







前端框架
前端框架太多了,真的学不动了,别慌,其实对于前端的三大马车,Angular、React、Vue 只要把其中一种框架学明白,底层原理实现,其他两个学起来不会很吃力,这也取决于你以后就职的公司要求你会哪一个框架了,当然,会的越多越好,但是往往每个人的时间是有限的,对于自学的学生,或者即将面试找工作的人,当然要选择一门框架深挖原理。
以 Vue 为例,我整理了如下的面试题。

如果你觉得对你有帮助,可以戳这里获取:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
2.使用神经网络做多项式回归
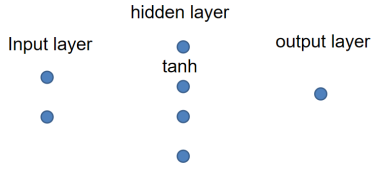
思路:中间隐藏节点变多(最主要的是激活函数)

添加一个隐藏层


化简和合并同类项后其实还是线性的模型,没有实际意义,因此需要激活函数。

调节参数观察变化:
-
调整activator激活函数sigmoid,relu,tanh
-
改变learning rate学习率0.2,0.1,0.01
-
调整optimizer:sgd,adam
-
增加网络层数
(Relu 不够平滑;添加很多层之后,使用relu折线变多,使用Sigmoid可能会出现梯度消失;也并不是越复杂的网络就越好)
效果展示:
1. 使用relu,adam,learning rate=0.01
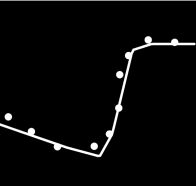
2. 使用relu,adam,learning rate=0.1

3. 使用tanh,adam,learning rate=0.01
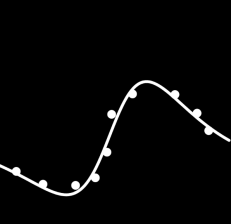
4. 使用sigmoid,adam,learning rate=0.01
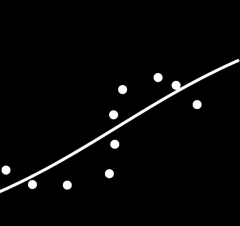
5. tanh,sgd,learning rate=0.01
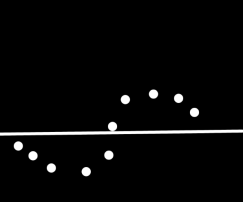
xs = [];
ys = [];
// 1. 搭建神经网络结构
const model = tf.sequential();
model.add(tf.layers.dense({
units: 10,
inputShape: [2],
activation: ‘sigmoid’ // 激活函数可以选择sigmoid,relu,tanh
}));
model.add(tf.layers.dense({
units: 10,
activation: ‘sigmoid’
}));
model.add(tf.layers.dense({
units: 1, // 输出为一维
}));
// 2.训练准备工作:声明optimizer和loss
const Optimizer = tf.train.sgd(0.01) // learning rating=0.2
/* 注意:
sgd一般没有adam好
-
sgd收敛慢 抖动较大 但是比较通用
-
adam对于训练数据的拟合能力比较强 */
const config = {
optimizer: Optimizer,
loss: tf.losses.meanSquaredError, // 自带的loss函数
}
model.compile(config);
// 3. 输入点
function mousePressed() {
let x = map(mouseX, 0, width, 0, 1); // format
let y = map(mouseY, 0, height, 0, 1);
xs.push([x, 1]); // 鼠标点击值x1,以及一个不变量1
ys.push(y);
console.log(xs);
}
function setup() {
createCanvas(400, 400); // 创建画布
background(0); // 设置背景颜色
}
function draw() {
background(0, 0, 0);
stroke(255, 255, 255);
strokeWeight(15);
// 4. 在画布上画点
for (let i = 0; i < xs.length; i++) {
let x = map(xs[i][0], 0, 1, 0, width);
let y = map(ys[i], 0, 1, 0, height);
point(x, y);
}
if (xs.length >= 10) { // 输入数据大于5才进行操作
// 把xs,ys转化为tensor类型
const inputs = tf.tensor2d(xs);
outputs = tf.tensor1d(ys);
// 5. 使用fit训练模型
async function train() {
for (let i = 1; i < 500; i++) {
const h = await model.fit(inputs, outputs,{
// await:下一个的结果是在上一个结果的基础上进行优化
// (如果没有await就会有多个fit线程)
batchSize: 2, // 一次训练的数目
epochs: 1 // 所有数据训练一遍
});
console.log("Loss after Epoch " + i + " : " + h.history.loss[0]);
}
}
// 6. 画线
train().then(() => {
let linex = [];
for (let x = 0; x < 1; x += 0.01) {
linex.push([x, 1]);
}
tflinex = tf.tensor2d(linex);
output_tem = model.predict(tflinex);
output_tem = output_tem.dataSync(); // 类型转换
beginShape();
noFill();
stroke(255);
strokeWeight(5);
for (let i = 0; i < linex.length; i++) {
let x = map(linex[i][0], 0, 1, 0, width);
let y = map(output_tem[i], 0, 1, 0, height);
vertex(x, y);
}
endShape();
})
noLoop()
}
}
3. 使用神经网络做分类

对于圆形尽量拟合输出为1,三角形的输出为0
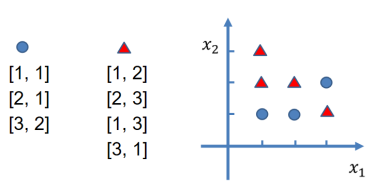
目标:前三个拟合效果接近于1,后四个拟合效果接近于0

结果展示:
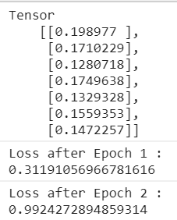

xs = [];
ys = [];
const model = tf.sequential();
model.add(tf.layers.dense({
units: 10,
inputShape: [2],
activation: ‘sigmoid’
}));
model.add(tf.layers.dense({
units: 10,
activation: ‘sigmoid’
}));
model.add(tf.layers.dense({
units: 1,
}));
const Optimizer = tf.train.adam(0.1)
const config = {
optimizer: Optimizer,
loss: tf.losses.meanSquaredError,
}
model.compile(config);
const inputs = tf.tensor2d([[1, 1], [2, 1], [3, 2], [1, 2],[2, 3], [1, 3], [3, 1]]);
const outputs = tf.tensor2d([[1], [1], [1], [0], [0], [0], [0]]); // 标签
最后
面试题千万不要死记,一定要自己理解,用自己的方式表达出来,在这里预祝各位成功拿下自己心仪的offer。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】




;
const outputs = tf.tensor2d([[1], [1], [1], [0], [0], [0], [0]]); // 标签
最后
面试题千万不要死记,一定要自己理解,用自己的方式表达出来,在这里预祝各位成功拿下自己心仪的offer。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
[外链图片转存中…(img-lkCxtUG6-1715681443940)]
[外链图片转存中…(img-JgPHVr4H-1715681443941)]
[外链图片转存中…(img-hjU8GgJ6-1715681443941)]
[外链图片转存中…(img-elostVUj-1715681443942)]















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









