







最后
在面试前我花了三个月时间刷了很多大厂面试题,最近做了一个整理并分类,主要内容包括html,css,JavaScript,ES6,计算机网络,浏览器,工程化,模块化,Node.js,框架,数据结构,性能优化,项目等等。
包含了腾讯、字节跳动、小米、阿里、滴滴、美团、58、拼多多、360、新浪、搜狐等一线互联网公司面试被问到的题目,涵盖了初中级前端技术点。
-
HTML5新特性,语义化
-
浏览器的标准模式和怪异模式
-
xhtml和html的区别
-
使用data-的好处
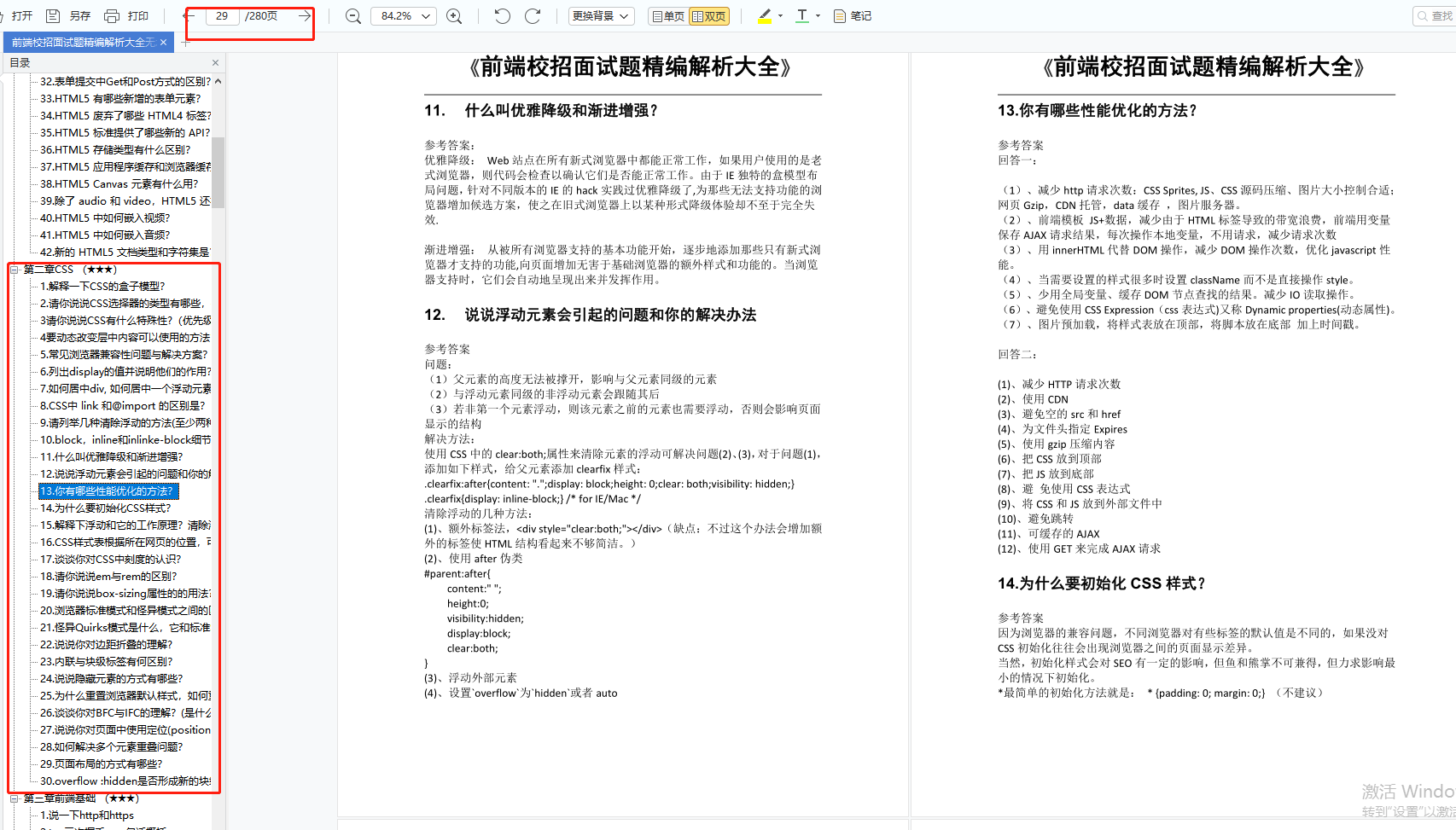
-
meta标签
-
canvas
-
HTML废弃的标签
-
IE6 bug,和一些定位写法
-
css js放置位置和原因
-
什么是渐进式渲染
-
html模板语言
-
meta viewport原理
和 HTML 文件一样,浏览器也是无法直接理解这些纯文本的 CSS 样式,所以当渲染引擎接收到 CSS 文本时,会执行一个转换操作,将 CSS 文本转换为浏览器可以理解的结构——styleSheets。
为了加深理解,你可以在 Chrome 控制台中查看其结构,只需要在控制台中输入 document.styleSheets,然后就看到如下图所示的结构:

从图中可以看出,这个样式表包含了很多种样式,已经把那三种来源的样式都包含进去了。当然样式表的具体结构不是我们今天讨论的重点,你只需要知道渲染引擎会把获取到的 CSS 文本全部转换为 styleSheets 结构中的数据,并且该结构同时具备了查询和修改功能,这会为后面的样式操作提供基础。
现在我们已经把现有的 CSS 文本转化为浏览器可以理解的结构了,那么接下来就要对其进行属性值的标准化操作。
要理解什么是属性值标准化,你可以看下面这样一段 CSS 文本:
body { font-size: 2em }
p {color:blue;}
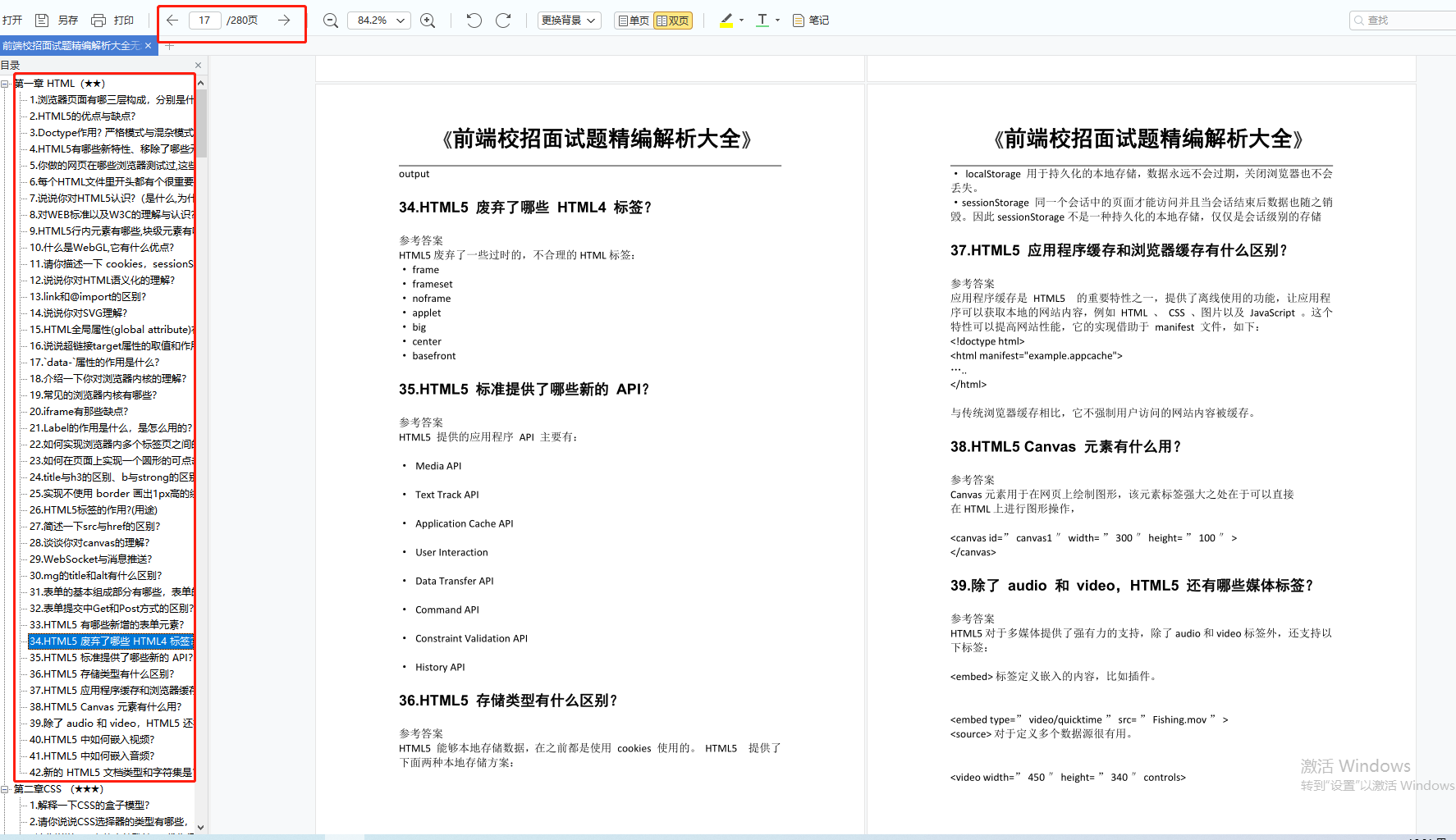
span {display: none}
div {font-weight: bold}
div p {color:green;}
div {color:red; }
可以看到上面的 CSS 文本中有很多属性值,如 2em、blue、bold,这些类型数值不容易被渲染引擎理解,所以需要将所有值转换为渲染引擎容易理解的、标准化的计算值,这个过程就是属性值标准化。
那标准化后的属性值是什么样子的?

从图中可以看到,2em 被解析成了 32px,red 被解析成了 rgb(255,0,0),bold 被解析成了 700……
现在样式的属性已被标准化了,接下来就需要计算 DOM 树中每个节点的样式属性了,如何计算呢?
这就涉及到 CSS 的继承规则和层叠规则了。
首先是 CSS 继承。CSS 继承就是每个 DOM 节点都包含有父节点的样式。这么说可能有点抽象,我们可以结合具体例子,看下面这样一张样式表是如何应用到 DOM 节点上的。
body { font-size: 20px }
p {color:blue;}
span {display: none}
div {font-weight: bold;color:red}
div p {color:green;}
这张样式表最终应用到 DOM 节点的效果如下图所示:

从图中可以看出,所有子节点都继承了父节点样式。比如 body 节点的 font-size 属性是 20,那 body 节点下面的所有节点的 font-size 都等于 20。
为了加深你对 CSS 继承的理解,你可以打开 Chrome 的“开发者工具”,选择第一个“element”标签,再选择“style”子标签,你会看到如下界面:

这个界面展示的信息很丰富,大致可描述为如下:
-
首先,可以选择要查看的元素的样式(位于图中的区域 2 中),在图中的第 1 个区域中点击对应的元素,就可以在下面的区域查看该元素的样式了。比如这里我们选择的元素是< p >标签,位于 html.body.div. 这个路径下面。
-
其次,可以从样式来源(位于图中的区域 3 中)中查看样式的具体来源信息,看看是来源于样式文件,还是来源于 UserAgent 样式表。这里需要特别提下 UserAgent 样式,它是浏览器提供的一组默认样式,如果你不提供任何样式,默认使用的就是 UserAgent 样式。
-
最后,可以通过区域 2 和区域 3 来查看样式继承的具体过程。
以上就是 CSS 继承的一些特性,样式计算过程中,会根据 DOM 节点的继承关系来合理计算节点样式。
样式计算过程中的第二个规则是样式层叠。层叠是 CSS 的一个基本特征,它是一个定义了如何合并来自多个源的属性值的算法。它在 CSS 处于核心地位,CSS 的全称“层叠样式表”正是强调了这一点。关于层叠的具体规则这里就不做过多介绍了,网上资料也非常多,你可以自行搜索学习。
总之,样式计算阶段的目的是为了计算出 DOM 节点中每个元素的具体样式,在计算过程中需要遵守 CSS 的继承和层叠两个规则。这个阶段最终输出的内容是每个 DOM 节点的样式,并被保存在 ComputedStyle 的结构内。
如果你想了解每个 DOM 元素最终的计算样式,可以打开 Chrome 的“开发者工具”,选择第一个“element”标签,然后再选择“Computed”子标签,如下图所示:

上图红色方框中显示了 html.body.div.p 标签的 ComputedStyle 的值。你想要查看哪个元素,点击左边对应的标签就可以了。
=====================================================================
现在,我们有 DOM 树和 DOM 树中元素的样式,但这还不足以显示页面,因为我们还不知道 DOM 元素的几何位置信息。那么接下来就需要计算出 DOM 树中可见元素的几何位置,我们把这个计算过程叫做布局。
Chrome 在布局阶段需要完成两个任务:创建布局树和布局计算。
你可能注意到了 DOM 树还含有很多不可见的元素,比如 head 标签,还有使用了 display:none 属性的元素。所以在显示之前,我们还要额外地构建一棵只包含可见元素布局树。
我们结合下图来看看布局树的构造过程:

从上图可以看出,DOM 树中所有不可见的节点都没有包含到布局树中。
为了构建布局树,浏览器大体上完成了下面这些工作:
-
遍历 DOM 树中的所有可见节点,并把这些节点加到布局树中;
-
而不可见的节点会被布局树忽略掉,如 head 标签下面的全部内容,再比如 body.p.span 这个元素,因为它的属性包含 dispaly:none,所以这个元素也没有被包进布局树。
现在我们有了一棵完整的布局树。那么接下来,就要计算布局树节点的坐标位置了。布局的计算过程非常复杂,我们这里先跳过不讲,等到后面章节中我再做详细的介绍。
在执行布局操作的时候,会把布局运算的结果重新写回布局树中,所以布局树既是输入内容也是输出内容,这是布局阶段一个不合理的地方,因为在布局阶段并没有清晰地将输入内容和输出内容区分开来。针对这个问题,Chrome 团队正在重构布局代码,下一代布局系统叫 LayoutNG,试图更清晰地分离输入和输出,从而让新设计的布局算法更加简单。
===================================================================
现在我们有了布局树,而且每个元素的具体位置信息都计算出来了,那么接下来是不是就要开始着手绘制页面了?
答案依然是否定的。
因为页面中有很多复杂的效果,如一些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree)。如果你熟悉 PS,相信你会很容易理解图层的概念,正是这些图层叠加在一起构成了最终的页面图像。
要想直观地理解什么是图层,你可以打开 Chrome 的“开发者工具”,选择“Layers”标签,就可以可视化页面的分层情况,如下图所示:

从上图可以看出,渲染引擎给页面分了很多图层,这些图层按照一定顺序叠加在一起,就形成了最终的页面,你可以参考下图:

现在你知道了浏览器的页面实际上被分成了很多图层,这些图层叠加后合成了最终的页面。下面我们再来看看这些图层和布局树节点之间的关系,如文中图所示:

通常情况下,并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么这个节点就从属于父节点的图层。如上图中的 span 标签没有专属图层,那么它们就从属于它们的父节点图层。但不管怎样,最终每一个节点都会直接或者间接地从属于一个层。
那么需要满足什么条件,渲染引擎才会为特定的节点创建新的图层呢?通常满足下面两点中任意一点的元素就可以被提升为单独的一个图层。
第一点,拥有层叠上下文属性的元素会被提升为单独的一层。
页面是个二维平面,但是层叠上下文能够让 HTML 元素具有三维概念,这些 HTML 元素按照自身属性的优先级分布在垂直于这个二维平面的 z 轴上。你可以结合下图来直观感受下:

从图中可以看出,明确定位属性的元素、定义透明属性的元素、使用 CSS 滤镜的元素等,都拥有层叠上下文属性。
第二点,需要剪裁(clip)的地方也会被创建为图层。
不过首先你需要了解什么是剪裁,结合下面的 HTML 代码:
所以元素有了层叠上下文的属性或者需要被剪裁,那么就会被提升成为单独一层,你可以参看下图:
从上图我们可以看到,document层上有A和B层,而B层之上又有两个图层。这些图层组织在一起也是一颗树状结构。
图层树是基于布局树来创建的,为了找出哪些元素需要在哪些层中,渲染引擎会遍历布局树来创建层树(Update LayerTree)。
在这里我们把 div 的大小限定为 200 * 200 像素,而 div 里面的文字内容比较多,文字所显示的区域肯定会超出 200 * 200 的面积,这时候就产生了剪裁,渲染引擎会把裁剪文字内容的一部分用于显示在 div 区域,下图是运行时的执行结果:

出现这种裁剪情况的时候,渲染引擎会为文字部分单独创建一个层,如果出现滚动条,滚动条也会被提升为单独的层。你可以参考下图:

所以说,元素有了层叠上下文的属性或者需要被剪裁,满足其中任意一点,就会被提升成为单独一层。
=====================================================================
在完成图层树的构建之后,渲染引擎会对图层树中的每个图层进行绘制,那么接下来我们看看渲染引擎是怎么实现图层绘制的?
试想一下,如果给你一张纸,让你先把纸的背景涂成蓝色,然后在中间位置画一个红色的圆,最后再在圆上画个绿色三角形。你会怎么操作呢?
通常,你会把你的绘制操作分解为三步:
-
绘制蓝色背景;
-
在中间绘制一个红色的圆;
-
再在圆上绘制绿色三角形。
渲染引擎实现图层的绘制与之类似,会把一个图层的绘制拆分成很多小的绘制指令,然后再把这些指令按照顺序组成一个待绘制列表,如下图所示:

从图中可以看出,绘制列表中的指令其实非常简单,就是让其执行一个简单的绘制操作,比如绘制粉色矩形或者黑色的线等。而绘制一个元素通常需要好几条绘制指令,因为每个元素的背景、前景、边框都需要单独的指令去绘制。所以在图层绘制阶段,输出的内容就是这些待绘制列表。
你也可以打开“开发者工具”的“Layers”标签,选择“document”层,来实际体验下绘制列表,如下图所示:

在该图中,区域 1 就是 document 的绘制列表,拖动区域 2 中的进度条可以重现列表的绘制过程。
====================================================================
绘制列表只是用来记录绘制顺序和绘制指令的列表,而实际上绘制操作是由渲染引擎中的合成线程来完成的。你可以结合下图来看下渲染主线程和合成线程之间的关系:

如上图所示,当图层的绘制列表准备好之后,主线程会把该绘制列表提交(commit)给合成线程,那么接下来合成线程是怎么工作的呢?
那我们得先来看看什么是视口,你可以参看下图:

通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(viewport)。
在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
基于这个原因,合成线程会将图层划分为图块(tile),这些图块的大小通常是 256x256 或者 512x512,如下图所示:

然后合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。而图块是栅格化执行的最小单位。渲染进程维护了一个栅格化的线程池,所有的图块栅格化都是在线程池内执行的,运行方式如下图所示:

通常,栅格化过程都会使用 GPU 来加速生成,使用 GPU 生成位图的过程叫快速栅格化,或者 GPU 栅格化,生成的位图被保存在 GPU 内存中。
相信你还记得,GPU 操作是运行在 GPU 进程中,如果栅格化操作使用了 GPU,那么最终生成位图的操作是在 GPU 中完成的,这就涉及到了跨进程操作。具体形式你可以参考下图:

从图中可以看出,渲染进程把生成图块的指令发送给 GPU,然后在 GPU 中执行生成图块的位图,并保存在 GPU 的内存中。
最后
好了,这就是整理的前端从入门到放弃的学习笔记,还有很多没有整理到,我也算是边学边去整理,后续还会慢慢完善,这些相信够你学一阵子了。
做程序员,做前端工程师,真的是一个学习就会有回报的职业,不看出身高低,不看学历强弱,只要你的技术达到应有的水准,就能够得到对应的回报。
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
学习从来没有一蹴而就,都是持之以恒的,正所谓活到老学到老,真正懂得学习的人,才不会被这个时代的洪流所淘汰。















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









