







- Out-place: 占用额外内存
十大经典排序算法的总结:

算法分类图:
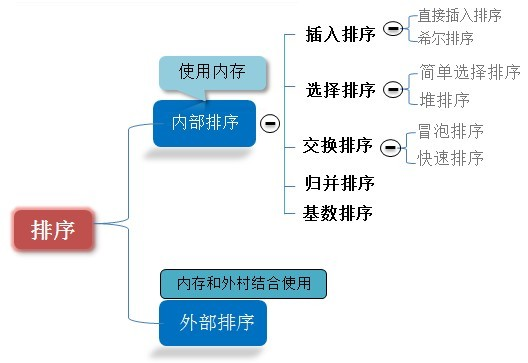
经过思考,我发现了算法的具体实现也是分两类的
分别是:
- 比较排序
例如冒泡排序就是比较排序 他依赖于两个元素的比较
每个数都必须和其他数组比较,比较排序适用于各种规模的数据
- 非比较排序
又例如计数排序就术语非比较排序 他是通过确定每个元素之前有多少个元素来排序
非比较排序时间复杂度低,为:O(n),但由于非比较排序需要占用空间来确定唯一位置,对数据规模和数据分布有一定的要求
===================================================================
实现步骤:
-
1: 比较相邻的元素,较大数字交换之较小数字之后
-
2: 对每一对相邻元素作同样的工作,到最后应该为最大元素
-
3: 针对所有的元素重复以上的步骤,除了最后一个
-
4: 重复步骤 1~3,直到排序完成
动图:

代码:
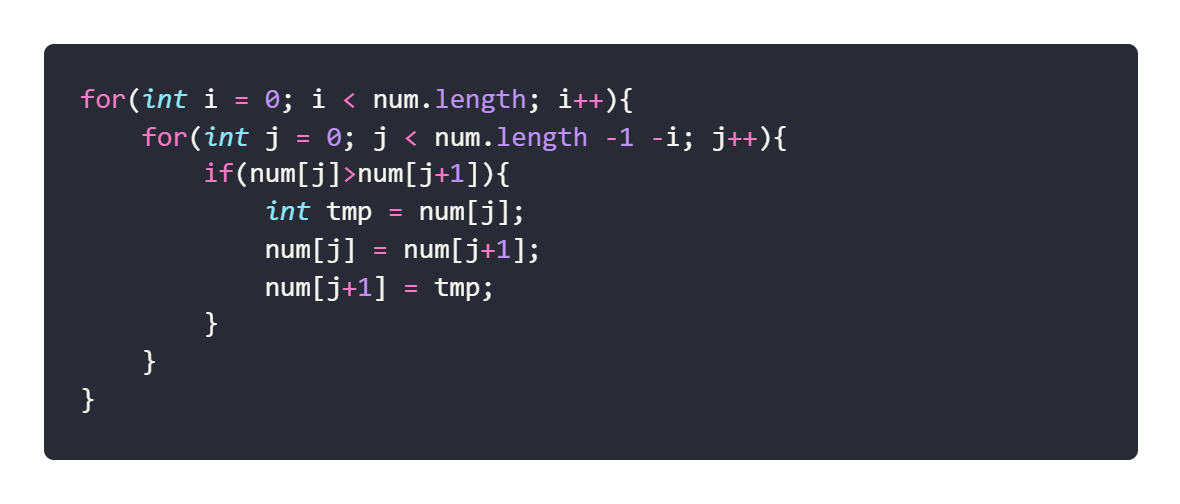
算法分析
-
最佳情况:T(n) = O(n^2)
-
最差情况:T(n) = O(n^2)
-
平均情况:T(n) = O(n^2)
但是不应该呀,冒泡排序的最佳情况是可以做到 O(n) 的
优化:
1.优化外层循环
若在某一趟排序中未发现气泡位置的交换,则说明待排序的无序区中所有气泡均满足排序结果,因此,冒泡排序过程可在此趟排序后终止
> 2.优化内层循环
在每趟扫描中,记住最后一次交换发生的位置。下一趟排序开始时,R[位置-1]是无序区,R[位置~n]是有序区,从而减少排序的趟数。
> 算法分析
最佳情况:T(n) = O(n)
最差情况:T(n) = O(n^2)
平均情况:T(n) = O(n^2)
===================================================================
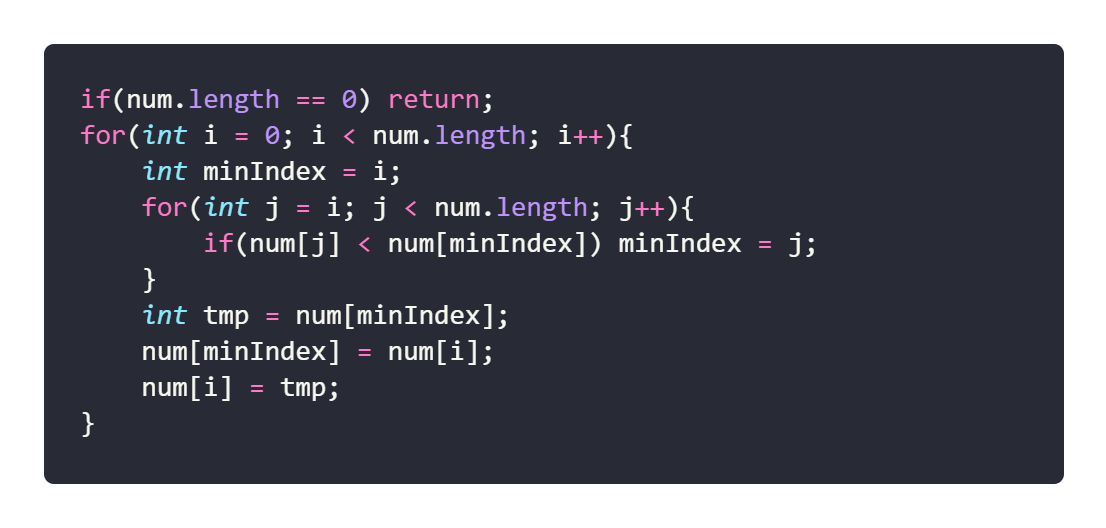
实现步骤:
-
1: 初始状态:无序区为[1…n],有序区为空
-
2: 第 i 趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为[1…i-1]和(i…n)。该趟排序从当前无序区中-选出关键字最小的记录 [k],将它与无序区的第 1 个记录 R 交换,使[1…i]和[i+1…n)分别变为记录个数增加 1 个的新有序区和记录个数减少 1 个的新无序区
-
3: n-1 趟结束,数组有序化了
动图:
代码:
算法分析
-
最佳情况:T(n) = O(n^2)
-
最差情况:T(n) = O(n^2)
-
平均情况:T(n) = O(n^2)
===================================================================
实现步骤:
-
1: 从第一个元素开始,该元素可以认为已经被排序
-
2: 取出下一个元素,在已经排序的元素序列中从后向前扫描
-
3: 如果该元素(已排序)大于新元素,将该元素移到下一位置
-
4: 重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置
-
5: 将新元素插入到该位置后
-
6: 重复步骤 2~5。
动图:
代码:
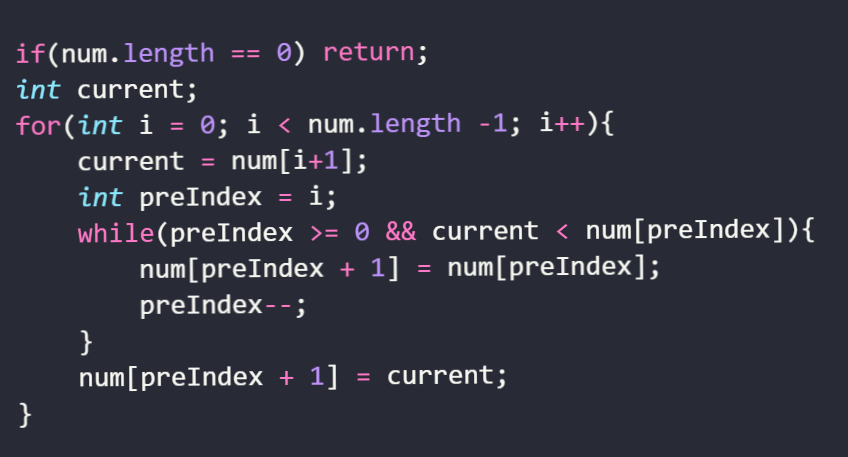
算法分析
-
最佳情况:T(n) = O(n)
-
最差情况:T(n) = O(n^2)
-
平均情况:T(n) = O(n^2)
===================================================================
实现步骤:
-
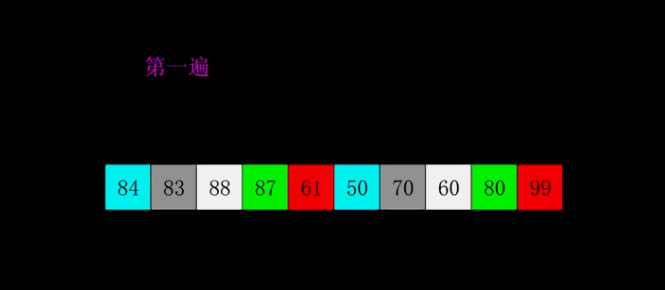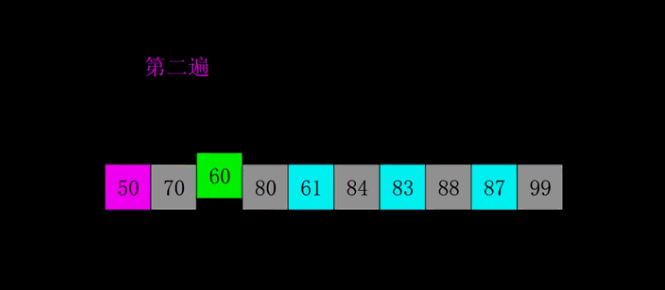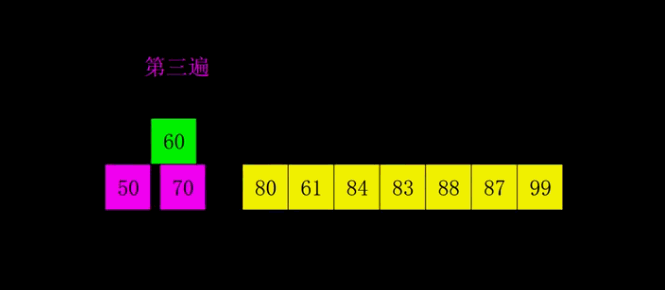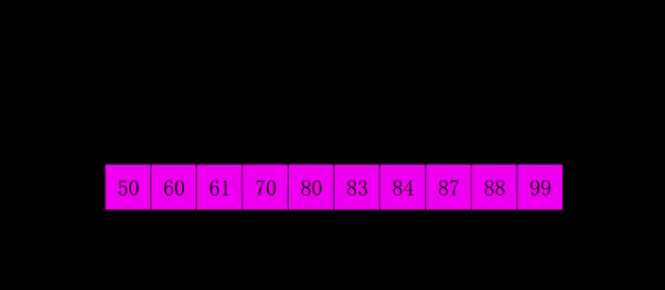
1:选择一个增量序列 t1,t2,…,tk,其中 ti>tj,tk=1;
-
2:按增量序列个数 k,对序列进行 k 趟排序;
-
3:每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
动图:
代码:
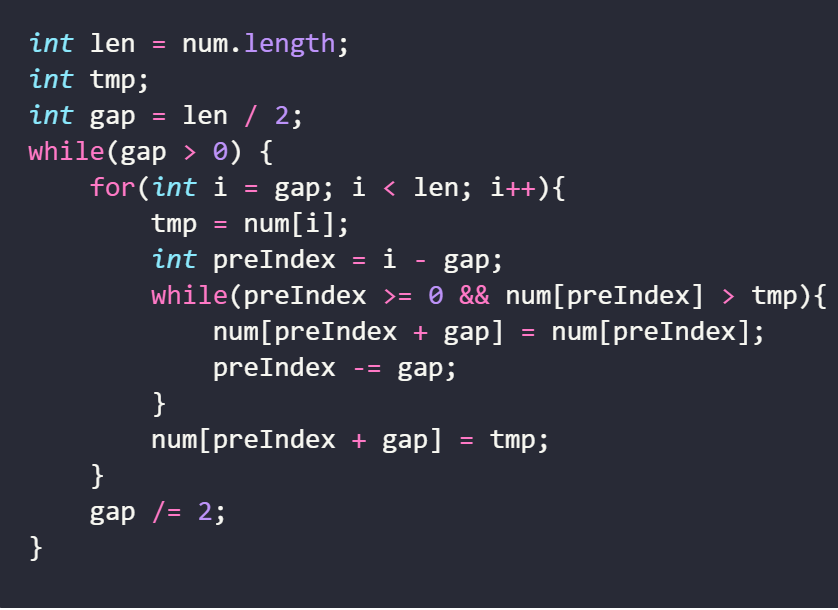
算法分析
-
最佳情况:T(n) = O(nlog2 n)
-
最差情况:T(n) = O(nlog2 n)
-
平均情况:T(n) = O(nlog2 n)
===================================================================
实现步骤:
-
1:把长度为 n 的输入序列分成两个长度为 n/2 的子序列
-
2:对这两个子序列分别采用归并排序
-
3:将两个排序好的子序列合并成一个最终的排序序列
动图:
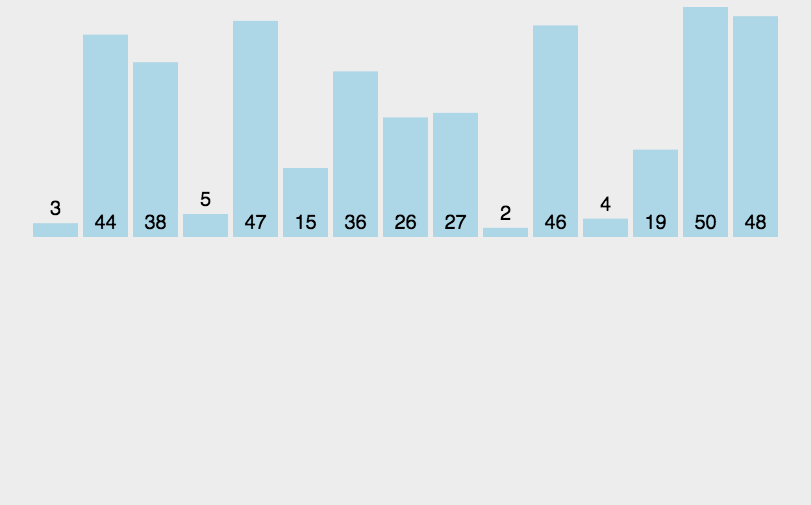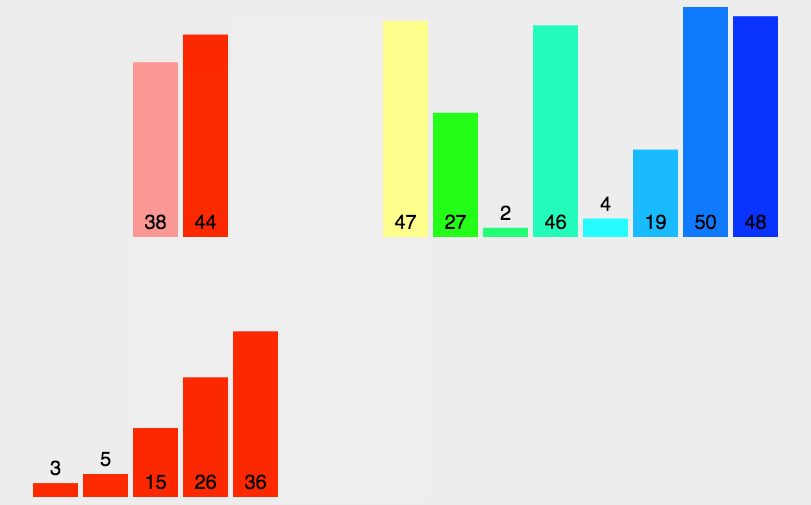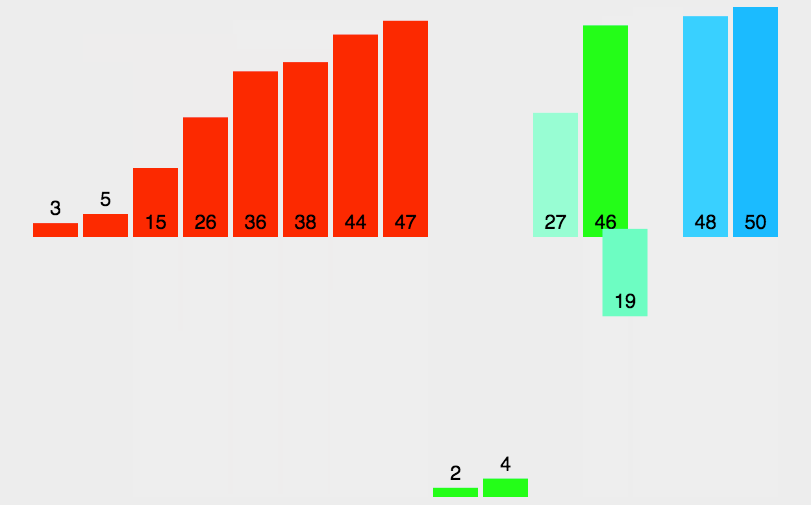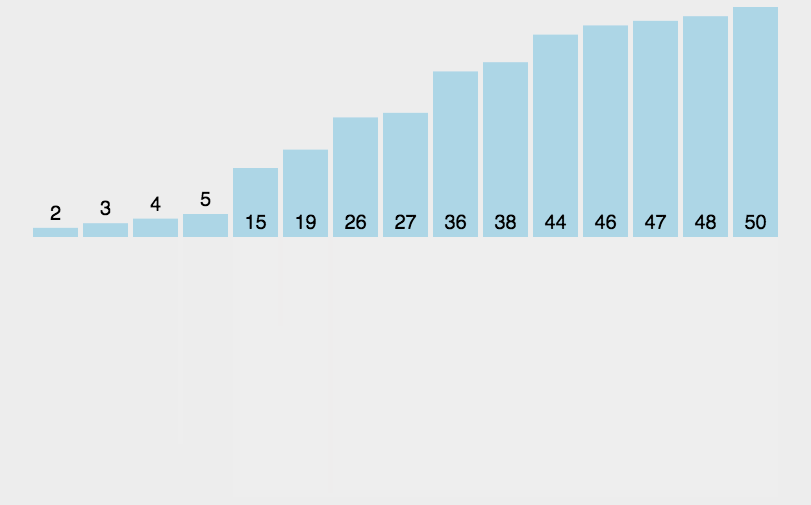
代码:
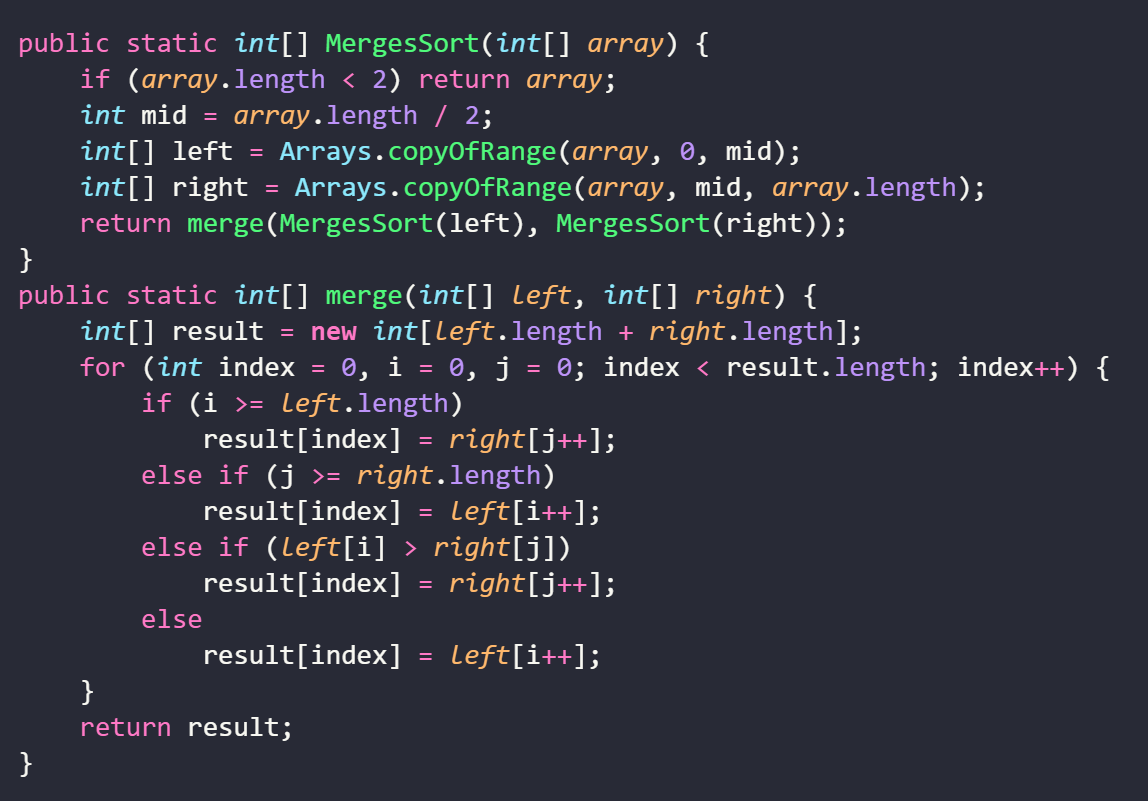
算法分析
-
最佳情况:T(n) = O(n)
-
最差情况:T(n) = O(nlogn)
-
平均情况:T(n) = O(nlogn)
===================================================================
实现步骤:
-
1:从数列中挑出一个元素,称为 “基准”(pivot )
-
2:重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作
-
3:递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序
动图:
代码:
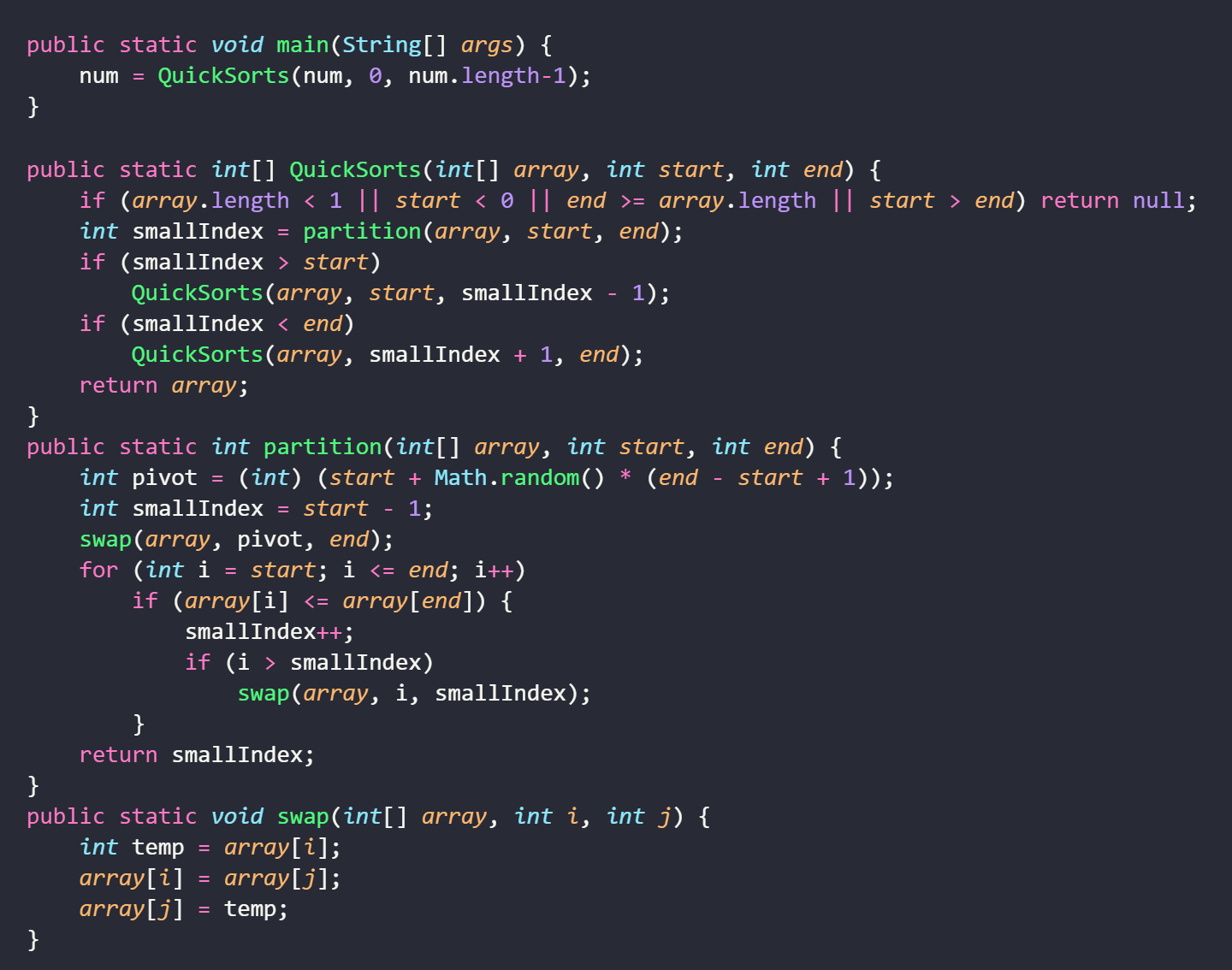
算法分析
-
最佳情况:T(n) = O(nlogn)
-
最差情况:T(n) = O(n^2)
-
平均情况:T(n) = O(nlogn)
Vue 编码基础
2.1.1. 组件规范
2.1.2. 模板中使用简单的表达式
2.1.3 指令都使用缩写形式
2.1.4 标签顺序保持一致
2.1.5 必须为 v-for 设置键值 key
2.1.6 v-show 与 v-if 选择
2.1.7 script 标签内部结构顺序
2.1.8 Vue Router 规范
Vue 项目目录规范
2.2.1 基础
2.2.2 使用 Vue-cli 脚手架
2.2.3 目录说明
2.2.4注释说明
2.2.5 其他
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









