似度可以通过余弦相似度、欧氏距离和L2形式等不同度量来计算。默认配置使用余弦相似度。
metrics = ["cosine", "euclidean", "euclidean\_l2"]
#face verification
result = DeepFace.verify(img1_path = "img1.jpg",
img2_path = "img2.jpg",
distance_metric = metrics[1]
)
#face recognition
dfs = DeepFace.find(img_path = "img1.jpg",
db_path = "C:/workspace/my\_db",
distance_metric = metrics[2]
)
# 实际测试
# face verification
result = DeepFace.verify(img1_path="tests/dataset/img1.jpg",
img2_path="tests/dataset/img2.jpg",
model_name="Facenet",
distance_metric=metrics[1]
)
# face recognition
dfs = DeepFace.find(img_path="tests/dataset/img1.jpg",
db_path="tests/dataset/",
model_name="Facenet",
distance_metric=metrics[2]
)
前面的cosine距离是0.24256996744273296:
{
"detector\_backend": "opencv",
"distance": 8.146639638611239,
"facial\_areas": {
"img1": {
"h": 769,
"w": 769,
"x": 345,
"y": 211
},
"img2": {
"h": 512,
"w": 512,
"x": 516,
"y": 192
}
},
"model": "Facenet",
"similarity\_metric": "euclidean",
"threshold": 10,
"time": 4.53,
"verified": True
}
之前的Facenet_cosine跟Facenet_euclidean_l2区别还是挺大的:
[ identity source_x ... source_h Facenet_euclidean_l2
0 tests/dataset//img1.jpg 345 ... 769 0.000000
1 tests/dataset//img11.jpg 345 ... 769 0.607683
2 tests/dataset//img7.jpg 345 ... 769 0.622369
3 tests/dataset//img10.jpg 345 ... 769 0.665341
4 tests/dataset//couple.jpg 345 ... 769 0.672360
5 tests/dataset//img6.jpg 345 ... 769 0.679286
6 tests/dataset//img2.jpg 345 ... 769 0.696520
7 tests/dataset//img4.jpg 345 ... 769 0.702221
8 tests/dataset//img5.jpg 345 ... 769 0.719814
[9 rows x 6 columns]]
欧几里得L2形式似乎比余弦和正则欧几里得距离更稳定。但是实际使用,更常用的是cosine因为它的结果是0~1可以换算成相似度100%~0%。
2.8 Facial Attribute Analysis
Deepface还配备了强大的面部属性分析模块,包括年龄,性别,面部表情(包括愤怒,恐惧,中性,悲伤,厌恶,惊喜)和种族(包括亚洲人、白人、中东人、印度人、拉丁裔和黑人)预测。结果将是出现在源图像中的脸的大小。
objs = DeepFace.analyze(img_path = "img4.jpg",
actions = ['age', 'gender', 'race', 'emotion']
)
# 实际测试
objs = DeepFace.analyze(img_path="tests/dataset/img4.jpg", actions=['age', 'gender', 'race', 'emotion'])
结果数据:
[
{
"age": 31,
"dominant\_emotion": "happy",
"dominant\_gender": "Woman",
"dominant\_race": "white",
"emotion": {
"angry": 0.06343021349136967,
"disgust": 0.000025026363773344608,
"fear": 0.16905087126557575,
"happy": 92.43509859620349,
"neutral": 6.627006038784261,
"sad": 0.4689154121827588,
"surprise": 0.23647171420196125
},
"gender": {
"Man": 0.00018949589275507606,
"Woman": 99.99980926513672
},
"race": {
"asian": 0.05465112952298698,
"black": 0.0038303477149617426,
"indian": 0.08727377218708528,
"latino hispanic": 3.3318923909600016,
"middle eastern": 5.098589813625205,
"white": 91.42376133345135
},
"region": {
"h": 919,
"w": 919,
"x": 419,
"y": 301
}
}
]

根据其教程,年龄模型的平均绝对误差为±4.65,性别模型的准确率为97.44%,精度为96.29%,召回率为95.05%。
2.9 Face Detectors
人脸检测和对齐是现代人脸识别流程的重要早期阶段。实验表明,仅仅对齐就能使人脸识别准确率提高近1%。OpenCV,SSD,Dlib,MTCNN,RetinaFace,MediaPipe,YOLOv8 Face和YuNet探测器被包裹在deepface中。
所有deepface函数都接受一个可选的检测器后端输入参数。你可以用这个参数在这些检测器之间切换。OpenCV是默认的检测器。
backends = [
'opencv',
'ssd',
'dlib',
'mtcnn',
'retinaface',
'mediapipe',
'yolov8',
'yunet',
]
#face verification
obj = DeepFace.verify(img1_path = "img1.jpg",
img2_path = "img2.jpg",
detector_backend = backends[0]
)
#face recognition
dfs = DeepFace.find(img_path = "img.jpg",
db_path = "my\_db",
detector_backend = backends[1]
)
#embeddings
embedding_objs = DeepFace.represent(img_path = "img.jpg",
detector_backend = backends[2]
)
#facial analysis
demographies = DeepFace.analyze(img_path = "img4.jpg",
detector_backend = backends[3]
)
#face detection and alignment
face_objs = DeepFace.extract_faces(img_path = "img.jpg",
target_size = (224, 224),
detector_backend = backends[4]
)
# 这里不再进行详细的测试
人脸识别模型实际上是CNN模型,它们期望标准大小的输入。因此,在表示之前需要调整大小。为了避免变形,deepface在检测和对齐后根据目标大小参数添加黑色填充像素。
RetinaFace和MTCNN似乎在检测和对齐阶段表现优异,但它们要慢得多。如果管道的速度更重要,那么应该使用opencv或ssd。另一方面,如果你考虑到准确性,那么你应该使用retinaface或mtcnn。
如下图所示,即使在人群中,RetinaFace的表现也非常令人满意。此外,它还具有令人难以置信的面部地标检测性能。突出的红点表示一些面部标志,如眼睛、鼻子和嘴巴。因此,RetinaFace的对齐分数也很高。

你可以在这个回购上找到更多关于RetinaFace的信息。
3.总结
框架很强大,有现成的模型和api,部署等由于篇幅所限我们下篇继续。
4.更新
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









