






数据表中的记录默认使用主键(一般为id)排序,上面的结果相当于:
select * from orders_history where type=8 order by id limit 10000,10;
三次查询时间分别为:
-
3040 ms
-
3063 ms
-
3018 ms
针对这种查询方式,下面测试查询记录量对时间的影响:
select * from orders_history where type=8 limit 10000,1;
select * from orders_history where type=8 limit 10000,10;
select * from orders_history where type=8 limit 10000,100;
select * from orders_history where type=8 limit 10000,1000;
select * from orders_history where type=8 limit 10000,10000;
三次查询时间如下:
-
查询1条记录:3072ms 3092ms 3002ms
-
查询10条记录:3081ms 3077ms 3032ms
-
查询100条记录:3118ms 3200ms 3128ms
-
查询1000条记录:3412ms 3468ms 3394ms
-
查询10000条记录:3749ms 3802ms 3696ms
另外我还做了十来次查询,从查询时间来看,基本可以确定,在查询记录量低于100时,查询时间基本没有差距,随着查询记录量越来越大,所花费的时间也会越来越多。
针对查询偏移量的测试:
select * from orders_history where type=8 limit 100,100;
select * from orders_history where type=8 limit 1000,100;
select * from orders_history where type=8 limit 10000,100;
select * from orders_history where type=8 limit 100000,100;
select * from orders_history where type=8 limit 1000000,100;
三次查询时间如下:
-
查询100偏移:25ms 24ms 24ms
-
查询1000偏移:78ms 76ms 77ms
-
查询10000偏移:3092ms 3212ms 3128ms
-
查询100000偏移:3878ms 3812ms 3798ms
-
查询1000000偏移:14608ms 14062ms 14700ms
随着查询偏移的增大,尤其查询偏移大于10万以后,查询时间急剧增加。
这种分页查询方式会从数据库第一条记录开始扫描,所以越往后,查询速度越慢,而且查询的数据越多,也会拖慢总查询速度。
这种方式先定位偏移位置的 id,然后往后查询,这种方式适用于 id 递增的情况。
select * from orders_history where type=8 limit 100000,1;
select id from orders_history where type=8 limit 100000,1;
select * from orders_history where type=8 and
id>=(select id from orders_history where type=8 limit 100000,1)
limit 100;
select * from orders_history where type=8 limit 100000,100;
4条语句的查询时间如下:
-
第1条语句:3674ms
-
第2条语句:1315ms
-
第3条语句:1327ms
-
第4条语句:3710ms
针对上面的查询需要注意:
-
比较第1条语句和第2条语句:使用 select id 代替 select * 速度增加了3倍
-
比较第2条语句和第3条语句:速度相差几十毫秒
-
比较第3条语句和第4条语句:得益于 select id 速度增加,第3条语句查询速度增加了3倍
这种方式相较于原始一般的查询方法,将会增快数倍。
这种方式假设数据表的id是连续递增的,则我们根据查询的页数和查询的记录数可以算出查询的id的范围,可以使用 id between and 来查询:
select * from orders_history where type=2
and id between 1000000 and 1000100 limit 100;
查询时间:15ms 12ms 9ms
这种查询方式能够极大地优化查询速度,基本能够在几十毫秒之内完成。限制是只能使用于明确知道id的情况,不过一般建立表的时候,都会添加基本的id字段,这为分页查询带来很多便利。
还可以有另外一种写法:
select * from orders_history where id >= 1000001 limit 100;
当然还可以使用 in 的方式来进行查询,这种方式经常用在多表关联的时候进行查询,使用其他表查询的id集合,来进行查询:
select * from orders_history where id in
(select order_id from trade_2 where goods = ‘pen’)
limit 100;
这种 in 查询的方式要注意:某些 mysql 版本不支持在 in 子句中使用 limit。
这种方式已经不属于查询优化,这儿附带提一下。
文末
逆水行舟不进则退,所以大家要有危机意识。
同样是干到35岁,普通人写业务代码划水,榜样们深度学习拓宽视野晋升管理。
这也是为什么大家都说35岁是程序员的门槛,很多人迈不过去,其实各行各业都是这样都会有个坎,公司永远都缺的高级人才,只用这样才能在大风大浪过后,依然闪耀不被公司淘汰不被社会淘汰。
为了帮助大家更好温习重点知识、更高效的准备面试,特别整理了《前端工程师核心知识笔记》电子稿文件。
内容包括html,css,JavaScript,ES6,计算机网络,浏览器,工程化,模块化,Node.js,框架,数据结构,性能优化,项目等等。
269页《前端大厂面试宝典》
包含了腾讯、字节跳动、小米、阿里、滴滴、美团、58、拼多多、360、新浪、搜狐等一线互联网公司面试被问到的题目,涵盖了初中级前端技术点。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
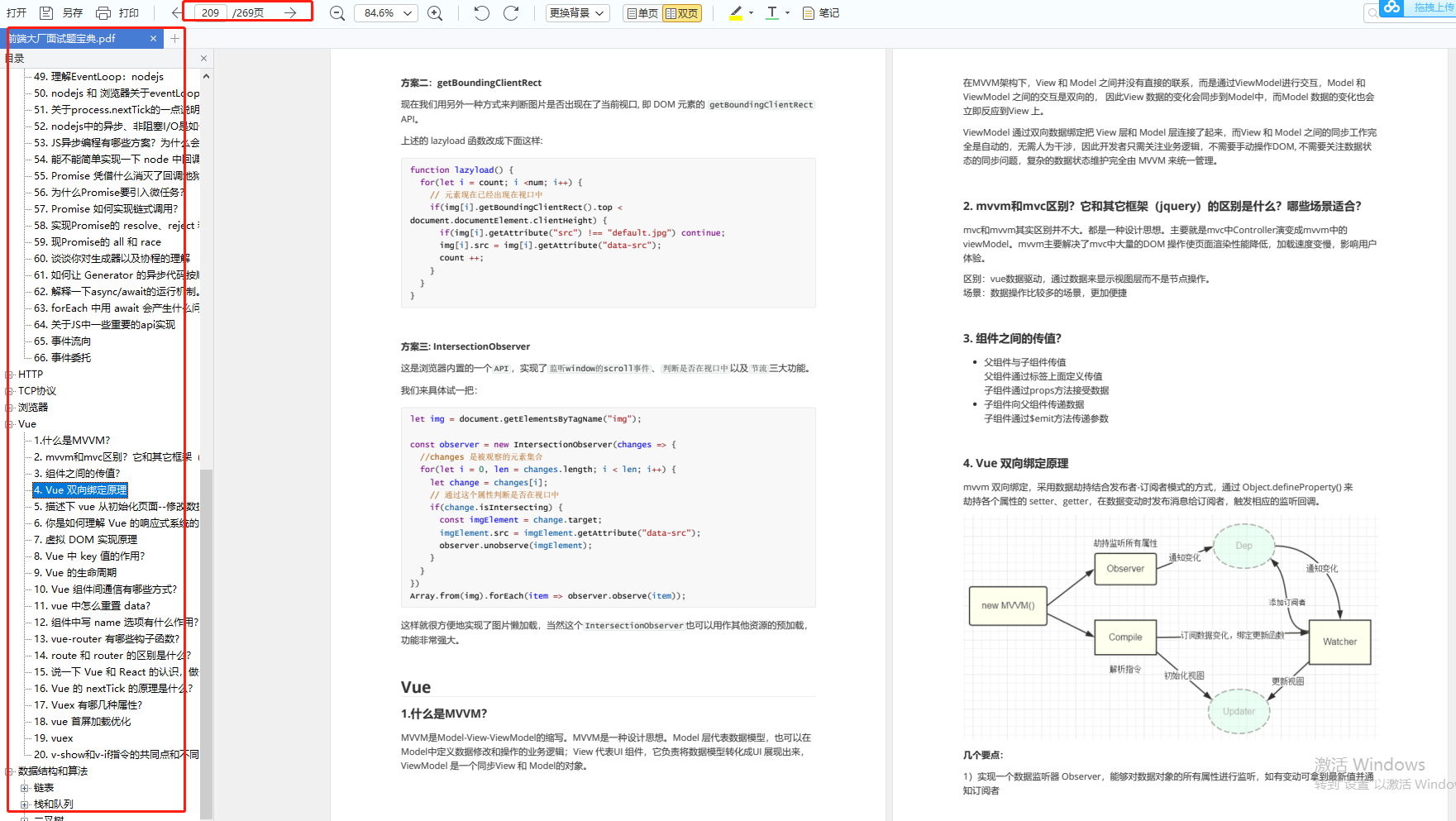
前端面试题汇总
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









