







总结
-
框架原理真的深入某一部分具体的代码和实现方式时,要多注意到细节,不要只能写出一个框架。
-
算法方面很薄弱的,最好多刷一刷,不然影响你的工资和成功率😯
-
在投递简历之前,最好通过各种渠道找到公司内部的人,先提前了解业务,也可以帮助后期优秀 offer 的决策。
-
要勇于说不,对于某些 offer 待遇不满意、业务不喜欢,应该相信自己,不要因为当下没有更好的 offer 而投降,一份工作短则一年长则 N 年,为了幸福生活要慎重选择!!!
喜欢这篇文章文章的小伙伴们点赞+转发支持,你们的支持是我最大的动力!
// V8函数绑定示例
static void LogCallback(const v8::FunctionCallbackInfov8::Value& args){…}
…
// Create a template for the global object and set the
// built-in global functions.
v8::Localv8::ObjectTemplate global = v8::ObjectTemplate::New(isolate);
global->Set(v8::String::NewFromUtf8(isolate, “log”),
v8::FunctionTemplate::New(isolate, LogCallback));
// Each processor gets its own context so different processors
// do not affect each other.
v8::Persistentv8::Context context =
v8::Context::New(isolate, nullptr, global);
以小程序环境为例,小程序容器初始化时,会分别创建Render和Worker,Render负责界面渲染,Worker负责执行业务逻辑,拥有独立JSContext,Canvas提供了createCanvas()和createOffscreenCanvas() 全局函数需要绑定到该JSContext的GlobalObject上,因此Worker需要有一个时机通知canvas注入API,从小程序视角来看,Worker依赖Canvas显然不合理,因此小程序提供了插件机制,每个插件都是一个动态库,Canvas作为插件先注册到Worker,随后Worker创建之后会扫描一遍插件,依次dlopen每个插件并执行插件的初始化函数,将JSContext作为参数传给插件,这样插件就可以向JSContext中绑定API了。
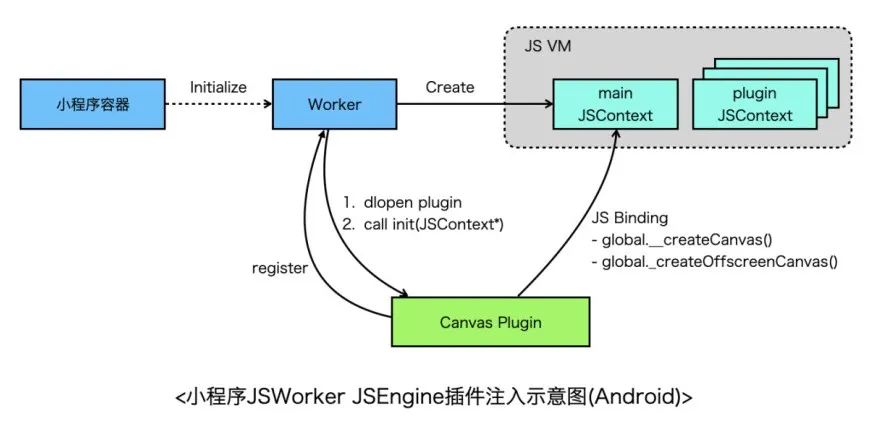
关于JSEngine和Binding有两个需要注意的点(以V8为例):
-
关于线程安全。JSContext通常设计为非线程安全的,需要注意不要在非JS线程中访问JS资源。其次,在V8中一个线程可能有多个JSContext,需要使用v8::Context::Scope切换正确的JSContext;
-
关于Binding对象的生命周期。众所周知,C与JS语言内存管理方式不一样,C需要开发者手动管理内存,JS由虚拟机管理。对于C++ Binding的JS对象的生命周期理论上需要跟普通JS对象一致,因此需要有一种机制,当JS对象被GC回收时,需要通知到C++ Binding对象,以便执行相应的析构函数释放内存。事实上,JS引擎通常会提供让一个JS对象脱离/回归GC管理的机制,且JS对象的生命周期均有钩子函数可以进行监听。V8中有Handle(句柄)的概念,Handle分为LocalHandle、PersistentHandle、Weak PersistentHandle。LocalHandle在栈上分配,由HandleScope控制其作用域,超出作用域即被标记为可释放,PersistentHandle在堆上分配,生命周期长,通常需要开发者显式通过PersistentHandle#Reset的方式释放对象。通过SetWeak函数可以让一个PersistentHandle转为一个Weak PersistentHandle,当没有其他引用指向Weak句柄时就会触发回调,开发者可以在回调中释放内存。
最后再讨论下Binding代码如何跨JSEngine的问题。
当前主流的JSEngine有V8、JavaScriptCore、QuickJS等,如果需要更换JSEngine的话,Binding代码需要重写,成本有点高(Canvas接口非常多),因此理论上可以再封装一个抽象层,屏蔽不同引擎的差异,对外提供一致接口,基于抽象层编写一次Binding代码,就可以适配到多个JSEngine(使用IDL生成代码是另外一条路),目前我们使用了UC团队提供的JSI SDK适配多JS引擎。
平台窗体抽象层设计
要想做到跨平台,就需要设计一个抽象的平台胶水层,胶水层的职责是对下屏蔽各个平台间的实现差异,对上为Canvas提供统一的接口操作Surface,封装MakeCurrent、SwapBuffer等行为。实现上可以借鉴Flutter Engine,Flutter Engine的Shell模块对GL胶水层做了较好的封装,可以无缝接入到Android、iOS等主流平台,扩展到新平台比如鸿蒙OS也不在话下。
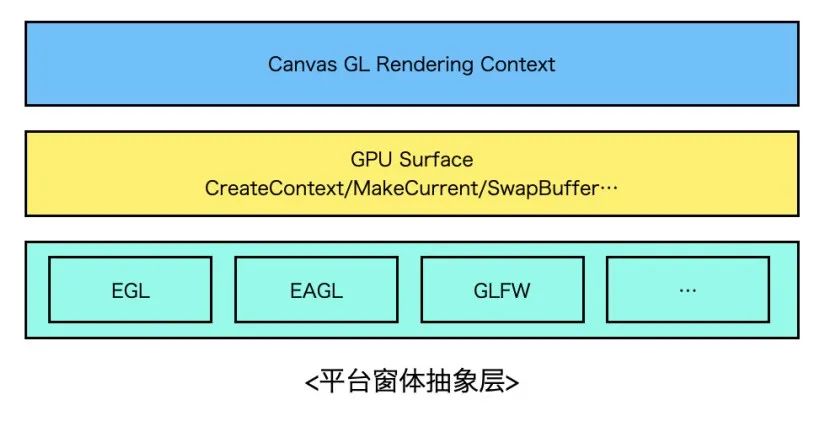
当设计好GL胶水层接口后,分平台进行实现即可。以Android为例,如果想创建一个GL上下文并绘制到屏幕上,必须通过EGL绑定平台窗体环境,即Surface或者是ANativeWindow对象,而能够创建Surface的View只有SurfaceView和TextureView(如果是一个全屏游戏没有其他Native View的话,还可以考虑直接使用NativeActivity,这里先不考虑这种情况),应该如何选择?这里可以从渲染原理上分析下两者的差异再分场景进行决策。
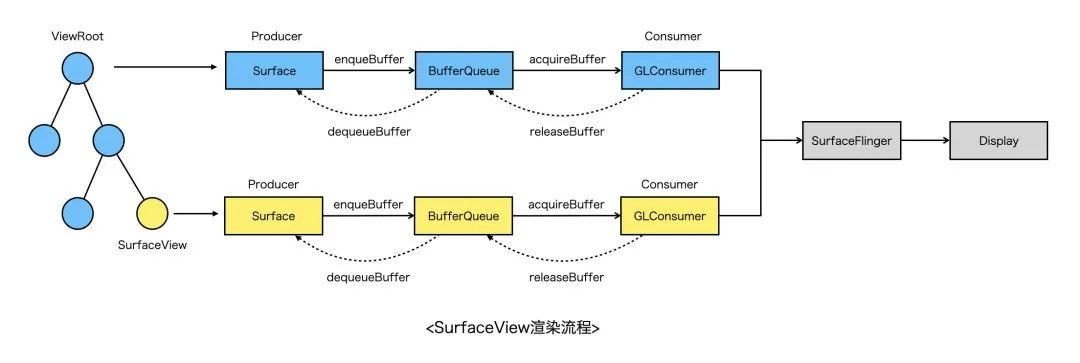
先看SurfaceView的渲染流程,简单来说分为如下几个步骤(硬件加速场景):
-
通过SurfaceView申请的Surface创建EGL环境;
-
Surface通过dequeueBuffer向SurfaceFlinger请求一块GraphicBuffer(可理解为一块内存,用于存储绘图数据),随后所有绘制内容都会写到这块Buffer上;
-
当调用EGL swapBuffer之后,会将GraphicBuffer入队到BufferQueue;
-
SurfaceFlinger在下一个VSYNC信号到来时,取GraphicBuffer,进行合成上屏;
对比SurfaceView,TextureView的渲染流程更长一些,主要经历以下关键阶段:
-
通过TextureView绑定的SurfaceTexture创建EGL环境;
-
生产端(Surface)通过dequeueBuffer从SurfaceTexture管理的BufferQueue中获得一块GraphicBuffer,后续所有绘制内容都会写到这块Buffer上;
-
当调用EGL swapBuffer之后,会将GraphicBuffer入队到SurfaceTexture内部的BufferQueue;
-
随后TextureView触发frameAvailable,通知系统进行重绘(view#invalidate);
-
系统在下次VSYNC信号到来的时候进行重绘,在UI线程生成DisplayList,然后驱动渲染线程进行真正渲染;
-
渲染线程会将步骤2中的GraphicBuffer作为一张特殊的纹理(GL_TEXTURE_EXTERNAL_OES)上传,与View Hierarchy上其他视图一起通过SurfaceFlinger进行合成;
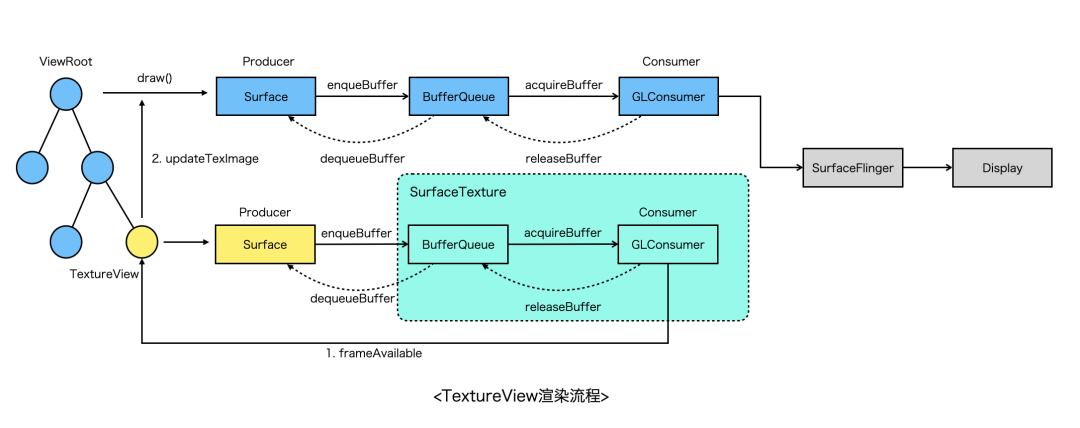
由以上两者的渲染流程对比可发现,SurfaceView的优势是渲染链路短、性能好,但是相比普通的View,没法支持Transform动画,通常全屏的游戏、视频播放器优先选择SurfaceView。而TextureView则弥补了SurfaceView的缺陷,它跟普通的View完全兼容,同样会走HWUI渲染,不过缺陷是内存占用比SurfaceView高,渲染需要在多个线程之间同步整体性能不如SurfaceView。
具体如何选择需要分场景来看,以我们为例,我们这边同时支持在SurfaceView和TextureView中渲染,但是由于目前主要服务于淘宝小程序互动业务,而在小程序容器中,需要通过UC提供的WebView同层渲染技术将Canvas嵌入到WebView中,由于业务上需要同时支持全屏和非全屏互动,且需要支持各种CSS效果,因此只能选择EmbedSurface模式,而EmbedSurface不支持SurfaceView,因此我们选择的是TextureView。
渲染管线
Canvas渲染引擎的核心当然是渲染了,上层的互动业务的性能表现,很大程度取决于Canvas的渲染管线设计是否足够优秀。这一部分会分别讨论Canvas2D/WebGL的渲染管线技术选型及具体的方案设计。
▐ Canvas2D Rendering Context
从Canvas2D标准来看,引擎需要提供的原子能力如下:
软件渲染指的是使用CPU渲染图形,而硬件渲染则是利用GPU。使用GPU的优势一方面是可以降低CPU的使用率,另外GPU的特性(擅长并行计算、浮点数运算等)也使其性能通常会更好。但是GPU在发展的过程中,更多关注的是三维图形的运算,二维矢量图形的渲染似乎关注的较少,因此可以看到像freetype、cairo、skia等早期主要都是使用CPU渲染,虽然khronos组织推出了OpenVG标准,但是也并没有推广开来。目前主流的移动设备都自带GPU,因此对于Canvas2D的技术选型来说,我们更倾向于使用硬件加速的引擎,具体分析可以接着往下看。
Canvas2D的实现成本颇高,从零开始写也不太现实,好在社区中有很多关于Canvas 2D矢量绘制的库,这里仅列举了一部分比较有影响力的,主要从backend、成熟度、移植成本等角度进行评判,详细如下表所示。
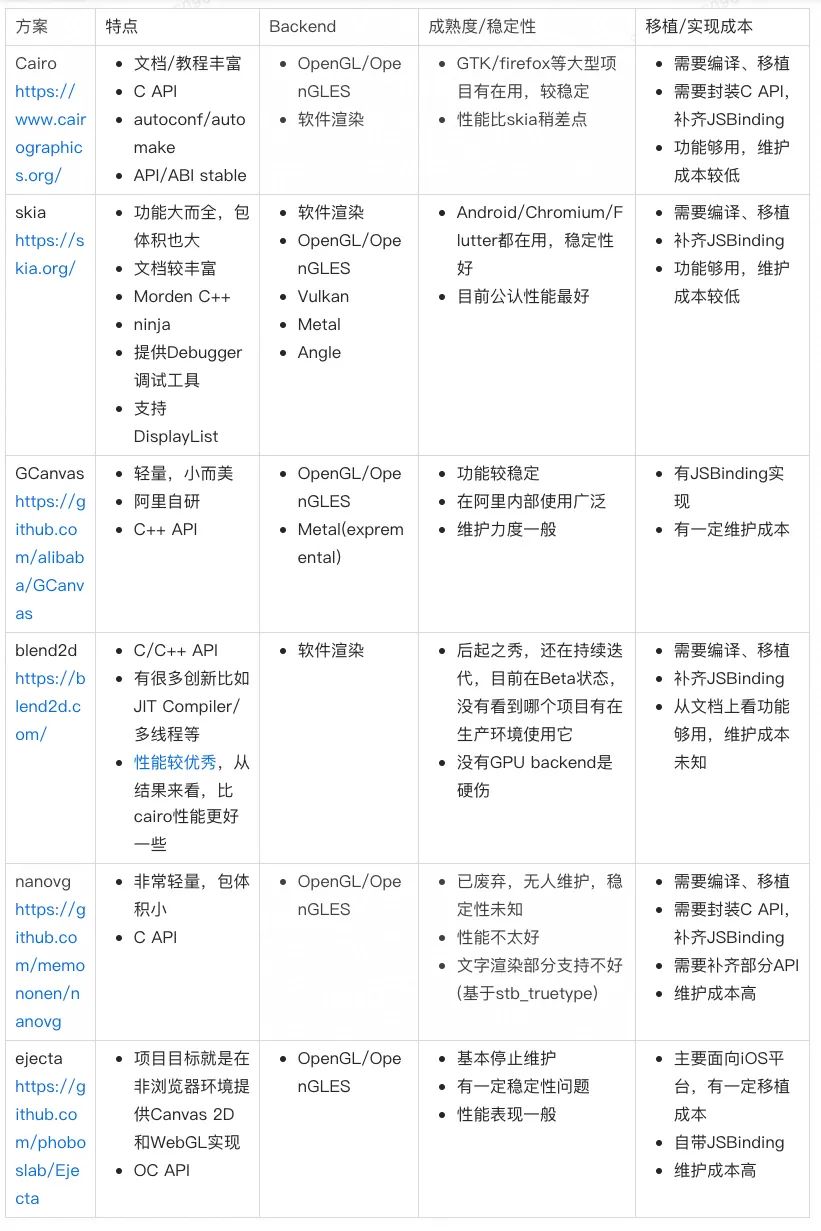
Cairo和Skia是老牌的2D矢量图形渲染引擎了,成熟度和稳定性都很高,且同时支持软件与硬件渲染(cairo的硬件渲染支持比较晚),性能上通常skia占优(也看具体case),不过体积大的多。nanovg和GCanvas以小而美著称,性能上GCanvas更优秀一点,nanovg需要经过特别的定制与调优,文字渲染也不尽如人意。Blend2D是一个后起之秀,通过引入并发渲染、JIT编译等特性宣称比Caico性能更优,不过目前还在beta阶段,且硬伤是只支持软件渲染,没办法利用GPU硬件能力。最后ejecta项目最早是为了在非浏览器环境支持W3C Canvas标准,有OpenGLES backend,自带JSBinding实现,不过可惜的是现在已无人维护,性能表现也比较一般。
我认为技术选型没有最好的方案,只有最适合团队的方案,从实现角度来看,以上列举的方案均可以达到目标,但是没有银弹,选择不同的方案对技术同学的要求、产品的维护成本、性能&稳定性、扩展性等均会产生深远的影响。以我们团队为例,业务形态上看主要服务于淘系互动小程序业务,面向的是淘宝开放平台上的商家、ISV开发者等, 我们对于Canvas渲染引擎最主要的诉求是跨平台渲染一致性、性能、稳定性,因此nanovg、blend2d、ejecta不满足需求。从团队资源的角度看,我们更倾向于使用开箱即用、维护成本低的方案,ejecta、GCanvas不满足需求。最后从组织架构上看,我们团队主要负责手淘跨平台相关产品,其中包括Flutter,而Flutter自带了skia,它同时满足开箱即用、高性能&高可用等特点,而且由于Chromium同样使用了skia,因此渲染一致性也得到了保证,所以复用skia对于我们来说是相对比较优的选择,但与此同时我们的包大小也增大了很多,未来需要持续优化包大小。
这里主要介绍下基于Skia的Canvas 2D渲染流程。JSBinding代码的实现较简单,可以参考chromium Canvas 2D的实现,这里就不展开了。
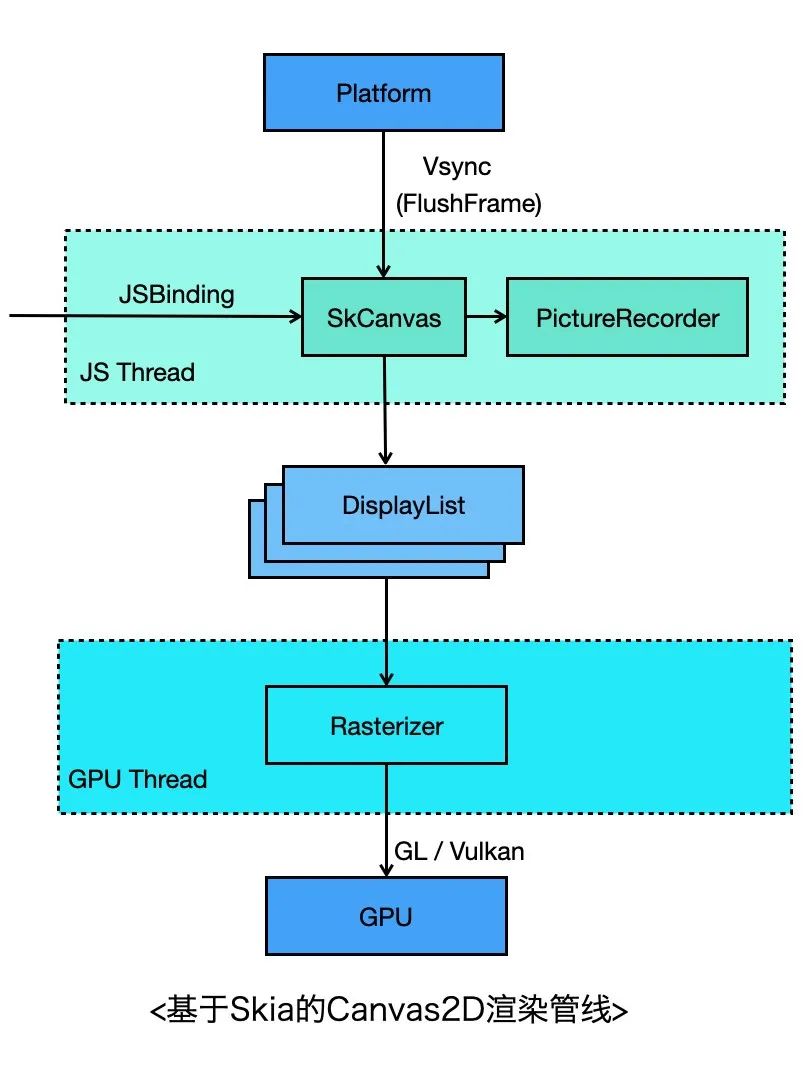
看下渲染的流程,关键步骤如下,其中4~6步与当前Flutter Engine基本保持一致:
-
开发者创建Canvas对象,并通过 Canvas.getContext(‘2d’) 获取2D上下文;
-
通过2D上下文调用Canvas Binding API,内部实际上通过SkCanvas调用Skia的绘图API,不过此时并没有绘制,而是将绘图命令记录下来;
-
当平台层收到Vsync信号时,会调度到JS线程通知到Canvas;
-
Canvas收到信号后,停止记录命令,生成SkPicture对象(其实就是个DisplayList),封装成PictureLayer,添加到LayerTree,发送到GPU线程;
-
GPU线程Rasterizer模块收到LayerTree之后,会拿到Picture对象,交给当前Window Surface关联的SkCanvas;
-
这个SkCanvas先通过Picture回放渲染命令,再根据当前backend选择vulkan、GL或者metal图形API将渲染指令提交到GPU。
文字渲染其实非常复杂,这里仅作简要介绍。
目前字体的事实标准是OpenType和TrueType,它们通过使用贝塞尔曲线的方式定义字体的形状,这样可以保证字体与分辨率无关,可以输出任意大小的文字而不会变形或者模糊。
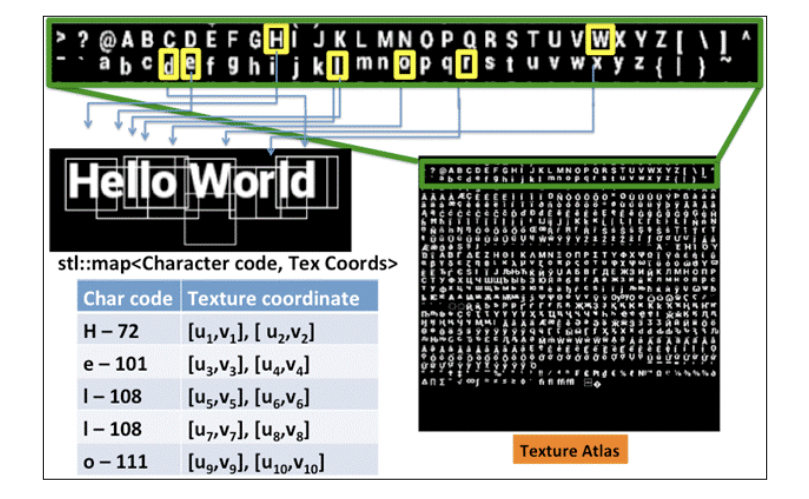
众所周知,OpenGL并没有提供直接的方式用于绘制文字,最容易想到的方式是先在CPU上加载字体文件,光栅化到内存,然后作为GL纹理上传到GPU,目前业界用的最广泛的是 Freetype 库,它可以用来加载字体文件、处理字形,生成光栅化的位图数据。如果每个文字对应一张纹理显然代价非常高,主流的做法是使用 texture atlas 的方式将所有可能用到的文字全部写到一张纹理上,进行缓存,然后根据uv坐标选择正确的文字,有点类似雪碧图。
以上还只是文字的渲染,当涉及到多语言、国际化时,情况会变得更加复杂,比如阿拉伯语、印度语中连字(Ligatures)的处理,LTR/RTL布局的处理等,Harfbuzz 库就是专门用来干这个的,可以开箱即用。
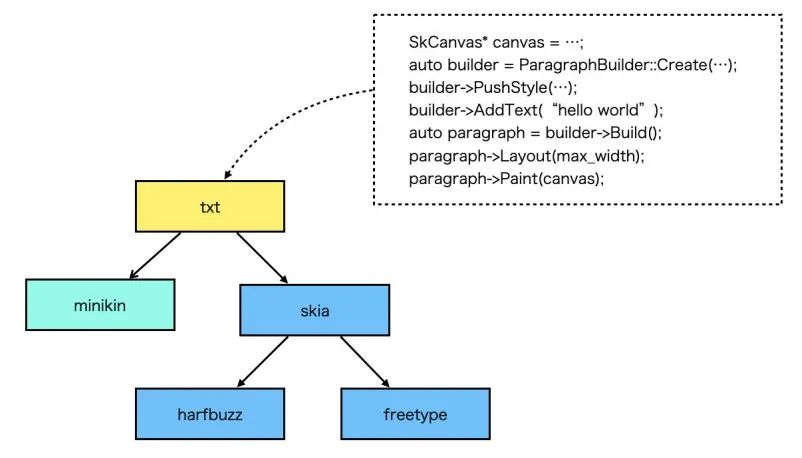
从Canvas2D的文字API来看,只需要提供文本测量和基本的渲染的能力即可,使用OpenGL+Freetype+Harfbuzz通常就够用了,但是如果是一个GUI应用如Android、Flutter,那么还需要处理断句断行、排版、emoji、字体库管理等逻辑,Android提供了一个minikin库就是用来干这个的,Flutter中的txt模块二次封装了minikin,提供了更友好的API。目前我们的Canvas引擎的文字渲染模块跟Flutter保持一致,直接复用libtxt,使用起来比较简单。
上面涉及到的一些库链接如下:
-
Freetype: https://www.freetype.org/
-
Harfbuzz: https://harfbuzz.github.io/
-
minikin: https://android.googlesource.com/platform/frameworks/minikin/
-
flutter txt:
https://github.com/flutter/engine/blob/master/third_party/txt
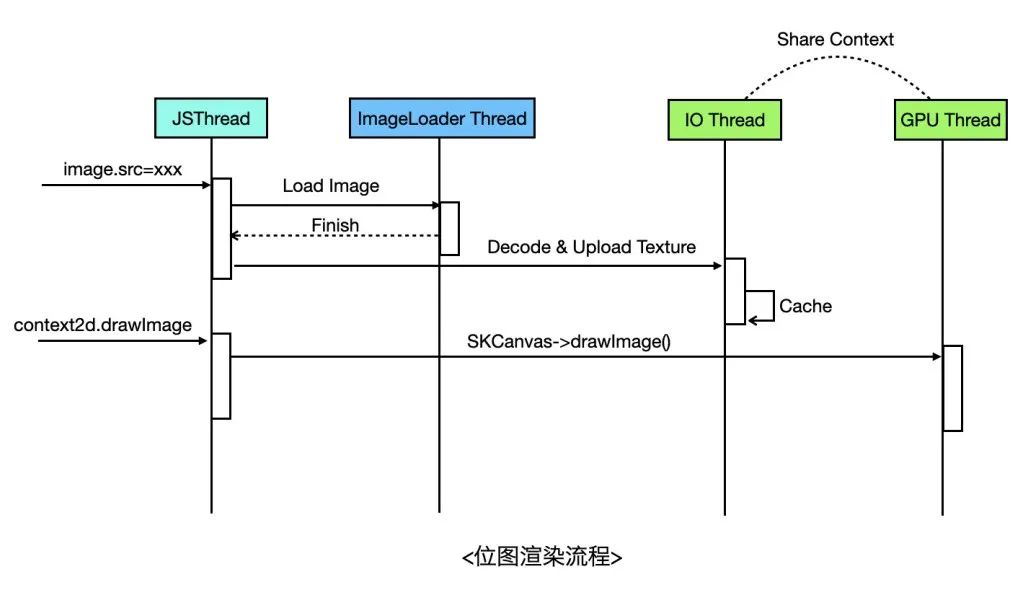
位图渲染的基本流程是下载图片 -> 图片解码 -> 获得位图像素数据 -> 作为纹理上传GPU -> 渲染位图,拿到像素数据后,就可以上传到GPU作为一张纹理进行渲染。不过由于上传像素数据也是个耗时过程,可以放到独立的线程做,然后通过Share GLContext的方式使用纹理,这也是Flutter目前的做法,Flutter会使用独立的IO线程用于异步上传纹理,通过Share Context与GPU线程共享纹理,与Flutter不一样的是,我们的图片下载和解码直接代理给原生的图片库来做。
▐ WebGL Rendering Context
WebGL实现比2D要简单的多,因为WebGL的API基本与OpenGLES一一对应,只需要对OpenGLES API简单进行封装即可。这里不再介绍OpenGL本身的渲染管线,而主要关注下WebGL Binding层的设计,从技术实现上主要分为单线程模型和双线程模型。
单线程模型即直接在JS线程发起GL调用,这种方式调用链路最短,在一般场景性能不会有大的问题。但是由于WebGL的API调用与业务逻辑的执行都在JS线程,而某些复杂场景每帧会调用大量的WebGL API,这可能会导致JS线程阻塞。

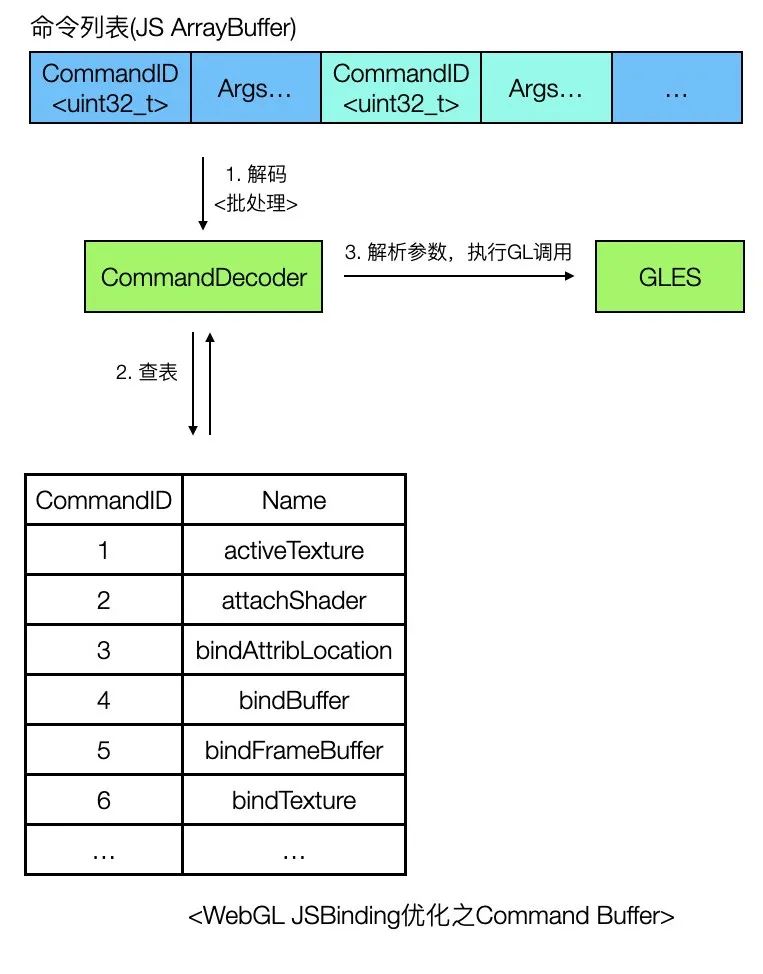
通过profile可以发现,这个场景JS线程的阻塞可能并不在GPU,而是在CPU,原因是JS引擎Binding调用本身的性能损耗也很可观,有一种优化方案是引入Command Buffer优化JSBinding链路损耗,如下图所示。
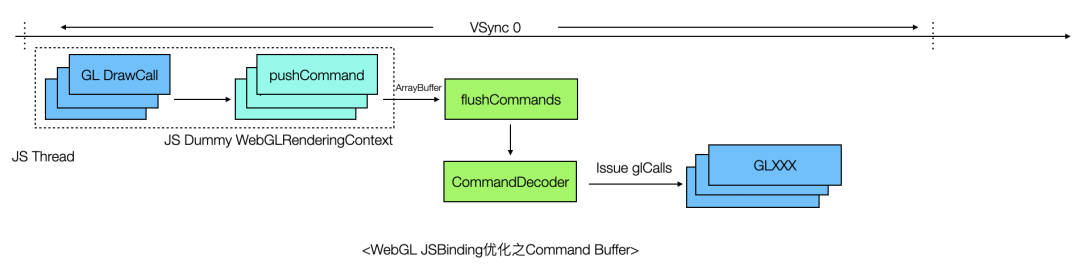
这个方案的思路是这样的,JS侧封装一个虚拟的 WebGLRenderingContext 对象,API与W3C标准一致,但是其实现并不调用Native侧的JSBinding接口,而是按照指定规则对WebGL Call进行编码,存储到ArrayBuffer中,然后在特定时机(如收到VSync信号或者时执行到同步API时)通过一个Binding接口(上图flushCommands)将ArrayBuffer一次性传到Native侧,之后Native对ArrayBuffer中的指令查表、解析,最后执行渲染,这样做可以减少JSBinding的调用频率,假设ArrayBuffer中存储了N条同步指令,那么只需要执行1次Binding调用,减少了(N-1)次Binding调用的耗时,从而提升了整体性能。
双线程模型指的是将GL调用转移到独立的渲染线程执行,解放JS线程的压力。具体的做法可以参考chromium GPU Command Buffer(注意这里的Command Buffer与上面提到的解决的并不是同一个问题,不要混淆),思路是这样的,JS线程收到Binding调用后,并不直接提交,而是先encode到Command Buffer(通常使用Ring buffer数据结构)缓存起来,随后在渲染线程中访问CommandBuffer,进行Decode,调用真正的GL命令,双线程模型实现要复杂的多,需要考虑Lock Free&WaitFree、同步、参数拷贝等问题,写的不好可能性能还不如单线程模型。
最后再提一句,在chromium中,不仅实现了多线程的WebGL渲染模型,还支持了多进程Command Buffer的模型,使用多进程模型可以有效屏蔽各种硬件兼容性问题,带来更好的稳定性。
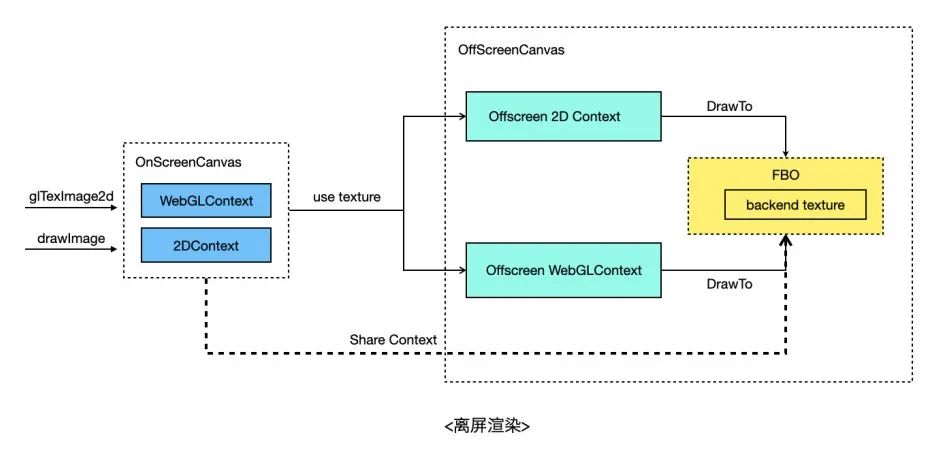
▐ 离屏渲染
离屏Canvas在Web中还是个实验特性,不过因为其实用性,目前主流的小游戏/小程序容器基本都实现了。使用到离屏Canvas的主要是2D的 drawImage 接口以及WebGL的 texImage2D/texSubImage2D 接口,WebGL通常会使用离屏Canvas渲染文本或者做一些游戏场景的预热等等。
离屏渲染通常会使用PBuffer或者FBO来实现:
-
PBuffer: 需要通过PBuffer创建新的GL Context,每次渲染都需要切换GL上下文;
-
FBO: FBO是OpenGL提供的能力,通过 glGenFramebuffers 创建FBO,可以绑定并渲染到纹理,并且不需要切换GL上下文,性能通常会更好些(没有做过测试,严格来说也不一定,因为目前移动端GPU主要采用TBR架构,切换FrameBuffer可能会造成Tile Cache失效,导致性能下降)。
除了上面两种方案之外,Android上还可以通过SurfaceTexture(本质上是EGLImage)实现离屏渲染,不过这是一种特殊的纹理类型,只能绑到GL_TEXTURE_EXTERNAL_OES上。特别地,对于2D来说,还可以通过CPU软件渲染来间接实现离屏渲染。
离屏渲染中比较影响性能的地方是上传离屏Canvas数据到在屏Canvas,如果先readPixels再upload性能会比较差。解决方案是将离屏Canvas渲染到纹理,再通过OpenGL shareContext的方式与在屏Canvas共享纹理。这样,对于在屏Canvas来说就可以直接复用这个纹理了,具体点,对于在屏2D Context的drawImage来说,可以基于该纹理创建texture backend SkImage,然后作为图片上传。对于在屏WebGL Context的texImage2D来说,有几种方式,一种方式提供非标API,调用该API将直接绑定离屏Canvas所对应的纹理,开发者不用自己再创建纹理。另一种方式是texImage2D时,通过FBO拷贝离屏纹理到开发者当前绑定的纹理上。还有一种方式是在texImage2D时,先删除用户当前绑定的纹理,然后再绑定到离屏Canvas所对应的纹理,这种方案有一定使用风险,因为被删除的纹理可能还会被开发者用到。
帧同步机制
所谓帧同步指的是游戏渲染循环与操作系统的显示子系统(在Android平台即为SurfaceFlinger)和底层硬件之间的同步。众所周知,在GPU加速模式下,我们在屏幕上看到的游戏或者动画需要先在CPU上完成游戏逻辑的运算,然后生成一系列渲染指令,再交由GPU进行渲染,GPU的渲染结果写入FrameBuffer,最终会由显示设备刷新到屏幕。
总结一下
面试前要精心做好准备,简历上写的知识点和原理都需要准备好,项目上多想想难点和亮点,这是面试时能和别人不一样的地方。
还有就是表现出自己的谦虚好学,以及对于未来持续进阶的规划,企业招人更偏爱稳定的人。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
万事开头难,但是程序员这一条路坚持几年后发展空间还是非常大的,一切重在坚持。
为了帮助大家更好更高效的准备面试,特别整理了《前端工程师面试手册》电子稿文件。
前端面试题汇总
JavaScript
性能
linux
前端资料汇总
前端工程师岗位缺口一直很大,符合岗位要求的人越来越少,所以学习前端的小伙伴要注意了,一定要把技能学到扎实,做有含金量的项目,这样在找工作的时候无论遇到什么情况,问题都不会大。















 2272
2272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









