







选举完成后,ISIS 网络链路内所有的路由器之间都建立的是邻接关系。OSPF 中 DRothers 只与 DR/BDR 形成 full 邻接关系, DRothers 之间只有 2-way 的关系
11.接口优先级的修改
接口优先级 就是DIS的优先级。 如果默认什么都不加 就是把一类和二类的DIS都改了,建议改的时候要明确是一类还是二类的
12.IS-IS 开销值
IS-IS 有三种方式来确定接口的开销,按照优先级由高到底分别如下:
①接口开销:为单个接口设置开销,优先级最高。 默认是10
int g0/0/0
isis cost 50
②全局开销:为所有接口设置开销,优先级中等。
isis
circuit-cost 30
③自动计算开销:根据接口带宽自动计算开销,优先级最低。
isis
bandwidth-reference 1000
auto-cost enable
13.接口开销类型(narrow,wide)
IS-IS 开销类型默认为 narrow ,接口下最大只能配置值为 63 的开销值,但是在大型
网络设计中,较小的度量范围不能满足实际需求。 IS-IS 开销类型 wide , 接口
开销值可以扩展到 16777215
14.IS-IS 路由聚合
IS-IS 也能够通过路由聚合来减少路由条目。
isis
summary 10.0.1.0 255.255.255.252 level-1 默认以L2类型发送
15.IS-IS 缺省路由
第一种缺省路由是由 level-1 路由器在特定条件下自动产生的,它的下一跳是离它最近的 (cost 最小)level-1-2 路由器。
第二种缺省路由是 IS-IS 路由器上使用 default-route-advertise 命令产生并发布的。
isis
default-route-advertise match default level-1-2
16.IS-IS 路由引入
IS-IS 网络能够引入其他路由协议的路由和其他 IS-IS 协议进程的路由。默认情况下,IS-IS 总是以 level-2 路由类型引入外部路由。但是,通过手动配置,也可以以 level-1 路由类型引入外部路由。
isis
import-route ospf 1 level-1 cost-type internal cost 30
17.IS-IS 路由过滤
使用 filter-policy 工具对 IS-IS 路由进行过滤
route-policy 10 deny node 2
if-match ip next-hop acl 2014
if-match acl 2001
route-policy 10 permit node 3
isis
filter-policy route-policy 10 import
18.IS-IS 路由渗透
IS-IS 路由渗透指的是 Level 1-2 和 Level-2 路由将自己知道的其他 Level-1区域以及 Level-2 区域的路由信息通报给指定的 Level-1 区域的过程。
isis
import-route isis level-2 into level-1
因为ISIS没有全局的概念,L1的路由器要出去就是找最近的,看不到整个路径。 把2类的明细发送给1类,这样就不会产生次优
19.补充
需求:ISIS不同网段建立邻居。使地址不在同一个网段 也能建立起邻居关系。
[R2\R1]int s0/0/0
[ ]isis peer-ip-ignore (两端都得改)
解析:因为ISIS本质是基于二层建立起来的
需求:修改System ID ,让它更短一点
[R2\R1]isis
[R2-isis-1]is-name R2\R1 (两端都得改)
BGP 知识点
BGP知识点:
BGP基础配置,BGP 5种报文,6种邻居状态,4大类细分10种属性,IBGP EBGP(环回口 物理接口)建立邻居,BGP认证,fake-as,路由传递原则,IBGP防环,EBGP防环,RR防环,BGP路由自动聚合,手工聚合(detail-suppressed,supress-policy,attribute-policy,origin-policy),BGP 5种 community属性,BGP选路,BGP联盟,路由反射器,BGP路由过滤,引入,下放默认路由
1.BGP 5种报文
建立邻居 open
更新 update
警告 notification
周期性存活 keepalive (默认是60秒,还有hold time,是keepalive time的3倍关系,也就是180秒)
路由刷新 route-refresh
2.6种状态:Idle\connect\active\opensent\open confirm\established
3.4大类属性
4大类属性:
公认必遵(Origin、AS-PATH、Next-hop) 公认必遵的三个是BGP报文必须要有的
公认任意(Local-Preference\原子聚合)
可选过渡(aggregator\community(internet,no-advertise,no-export,no-open-stubconfig))
可选非过渡(med\cluster-list\origin-id)
4.IBGP EBGP(环回口 物理接口)建立邻居
使用物理接口建立 IBGP 邻居
bgp 100
router-id 1.1.1.1
peer 192.168.12.2 as-number 100
使用环回口建立 IBGP 邻居
peer 2.2.2.2 as-n 100
peer 2.2.2.2 connect interface loo0
使用环回口建立 EBGP 邻居,ebgp 多跳
peer 3.3.3.3 as-n 200
peer 3.3.3.3 connect interface loo0
peer 3.3.3.3 ebgp-max-hop 255
5.BGP认证
认证是指路由器对路由信息来源的可靠性及路由信息本身的完整性进行检测的机制。
简单认证
bgp 100
peer 192.168.12.2 password simple Huawei
keychain 认证
keychain key mode periodic daily
key-id 1
key-string huawei
algorithm md5
send-time daily 08:00 to 18:00
receive-time daily 08:00 to 18:00
bgp 100
peer 192.168.12.2 keychain key
6.fake-as
fake-as
使用 fake-as 可以将本地真实的 AS 编号隐藏,其他 AS 内的对等体在指定本
端对等体所在的 AS 编号时,应该设置成这个伪 AS 编号
bgp 2000
peer 192.168.12.1 fake-as 200
7.路由传递原则
BGP 设备将最优路由加入 BGP 路由表,形成 BGP 路由。BGP 设备与对等体建
立邻居关系后,采取以下交互原则:
1、从 IBGP 对等体获得的 BGP 路由,BGP 设备只发布给它的 EBGP 对等体。
2、从 EBGP 对等体获得的 BGP 路由,BGP 设备发布给它所有 EBGP 和 IBGP 对 9等体。
3、当存在多条到达同一目的地址的有效路由时,BGP 设备只将最优路由发布给对等体。
4、路由更新时,BGP 设备只发送更新的 BGP 路由。
5、所有对等体发送的路由,BGP 设备都会接收
8.防环机制
IBGP的防环:水平分割,路由器从它的一个BGP对等体那里接收到的路由条目不会将该路由器再传递给其他IBGP对等体。
EBGP的防环:当路由器从EBGP邻居收到BGP路由时,如果该路由的AS_Path中包含了自己的AS编号,则该路由将会直接丢弃
RR 路由反射器的防环:Originator_id,Cluster_list
举例:
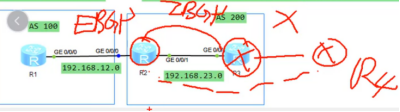
R2从EBGP邻居R1 收到R1的路由条目,会发送给R3。
如果R3后还有R4,观察点要转移到R3,R3是通过IBGP邻居R2收到的路由条目,是不会发给R4的。
9.BGP路由聚合
自动聚合(默认情况下是关闭的,只适用于通过路由引入方式引入的路由,对network无效)
bgp 100
summary automatic
手工聚合(detail-suppressed,supress-policy,attribute-policy,origin-policy)
null 0 表示不存在的接口,起到防环作用
分为静态 和 aggravate
1.配置一条静态路由,然后 network 命令进行通告
ip route-static 192.168.0.0 21 NULL 0
bgp 400 network 192.168.0.0 255.255.248.0
2.使用 aggregate 命令进行聚合。(推荐)
bgp 400
aggregate 172.16.0.0 255.255.248.0
如何解决BGP路由聚合带来的潜在环路问题? —— 带AS号, 因为默认是不带的
detail-suppressed 抑制明细
bgp 400
aggregate 172.16.0.0 21 detail-suppressed
suppress-policy 抑制部分明细
bgp 400
aggregate 172.16.0.0 21 suppress-policy sup
attribute-policy 可以修改聚合后的路由属性
route-policy att permit node 10
apply origin incomplete bgp 400
aggregate 172.16.0.0 21 attribute-policy att
10.BGP 5种 community属性
4 个特殊的团体:
internet ,no-export , no-advertise , no-export-Subconfed
internet : 可以向任何 BGP 对等体发布路由
no-export: 不会发给 EBGP 对等体,但可以发布给联盟(Confederation)EBGP 对等体
no-advertise: 不会发给任何 BGP 对等体,谁都不发
no-export-Subconfed :不会发给 EBGP 对等体,也不会发布给联盟(Confederation)EBGP 对等体
aa:nn 自定义团体属性
11.BGP选路
丢弃下一跳不可达的路由
11种选路
一般来说,BGP计算路由优先级的规则: 要记住这8条及顺序
当到达同一目的地存在多条路由且下一跳可达
1.优选协议首选值(Preference_Value)最高的路由。(私有属性,仅本地有效)
2.优选本地优先级(Local_Preference)最高的路由。 (100,IBGP,越大越优)
3.优选本地生成的路由。手动聚合>自动聚合>network>import>从对等体学到的。
4.优选 AS_Path 短的路由。
5.比较 Origin 属性,起源类型 IGP>EGP>Incomplete。 i>e>?
6.优选 MED(Multi Exit Discriminator)值最低的路由。 (0,EBGP,越小越优)
7.优选从 EBGP 学来的路由(EBGP>IBGP)。
8.优选 AS 内部 IGP 的 Metric 最小的路由。
bgp 100
max load-balancing 2
9.优选 Cluster_List 最短的路由。 (有做路由反射器RR才考虑)
10.优选 Router_ID 最小的路由器发布的路由。
11.优选具有较小 IP 地址的邻居学来的路由。
如果配置了负载分担,当前8个规则相同,且存在多条AS_Path完全相同的外部路由,则根据配置的路由条数选择多条路由进行负载分担
bgp 100
maximum load-balancing 2 2以上的数字代表开启,如果有三条分支,则改成3
dis ip routing-table
12.BGP联盟
BGP 路由反射器可以用来减少大型 AS 中 IBGP 邻居关系的数量和简化 IBGP 邻居关系的管理和维护,BGP 联盟(Condeferation)也可以用来实现类似的目的。
一个 BGP 联盟是一个具有内部层次结构的 AS,一个 BGP 联盟由若干个子 AS组成。对于一个 BGP 联盟,其成员 AS 内部的路由器之间需要建立全互联的IBGP 邻居使用 BGP 路由反射器,而成员之间需要建立 EBGP 邻居关系。从联盟外的 EBGP 对等体来看,整个联盟无异于一个普通的 AS,联盟内部的结构对于联盟外的 EBGP 对等体来说是完全透明的。
bgp 2003
router-id 5.5.5.5
confederation id 200
confederation peer-as 2001
若公司网络规模需要扩大,则一般只需要在相应的成员 AS 中添加路由器并进行
相关的配置即可,配置工作量远远小于不使用 BGP 联盟的情形。
详细看 BGP 选路实验。
13.BGP路由过滤,引入,下放默认路由 —— 详细看BGP路由过滤,引入,下放默认路由 实验
BGP 路由过滤
路由属性的丰富性可以为实现路由过滤、路由引入等路由策略和控制提供非常有利的条件。
利用 AS-Path 进行路由过滤
ip as-path-filter 1 permit 100$
bgp 200
peer 192.168.13.1 as-path-filter 1 import
利用 Community 属性进行路由过滤
route-policy 10 permit node 1
apply community no-export
bgp 300
peer 192.168.14.1 route-policy 10 export
peer 192.168.14.1 advertise-community
利用 Next Hop 属性进行路由过滤
ip ip-prefix 1 permit 192.168.25.5 32
route-policy 10 deny node 1
if-match ip next-hop ip-prefix 1
route-policy 10 permit node 2
bgp 100
peer 192.168.26.6 route-policy 10 export
BGP 路由引入
在多协议混合的网络环境中,不同的路由协议使用的协议报文各不相同,就好比
说着不同的语言。如果一种路由协议需要从别的路由协议那里获取路由信息,则
可以使用路由引入技术。
ip ip-prefix 10 permit 5.5.5.5 32
route-policy 10 permit node 1
if-match ip-prefix 10
bgp 100
import-route ospf 1 route-policy 10
BGP 缺省路由
在 BGP 网络中,一台路由器可以向它的一个 BGP 对等体发布一条下一跳为自己
的缺省路由,也可以使用 network 向整个 AS 通告一条下一跳为自己的缺省路
由,另外,还可以根据需要在 BGP 路由器上手工配置静态缺省路由。
第一种方法:default-route-advertise
bgp 100
peer 192.168.14.1 default-route-advertise
第二种方法:network 0.0.0.0 手工写一条缺省路由,在 BGP 中通告
ip route-static 0.0.0.0 0.0.0.0 NULL 0
bgp 100
network 0.0.0.0 0.0.0.0
第三种方法:手工添加一条静态缺省路由
ip route-static 0.0.0.0 0.0.0.0 192.168.12.2
IGMP 知识点
1.组播 multicast
单播(Unicast)是在一台源 IP 主机和一台目的 IP 主机之间进行。
广播(Broadcast)是在一台源 IP 主机和网络中所有其它的 IP 主机之间进行
组播(Multicast)是在一台源 IP 主机和多台(一组)IP 主机之间进行,中间的
交换机和路由器根据接收者的需要,有选择性地对数据进行复制和转发。
2.组播基本架构
组播源到路由器:组播源生成组播数据,完成数据封装并发送给网关路由器。
路由器到路由器:路由器根据接收者的分布情况有选择地对数据进行复制和转发。
路由器到接收端:路由器收到组播数据并发送给相应的接收者。
ASM 全称为 Any-Source Multicast,译为任意源组播
SSM 全称为 Source-Specific Multicast,译为指定源组播。
3.组播地址
224.0.0.1 地址(表示同一网段内所有主机和路由器)
224.0.0.2 地址(本地网段内的所有组播路由器)
224.0.0.13 地址( PIM 路由器)
4.IGMPV1 V2 V3
IGMP(Internet Group Management Protocol,因特网组管理协议)
IGMP 有 3 个版本,分别 是 IGMPv1、IGMPv2、IGMPv3.
IGMPv1 主要基于查询和响应机制来完成组播组的管理。主机通过发送 report 消息加入到某组播组,主机离开组播时不发送离开报文,离开后再收到路由器发送的查询消息时不反馈 report 消息,待维护组成员关系的定时器超时后,路由器会自动删除该主机的成员记录。
IGMPv2 与 IGMPv1 基本相似,主机的不同点在于 IGMPv2 具有某些报文抑制机制,可以减少不必要的 IGMP 重复报文,从而节省网络带宽资源,另外,主机离开组播组时,会主动向路由器发送离开报文。
IGMPv1 和 IGMPv2 报文中都只能携带组播组的信息,不能携带组播源的信息,所以主机只能选择加入某个组,而不能选择组播源,这一问题在 IGMPv3 中得到了解决。运行 IGMPv3 时,主机不仅能够选择组,还能根据选择组播源。主机发送的 IGMPv3 报文中可以包含多个组记录,每个组记录中可以包含多个组播源
PIM: Protocol Independent Multicast 协议无关组播。目前常用版本是PIMv2,PIM 报文直接封装在 IP 报文中,协议号为 103,PIMv2 组播地址为224.0.0.13。
PIM-DM ( Protocol Independent Multicast Dense Mode)
PIM-SM ( Protocol Independent Multicast Sparse Mode)是两个常见的组播路由协议
RPF(Reverse Path Forwarding,逆向路径转发)。
PIM-DM :采用“推(Push)模式”转发组播报文。
PIM-DM 假设网络中的组成员分布非常稠密,每个网段都可能存在组成员。
缺点:在组播成员分布较为稀疏的网络中,组播流量的周期性扩散会给网络带来较大负担。
组播分发树是指从组播源到接收者之间形成的一个单向无环数据传输路径。组播分发树有两类:SPT 和 RPT。
其设计思想是:
首先将组播数据报文扩散到各个网段。然后再裁剪掉不存在组成员的网段。通过周期性的“扩散—剪枝”,构建并维护一棵连接组播源和组成员的单向无环SPT。
PIM-DM 的关键工作机制包括邻居发现、扩散与剪枝、状态刷新、嫁接和断言。
在 PIM-DM 网络中,路由器周期性发送 Hello 消息来发现、建立并维护邻居关系。
pim timer hello interval,在接口视图下配置发送 Hello 消息的时间间隔。Hello 消息默认周期是 30 秒。
pim hello-option holdtime interval,在接口视图下配置 Hello 消息超时时间值。默认情况超时时间值为 105 秒。
DR 充当 IGMPv1 的查询器。
接口 DR 优先级大的路由器将成为该 MA 网络的 DR,在优先级相同的情况下,
接口 IP 地址大的路由器将成为 DR。
Assert 竞选规则如下:
到组播源的单播路由协议优先级较小者获胜。
如果优先级相同,则到组播源的路由协议开销较小者获胜。
如果以上都相同,则连接到接受者 MA 网络接口 IP 地址最大者获胜
PIM-SM :使用“拉(Pull)模式”转发组播报文。
PIM-SM 假设网络中的组成员分布非常稀疏,几乎所有网段均不存在组成员,直到某网段出现组成员时,才构建组播路由,向该网段转发组播数据。一般应用于组播组成员规模相对较大、相对稀疏的网络。
PIM-SM 的关键机制包括邻居建立、DR 竞选、RP 发现、RPT 构建、组播源注册、SPT 切换、Assert
汇聚点 RP(Rendezvous Point)
RP 的作用:
RP 是 PIM-SM 域中的核心路由器,担当 RPT 树根节点。
共享树里所有组播流量都要经过 RP 转发给接收者。
运行 PIM-SM 的网络,都会进行 DR(Designated Router)的选举。其中有两种 DR 分别称为接收者侧 DR 和组播源侧 DR。
组播接收者侧 DR:与组播组成员相连的 DR,负责向 RP 发送(*,G)的 Join加入消息。
组播源侧 DR:与组播源相连的 DR,负责向 RP 发送单播的 Register 消息。
修改 DR 优先级
int g0/0/0
pim hello-option dr-priority 2
Switchover 机制
从组播源到接收者的路径不一定是最优的,并且 RP 的工作负担非常大。为此,我们可以启用 RPT 向 SPT 进行的切换机制。
通过 RPT 树到 SPT 树的切换,PIM-SM 能够以比 PIM-DM 更精确的方式建立SPT 转发树。
使用配置命令来禁止切换
pim
spt-switch-threshold infinity
PIM-SM 的 RP
一个 PIM-SM 网络中可以存在一个或多个 RP 。一个 RP 可以对应若干个组播组,负责这些组播组的注册消息的处理、加入消息的处理以及组播数据的转发,但是同一个组播组只能对应一个 RP 。RP 是 PIM-SM 网络的核心,网络中的路由器必须知道 RP 的地址。
RP 有两种形式:静态 RP 和动态 RP。
静态 RP 是由人工选定的,PIM 网络中的所有 PIM 路由器上都需要逐一进行配置。通过配置,每台路由便知道了静态 RP 的地址。
动态 RP 的确定过程相对比较复杂一些,在 PIM 网络中人工选定并配置若干台PIM 路由器,使得它们成为 C-RP( Candidate-RP ),RP 将从 C-RP 中选举产生。如果 C-RP 只有一个,则 RP 就是这个 C-RP。如果有多个 C-RP ,则优先级最高者(优先级数值越小优先级超高,缺省值是 0)将会被选举为 RP,如果通过优先级比较无法选举出 RP,则依靠 Hash 算法算出的数值来决定 RP,数值最大者将成为 RP(Hash 算法参数:组地址、掩码长度、C-RP 地址),如果通过 Hash 数值也无法确定出 RP ,则拥有最高 IP 地址的 C-RP 将成为RP 。
选定和配置 C-RP 时,还必须同时选定和配置 C-BSR (Candidate-BootStrap Router),并由C-BSR 选举产生出一个 BSR。如果有多个 C-BSR,则拥有最高IP 地址的 C-BSR 将成为 BSR。BSR 是 PIM-SM 网络的管理核心,它负责收集网络中 C-RP 发出的 Advertisement 宣告信息,并计算出与每个组播组对应的 RP ,然后将 RP 的信息发布到整个 PIM-SM 网络中。BSR 动态映射组播组与 RP 的关系静态 RP
pim
static-rp 11.11.11.11
动态 RP
int LoopBack 0
pim sm
pim
c-rp LoopBack 0
路由控制知识点
1.ACL
ACL 的常用类型:基本 ACL,高级 ACL,二层 ACL,用户自定义 ACL 等,其中应用最为广泛的是基本 ACL 和高级 ACL。基本 ACL 可以根据源 IP 地址、报文分片标记和时间段信息来定义规则。高级 ACL 可以根据源/目的 IP 地址、TCP 源/目的端口号、UDP 源/目的端口号、协议号、报文优先级、报文大小、时间段等信息来定义规。高级 ACL 可以比基本 ACL 定义出精细度更高的规则。
基本 ACL :2000-2999
高级 ACL :3000-3999
二层ACL :4000 ~ 4999
用户自定义ACL:5000~5999
把接口加入到相应的区域后,就可以实施基于安全区域的 ACL。
在配置时,要注意路由器的防火墙特性:流量方向。
从较高安全级别区域去往较低安全级别区域的报文称为 outbound 报文
从较低安全级别区域去往较高安全级别区域的报文称为 inbound 报文
2.Route-policy
由一个或多个节点(Node)构成,Node 之间是“或”的关系。
每个 Node 都有一个编号,路由项按照 Node 编号由小到大的顺序通过各个Node。每个 Node 下面可以有若干个 if-match 和 apply 子句(特殊情况下可以完全没有 if-match 和 apply 子句),if-match 之间是“与”关系。If-match子句用来定义匹配规则,即路由项通过当前 Node 所需要满足的条件,匹配对象是路由项的某些属性,比如路由前缀,Next Hop ,cost ,路由优先级等,apply子句用来规定处理动作。
3.PPPoE (Point to Point Protocol over Ethernet) 基于以太网的点对点协议
运营商希望通过同一台接入设备来连接远程的多个主机,同时接入设备能够提供访问控制和计费功能。在众多的接入技术中,把多个主机连接到接入设备的最经济的方法就是以太网,而 PPP 协议可以提供良好的访问控制和计费功能,于是产生了在以太网上传输 PPP 报文的技术,即 PPPoE。
PPPoE 利用以太网将大量主机组成网络,通过一个远端接入设备连入因特网,并运用 PPP 协议对接入的每个主机进行控制,具有适用范围广、安全性高、计费方便的特点。
PPPoE 分为 2 个阶段,discovery 发现阶段和 session 会话阶段。
一、discovery 阶段,是进行 pppoe 的发现和响应阶段。
二、session 阶段,是进行 ppp 链路建立的阶段
4.Eth-Trunk
Eth-Trunk 是一种捆绑技术,它将多个物理接口捆绑成一个逻辑接口,这个逻辑接口就称为 Eth-Trunk 接口,捆绑在一起的每个物理接口称为成员接口。EthTrunk 只能由以太网链路构成。
手动负载均衡(manual load-balance)模式
LACP(Link Aggregation Control Protocol)模式
Trunk 的优势在于:
增加带宽:Eth-Trunk 接口的带宽是各成员接口带宽的总和。
提高可靠性:当某个成员链路出现故障时,流量会自动的切换到其他可用的链路上,从而提供整个 Eth-Trunk 链路的可靠性。
负载分担:在一个 Eth-Trunk 接口内,通过对各成员链路配置不同的权重,可以实现流量负载分担
5.VLAN
交换机的 VLAN 端口可以分为 Access , Trunk 和 Hybrid 3 种类型。Access端口是交换机上用来直接连接用户终端的端口,它只允许属于该端口的缺省VLAN 的帧通过。Access 端口发往用户终端的帧一定不带 VLAN 签。Trunk 端口是交换机上用来连接其他交换机的端口,它可以允许属于多个 VLAN 的帧通过。Hybrid 端口是交换机上既可以连接用户终端,又可以连接其他交换机的端口。Hybrid 端口也可以允许属于多个 VLAN 的帧通过,并且可以在出端口的方向上将某些 VLAN 帧的标签剥掉。
interface g0/0/3
port link-type access
port default vlan 30
int g0/0/24
port link-type trunk
port trunk allow-pass vlan 10 20 30
6.MUX VLAN
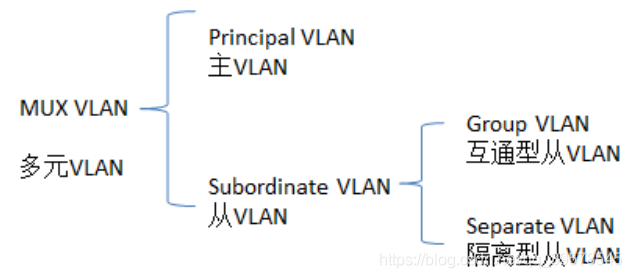
MUX VLAN(Multiplex vlan )提供了一种在 VLAN 内的端口间进行二层流量隔离的机制。MUX VLAN 分为 Principal VLAN 和 Subordinate VLAN,
Subordinate VLAN 又分为 Separate VLAN 和 Group VLAN。在一个主 VLAN中,隔离型从 VLAN 有一个,互通型从 VLAN 可以有多个
 vlan 10
vlan 10
mux-vlan
subordinate group 20
subordinate separate 30
交换机端口开启 Mux VLAN 功能
int g0/0/1
port mux-vlan enable
7.端口隔离
为了实现用户之间的二层隔离,可以将不同的用户加入不同的 VLAN,但这样会浪费有限的 VLAN 资源。采用端口隔离功能,可以实现同一 VLAN 内端口之间的隔离。用户只需要将端口加入到同一隔离组中,就可以实现隔离组内端口之间二层数据的隔离。端口隔离功能为用户提供了更安全、更灵活的组网方案。
int g0/0/1
port-isolate enable group 1
int g0/0/2
port-isolate enable group 1
display port-isolate group 1 查看所有创建的隔离组情况
8.端口安全
配置端口安全功能,将接口学习到的 MAC 地址转换为安全 MAC 地址,接口学习的最大 MAC 数量达到上限后不再学习新的 MAC 地址,只允许学习到 MAC地址的设备通信。这样可以阻止其他非信任用户通过本接口和交换机通信,提高设备与网络的安全性。
restrict :丢弃源 MAC 地址不存在的报文并上报告警。推荐使用 restrict 动作。
protect : 只丢弃源 MAC 地址不存在的报文,不上报告警。
shutdown : 接口状态被置为 error-down,并上报告警。
int g0/0/1 port-security enable,使能端口安全功能。
port-security mac-address sticky,使能接口 Sticky MAC 功能。
port-security max-mac-num max-number,配置接口 Sticky MAC 学习限制数量。 缺省情况下,接口学习的 MAC 地址限制数量为 1。
(可选)port-security protect-action { protect | restrict | shutdown },配置端口安全保护动作。 缺省情况下,端口安全保护动作为 restrict。
(可选)执行命令 port-security mac-address sticky mac-address vlan vlanid,手动配置一条 sticky-mac 表项。
int g0/0/1
port-security max-mac-num 2
port-security mac-address sticky
port-security protect-action protect
9.Q in Q
qinq(dot1q in dot1q)是一种二层环境中的二层技术,用于二层 ISP 网络将相同客户网络中的 vlan 帧,再打一层 vlan-tag 的手段实现同一个客户的不同站点之间的数据通信。
qinq 的配置类型分为端口 qinq 和灵活 qinq
端口 qinq 是在 isp 设备入端口收到多个帧都打上同一个外层 tag 发送到对端
灵活 qinq 是在 isp 设备入端口根据收到的不同客户 vlan 帧打上不同的外层vlan-tag 发送到对端的模式
int g0/0/2
port link-type dot1q-tunnel 启用端口 qinq 模式,qinq 通道
port default vlan 100 isp 设备接口收到的帧全部在外侧打上 vlan100 tag
灵活的 qinq 可以根据需求将客户网络的多个 vlan 集合分别对应 isp 内的多个vlan 集合,如上述拓扑中客户 site 中的 vlan2、vlan3 在进入 isp 网络的时候分别在外层打上 vlan100、vlan200 的外层 tag 传递到对端的 site 中
int g0/0/2
port link-type hybrid
qinq vlan-translation enable
port hybrid untagged vlan 100 200
port vlan-stacking vlan 2 stack-vlan 100
port vlan-stacking vlan 3 stack-vlan 200
生成树协议
1.STP Spanning Tree Protocol :生成树协议
STP :IEEE 802.1d
RSTP:IEEE 802.1w
MSTP:IEEE 802.1s
STP 从初始状态到完全收敛至少需经过 30s:
STP 选路规则:
每个网络只有一个根桥
每个非根桥都要选出一个根端口
每个 Segment 只有一个指定端口
非指定端口将被堵塞
bridge ID 由两部分组成:Bridge 优先级和 MAC 地址,默认优先级为 32768。
根端口选举:依据该端口的根路径开销、对端 BID(Bridge ID)、对端 PID(Port
ID)和本端 PID。
指定端口选举:依据该端口的根路径开销、BID、PID
2.STP 有 3 个常用的计时器
Hello Time 定时器:2s
Max Age 定时器:20s
Forwarding Delay 定时器:15s
3.RSTP 定义了两种新的端口角色:备份端口(Backup Port)和预备端口
(Alternate Port)。
AP 是 RP 的备份
BP 是 DP 的备份
RSTP 在选举的过程中加入了“发起请求-回复同意”(P/A 机制)这种确认机制,由于每个步骤有确认就不需要依赖计时器来保证网络拓扑无环才去转发,只需要考虑 BPDU 发送报文并计算无环拓扑的时间(一般都是秒级)。
4.RSTP 端口状态共有 3 种,即 discarding ,learning 和 forwarding
5.在 RSTP 或 MSTP 交换网络中,为了防止恶意或临时环路的产生,可配置保护功能来增强网络的健壮性和安全性。
BPDU 保护
根保护
环路保护
防止 TC-BPDU 攻击
BPDU保护(有边缘端口的交接机,全局配置)
在交换设备上,通常将直接与用户终端或文件服务器等非交换设备相连的端口配置为边缘端口,边缘端口一般不会收到BPDU。如果有人伪造BPDU恶意攻击交换机,边缘端口接收到BPDU后,交换机会自动将边缘端口设置为非边缘端口,并重新进行生成树计算,从而引起网络震荡。交换机上启动了BPDU保护功能后,如果边缘端口收到了BPDU,那么边缘端口将被关闭,但是边缘端口属性不变,同时通知网管系统。被关闭的边缘端口只能由网络管理员手动恢复,如果需要被关闭的边缘端口自动恢复,可以配置端口自动恢复功能,并设置延迟时间。
根保护(交接机的 DP 端口,接口配置)
由于维护人员的错误配置或网络中的恶意攻击,网络中的合法根交换机有可能会收到优先级更高的BPDU,使得合法根交换机失去根交换机的地位,从而引起网络拓扑结构的错误变动。这种不合法的拓扑变化,可能会导致原来应该通过高速链路的流量被牵引到低速链路上,造成网络拥塞。对于启用了根保护功能的端口,其端口角色不能成为根端口,**一旦启用根保护功能的指定端口收到
了优先级更高的BPDU时,端口将进入Discarding状态,不再转发报文。**在经过一段时间(通常为 2 倍的 Forward Delya, 30s)后,如果端口一直没有再收到优先级更高的BPDU,端口会自动恢复到正常的Forwarding状态。
环路保护(有阻塞端口的交接机,端口配置)
在运行RSTP或MSTP的协议网络中,根端口和其他阻塞端口的状态是依靠上游交换机为断发来的BPDU进行维持的。当由于链路拥塞或者单向链路故障导致这些端口收不到来自上游交换机的BPDU时,交换机就会重新选择根端口。原先的根端口会转变为指定端口,而原先的阻塞端口会迁移到转发状态,从而造成交换机中可能产生环路。在启动了环路保护功能后,如果根端口或Alternate端口长时间收不到来自上游的BPDU,则会向网络管理员发送通知信息,如果是根端口则进入Discarding状态,阻塞端口则会一直保持在阻塞状态,不转发报文,从而不会在网络中形成环路。直到根端口或Alternate端口收到BPDU后,端口状态才恢复到Forwarding状态。
防止TC-BPDU攻击(所有交接机,全局配置)
交换机在接收到TC BPDU后,会执行MAC地址表项和ARP表项的删除操作。如果有人伪造了TC BPDU报文恶意攻击交换机,交换机在短时间内会收到很多TC BPDU报文,频繁的删除操作会给设备造成很大的负担,给网络的稳定性带来很大隐患。启用防TC BPDU报文攻击功能后,可以配置交换机在单位时间内处理TC BPDU报文的次数。如果在单位时间内,交换机收到的TC BPDU报文数量大于配置的阈值,交换机只会处理阈值指定的次数。对于其他超出阈值的TC BPDU报文,定时器到期后设备只对其统一处理一次。这样可以避免频繁地删除MAC地址表项和ARP表项,从而达到保护设备的目的。
6.多生成树协议 MSTP(Multiple Spanning Tree Protocol)
MST 域是多生成树域(Multiple Spanning Tree Region),由交换网络中的多台交换设备以及它们之间的网段所构成。
MSTP 同域的三要素就是域名、实例和 vlan 映射、修订级别
stp instance 1 root secondary
stp instance 2 priority 0
stp region-configuration
region-name huawei
revision-level 1
instance 1 vlan 10
instance 2 vlan 20
active region-configuration
MPLS
1.MPLS (Multi-Protocol Label Switching, 多协议标签交换)
根据数据流的方向,LSP 的入口 LER 被称为入节点(Ingress);位于 LSP 中间的 LSR 被称为中间节点(Transit);LSP 的出口 LER 被称为出节点(Egress)。
0~15: 特殊标签。如标签 3,称为隐式空标签,用于倒数第二跳弹出;
16~1023: 静态 LSP 和静态 CR-LSP(Constraint-based Routed Label Switched Path)共享的标签空间;
1024 及以上:LDP、RSVP-TE(Resource Reservation Protocol-Traffic Engineering)、MP-BGP
2.标签的发布方式:华为采用 DU 下游自主
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









