







css
1,盒模型
2,如何实现一个最大的正方形
3,一行水平居中,多行居左
4,水平垂直居中
5,两栏布局,左边固定,右边自适应,左右不重叠
6,如何实现左右等高布局
7,画三角形
8,link @import导入css
9,BFC理解

js
1,判断 js 类型的方式
2,ES5 和 ES6 分别几种方式声明变量
3,闭包的概念?优缺点?
4,浅拷贝和深拷贝
5,数组去重的方法
6,DOM 事件有哪些阶段?谈谈对事件代理的理解
7,js 执行机制、事件循环
8,介绍下 promise.all
9,async 和 await,
10,ES6 的 class 和构造函数的区别
11,transform、translate、transition 分别是什么属性?CSS 中常用的实现动画方式,
12,介绍一下rAF(requestAnimationFrame)
13,javascript 的垃圾回收机制讲一下,
14,对前端性能优化有什么了解?一般都通过那几个方面去优化的?

开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
pip install requests
在博文《Python进阶(二十)-Python爬虫实例讲解》、《Python进阶(十八)-Python3爬虫小试牛刀之爬取CSDN博客个人信息》中讲解了利用urllib、bs4爬取网页信息。下面讲解利用requests和bs4的爬取网页信息。
三、数据获取
在模拟访问过程中,需要设置好请求头,已达到模拟浏览器访问的效果请求头设置如下:
#伪装headers
headers = {
#伪装成浏览器访问,直接访问的话csdn会拒绝
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
# 若写成'Proxy-Connection':'keep-alive',则CSDN会拒绝访问
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,\*/\*;q=0.8',
'Referer': 'http://write.blog.csdn.net/postlist/6788536/0/enabled/2',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
有关请求头的获取,可使用浏览器自带的“开发者工具获取”或利用Fiddler工具,有关Fiddler的详细使用参见博文《Fiddler(一) - Fiddler简介》、《Fiddler(二) - 使用Fiddler做抓包分析》、《Python进阶(三十五)-Fiddler命令行和HTTP断点调试》。
使用requests访问网站时语句特别简洁,如下:
#构造请求,访问页面
response = requests.get(myUrl,headers=headers)
其中,response即为访问返回结果。获取到结果之后requests的使用至此结束。然后就是使用bs4进行文档解析了。代码如下:
# 创建BeautifulSoup对象
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, "html.parser")
下面以获取博客访问信息为例,首先参照网页源码获悉页面元素布局。

bs4解析代码如下:
# 获取<ul id="blog\_rank">
ul = soup.find('ul', {'id': 'blog\_rank'})
# 获取所有的li
lists = ul.find_all('li')
# 对每个li标签中的内容进行遍历
for li in lists:
# 找到访问总量
data = li.find('span').string
# print(type(data))
if data is None:
# http://c.csdnimg.cn/jifen/images/xunzhang/jianzhang/blog8.png
src = dict(li.find('img', {'id': 'leveImg'}).attrs)['src']
# 52
# print(src.index('blog'))
# print(src[56])
data = src[56]
在获取等级时,需要进行特殊处理。
四、模拟登录
在获取粉丝数量时,首先要模拟用户登录。
采用python模拟登录CSDN的时候分为三步走:
- 获取url=https://passport.csdn.net/account/login;
- 分析登录信息:从网页中得到username,password和hideen标签隐藏的属性,在CSDN中有三个隐藏标签,lt,execution,_eventId //注意这三个标签是动态的。同时注意到表单使用post提交方式。

- 下面使用post方式实现表单提交操作,代码如下:
import re
import requests
url = "https://passport.csdn.net/account/login"
head = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36",
}
Username = "\*\*\*"
PassWord = "\*\*\*"
s = requests.session()
r = s.get(url,headers=head)
lt_execution_id = re.findall('name="lt" value="(.\*?)".\*\sname="execution" value="(.\*?)"', r.text, re.S)
payload = {
"username": Username,
"password": PassWord,
"lt" : lt_execution_id[0][0],
"execution" : lt_execution_id[0][1],
"\_eventId" : "submit"
}
r2 = s.post(url,headers=head,data=payload)
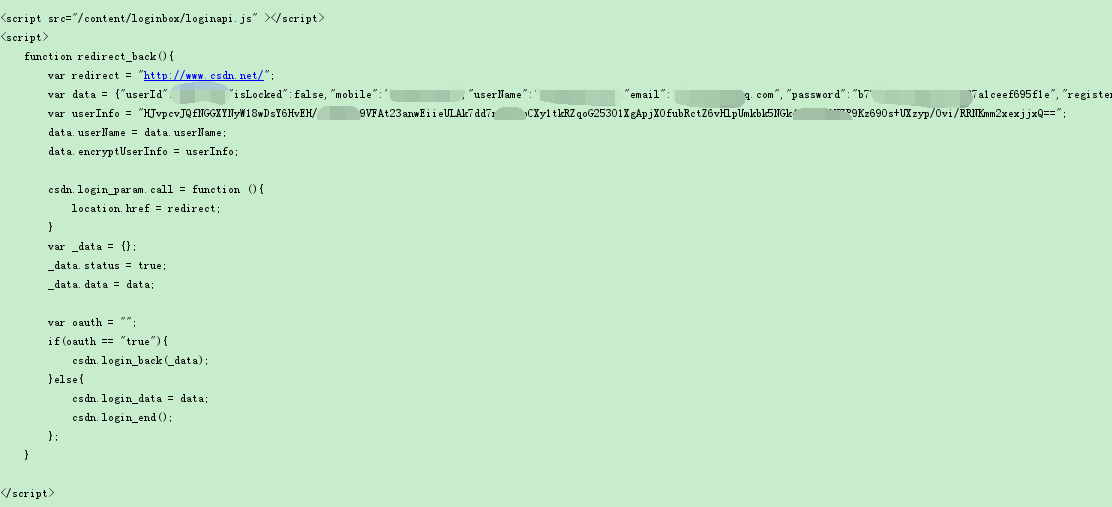
print(r2.text) #登录成功会返回一段loginapi.js的脚本
print("\*"\*100) #分隔符
r3 = s.get("http://my.csdn.net",headers=head)
print(r3.text) #成功获取"我的主页"源代码
程序运行结果如下:

五、bs4解析
接下来使用bs4解析出粉丝数量及个人信息。
def craw\_csdn(self, response):
# 创建BeautifulSoup对象
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, "html.parser")
# 按照标准的缩进格式的结构输出
# print(soup.prettify())
# 获取body部分
body = soup.body
# <dd class="focus\_num"><b><a href='/my/follow' target=\_blank>5</a></b>关注</dd>
focus = soup.find('dd', class_='focus\_num').find('a').string
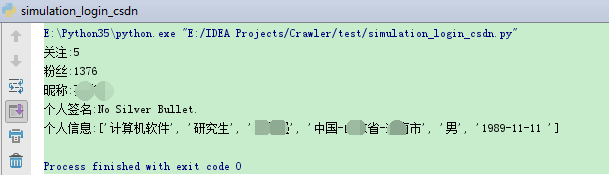
print("关注:" + str(focus))
# <dd class="fans\_num"><b><a href='/my/fans' target=\_blank>1374</a></b>粉丝</dd>
fans = soup.find('dd', class_='fans\_num').find('a').string
print("粉丝:" + str(fans))
# <dt class="person-nick-name">
# <span>\*\*\*</span> </dt>
nick_name = soup.find('dt', class_='person-nick-name').find('span').string
print("昵称:" + str(nick_name))
# <dd class="person-detail">
# 计算机软件<span>|</span>研究生<span>|</span>\*\*\*<span>|</span>中国-\*\*省-\*\*市<span>|</span>男<span>|</span>19\*\*11-11 </dd>
# <dd class="person-sign">No Silver Bullet.</dd>
person_detail = soup.find('dd', class_='person-detail').contents
# print(len(person\_detail))
len_person_detail = len(person_detail)
pd = []
#代表从0到5,间隔2(不包含5)
for i in range(0,len_person_detail,2):
# print(person\_detail[i])
if i == 0:
pd.append(person_detail[i].lstrip(' \n \t\t'))
else:
pd.append(person_detail[i])
print("个人信息:" + str(pd))
return int(fans)
爬取结果如下图所示:
六、总结
最后
前端CSS面试题文档,JavaScript面试题文档,Vue面试题文档,大厂面试题文档
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】


前端CSS面试题文档,JavaScript面试题文档,Vue面试题文档,大厂面试题文档*
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
[外链图片转存中…(img-WDueNqwa-1715792548420)]
[外链图片转存中…(img-j7f2eJe0-1715792548421)]















 1336
1336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









