







给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网络安全面试题
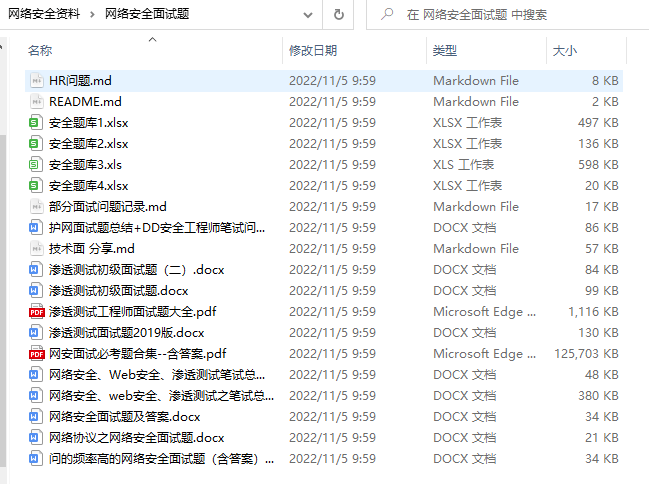
绿盟护网行动
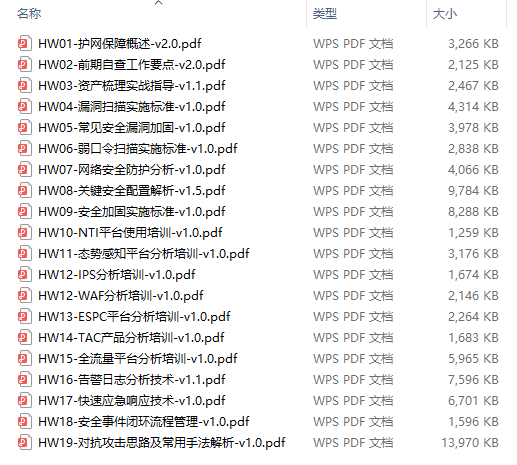
还有大家最喜欢的黑客技术
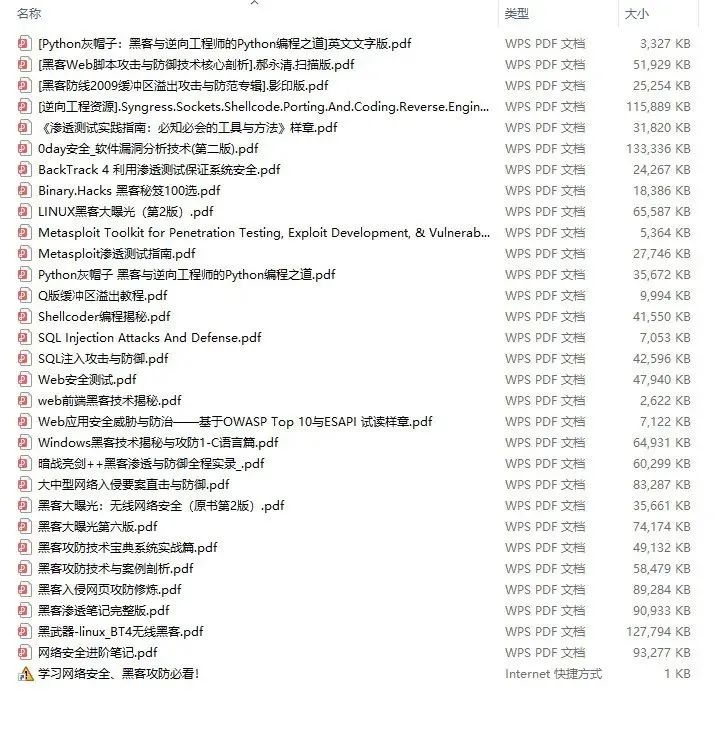
网络安全源码合集+工具包

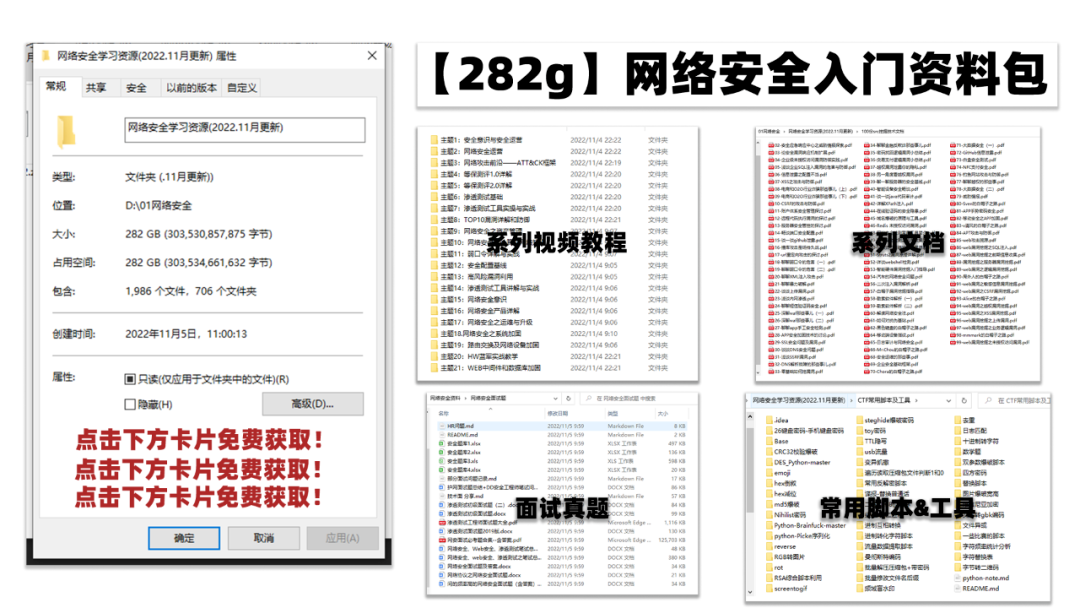
所有资料共282G,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
48.4 二叉树曾经有多少个路径经过当前节点
48.5 删除字符串
48.6 整型数组中都是3位数,是否能得到最趋近999的和
49、图、无向图、有向图、邻接表、邻接矩阵
50、图的宽度优先遍历
51、图的深度优先遍历
52、拓扑排序
53、最小生成树:Kruskal算法、Prim算法
54、Dijkstra算法
55、递归概念
56、汉诺塔问题
57、打印一个字符串的全部子序列
58、打印一个字符串的全部序列
59、母牛生小牛问题、人走台阶问题
60、给定数字字符串,转换成字母字符串
61、逆序栈,不用额外空间,递归
62、动态规划概念
63、数组从左上走到右下的最小路径和
64、数组中的数是否能累加到aim
65、01背包问题
66、堆的应用、攻克城市
67、数组代表容器,求max装水量
68、最大的leftmax与rightmax之差的绝对值
69、求最大子数组和
70、字符串是否可循环右移得到某字符串
71、字符串右移K位后的字符串,原地调整
72、生成窗口最大值数组
73、拼接字符串,使其字典顺序最小
74、占用会议室问题
75、Morris遍历
76、搜索二叉树
77、平衡树AVL
78、SB树、红黑树
79、跳表
一、第一次课(2017.11.11)
1、时间复杂度计算
描述一个流程中常数操作数的指标。只看高阶项,忽略常数系数。
2、冒泡排序、利用位运算交换元素
2.1 利用位运算交换
已知:a^a=0 a^0=a
void swap(int &a ,int &b)
{
a = a^b; //
b = a^b; //b=a^b^b=a
a = a^b: //a=a^b^a=b
}
注意,这种操作要保证两个数是不同地址的数,否则会发生自己跟自己异或结果为0的情况。
2.2 冒泡排序
每次都首项开始依次向后比较,将大的数向后传送,找到最大的那个,放到末尾。第二次时找到倒数第二大的数。
时间:O(N^2)
空间:O(1)
可做到稳定性
void bubble_sort(vector<int>&a)
{
for(int i=a.size()-1;i>0;i--)
{
for(int j=0;j<i;j++)
{
if(a[j+1]>a[j])
swap(a[j+1],a[j]);
}
}
}
3、插入排序
类似摸牌,从数组第二个位置开始,依次向前面已经排好序的数组中插入。
时间:O(N^2)
空间:O(1)
可做到稳定性
void insert_sort(vector<int>&a)
{
for(int i=1;i<a.size();i++)
{
for(int j=i;j>0;j--)
{
if(a[j]<a[j-1])
swap(a[j],a[j-1]);
}
}
}
4、选择排序
从第一个位置开始,从后开始找到最小的那个,放在第一个位置;
继续从第二个位置往后找第二小,放第二个位置;
…….
时间:O(N^2)
空间:O(1)
不可做到稳定性
void select_sort(vector<int>&a)
{
for(int i=0;i<a.size()-1;i++)
{
int min = i;
for(int j=i+1;j<a.size();j++)
{
if(a[j]<a[min])
min=j;
}
swap(a[i],a[min]);
}
}
5、随机快排
时间:O(NlogN)
空间:O(logN)
常规实现做不到稳定性,有论文实现,不必考虑
利用递归,每次随机选取一个值,将其作为基准值,小于它的放左边,等于的放中间,大于的放右边,然后递归调用左右两边。
vector<int> partition(vector<int>a, int l, int r)
{
int less = l-1;
int more = r;
while(l<more)
{
if(a[l]<a[r])
swap(a[++less], a[l++]);
else if(a[l]>a[r])
swap(a[--more], a[l]);
else
l++;
}
swap(a[r],a[more]);
vector<int>p;
p.push_back(less+1);
p.push_back(more);
return p;
}
void quick(vector<int>a, int l, int r)
{
if(l>=r)
return;
int pindex = rand()%(r-l+1);
swap(a[l + pindex],a[r]);
vector<int>p = partition(a, l, r);
quick(a, l, a[p[0]-1]);
quick(a, a[p[1]+1], r);
}
void quick_sort(vector<int>a)
{
if (a.size()<2)
return ;
quick(a, 0, a.size()-1);
}
6、二分查找
在已经排好序的数组中查找某个数是否存在。一般是取中间值比较,等于则存在,大于则递归调用右边,小于则递归调用左边。
bool binary(vector<int>a, int x)
{
int l = 0;
int r = a.size()-1;
while(l<r)
{
int mid = l + (r-l)>>1;
if (a[mid]==x)
return true;
if (a[mid] > x)
l = mid + 1;
if (a[mid] < x)
r = mid - 1;
}
return false;
}
7、Master公式
对于递归行为的复杂度,可以用公式来解决。如果一个N规模的程序可以分为N/b个规模,一共做a次(a次递归,每次N/b次操作),或者还带有其他非递归的复杂度,如下:
T(N)=aT(Nb)+O(Nd)
T(N)=aT(\frac{N}{b}) + O(N^d)
如果
logba>d
log_ba>d,则
T(N)=O(Nlogba)
T(N)=O(N^{log_ba})
如果
logba<d
log_ba<d,则
T(N)=O(Nd)
T(N)=O(N^{d})
如果
logba=d
log_ba=d,则
T(N)=O(NdlogN)
T(N)=O(N^dlogN)
二、第二次课(2017.11.12)
8、归并排序
递归划分两组,直到不能再分,组内有序,两两合并排序,需要额外数组。
时间:O(NlogN)
空间:O(N)
void merge(vector<int>&a, int l, int mid, int r)
{
vector<int>help(r-l+1);
int p1 = l;
int p2 = mid + 1;
int i = 0;
while(p1<=mid && p2<=r)
help[i++] = a[p1]<a[p2]?a[p1++]:a[p2++];
while(p1<=mid)
help[i++] = a[p1++];
while(p2<=r)
help[i++] = a[p2++];
for(i = 0;i<help.size();i++)
a[l+i] = help[i];
}
void merge_sort(vector<int>&a, int l, int r)
{
if(l == r)
return;
int mid = l + (r-l)>>1;
merge_sort(a, l, mid);
merge_sort(a, mid+1, r);
merge(a, l, mid, r);
}
merge_sort(a, 0, a.size()-1);
9、利用归并排序求小和
小和就是某个数之前所有比它小的数的和。求小和就是求整个数组的小和之和。
如:3 5 1 4 6,其小和就是3+(3+1)+(3+5+1+4)=20
利用归并排序,每次两两合并时,如果左边组一个数比右边组一个数小,那他肯定比右边组那个数及其后面的数都小。
用O(NlogN)解决。
int merge(vector<int>&a, int l, int mid, int r)
{
vector<int>help(r-l+1);
int p1 = l;
int p2 = mid + 1;
int i = 0;
int sum = 0;
while(p1<=mid && p2<=r)
sum += a[p1]<a[p2]?(a[p1]*(l-p2+1)):0;
help[i++] = a[p1]<a[p2]?a[p1++]:a[p2++];
while(p1<=mid)
help[i++] = a[p1++];
while(p2<=r)
help[i++] = a[p2++];
for(i = 0;i<help.size();i++)
a[l+i] = help[i];
return sum;
}
int merge_sort(vector<int>&a, int l, int r)
{
if(l == r)
return;
int mid = l + (r-l)>>1;
return merge_sort(a, l, mid)+merge_sort(a, mid+1, r)+merge(a, l, mid, r);
}
merge_sort(a, 0, a.size()-1);
10、利用归并排序求逆序对
逆序对是一个数,前面有比他大的数,这两个数就构成了逆序对。求数组中有多少个逆序对。用O(NlogN)解决。
利用归并排序,当两个组在合并时,如果左边组的一个数比右边组的一个数大,那左边组这个数及其后面的数都会比右边组的这个数大,这些数就构成了逆序对。
int merge(vector<int>&a, int l, int mid, int r)
{
vector<int>help(r-l+1);
int p1 = l;
int p2 = mid + 1;
int i = 0;
int sum = 0;
while(p1<=mid && p2<=r)
sum += a[p1]>a[p2]?(mid-p1+1):0;
help[i++] = a[p1]>a[p2]?a[p2++]:a[p1++];
while(p1<=mid)
help[i++] = a[p1++];
while(p2<=r)
help[i++] = a[p2++];
for(i = 0;i<help.size();i++)
a[l+i] = help[i];
return sum;
}
int merge_sort(vector<int>&a, int l, int r)
{
if(l == r)
return;
int mid = l + (r-l)>>1;
return merge_sort(a, l, mid)+merge_sort(a, mid+1, r)+merge(a, l, mid, r);
}
merge_sort(a, 0, a.size()-1);
11、堆排序、建堆、调整 堆
算法上的堆是一个完全二叉树,已知节点i,其父节点为(i-1)/2,左孩子为2i+1,右孩子为2i+2。
使用大根堆,任何一个节点,都是其子树中值最大的点。
堆排序,就是把整个数组变成一个大根堆,然后将根节点与尾节点交换,再向下调整大根堆。
如何建立大根堆:将节点依次插入堆中,如果碰到比自己的父节点大,则与其交换,递归向上调整。
根节点与尾节点交换后如何调整大根堆:向下调整,与左右孩子比较,若大于他们,不需要调整,如果小于,则跟其中大的孩子交换。然后递归向下调整。
void heapinsert(vector<int>&a, int index)
{
while(a[index]>a[(index-1)/2])
{
swap(a[index],a[(index-1)/2]);
index = (index-1)/2;
}
}
void heapify(vector<int>&a, int index, int size)
{
int left = 2*index+1;
while(left<size)
{
int largest = ((left+1<size) && (a[left+1]>a[left]))?left+1:left;
largest = a[largest]>a[index]?largest:index;
if (largest==index)
break;
swap(a[largest], a[index]);
index = largest;
left = 2*index+1;
}
}
void heap_sort(vector<int>&a)
{
if(a.size()<2)
return;
for(int i=1;i<a.size();i++)
heapinsert(a, i);
int size = a.size();
swap(a[0],a[--size]);
while(size>0)
{
heapify(a, 0, size);
swap(a[0],a[--size]);
}
}
12、桶排序
分为计数排序和基数排序。分开说。
这种不基于比较的排序,可实现时间复杂度为O(N),但浪费空间,对数据的位数与范围有限制。
13、比较器的使用
使用系统的默认排序函数sort时,是从小到大的,你可以改变比较器实现不同方式的排序。
bool mycompare1(int a, int b)
{//降序
return a - b > 0;
}
// 注意不能加等于号!
bool mycompare2(int a, int b)
{//升序
return b - a > 0;
}
sort(A.begin(), B.end(), mycomapre1);
14、计数排序
根据数组中的最大值max准备max+1个桶,每个桶记录数组中的这个数出现的次数。然后根据桶中的数字一次倒出每个数即可。
void bucket_sort(vector<int>&a)
{
if(a.size()<2)
return;
int max = INT_MIN;
for (int i=0;i<a.size();i++)
max = a[i]>max?a[i];max;
vector<int>bucket(max+1,0);
for(int i=0;i<a.size();i++)
bucket[a[i]]++;
int j=0;
for(int i=0;i<bucket.size();i++)
{
while(bucket[i]-->0)
a[j++] = i;
}
}
15、排序后最大相邻数差值问题
即n个数,则准备n+1个桶,最后一个桶放最大值max,其他min~(max-1)的数在前n个桶桑平分。比如说数i,它放在哪个桶中就取决于:((i-min)/(max-min))*n。
如果说有一个桶为空,则其左边第一个不为空的桶的最大值a,与其右边第一个不为空的桶的最小值b,这两个数在排序后一定是相邻的,且他们的差值比每个桶内的差值都大。所以只需要记录这些每个桶内的max和min,比较相邻的前后非空桶的min-max与桶内的max-min的差值大小即可。
所以准备三个n+1大小的数组,一个数组记录这个桶是否为空,另外两个数组分别记录这个桶内的max和min。
int maxgap(vector<int>a)
{
if(a.size()<2)
return 0;
int imax = INT_MIN;
int imin = INT_MAX;
for(int i=0;i<a.size();i++)
{
imax = a[i]>imax?a[i]:imax;
imin = a[i]<imin?a[i]:imin;
}
if(imin==imax)
return 0;
vector<bool>isempty(a.size()+1);
vector<int>amax(a.size()+1);
vector<int>amin(a.size()+1);
int index=0;
for(int i=0;i<a.size();i++)
{
index = (a[i]-imin)* a.size()/(imax-imin);
amax[index] = amax[index]?max(amax[index], a[i]):a[i];
amin[index] = amin[index]?min(amin[index],a[i]):a[i];
isempty[index] = true;
}
int gap = isempty[0]?amax[0]-amin[0]:0;
int lastmax = amax[0];
for (int i=1;i<isemppty.size();i++)
{
if(isempty[i])
{
gap = max(gap, amin[i]-lastmax);
lastmax = amax[i];
}
}
return gap;
}
16、KMP算法
想看详细介绍,请参见博客:
http://blog.csdn.net/liuxiao214/article/details/78026473
字符串匹配问题,字符串p是否是字符串s的子串,是的话,返回p在s中的起始位置,否的话返回-1。
暴力的方法是p与s的第一个字符比较,相等就继续比较,不相等就换s的第二个字符继续比较,这样做的话,遍历s的指针i会发生回溯,导致时间复杂度为O(N^2)。
那最好是i指针不用发生回溯。这里就用到了字符串的最大公共前缀后缀。
首先是找字符串p的最大公共前缀后缀,比如ABCAB,其最大公共前缀后缀就是AB,长度是2。这样当我们发生不匹配时,直接按照其最大公共前缀后缀长度移动字符串p就可以。
当然我们不直接使用最大相同公共前缀后缀,我们使用的是next数组,这个数组中的数是不包含当前字符的最大前缀后缀的长度,如图:
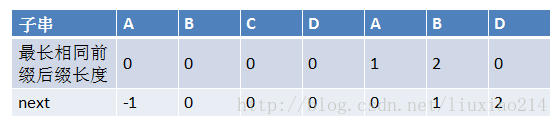
然后这样字符串匹配时,如果发生不匹配,遍历字符串s的指针i不必回溯,只需移动字符串p即可,即更改遍历p的指针j,j变为其next数组中的值。
求next数组利用递归。直接上代码:
vector<int> getnext(string s)
{
vector<int>next(s.length());
next[0] = -1;
if (s.length()<2)
return next;
next[1] = 0;
int cn = 0;
int i = 2;
while(i<s.length())
{
if(s[i-1]==s[cn])
next[i++] = ++cn;
else if(cn>0)
cn = next[cn];
else
next[i++] = 0;
}
}
int kmp(string s, string p)
{
if(s.length()<p.length() || s.length==0 || p.length==0)
return -1;
int i = 0;
int j = 0;
vector<int>next=getnext(p);
while(i<s.length() && j<p.length())
{
if(s[i]==p[j])
{
i++;
j++;
}
else if(next[j]==-1)
i++;
else
j = next[j];
}
return j==p.length()?i-j:-1;
}
三、第三次课(2017.11.18)
17、KMP算法应用:最大重合的新串
给定一个字符串str1,只能往str1的后面添加字符变成str2。
要求:str2中必须包含两个str1,即两个str1可以有重合,但不能是同一位置开头,即完全重合;且str2尽量短。
利用next数组,找到str1的最大公共前缀后缀,然后向str1尾部添加从前缀后开始到str1原尾部的字符。
如:str1=abracadabra,则str2=abracadabra+cadabra
int getnext(string s)
{
vector<int>next(s.length()+1);
next[0]=-1;
if (s.length()<2)
retrun -1;
next[1] = 0;
int cn = 0;
int i = 2;
while(i<s.length()+1)
{
if(s[i-1]==s[cn])
next[i++] = ++cn;
else if(cn>0)
cn = next[cn];
else
next[i++] = -1;
}
return next[s.length()];
}
string gettwo(string s)
{
if (s.length()==0)
return "";
if (s.length()==1)
return s+s;
if (s.length()==2)
return s[0]==s[1]?s+s.substr(1):s+s;
return s + s.substr(getnext(s));
}
18、KMP算法应用:两个二叉树是否子树匹配
给定两个二叉树T1,T2,返回T1的某个子树结构是否与T2相等。
常规解法是遍历头节点,看其子树结构是否与T2相等。
这里将二叉树T1与T2都转换为字符串,是否匹配就看T2是否是T1的子串。
如何转换呢?每一个节点的值后面都加一个特殊符号,比如“_”,空节点用另一个特殊符号表示,如“#”。序列化要按照同样的遍历方式,比如前序遍历。
3
1 2
2 3
上图中序列化后为“3 _ 1 _ 2 _ # _ #_ 3 _ # _ # _ 2 _ # _ # _”
struct TreeNode
{
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x):val(x),left(NULL),right(NULL){}
};
string tree2string(TreeNode *root)
{
if(root==NULL)
return "#\_";
string str = to_string(root->val) + "\_";
return str + tree2string(root->left) + tree2string(root->right);
}
vector<int> getnext(string s)
{
vector<int>next(s.length());
next[0] = -1;
if (s.length()<2)
return s;
next[1] = 0;
int cn = 0;
int i = 2;
while(i<s.length())
{
if(s[i-1]==[cn])
next[i++] = ++cn;
else if (cn>0)
cn = next[cn];
else
next[i++] = -1;
}
return next;
}
int kmp(string s, string p)
{
if(s.length() < p.length() || s.length()==0 || p.length()==0)
return -1;
vector<int>next = getnext(p);
int i = 0;
int j = 0;
while(i<s.length() && j<p.length())
{
if(s[i] == p[j])
{
i++;
j++;
}
else if (next[j]>0)
j = next[j];
else
i++:
}
return j == p.length() ? i-j : -1;
}
bool issubtree(TreeNode *root1, TreeNode *root2)
{
string s = tree2string(root1);
string p = tree2string(root2);
return kmp(s, p) != -1;
}
19、Manacher算法及其扩展(添加新串使回文且最短)
19.1 Manacher:找出字符串str最大的回文子串
首先解决奇回文和偶回文的问题。
我们在判断字符串是否回文时,是根据一个字符(奇回文)或空(偶回文)来判断的,这样需要分情况讨论,比较麻烦,所以最好统一一下。
添加辅助字符,(随便哪个字符都可以,不会影响原有字符匹配就可以),如“#”,在字符与字符之间、开头和结尾各添加“#”,这个“#”就相当于一个虚轴,虚轴只会和虚轴匹配。这样就可以统一奇回文和偶回文了。
传统方法是从str的每个字符开始,向两边扩,找到最大回文子串,复杂度为O(N^2)。
首先是将字符串转换为添加特殊字符后的新字符串。然后进行查找最大回文子串。
首先规定几个概念:
- 回文最右边界R
- 回文最右边界R的回文中心C
- 回文半径数组radius,记录每个字符以其为中心的回文半径。
- 最大回文半径与最大回文半径中心。
一共分为四种情况讨论。
1、当遍历到i时,如果字符i在最右边界R的右边,只能采用暴力匹配方式,向两边扩。
2、如果i在最右边界R的左边,则找到i关于R的对称点i’,如果i’的回文左边界在R的回文边界中,则i的回文边界也在R的回文边界中,不会再向外扩。
3、如果i’的回文左边界不在R的回文边界中,则i的回文右边界刚好与R重合,也不会扩。
4、如果i’的回文左边界刚好在R的回文左边界上,则i的回文半径至少到了R,至于R之后会不会扩,只能暴力匹配了。
那么在上述四种情况下,2、3的回文边界就不用暴力匹配了,直接去radiux[2C-i](即i’的回文半径)与R-i的小值就可以了。
string get_newstring(stirng s)
{
string ss = "#";
for (int i=0;i<s.length();i++)
ss = ss + s[i] + "#";
return ss;
}
string manacher(string s)
{
if(s.length()<2)
return "";
string news = get_newstring(s);
vector<int>radius(news.length(), 0);
int C = -1;
int R = -1;
int rmax = INT_MIN;
int rc = 0;
for(int i=0; i<news.length(); i++)
{
radius[i] = 1;
radius[i] = R>i ? min(R-i, radius[2*C-i]) : radius[i];
while( i - radius[i] >= 0 && i + radius[i] < news.length())
{
if(news[i - radius[i]] == news[i + radius[i]])
radius[i]++;
else
break;
}
if(i+raidus[i]>R)
{
R = i + radius[i];
C = i;
}
if(radius[i]>rmax)
{
rmax = radius[i];
rc = i;
}
}
rmax--;
return s.substr((ic-imax)/2, imax);
}
19.2 给定str1,在其后添加字符使得新字符串是回文字符串且最短
找到包含最后一个字符的最大回文子串,然后将这个回文子串之前的字符反向贴在str1的后面即可。
如“abc12321”,即将“abc”反向贴在后面即可,“abc12321cba”
string get_newstring(string s)
{
string news = "#";
for(int i=0; i<s.length(); i++)
news = news + s[i] + "#";
return news;
}
int manacher(string s)
{
string news = get_newstring(s);
vector<int>radius(news.length());
int C = -1;
int R = -1;
for(int i=0; i<news.length(); i++)
{
radius[i] = R>i ? min(R-i, radius[2*C-i]) : 1;
while(i - radius[i] >=0 && i + radius[i] < news.length())
{
if(news[i-radius[i]] == news[i+radius[i]])
radius[i]++;
}
if(i+radius[i]>R)
{
R = i+ radius[i];
C = i;
if (R == news.length())
return radius[i]-1;//包含最后一个字符的最大回文子串的长度
}
}
}
string getmaxstring(string s)
{
int r = manacher(s);
string ss = s;
for(int i= s.length()-r-1; i>=0; i--)
ss = ss + s[i];
return ss;
}
20、BFPRT算法:求第K小/大的数
利用快排中的partition过程。如果求第K小,就是求排序后数组中下标为k-1的值。如果k-1属于partition后的等于区,则可直接返回等于区的数,如果,在大于区,则递归调用大于区,在小于区,则递归调用小于区。
到那时BFPRT又做了优化,即在选取partition的划分值时不再是随机选取,而是有策略的选取。
如何选呢?首先,将数组5个一组进行划分,不足5个自动一组。
然后分别组内排序(可用插入排序),求出每个组内的中位数,将这些中位数组成新的数组mediumarray。
然后递归调用这个BFPRT的函数,得到这个中位数数组的上中位数。这个值就是进行partition的划分值。
vector<int> partition(vector<int>&a, int l, int r, int value)
{
int less = l-1;
int more = r+1;
while(l<more)
{
if(a[l]<value)
a[++less]=a[l++};
else if (a[l]>value)
a[--more]=a[l];
else
l++;
}
vector<int>p;
p.push_back(less+1);
p.push_back(more-1);
}
void insert_sort(vector<int>&a, int start, int end)
{
if(start==end)
return ;
for(int i=start+1;i<=end;i++)
{
for(int j=i-1;j>=start;j--)
{
if(a[j+1]<a[j])
swap(a[j+1],a[j]);
}
}
}
int getmedium(vector<int>&a, int start, int end)
{
insert_sort(a, start, end);
return a[strat + (end-start)/2];
}
int get_medium_of_medium(vector<int>&a, int start, int end)
{
int num = end-start+1;
int flag = num%5 == 0 ? 0 : 1;
vector<int>mediums(num/5+flag);
for(int i=0; i< mediums.size(0; i++)
{
int istart = start + i*5;
int iend = istart + 4;
mediums[i] = getmedium(a, istart, min(iend, end));
}
return findk(mediums, 0, mediums.size()-1, (mediums.size()-1)/2);
}
int findk(vector<int>&a, int start, int end, int k)
{
if(start==end)
return a[strat];
int pvalue = get_medium_of_medium(a, start, end);
vector<int>p = partition(a, start, end, pvalue);
if(k>=p[0] && k<=p[1])
return pvalue;
else if(k<p[0])
return findk(a, start, p[0]-1, k);
else
returun findk(a, p[1]+1, end, k);
}
int mink(vector<int>a, int k)
{
if(k<1 || k>a.size())
return NULL;
return findk(a, 0, a.size()-1, k-1);
}
21、基数排序
找到最大数的位数,并准备10个桶(0-9)。从个位数到高位数依次排序,按照其位上的数的大小依次入桶,顺序要保持一致,保持先进先出。
int maxbit(vector<int>a)
{
int imax = INT_MIN;;
for(int i=0; i<a.size() && imax<a[i]; i++)
imax = a[i];
int digit = 0;
while(imax>0)
{
imax /= 10;
digit++;
}
return digit;
}
int getnum(int x, int digit)
{
return (x/(pow(10, digit-1))) % 10;
}
void radix(vector<int>&a, int start, int end, int digit)
{
vector<int>help(end-start+1);
int num;
for(int d=1; d<=digit; d++)
{
vector<int>count(10,0);
for(int i=0; i<a.size(); i++)
{
num = getnum(a[i], d);
count[num]++;
}
fot(int i=1; i<10; i++)
count[i] += count[i-1];
for(int i=end; i>=start; i--)
{
num = getnum(a[i], d);
help[count[num]-1] = a[i];
count[num]--;
}
for(int i=0; i<help.size(); i++)
a[start + i]=help[i];
}
}
void radix_sort(vector<int>a)
{
if(a.size()<2)
return ;
radix(a, 0 ,a.size()-1, maxbits(a));
}
22、希尔排序
设置步长,每次选一个步长来进行排序,做很多遍,最终落在步长为1的排序上。大步长调整完基本有序,则小步长不必调整过多。
插入排序就是步长为1的希尔排序。
12 3 1 9 4 8 2 6 (未排序)
选择步长为4
4 3 1 6 12 8 2 9
选择步长为2
1 3 2 6 4 8 12 9
选择步长为1
1 2 3 4 6 8 9 12
23、实现特殊栈,O(1)实现getmin()
进栈、出栈、返回栈顶这些都与原来的栈的操作保持一致,主要是加了怎样在O(1)时间下得到栈内最小值。
两种方法,不过都要准备两个栈,一个数据栈data存放数据,一个help栈,存放最小值。
方法一:help栈存放最小值,每次data栈压栈时,help也压栈,不过help要保持最小的栈顶,即如果data新进的数如果比help栈顶小,则这个数可以压栈入help,否则将help栈顶的那个数再一次压入help栈中。
压栈的时候同步压,出栈同步出。
方法二:当压入data栈的数小于等于help栈顶时,可以向help压入,否则不压。当要弹出data栈的数时,如果这个数与help的栈顶值相等,则help也弹出,否则help不弹出。
则help的栈顶一直是当前栈内最小的数。
24、用数组结构实现大小固定的队列和栈
24.1 实现栈
维护一个size(初始为0),代表栈的大小,当push时,数直接放在a[size]上,size++,当pop时,直接取a[size-1]]的值,size–。
struct array_stack
{
vector<int>astack;
int size;
array_stack(int initsize)
{
if(initsize<0)
cout<<"请输入一个大于0的数,以保证栈不为空"<<endl;
astack=vector<int>(initsize);
size = 0;
}
int top()
{
if(size==0)
{
cout<<"the stack is empty"<<endl;
return NULL;
}
return a[size-1];
}
void push(int x)
{
if(size==astack.size())
{
cout<<"the stack is full"<<endl;
return ;
}
astack[size++] = x;
}
int pop()
{
if(size==0)
{
cout<<"the stack is empty"<<endl;
return NULL;
}
return astack[--size];
}
};
24.2 实现队列
维护start、end、size三个指针,size表示队列的大小(约束start与end的关系)。当push时,end++,pop时,start++,用start去追end,谁先触底,则回到开始位置。
struct array_queue
{
vector<int>aqueue;
int size;
int start;
int end;
aqueue(int initsize)
{
if(initsize<0)
cout<<"请输入一个大于0的数,以保证队列不为空"<<endl;
aqueue = vector<int>(initsize);
size = 0;
start = 0;
end = 0;
}
int top()
{
if(size == 0)
return null;
return aqueue[start];
}
void push(int x)
{
if(size == aqueue.size())
{
cout<<"the queue is full"<<endl;
return ;
}
aqueue[end] = x;
size ++;
end = end==aqueu.size()-1?0:end+1;
}
int pop()
{
if(size == 0)
{
cout<<"the queue is empty"<<endl;
return NULL;
}
size--;
int temp = start;
start = start == aqueue.size()-1?0:start+1;
return aqueue[temp];
}
}
25、用栈实现队列、用队列实现栈
25.1 用栈实现队列
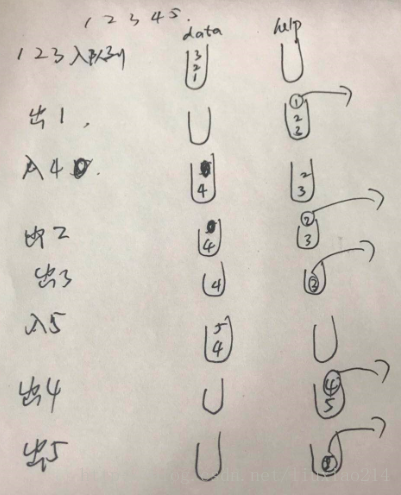
准备两个栈,一个数据栈data,一个辅助栈help,数据栈负责入队列,如果需要出队列,就把数据栈中的当前所有数据倒入辅助栈help中。然后从help中出队列。
注意两点:如果help栈不为空,data栈不要向help栈倒数据;data栈倒数据时,一次要全倒完。
struct stack2queue
{
stack<int>data;
stack<int>help;
stack2queue()
{
data = new stack<int>();
help = new stack<int>();
}
int top()
{
if(data.empty() && help.empty())
{
cout<<"the queue is empty"<<endl;
return NULL;
}
else if(help.empty())
{
while(!data.empty())
help.push(data.pop());
}
return help.top();
}
void push(int x)
{
data.push(x);
}
int pop()
{
if(data.empty() && help.empty())
{
cout<<"the queue is empty"<<endl;
return NULL;
**先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7**
**深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**






**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)**
0/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
struct stack2queue
{
stackdata;
stackhelp;
stack2queue()
{
data = new stack();
help = new stack();
}
int top()
{
if(data.empty() && help.empty())
{
cout<<“the queue is empty”<<endl;
return NULL;
}
else if(help.empty())
{
while(!data.empty())
help.push(data.pop());
}
return help.top();
}
void push(int x)
{
data.push(x);
}
int pop()
{
if(data.empty() && help.empty())
{
cout<<“the queue is empty”<<endl;
return NULL;
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
[外链图片转存中…(img-WyKNZiFr-1715251064773)]
[外链图片转存中…(img-6hJMxoiZ-1715251064774)]
[外链图片转存中…(img-bgzU4j4p-1715251064775)]
[外链图片转存中…(img-7SjzMKc9-1715251064776)]
[外链图片转存中…(img-7Z1KqyYk-1715251064777)]
[外链图片转存中…(img-UHNH4gYe-1715251064777)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









