







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
2、传递方式
- 基本数据类型是按值传递
- 引用数据类型是按引用传递
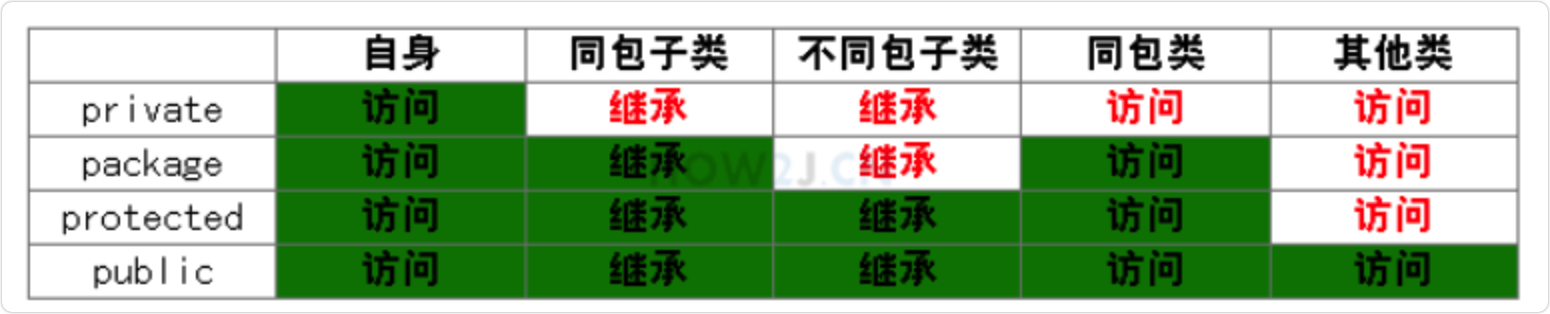
访问修饰符
访问修饰符就是限制变量的访问权限的。
比如你有个“赚钱”的方法,谁都不想给用,那就把方法设成private(私有);
后来你有了老婆孩子,你想让他们也会赚钱,就得设置成default(同一个包);
后来你又有了第二个孩子,但你发现他不会赚钱的方法,为啥呢?因为你被绿了(default不支持不同包的子类);
可为了大局,你还是选择接受这个孩子,悄悄把方法设置成了proteced(保护子类,即使不同包);
后来你老了,明白了开源才是共赢,就设置成了public(公有的);
不知道你听懂了吗,估计看到被那啥了就不想看了吧,没关系,看图(也是绿的)
static关键字
主要意义:
我日常调用方法都是对象.方法,static的主要意义就是可以创建独立于具体对象的域变量或者方法。也就是实现即使没有创建对象,也能使用属性和调用方法!
另一个比较关键的作用就是 用来形成静态代码块以优化程序性能。static块可以置于类中的任何地方,可以有多个。在类初次被加载的时候,会按照static块的顺序来执行每个static块,并且只会执行一次,可以用来优化程序性能
通俗理解:
static是一个可以让你升级的关键字,被static修饰,你就不再是你了。
final关键字
final翻译成中文是“不可更改的,最终的”,顾名思义,他的功能就是不能再修改,不能再继承。我们常见的String类就是被final修饰的。将类、方法、变量声明为final能够提高性能,这样JVM就有机会进行估计,然后优化。
按照Java代码惯例,final变量就是常量,而且通常常量名要大写:
- final关键字可以用于成员变量、本地变量、方法以及类。
- final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误。
- 不能够对final变量再次赋值。
- final方法不能被重写。
- final类不能被继承。
- 接口中声明的所有变量本身是final的。
- final和abstract这两个关键字是反相关的,final类就不可能是abstract的。
面向对象三大特性
封装
1.什么是封装
封装又叫隐藏实现。就是只公开代码单元的对外接口,而隐藏其具体实现。
其实生活中处处都是封装,手机,电脑,电视这些都是封装。你只需要知道如何去操作他们,并不需要知道他们里面是怎么构造的,怎么实现这个功能的。
2.如何实现封装
在程序设计里,封装往往是通过访问控制实现的。也就是刚才提到的访问修饰符。
3.封装的意义
封装提高了代码的安全性,使代码的修改变的更加容易,代码以一个个独立的单元存在,高内聚,低耦合。
好比只要你手机的充电接口不变,无论以后手机怎么更新,你依然可以用同样的数据线充电或者与其他设备连接。
封装的设计使使整个软件开发复杂度大大降低。我只需要使用别人的类,而不必关心其内部逻辑是如何实现的。我能很容易学会使用别人写好的代码,这就让软件协同开发的难度大大降低。
封装还避免了命名冲突的问题。
好比你家里有各种各样的遥控器,但比还是直到哪个是电视的,哪个是空调的。因为一个属于电视类一个属于空调类。不同的类中可以有相同名称的方法和属性,但不会混淆。
继承
继承的主要思想就是将子类的对象作为父类的对象来使用。比如王者荣耀的英雄作为父类,后裔作为子类。后裔有所有英雄共有的属性,同时也有自己独特的技能。
多态
多态的定义:
指允许不同类的对象对同一消息做出响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式。(发送消息就是函数调用)
简单来说,同样调用攻击这个方法,后裔的普攻和亚瑟的普攻是不一样的。
多态的条件:
- 要有继承
- 要有重写
- 父类引用指向子类对象
多态的好处:
多态对已存在代码具有可替换性。
多态对代码具有可扩充性。
它在应用中体现了灵活多样的操作,提高了使用效率。
多态简化对应用软件的代码编写和修改过程,尤其在处理大量对象的运算和操作时,这个特点尤为突出和重要。
Java中多态的实现方式:
- 接口实现
- 继承父类进行方法重写
- 同一个类中进行方法重载
完整讲解
入门练习案例
JavaWeb
JavaWeb是用Java技术来解决相关web互联网领域的技术栈。Web就是网页,分为静态和动态。涉及 的知识点主要包括jsp,servlet,tomcat,http,MVC等知识。
本章难度不高,但也不可忽视。其中前端基础不需花过多时间,重点放在Tomcat上,会陪伴你整个Java生涯。
HTTP网络请求方式
GET:最常用的方式,用来向服务器请求数据,没有请求体,请求参数放在URL后面。POST:用于向表单提交数据,传送的数据放在请求体中。PUT:用来向服务器上传文件,一般对应修改操作,POST用于向服务器发送数据,PUT用于向服务器储存数据。没有验证机制,任何人都可以操作,存在安全问题。具有幂等性。DELETE:用于删除服务器上的文件,具有幂等性。同样存在安全问题。HEAD:用HEAD进行请求服务器时,服务器只返回响应头,不返回响应体。与GET一样没有请求体,常用于检查请求的URL是否有效。PATCH:对资源进行部分修改。与PUT区别在于,PUT是修改所有资源,替代它,而PATCH只是修改部分资源。TRACE:用来查看一个请求,经过网关,代理到达服务器,最后请求的变换。因安全问题被禁用。OPTIONS:当客户端不清楚对资源操作的方法,可以使用这个,具有幂等性。
GET和POST
- 作用不同:GET 用于获取资源,而 POST 用于传输实体主体。
- 参数位置不一样: GET 的参数是以查询字符串出现在 URL 中,而 POST 的参数存储在实体主体中。虽然GET的参数暴露在外面,但可以通过加密的方式处理,而 POST 参数即使存储在实体主体中,我们也可以通过一些抓包工具如(Fiddler)查看。
- 幂等性:GET是幂等性,而POST不是幂等性。(面试官紧接着可能就会问你什么是幂等性?如何保证幂等性?)
- 安全性:安全的 HTTP 方法不会改变服务器状态,也就是说它只是可读的。 GET 方法是安全的,而 POST 却不是,因为 POST 的目的是传送实体主体内容,这个内容可能是用户上传的表单数据,上传成功之后,服务器可能把这个数据存储到数据库中,因此状态也就发生了改变。
幂等性
是否具有幂等性也是一个http请求的重要关注点。
幂等性:指的是同样的请求不管执行多少次,效果都是一样,服务器状态也是一样的。具有幂等性的请求方法没有副作用。(统计用途除外)
如何保证幂等性
假设这样一个场景:有时我们在填写某些
form表单时,保存按钮不小心快速点了两次,表中竟然产生了两条重复的数据,只是id不一样。这是一个比较常见的幂等性问题,在高并发场景下会变得更加复杂,那怎么保证接口的幂等性呢?
1.insert前select
插入数据前先根据某一字段查询一下数据库,如果已经存在就修改,不存在再插入。
2.加锁
加锁可解决一切问题,但也要考虑并发性。
主要包括悲观锁,乐观锁,分布式锁。
悲观锁的并发性较低,更适合使用在防止数据重复的场景,注意幂等性不光是防止重复还需要结果相同。
乐观锁可以很高的提升性能,也就是常说的版本号。
分布式锁应用在高并发场景,主要用redis来实现。
3.唯一索引
通过数据库的唯一索引来保证结果的一致性和数据的不重复。
4.Token
两次请求,第一请求拿到token,第二次带着token去完成业务请求。
常见的网络状态码
网络状态码共三位数字组成,根据第一个数字可分为以下几个系列:
1xx(信息性状态码)
代表请求已被接受,需要继续处理。
包括:100、101、102
这一系列的在实际开发中基本不会遇到,可以略过。
2xx(成功状态码)
表示成功处理了请求的状态代码。
200:请求成功,表明服务器成功了处理请求。
202:服务器已接受请求,但尚未处理。
204:服务器成功处理了请求,但没有返回任何内容。
206:服务器成功处理了部分 GET 请求。
3xx(重定向状态码)
300:针对请求,服务器可执行多种操作。
301:永久重定向
302:临时性重定向
303:303与302状态码有着相同的功能,但303状态码明确表示客户端应当采用GET方法获取资源。
301和302的区别?
301比较常用的场景是使用域名跳转。比如,我们访问 http://www.baidu.com 会跳转到https://www.baidu.com,发送请求之后,就会返回301状态码,然后返回一个location,提示新的地址,浏览器就会拿着这个新的地址去访问。
302用来做临时跳转比如未登陆的用户访问用户中心重定向到登录页面。
4xx(客户端错误状态码)
400:该状态码表示请求报文中存在语法错误。但浏览器会像200 OK一样对待该状态码。
401:表示发送的请求需要有通过HTTP认证的认证信息。比如token失效就会出现这个问题。
403:被拒绝,表明对请求资源的访问被服务器拒绝了。
404:找不到,表明服务器上无法找到请求的资源,也可能是拒绝请求但不想说明理由。
5xx(服务器错误状态码)
500:服务器本身发生错误,可能是Web应用存在的bug或某些临时的故障。
502:该状态码表明服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
⚠️有时候返回的状态码响应是错误的,比如Web应用程序内部发生错误,状态码依然返回200
转发和重定向
上面提到了重定向,那你知道什么是转发吗?
1.转发
A找B借钱,B没有钱,B去问C,C有钱,C把钱借给A的过程。
客户浏览器发送http请求,web服务器接受此请求,调用内部的一个方法在容器内部完成请求处理和转发动作,将目标资源发送给客户。
整个转发一个请求,一个响应,地址栏不会发生变化,不能跨域访问。
2.重定向
A找B借钱,B没有钱,B让A去找C,A又和C借钱,C有钱,C把钱借给A的过程。
客户浏览器发送http请求,web服务器接受后发送302状态码响应及对应新的location给客户浏览器,客户浏览器发现是302响应,则自动再发送一个新的http请求,请求url是新的location地址,服务器根据此请求寻找资源并发送给客户。
两个请求,两个响应,可以跨域。
Servlet
servlet是一个比较抽奖的概念,也是web部分的核心组件,大家回答这个问题一定要加入自己的理解,不要背定义。
servlet其实就是一个java程序,他主要是用来解决动态页面的问题。
之前都是浏览器像服务器请求资源,服务器(tomcat)返回页面,但用户多了之后,每个用户希望带到不用的资源。这时就该servlet上场表演了。
servlet存在于tomcat之中,用来网络请求与响应,但他的重心更在于业务处理,我们访问京东和淘宝的返回的商品是不一样的,就需要程序员去编写,目前MVC三层架构,我们都是在service层处理业务,但这其实是从servlet中抽取出来的。
看一下servlet处理请求的过程:
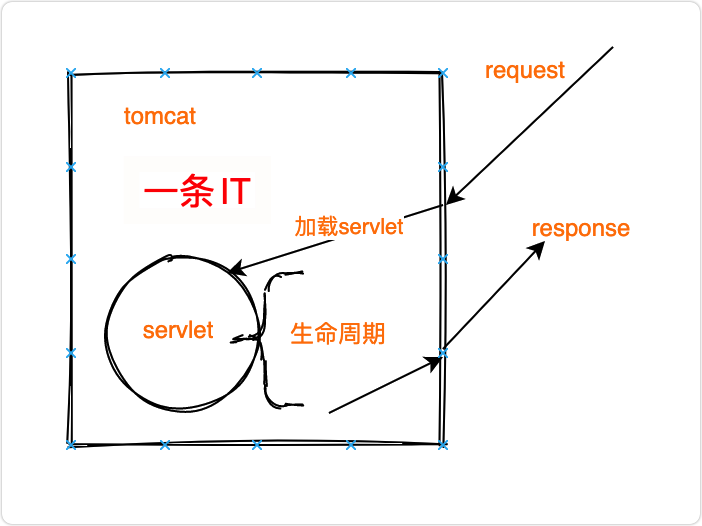
Servlet的生命周期
Servlet生命周期分为三个阶段:
- 初始化阶段 调用init()方法
- 响应客户请求阶段 调用service()方法-àdoGet/doPost()
- 终止阶段 调用destroy()方法
session、cookie、token
首先我们要明白HTTP是一种无状态协议,怎么理解呢?很简单
夏洛:大爷,楼上322住的是马冬梅家吧?
大爷:马冬什么?
夏洛:马冬梅。
大爷:什么冬梅啊?
夏洛:马冬梅啊。
大爷:马什么梅?
夏洛:行,大爷你先凉快着吧。
这段对话都熟悉吧,HTTP就是那个大爷,那如果我们就直接把“大爷”放给用户,用户不用干别的了,就不停的登录就行了。
既然“大爷不靠谱”,我们找“大娘”去吧。
哈哈哈,开个玩笑,言归正传。
为了解决用户频繁登录的问题,在服务端和客户端共同维护一个状态——会话,就是所谓session,我们根据会话id判断是否是同一用户,这样用户就开心了。
但是服务器可不开心了,因为用户越来越多,都要把session存在服务器,这对服务器来说是一个巨大的开销,这是服务器就找来了自己的兄弟帮他分担(集群部署,负载均衡)。
但是问题依然存在,如果兄弟挂了怎么办,兄弟们之间的数据怎么同步,用户1把session存放在机器A上,下次访问时负载均衡到了机器B,完了,找不到,用户又要骂娘。
这时有人思考,为什么一定要服务端保存呢,让客户端自己保存不就好了,所以就诞生了cookie,下一次请求时客户段把cookie发送给服务器,说我已经登录了。
但是空口无凭,服务器怎么知道哪个cookie是我发过去的呢?如何验证成了新的问题。
有人想到了一个办法,用加密令牌,也就是token,服务器发给客户端一个令牌,令牌保存加密后id和密钥,下一次请求时通过headers传给服务端,由于密钥别人不知道,只有服务端知道,就实现了验证,且别人无法伪造。
MVC与三层架构
三层架构与MVC的目标一致:都是为了解耦和、提高代码复用。MVC是一种设计模式,而三层架构是一种软件架构。
MVC
Model 模型
模型负责各个功能的实现(如登录、增加、删除功能),用JavaBean实现。
View 视图
用户看到的页面和与用户的交互。包含各种表单。 实现视图用到的技术有html/css/jsp/js等前端技术。
常用的web 容器和开发工具
Controller 控制器
控制器负责将视图与模型一一对应起来。相当于一个模型分发器。接收请求,并将该请求跳转(转发,重定向)到模型进行处理。模型处理完毕后,再通过控制器,返回给视图中的请求处。
三层架构
表现层(UI)(web层)、业务逻辑层(BLL)(service层)、数据访问层(DAL)(dao层) ,再加上实体类库(Model)
- 实体类库(Model),在Java中,往往将其称为Entity实体类。数据库中用于存放数据,而我们通常选择会用一个专门的类来抽象出数据表的结构,类的属性就一对一的对应这表的属性。一般来说,Model实体类库层需要被DAL层,BIL层和UI层引用。
- 数据访问层(DAL),主要是存放对数据类的访问,即对数据库的添加、删除、修改、更新等基本操作,DAL就是根据业务需求,构造SQL语句,构造参数,调用帮助类,获取结果,DAL层被BIL层调用
- 业务逻辑层(BLL),BLL层好比是桥梁,将UI表示层与DAL数据访问层之间联系起来。所要负责的,就是处理涉及业务逻辑相关的问题,比如在调用访问数据库之前,先处理数据、判断数据。
完整讲解
集合
工欲善其事必先利其器,集合就是我们的器。
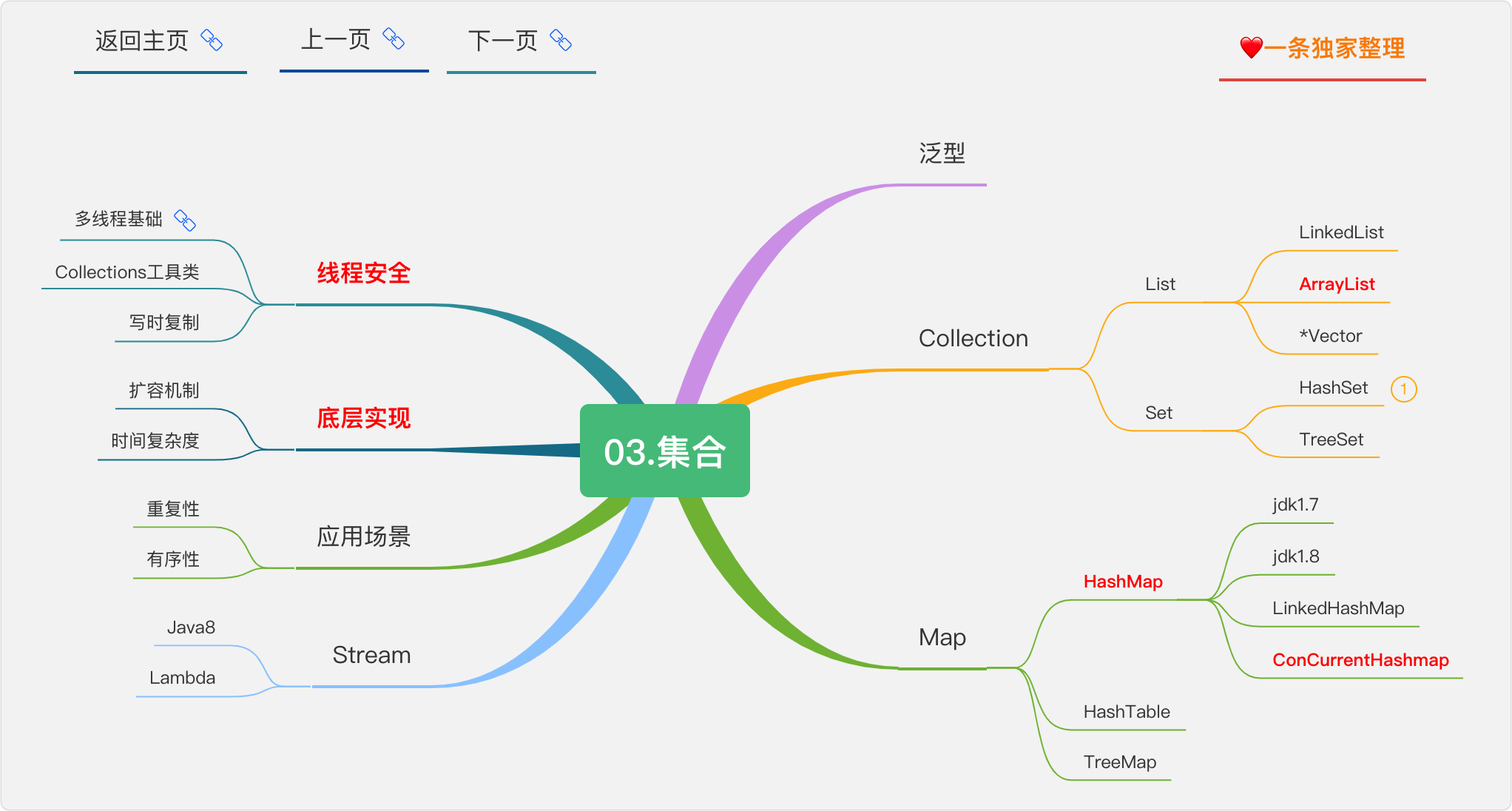
ArrayList
底层实现
由什么组成,我说了不算,看源码。怎么看呢?
List list = new ArrayList<>();
新建一个
ArrayList,按住ctrl或command用鼠标点击。
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
* 翻译
* 数组缓冲区,ArrayList的元素被存储在其中。ArrayList的容量是这个数组缓冲区的长度。
* 任何空的ArrayList,如果elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA,
* 当第一个元素被添加时,将被扩展到DEFAULT_CAPACITY。
*/
transient Object[] elementData;
毋庸置疑,底层由数组组成,那数组的特点就是ArrayList的特点。
- 由于数组以一块连续的内存空间,每一个元素都有对应的下标,查询时间复杂度为
O(1)。好比你去住酒店,每个房间都挨着,房门都写着房间号。你想找哪一间房是不是很容易。 - 相对的,一块连续的内存空间你想打破他就没那么容易,牵一发而动全身,所以新增和删除的时间复杂度为
O(n),想像你在做excel表格的时候,想增加一列,后面的列是不是都要跟着移动。 - 元素有序,可重复。可用在大多数的场景,这个就不需要过多解释了。
扩容
我们知道数组是容量不可变的数据结构,随着元素不断增加,必然要扩容。
所以扩容机制也是集合中非常容易爱问的问题,在源码中都可以一探究竟。
1.初始化容量为10,也可以指定容量创建。
/**
* Default initial capacity.
* 定义初始化容量
*/
private static final int DEFAULT_CAPACITY = 10;
2.数组进行扩容时,是将旧数据拷贝到新的数组中,新数组容量是原容量的1.5倍。(这里用位运算是为了提高运算速度)
private void grow(int minCapacity) {
int newCapacity = oldCapacity + (oldCapacity >> 1);
}
3.扩容代价是很高得,因此再实际使用时,我们因该避免数组容量得扩张。尽可能避免数据容量得扩张。尽可能,就至指定容量,避免数组扩容的发生。
为什么扩容是1.5倍?
- 如果大于1.5,也就是每次扩容很多倍,但其实我就差一个元素的空间,造成了空间浪费。
- 如果小于1.5,扩容的意义就不大了,就会带来频繁扩容的问题。
所以,1.5是均衡了空间占用和扩容次数考虑的。
线程安全问题
怎么看线程安全?说实话我以前都不知道,看网上说安全就安全,说不安全就不安全。
其实都在源码里。找到增加元素的方法,看看有没有加锁就知道了。
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
没有加锁,所以线程不安全
在多线程的情况下,插入数据的时可能会造成数据丢失,一个线程在遍历,另一个线程修改,会报ConcurrentModificationException(并发修改异常)错误.
多线程下使用怎么保证线程安全?
保证线程安全的思路很简单就是加锁,但是你可没办法修改源码去加个锁,但是你想想编写
java的大佬会想不到线程安全问题?早就给你准备了线程安全的类。
1.Vector
Vector是一个线程安全的List类,通过对所有操作都加上synchronized关键字实现。
找到add方法,可以看到被synchronized关键字修饰,也就是加锁,但synchronized是重度锁,并发性太低,所以实际一般不使用,随着java版本的更新,慢慢废弃。
public void add(E e) {
int i = cursor;
synchronized (Vector.this) {
checkForComodification();
Vector.this.add(i, e);
expectedModCount = modCount;
}
cursor = i + 1;
lastRet = -1;
}
2.Collections
注意是Collections而不是Collection。
Collections位于java.util包下,是集合类的工具类,提供了很多操作集合类的方法。其中Collections.synchronizedList(list)可以提供一个线程安全的List。
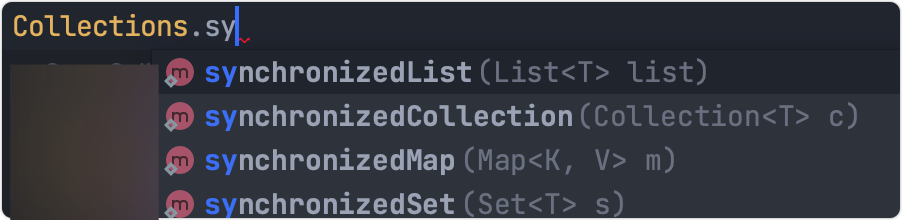
对于Map、Set也有对应的方法
3.CopyOnWrite(写时复制)
写时复制,简称COW,是计算机程序设计领域中的一种通用优化策略。
当有多人同时访问同一资源时,他们会共同获取指向相同的资源的指针,供访问者进行读操作。
当某个调用者修改资源内容时,系统会真正复制一份副本给该调用者,而其他调用者所见到的最初的资源仍然保持不变。修改完成后,再把新的数据写回去。
通俗易懂的讲,假设现在有一份班级名单,但有几个同学还没有填好,这时老师把文件通过微信发送过去让同学们填写(复制一份),但不需要修改的同学此时查看的还是旧的名单,直到有同学修改好发给老师,老师用新的名单替换旧的名单,全班同学才能查看新的名单。
共享读,分开写。读写分离,写时复制。
在java中,通过CopyOnWriteArrayList、CopyOnWriteArraySet容器实现了 COW 思想。
平时查询的时候,都不需要加锁,随便访问,只有在更新的时候,才会从原来的数据复制一个副本出来,然后修改这个副本,最后把原数据替换成当前的副本。修改操作的同时,读操作不会被阻塞,而是继续读取旧的数据。
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
源码里用到了ReentrantLock锁和volatile关键字,会在《资深程序员修炼》专栏中做全面深度讲解。
LinkedList
LinkedList和ArrayList同属于List集合。其共同特点可归纳为:存储单列数据的集合,存储的数据是有序并且是可以重复的。
但两者也有不同,往下看吧
底层实现
LinkedList类的底层实现的数据结构是一个双向链表。同时还实现了Deque接口,所以会有些队列的特性,会在下面讲。
class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable
先简单说一下链表这种数据结构,与数组相反,链表是一种物理存储单元上非连续、非顺序的存储结构,一个最简单的链表(单链表)有节点Node和数值value组成。通俗的讲,就像串在一起的小鱼干,中间用线连着。
transient Node first;
transient Node last;
链表中保存着对最后一个节点的引用,这就是双端链表
在单链表的结点中增加一个指向其前驱的pre指针就是双向链表,一种牺牲空间换时间的做法。
双端链表不同于双向链表,切记!
关于链表更详细代码级讲解会放《糊涂算法》专栏更新。敬请期待!
简单了解过后分析一下链表的特点:
- 查询速度慢,因为是非连续空间,没有下标。想像你需要在一份名单上找到你的名字,没有序号,你只能从头开始一个一个的看。
- 删改速度快,因为非连续,也就没有那么多约束。想像从一根项链上扣下来一块,只需要改变引用就可以了,不会牵一发而动全身。
- 元素有序,可重复。
如何解决查询慢的问题?
如果我查找的元素在尾部,则需要遍历整个链表,所以有了双端链表。
即使不在尾部,我如果只能一个方向遍历,也很麻烦,所以有了双向队列,牺牲空间换时间。
那么空间可不可以再牺牲一点?
可以,就是跳跃链表,简称「跳表」。
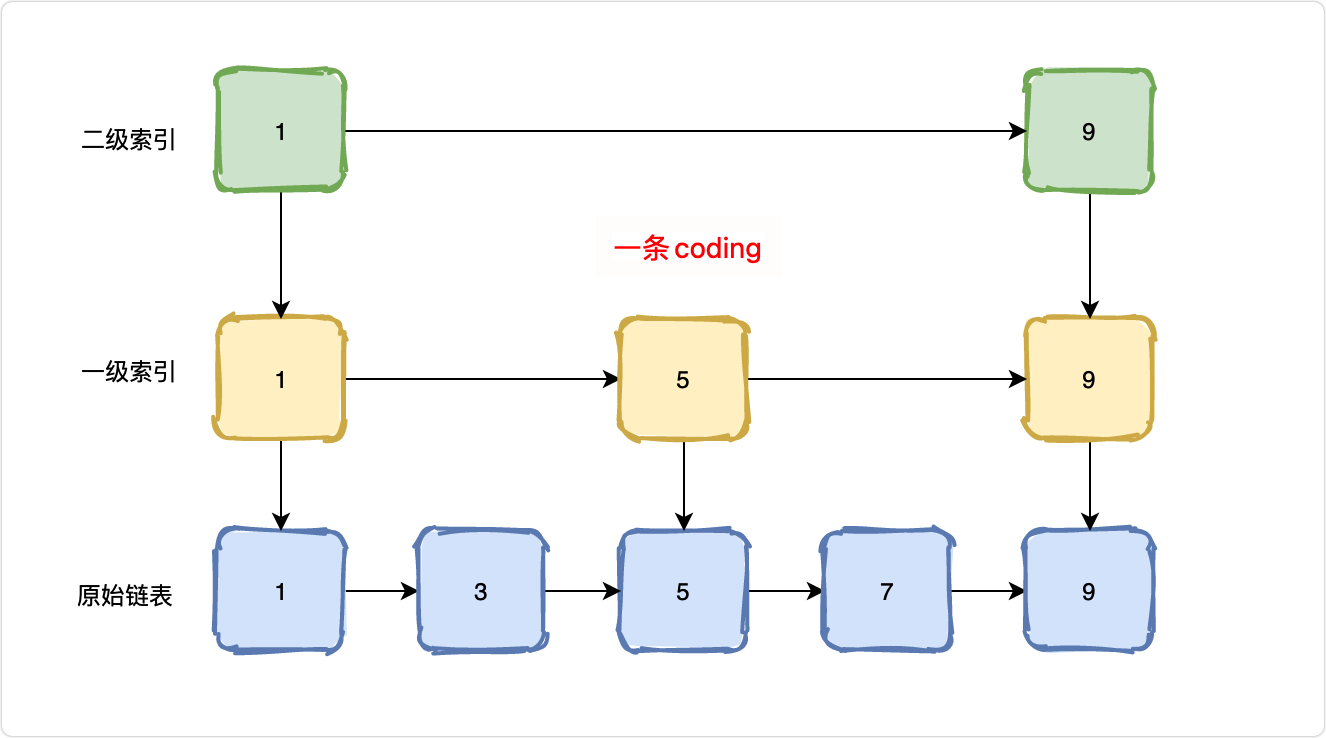
通过建立多级索引来加快查询速度。
线程安全问题
老办法,看看
add()方法。分为「头插法」和「尾插法」。
/**
* Inserts the specified element at the beginning of this list.
*
* @param e the element to add
*/
public void addFirst(E e) {
linkFirst(e);
}
/**
* Appends the specified element to the end of this list.
*
*
This method is equivalent to {@link #add}.
*
* @param e the element to add
*/
public void addLast(E e) {
linkLast(e);
}
都没加锁,百分之一百的不安全。
如何解决线程不安全问题
1.ConcurrentLinkedQueue
一个新的类,位于java.util.concurrent(juc)包下。实现了Queue接口。
class ConcurrentLinkedQueue extends AbstractQueue
implements Queue, java.io.Serializable{}
使用violate关键字实现加锁。
private transient volatile Node head;
private transient volatile Node tail;
1.Collections
和ArrayList一样,使用Collections.synchronizedList()。
Map:存储双列数据的集合,通过键值对存储数据,存储 的数据是无序的,Key值不能重复,value值可以重复
和ArrayList对比一下
共同点:有序,可重复。线程不安全。
不同点:底层架构,查询和删改的速度
完整讲解
JVM
重点来了,Java程序员一定要深入研究的内容
技术学习总结
学习技术一定要制定一个明确的学习路线,这样才能高效的学习,不必要做无效功,既浪费时间又得不到什么效率,大家不妨按照我这份路线来学习。



最后面试分享
大家不妨直接在牛客和力扣上多刷题,同时,我也拿了一些面试题跟大家分享,也是从一些大佬那里获得的,大家不妨多刷刷题,为金九银十冲一波!


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
ile Node head;
private transient volatile Node tail;
1.Collections
和ArrayList一样,使用Collections.synchronizedList()。
Map:存储双列数据的集合,通过键值对存储数据,存储 的数据是无序的,Key值不能重复,value值可以重复
和ArrayList对比一下
共同点:有序,可重复。线程不安全。
不同点:底层架构,查询和删改的速度
完整讲解
JVM
重点来了,Java程序员一定要深入研究的内容
技术学习总结
学习技术一定要制定一个明确的学习路线,这样才能高效的学习,不必要做无效功,既浪费时间又得不到什么效率,大家不妨按照我这份路线来学习。
[外链图片转存中…(img-J6W6wlgP-1713621521671)]
[外链图片转存中…(img-Wi3HTo6E-1713621521671)]
[外链图片转存中…(img-yj6sc2Yx-1713621521672)]
最后面试分享
大家不妨直接在牛客和力扣上多刷题,同时,我也拿了一些面试题跟大家分享,也是从一些大佬那里获得的,大家不妨多刷刷题,为金九银十冲一波!
[外链图片转存中…(img-ku7gnCSb-1713621521672)]
[外链图片转存中…(img-LDuosSwx-1713621521672)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-ZLdG80zi-1713621521673)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 6405
6405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









