







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
“”"
scaler.inverse_transform(x_std) #使用inverse_transform逆转标准化
“”"
array([[-1. , 2. ],
[-0.5, 6. ],
[ 0. , 10. ],
[ 1. , 18. ]])
“”"
对于StandardScaler和MinMaxScaler来说,空值NaN会被当做是缺失值,
-
在fit的时候忽略
-
在transform的时候保持缺失NaN的状态显示
尽管去量纲化过程不是具体的算法,但在fit接口中,依然只允许导入至少二维数组,一维数组导入会报错。通常来说,我们输入的X会是我们的特征矩阵,现实案例中特征矩阵不太可能是一维所以不会存在这个问题。
StandardScaler 和 MinMaxScaler 如何选择?
看情况
-
大多数机器学习算法中,会选择StandardScaler进行特征缩放,因为MinMaxScaler对异常值非常敏感
-
在PCA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardScaler往往是最好的选择
MinMaxScaler在不涉及距离度量、梯度、协方差计算以及数据需要被压缩到特定区间时使用广泛,比如数字图像处理中量化像素强度时,都会使用MinMaxScaler将数据压缩于[0,1]区间之中。
建议先试试看StandardScaler,效果不好换MinMaxScaler。
除了StandardScaler和MinMaxScaler之外,sklearn中也提供了各种其他缩放处理(中心化只需要一个pandas广播一下减去某个数就好了,因此sklearn不提供任何中心化功能)
-
在希望压缩数据,却不影响数据的稀疏性时(不影响矩阵中取值为0的个数时),我们会使用MaxAbsScaler
-
在异常值多,噪声非常大时,我们可能会选用分位数来无量纲化,此时使用RobustScaler
-
更多详情请参考以下列表:

机器学习和数据挖掘中所使用的数据,永远不可能是完美的。很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的情况。因此,数据预处理中非常重要的一项就是处理缺失值。
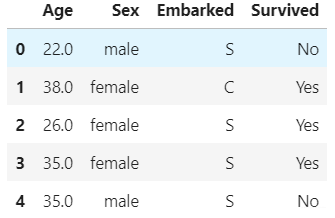
我们采用从泰坦尼克号提取出来的数据,这个数据有三个特征,如下:
-
Age 数值型
-
Sex 字符型
-
Embarked 字符型
import pandas as pd
#index_col=0是因为原数据中第1列本就是索引
data = pd.read_csv(r"…\datasets\Narrativedata.csv",index_col=0)
data.head()
缺失值填补 impute.SimpleImputer
class sklearn.impute.SimpleImputer (
missing_values=nan,
strategy=‘mean’,
fill_value=None,
verbose=0,
copy=True
)
这个类是专门用来填补缺失值的。它包括四个重要参数:
- missing_values
告诉SimpleImputer,数据中的缺失值长什么样,默认空值np.nan
- strategy
我们填补缺失值的策略,默认均值
输入"mean"使用均值填补(仅对数值型特征可用)
输入"median"用中值填补(仅对数值型特征可用)
输入"most_frequent"用众数填补(对数值型和字符型特征都可用)
输入"constant"表示请参考参数"fill_value"中的值(对数值型和字符型特征都可用)
- fill_value
当参数startegy为"constant"的时候可用,可输入字符串或数字表示要填充的值,常用0
- copy
默认为True,将创建特征矩阵的副本,反之则会将缺失值填补到原本的特征矩阵中去
import pandas as pd
#index_col=0是因为原数据中第1列本就是索引
data = pd.read_csv(r"…\datasets\Narrativedata.csv",index_col=0)
data.head()
data.info()
由运行结果可知Age和Embarked有缺失值
“”"
<class ‘pandas.core.frame.DataFrame’>
Int64Index: 891 entries, 0 to 890
Data columns (total 4 columns):
Column Non-Null Count Dtype
0 Age 714 non-null float64
1 Sex 891 non-null object
2 Embarked 889 non-null object
3 Survived 891 non-null object
dtypes: float64(1), object(3)
memory usage: 34.8+ KB
“”"
查看数据
Age = data.loc[:,“Age”].values.reshape(-1,1) #sklearn当中特征矩阵必须是二维
Age[:20]
“”"
array([[22.],
[38.],
[26.],
[35.],
[35.],
[nan],
[54.],
[ 2.],
[27.],
[14.]])
“”"
用各个值填补演示:
#填补年龄, 分别用均值、中位数、0填补
from sklearn.impute import SimpleImputer
imp_mean = SimpleImputer() #实例化,默认均值填补
imp_median = SimpleImputer(strategy=“median”) #用中位数填补
imp_0 = SimpleImputer(strategy=“constant”,fill_value=0) #用0填补
#fit_transform一步完成调取结果
imp_mean = imp_mean.fit_transform(Age) #均值填补
imp_median = imp_median.fit_transform(Age) #中值填补
imp_0 = imp_0.fit_transform(Age) # 使用0填补
imp_mean[:20] # 查看用均值填补后的前20条数据
imp_median[:10] # 查看用中值填补后的前20条数据
imp_0[:10] # 查看用0填补后的前20条数据
在这里我们用中位数填补Age,用众数填补Embarked:
#在这里我们使用中位数填补Age
data.loc[:,“Age”] = imp_median
#data.info()
#使用众数填补Embarked
Embarked = data.loc[:,“Embarked”].values.reshape(-1,1)
imp_mode = SimpleImputer(strategy = “most_frequent”)
data.loc[:,“Embarked”] = imp_mode.fit_transform(Embarked)
data.info() #
由结果可知填补已经完成了
“”"
<class ‘pandas.core.frame.DataFrame’>
Int64Index: 891 entries, 0 to 890
Data columns (total 4 columns):
Column Non-Null Count Dtype
0 Age 891 non-null float64
1 Sex 891 non-null object
2 Embarked 891 non-null object
3 Survived 891 non-null object
dtypes: float64(1), object(3)
memory usage: 34.8+ KB
“”"
data.head(20) #显示填补后的前20条数据
用Pandas和Numpy进行填补其实更加简单
import pandas as pd
data = pd.read_csv(r"…\datasets\Narrativedata.csv",index_col=0)
data.head()
data.loc[:,“Age”] = data.loc[:,“Age”].fillna(data.loc[:,“Age”].median())
#.fillna 在DataFrame里面直接进行填补
data.dropna(axis=0,inplace=True)
#.dropna(axis=0)删除所有有缺失值的行,.dropna(axis=1)删除所有有缺失值的列
#参数inplace,为True表示在原数据集上进行修改,为False表示生成一个复制对象,不修改原数据,默认False
在机器学习中,大多数算法等都只能够处理数值型数据,不能处理文字。在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)
然而在现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的:
-
学历的取值可以是 [“小学”,“初中”,“高中”,“大学”]
-
付费方式可能包含 [“支付宝”,“现金”,“微信”]
-
…
在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,也就是要将文字型数据转换为数值型。
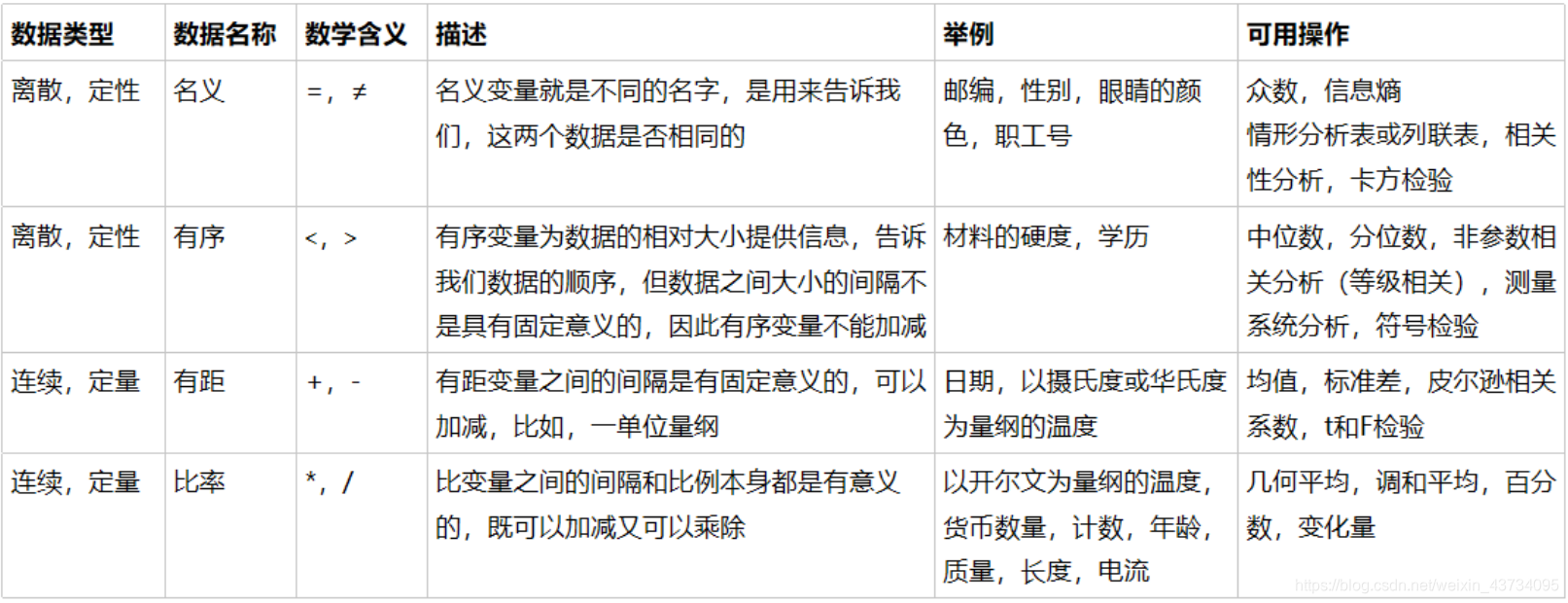
preprocessing.LabelEncoder 标签专用,将分类转换为分类数值
from sklearn.preprocessing import LabelEncoder
y = data.iloc[:,-1] #要输入的是标签,不是特征矩阵,所以允许一维
#进行编码
le = LabelEncoder() #实例化
le = le.fit(y) #导入数据
label = le.transform(y) #transform接口调取结果
#label #查看获取的结果label
#le.classes_ #属性.classes_查看标签中究竟有多少类别
“”"
array([‘No’, ‘Unknown’, ‘Yes’], dtype=object)
“”"
#le.fit_transform(y) #也可以直接fit_transform一步到位,但是不能查看属性classes_
#le.inverse_transform(label) #使用inverse_transform可以逆转
data.iloc[:,-1] = label #让标签等于我们运行出来的结果
#data.head()
以上代码可以用1步完成:
from sklearn.preprocessing import LabelEncoder
data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])
preprocessing.OrdinalEncoder 特征专用,将分类特征转换为分类数值
from sklearn.preprocessing import OrdinalEncoder
data_ = data.copy()
#data_.head()
#接口categories_对应LabelEncoder的接口classes_,一模一样的功能
#OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_
data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])
#data_.head()
preprocessing.OneHotEncoder 独热编码,创建哑变量
我们刚才已经用OrdinalEncoder把分类变量Sex和Embarked都转换成数字对应的类别了。在舱门Embarked这一列中,我们使用 [0,1,2] 代表了三个不同的舱门,然而这种转换是正确的吗?
我们来思考三种不同性质的分类数据:
- 舱门(S,C,Q)
三种取值S,C,Q是相互独立的,彼此之间完全没有联系,表达的是 S≠C≠Q 的概念。这是名义变量
- 学历(小学,初中,高中)
三种取值不是完全独立的,我们可以明显看出,在性质上可以有高中>初中>小学这样的联系,学历有高低,但是学历取值之间却不是可以计算的,我们不能说小学 + 某个取值 = 初中。这是有序变量
- 体重(>45kg,>90kg,>135kg)
各个取值之间有联系,且是可以互相计算的,比如135kg - 45kg = 90kg,分类之间可以通过数学计算互相转换。这是有距变量。
然而在对特征进行编码的时候,这三种分类数据都会被我们转换为 [0,1,2],这三个数字在算法看来,是连续且可以计算的,这三个数字相互不等,有大小,并且有着可以相加相乘的联系。所以算法会把舱门,学历这样的分类特征,都误会成是体重这样的分类特征。我们把分类转换成数字的时候,忽略了数字中自带的数学性质,所以给算法传达了一些不准确的信息,这会影响我们的建模。
OrdinalEncoder可以用来处理有序变量,但对于名义变量,我们只有使用哑变量的方式来处理,才能够尽量向算法传达最准确的信息:

这样的变化,让算法能够彻底领悟,原来三个取值是没有可计算性质的,是“有你就没有我”的不等概念。在我们的数据中,性别和舱门,都是这样的名义变量。因此我们需要使用独热编码,将两个特征都转换为哑变量。
#data.head()
from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:,1:-1]
enc = OneHotEncoder(categories=‘auto’).fit(X)
result = enc.transform(X).toarray()
#result
#依然可以直接一步到位,但为了给大家展示模型属性,所以还是写成了三步
#OneHotEncoder(categories=‘auto’).fit_transform(X).toarray()
#依然可以还原
#pd.DataFrame(enc.inverse_transform(result))
#enc.get_feature_names()
#result
#result.shape
#axis=1,表示跨行进行合并,也就是将量表左右相连,如果是axis=0,就是将量表上下相连
newdata = pd.concat([data,pd.DataFrame(result)],axis=1)
newdata.head()
newdata.drop([“Sex”,“Embarked”],axis=1,inplace=True)
newdata.columns = [“Age”,“Survived”,“Female”,“Male”,“Embarked_C”,“Embarked_Q”,“Embarked_S”]
newdata.head()
总结
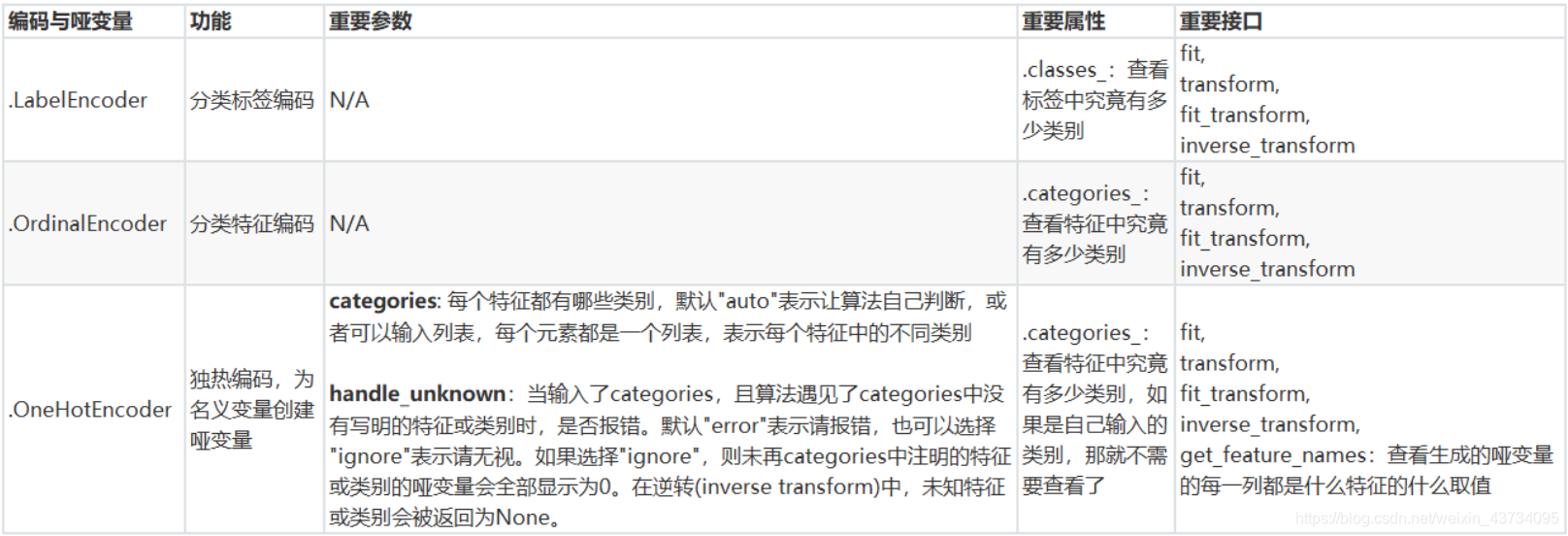
数据类型以及常用的统计量
sklearn.preprocessing.Binarizer 根据阈值将数据二值化
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈值的值映射为0。默认阈值为0时,特征中所有的正值都映射到1。二值化是对文本计数数据的常见操作,分析人员可以决定仅考虑某种现象的存在与否。它还可以用作考虑布尔随机变量的估计器的预处理步骤(例如,使用贝叶斯设置中的伯努利分布建模)。
#将年龄二值化
data_2 = data.copy()
#data_2
from sklearn.preprocessing import Binarizer
X = data_2.iloc[:,0].values.reshape(-1,1) #类为特征专用,所以不能使用一维数组
transformer = Binarizer(threshold=30).fit_transform(X)
#transformer
preprocessing.KBinsDiscretize
这是将连续型变量划分为分类变量的类,能够将连续型变量排序后按顺序分箱后编码。
总共包含三个重要参数:
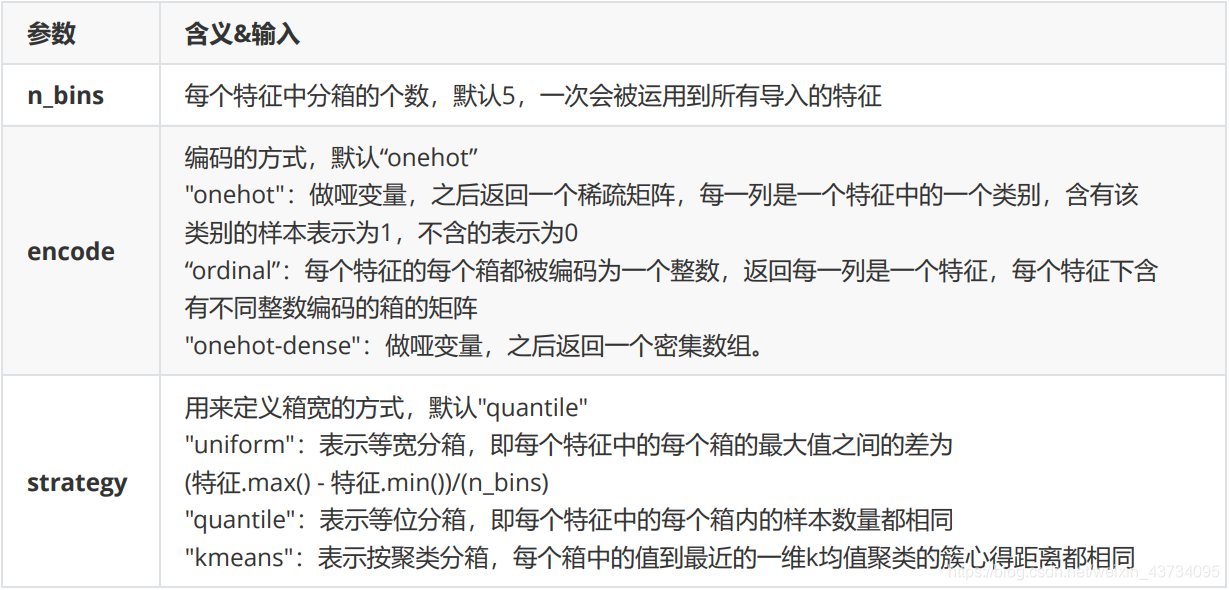
from sklearn.preprocessing import KBinsDiscretizer
X = data.iloc[:,0].values.reshape(-1,1)
est = KBinsDiscretizer(n_bins=3, encode=‘ordinal’, strategy=‘uniform’)
est.fit_transform(X)
#查看转换后分的箱:变成了一列中的三箱
set(est.fit_transform(X).ravel())
est = KBinsDiscretizer(n_bins=3, encode=‘onehot’, strategy=‘uniform’)
#查看转换后分的箱:变成了哑变量
est.fit_transform(X).toarray()
惊喜
最后还准备了一套上面资料对应的面试题(有答案哦)和面试时的高频面试算法题(如果面试准备时间不够,那么集中把这些算法题做完即可,命中率高达85%+)


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Discretizer(n_bins=3, encode=‘ordinal’, strategy=‘uniform’)
est.fit_transform(X)
#查看转换后分的箱:变成了一列中的三箱
set(est.fit_transform(X).ravel())
est = KBinsDiscretizer(n_bins=3, encode=‘onehot’, strategy=‘uniform’)
#查看转换后分的箱:变成了哑变量
est.fit_transform(X).toarray()
惊喜
最后还准备了一套上面资料对应的面试题(有答案哦)和面试时的高频面试算法题(如果面试准备时间不够,那么集中把这些算法题做完即可,命中率高达85%+)
[外链图片转存中…(img-humFY6QH-1713429942009)]
[外链图片转存中…(img-ZgR5k2wy-1713429942009)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-dSAIhUi3-1713429942010)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









