







每个 ES|QL 查询都以源命令开头。 源命令会生成一个表,通常包含来自 Elasticsearch 的数据。
FROM source 命令返回一个表,其中包含来自数据流、索引或别名的文档。 结果表中的每一行代表一个文档。 此查询从 sample_data 索引中返回最多 500 个文档:
esql_query = "FROM sample_data"
response = es.esql.query(query=esql_query)
format_response(response)
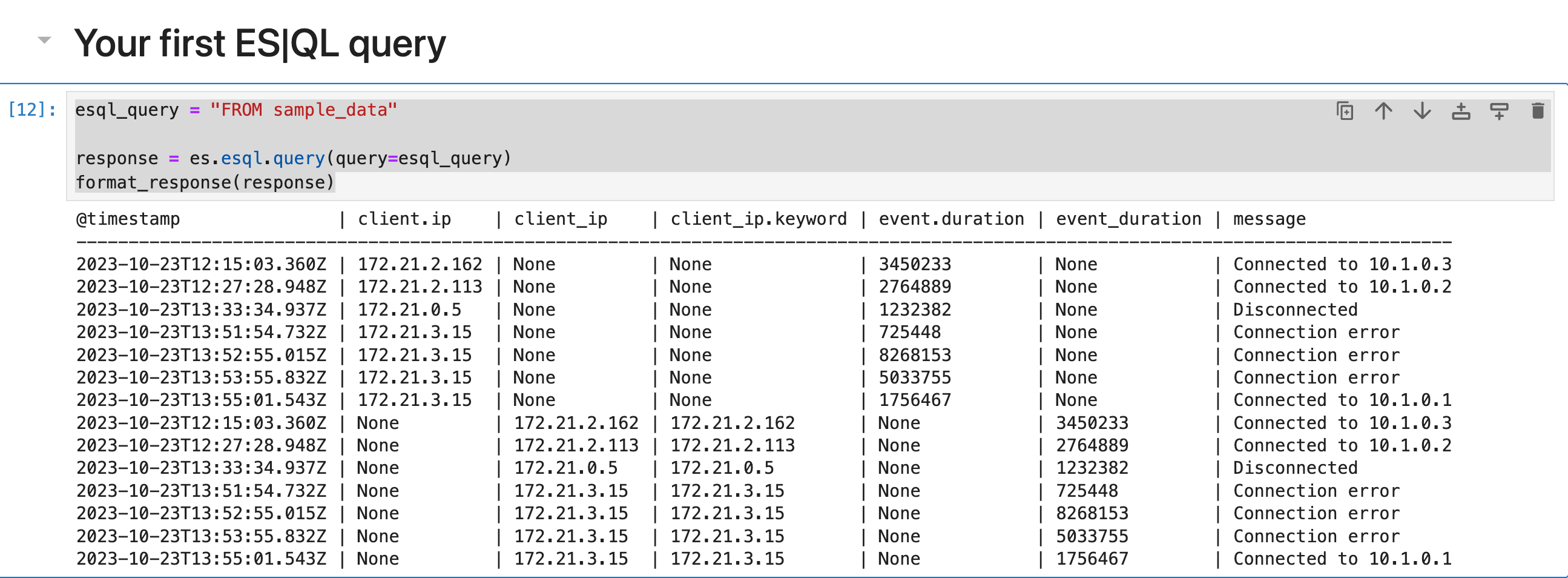
每列对应一个字段,并且可以通过该字段的名称进行访问。
ℹ️ ES|QL 关键字不区分大小写。 FROM sample_data 与 from sample_data 相同。
处理命令
源命令后面可以跟一个或多个处理命令,用竖线字符分隔:|。 处理命令通过添加、删除或更改行和列来更改输入表。 处理命令可以执行过滤、投影、聚合等。
例如,你可以使用 LIMIT 命令来限制返回的行数,最多为 10,000 行:
esql_query = """
FROM sample_data
| LIMIT 3
"""
response = es.esql.query(query=esql_query)
format_response(response)

对表格进行排序
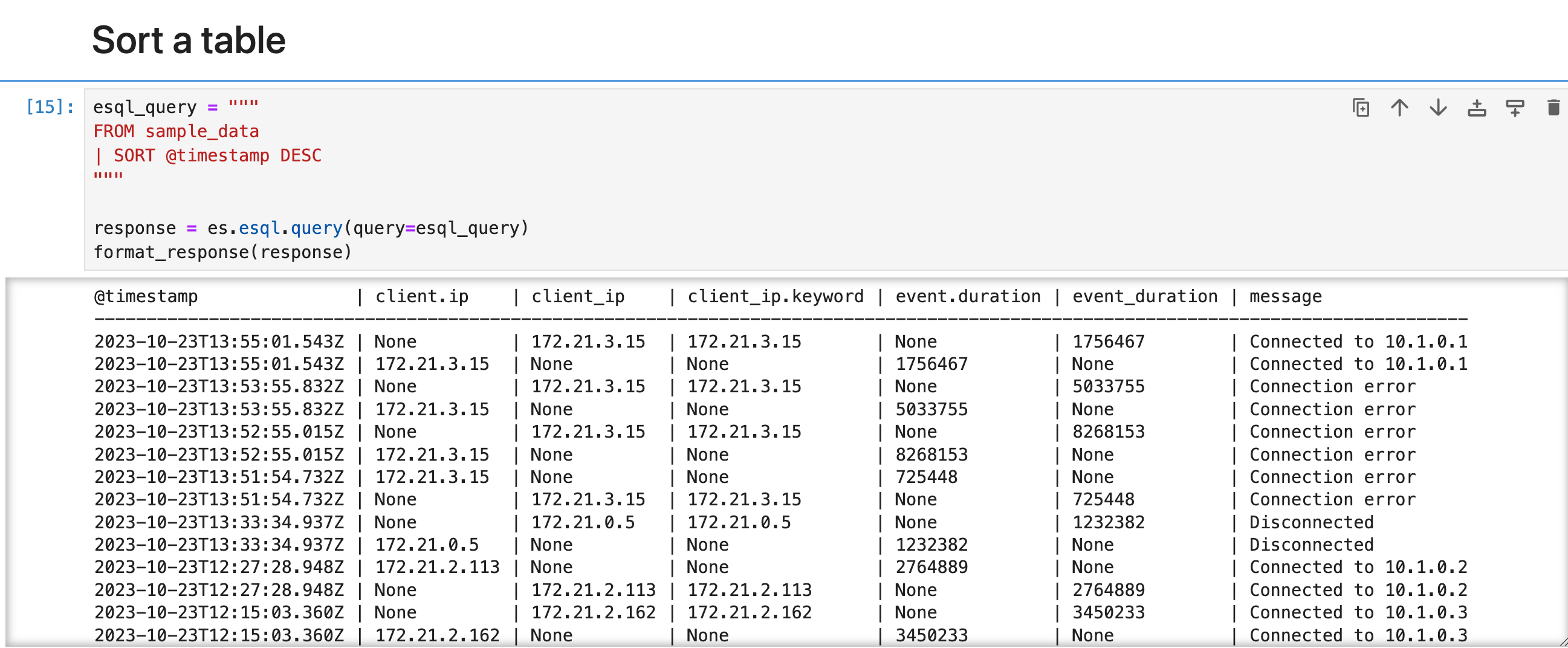
另一个处理命令是 SORT 命令。 默认情况下,FROM 返回的行没有定义的排序顺序。 使用 SORT 命令对一列或多列上的行进行排序:
esql_query = """
FROM sample_data
| SORT @timestamp DESC
"""
response = es.esql.query(query=esql_query)
format_response(response)
查询数据
使用 WHERE 命令来查询数据。 例如,要查找持续时间超过 5 毫秒的所有事件:
esql_query = """
FROM sample_data
| WHERE event_duration > 5000000
"""
response = es.esql.query(query=esql_query)
format_response(response)
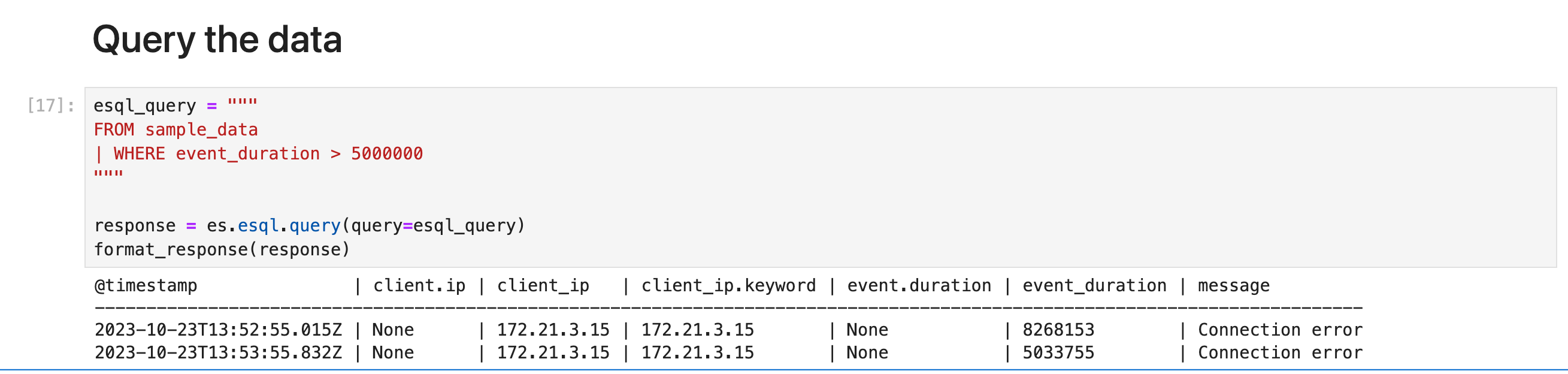
WHERE 支持多个运算符。
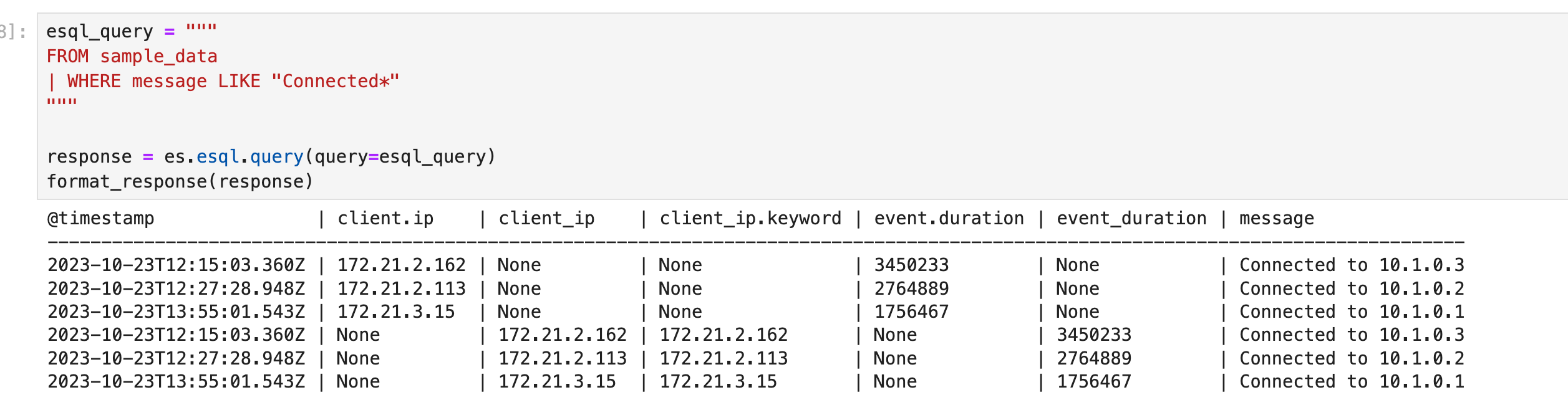
例如,你可以使用 LIKE 对消息列运行通配符查询:
esql_query = """
FROM sample_data
| WHERE message LIKE "Connected*"
"""
response = es.esql.query(query=esql_query)
format_response(response)
更多处理命令
还有许多其他处理命令,例如用于保留或删除列的 KEEP 和 DROP、用于使用 Elasticsearch 中索引的数据丰富表的 ENRICH 以及用于处理数据的 DISSECT 和 GROK。 有关概述,请参阅处理命令。
链式处理命令
你可以链接处理命令,并用竖线字符分隔:|。 每个处理命令都作用于前一个命令的输出表。 查询的结果是最终处理命令生成的表。
以下示例首先根据 @timestamp 对表进行排序,然后将结果集限制为 3 行:
esql_query = """
FROM sample_data
| SORT @timestamp DESC
| LIMIT 3
"""
response = es.esql.query(query=esql_query)
format_response(response)
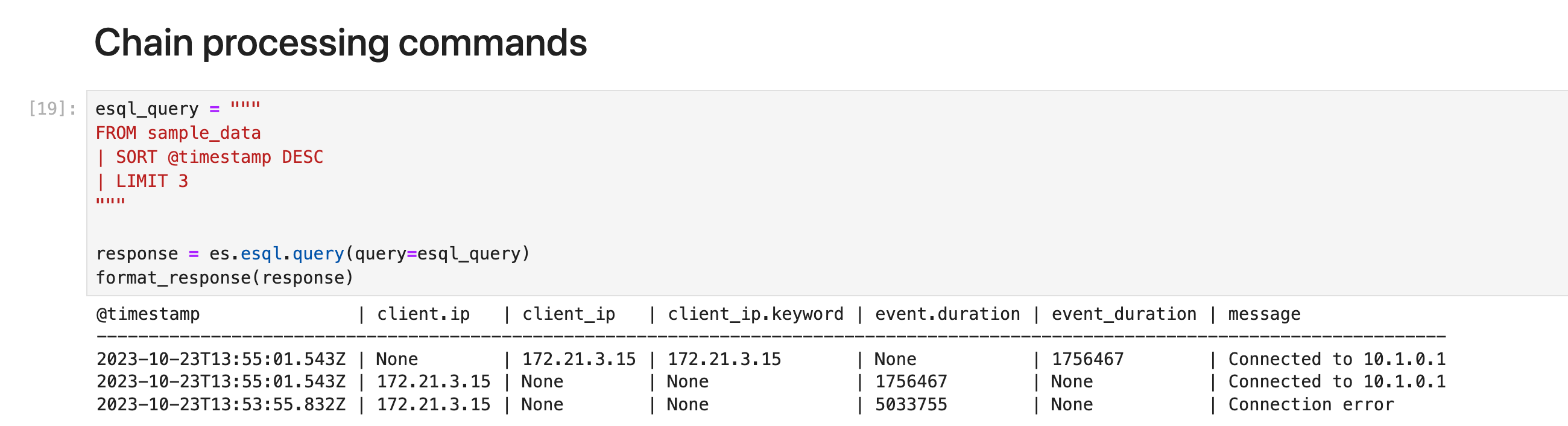
ℹ️ 处理命令的顺序很重要。 首先将结果集限制为 3 行,然后再对这 3 行进行排序,很可能会返回与此示例不同的结果,其中排序在限制之前。
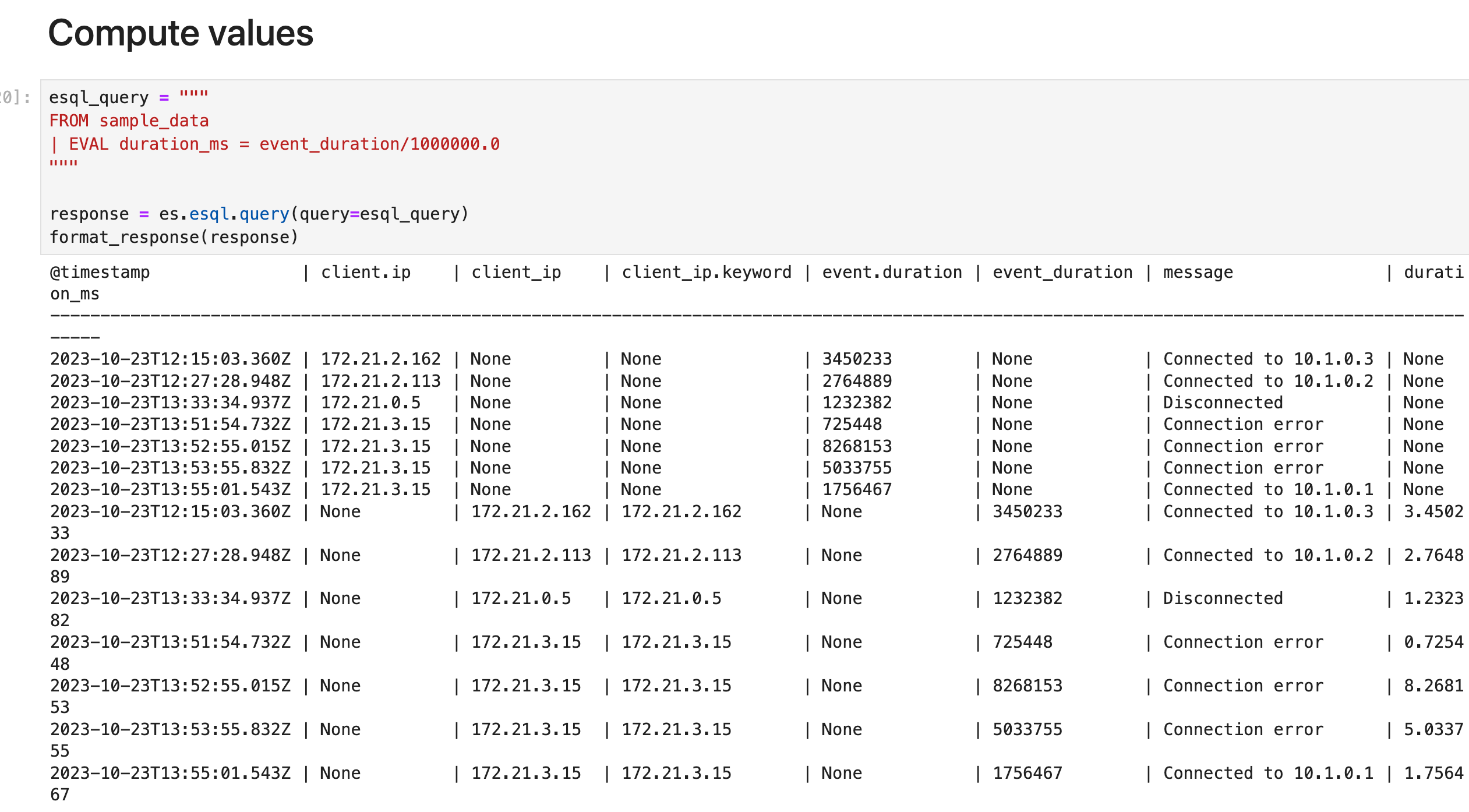
计算值
使用 EVAL 命令将包含计算值的列追加到表中。 例如,以下查询附加一个 duration_ms 列。 该列中的值是通过将 event_duration 除以 1,000,000 计算得出的。 换句话说: event_duration 从纳秒转换为毫秒。
esql_query = """
FROM sample_data
| EVAL duration_ms = event_duration/1000000.0
"""
response = es.esql.query(query=esql_query)
format_response(response)
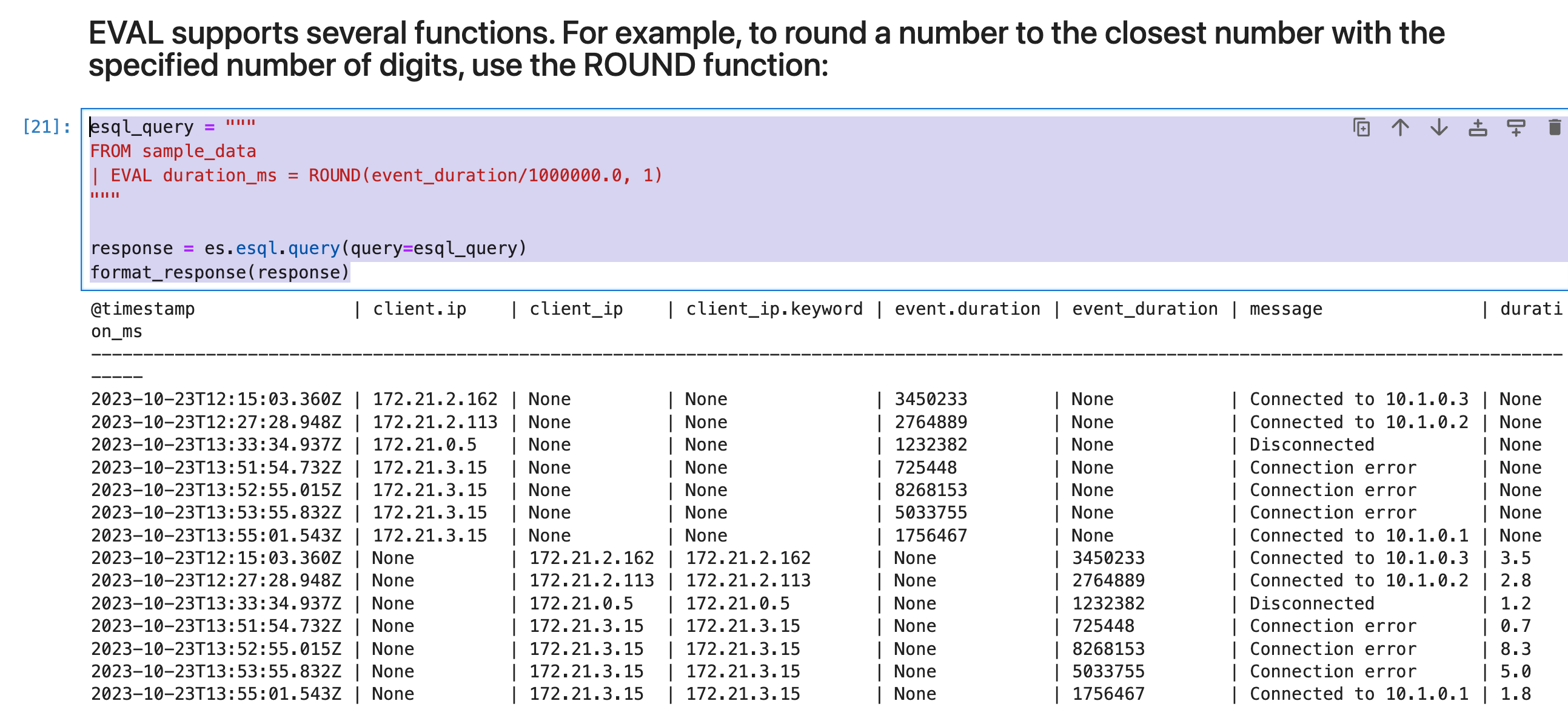
EVAL 支持多种函数。 例如,要将数字四舍五入为最接近指定位数的数字,请使用 ROUND 函数:
esql_query = """
FROM sample_data
| EVAL duration_ms = ROUND(event_duration/1000000.0, 1)
"""
response = es.esql.query(query=esql_query)
format_response(response)
计算统计数据
你还可以使用 ES|QL 来聚合数据。 使用 STATS … BY 命令计算统计数据。
例如,计算中位持续时间:
esql_query = """
FROM sample_data
| STATS median_duration = MEDIAN(event_duration)
"""
response = es.esql.query(query=esql_query)
format_response(response)

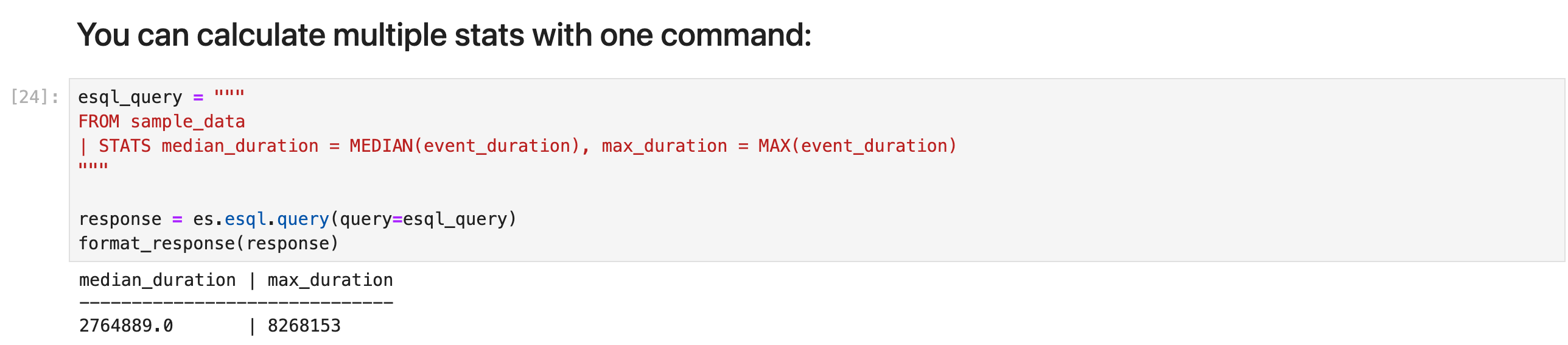
你可以使用一个命令计算多个统计数据:
esql_query = """
FROM sample_data
| STATS median_duration = MEDIAN(event_duration), max_duration = MAX(event_duration)
"""
response = es.esql.query(query=esql_query)
format_response(response)
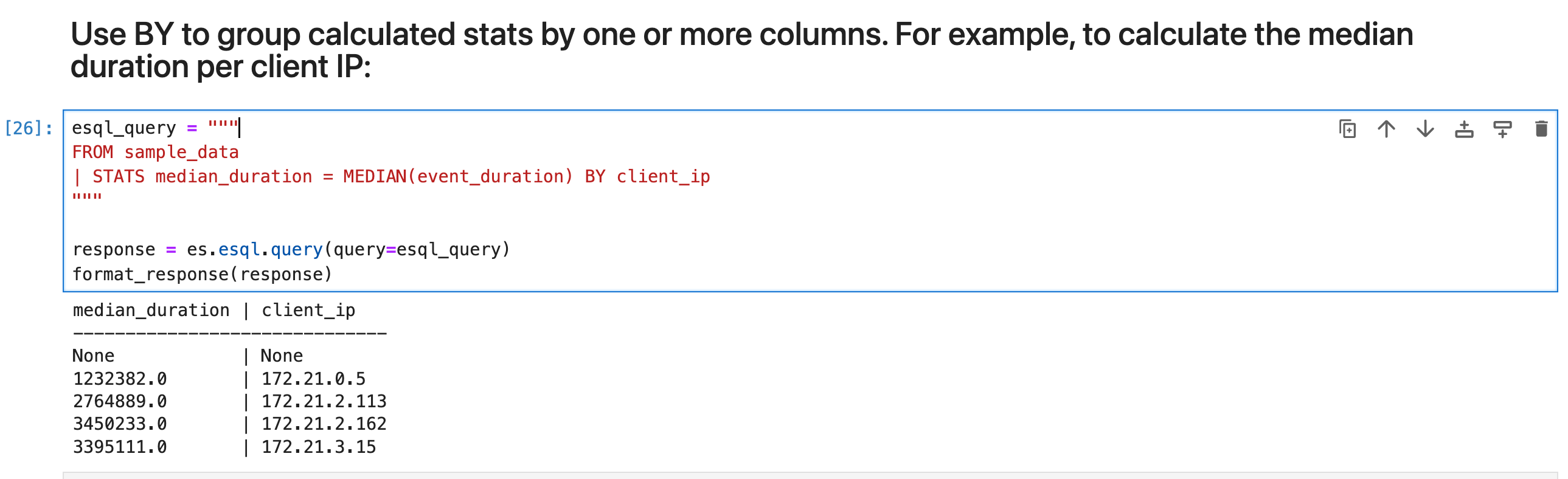
使用 BY 按一列或多列对计算的统计数据进行分组。 例如,要计算每个客户端 IP 的中位持续时间:
esql_query = """
FROM sample_data
| STATS median_duration = MEDIAN(event_duration) BY client_ip
"""
response = es.esql.query(query=esql_query)
format_response(response)
访问列
你可以通过名称访问列。 如果名称包含特殊字符,则需要用反引号(`)引起来。
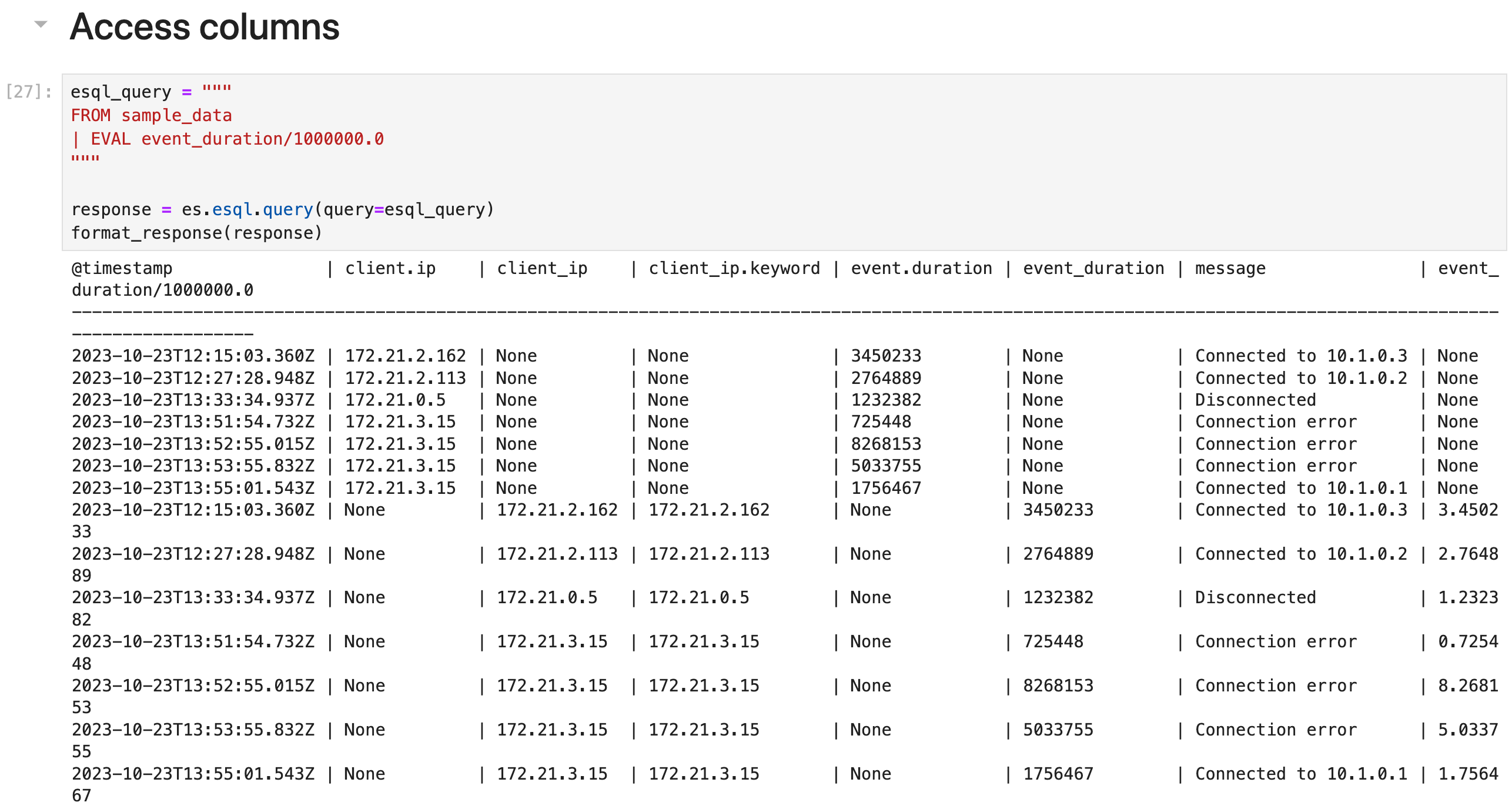
为 EVAL 或 STATS 创建的列分配显式名称是可选的。 如果不提供名称,则新列名称等于函数表达式。 例如:
esql_query = """
FROM sample_data
| EVAL event_duration/1000000.0
"""
response = es.esql.query(query=esql_query)
format_response(response)
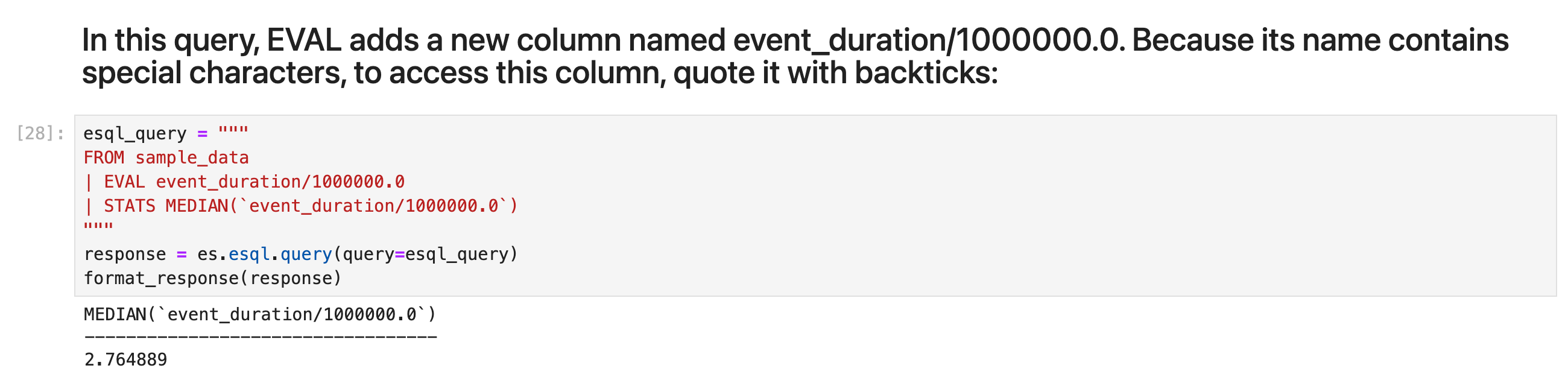
在此查询中,EVAL 添加一个名为 event_duration/1000000.0 的新列。 由于其名称包含特殊字符,因此要访问此列,请用反引号引用它:
esql_query = """
FROM sample_data
| EVAL event_duration/1000000.0
| STATS MEDIAN(`event_duration/1000000.0`)
"""
response = es.esql.query(query=esql_query)
format_response(response)
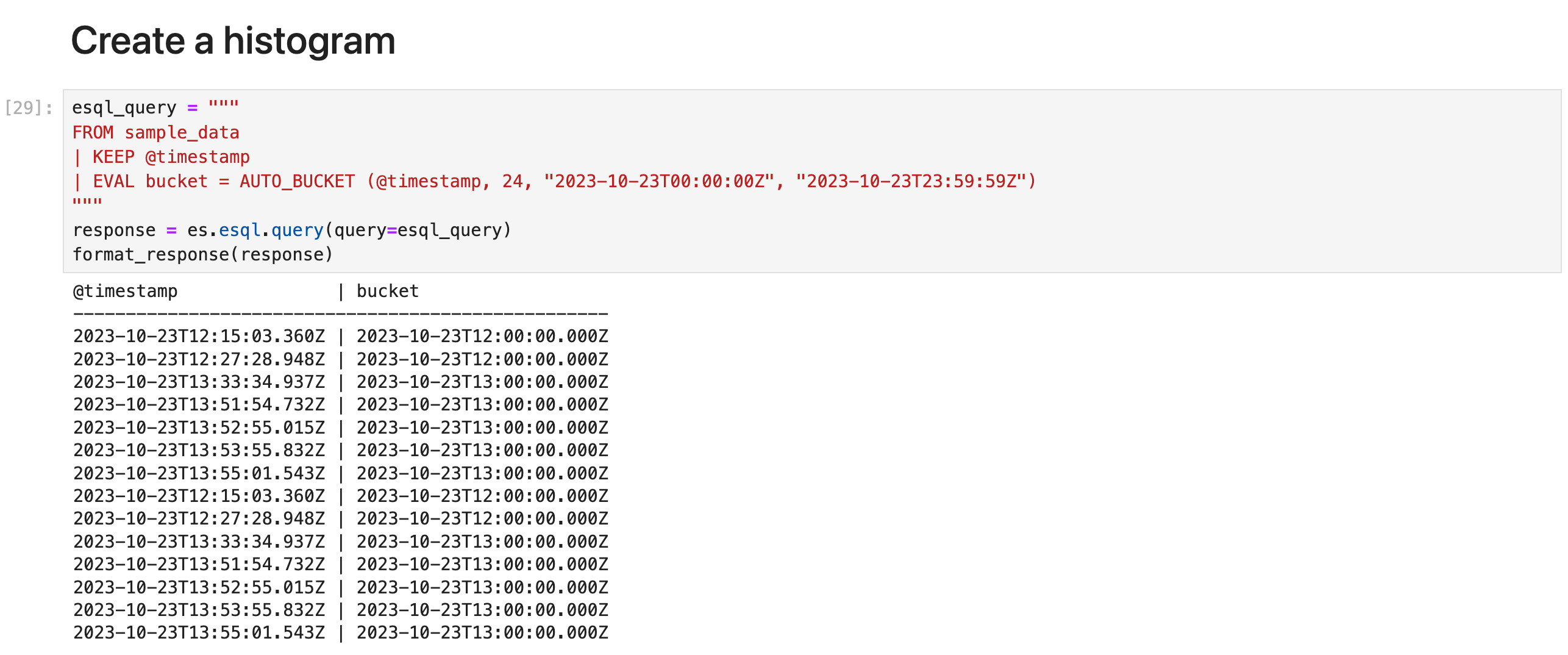
创建直方图
为了跟踪一段时间内的统计数据,ES|QL 允许你使用 AUTO_BUCKET 函数创建直方图。 AUTO_BUCKET 创建人性化的存储桶大小,并为每行返回一个与该行所属的结果存储桶相对应的值。
例如,要为 10 月 23 日的数据创建每小时存储桶:
esql_query = """
FROM sample_data
| KEEP @timestamp
| EVAL bucket = AUTO_BUCKET (@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
"""
response = es.esql.query(query=esql_query)
format_response(response)
将 AUTO_BUCKET 与 STATS … BY 结合起来创建直方图。 例如,要计算每小时的事件数:
esql_query = """
FROM sample_data
| KEEP @timestamp, event_duration
| EVAL bucket = AUTO_BUCKET (@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
| STATS COUNT(*) BY bucket
"""
response = es.esql.query(query=esql_query)
format_response(response)

或每小时的中位持续时间:
esql_query = """
FROM sample_data
| KEEP @timestamp, event_duration
| EVAL bucket = AUTO_BUCKET (@timestamp, 24, "2023-10-23T00:00:00Z", "2023-10-23T23:59:59Z")
| STATS median_duration = MEDIAN(event_duration) BY bucket
"""
response = es.esql.query(query=esql_query)
format_response(response)

丰富数据
ES|QL 使你能够使用 ENRICH 命令使用 Elasticsearch 中索引的数据来丰富表。
ℹ️ 在使用 ENRICH 之前,你首先需要创建并执行丰富策略。 我们在 ela.st/ql 提供了一个演示环境,其中已经创建并执行了名为 clientip_policy 的丰富策略,如果你只是想看看它是如何工作的。
以下请求创建并执行名为 clientip_policy 的策略。 该策略将 IP 地址链接到环境(“Development”、“QA” 或 “Production”)。
# Define the mapping
mapping = {
"mappings": {
"properties": {"client_ip": {"type": "keyword"}, "env": {"type": "keyword"}}
}
}
# Create the index with the mapping
es.indices.create(index="clientips", body=mapping)
# Prepare bulk data
bulk_data = [
{"index": {}},
{"client_ip": "172.21.0.5", "env": "Development"},
{"index": {}},
{"client_ip": "172.21.2.113", "env": "QA"},
{"index": {}},
{"client_ip": "172.21.2.162", "env": "QA"},
{"index": {}},
{"client_ip": "172.21.3.15", "env": "Production"},
{"index": {}},
{"client_ip": "172.21.3.16", "env": "Production"},
]
# Bulk index the data
es.bulk(index="clientips", body=bulk_data)
# Define the enrich policy
policy = {
"match": {
"indices": "clientips",
"match_field": "client_ip",
"enrich_fields": ["env"],
}
}
# Put the enrich policy
es.enrich.put_policy(name="clientip_policy", body=policy)
# Execute the enrich policy without waiting for completion
es.enrich.execute_policy(name="clientip_policy", wait_for_completion=True)

创建并执行策略后,你可以将其与 ENRICH 命令一起使用:
esql_query = """
FROM sample_data
| KEEP @timestamp, client_ip, event_duration
| EVAL client_ip = TO_STRING(client_ip)
| ENRICH clientip_policy ON client_ip WITH env
"""
response = es.esql.query(query=esql_query)
format_response(response)
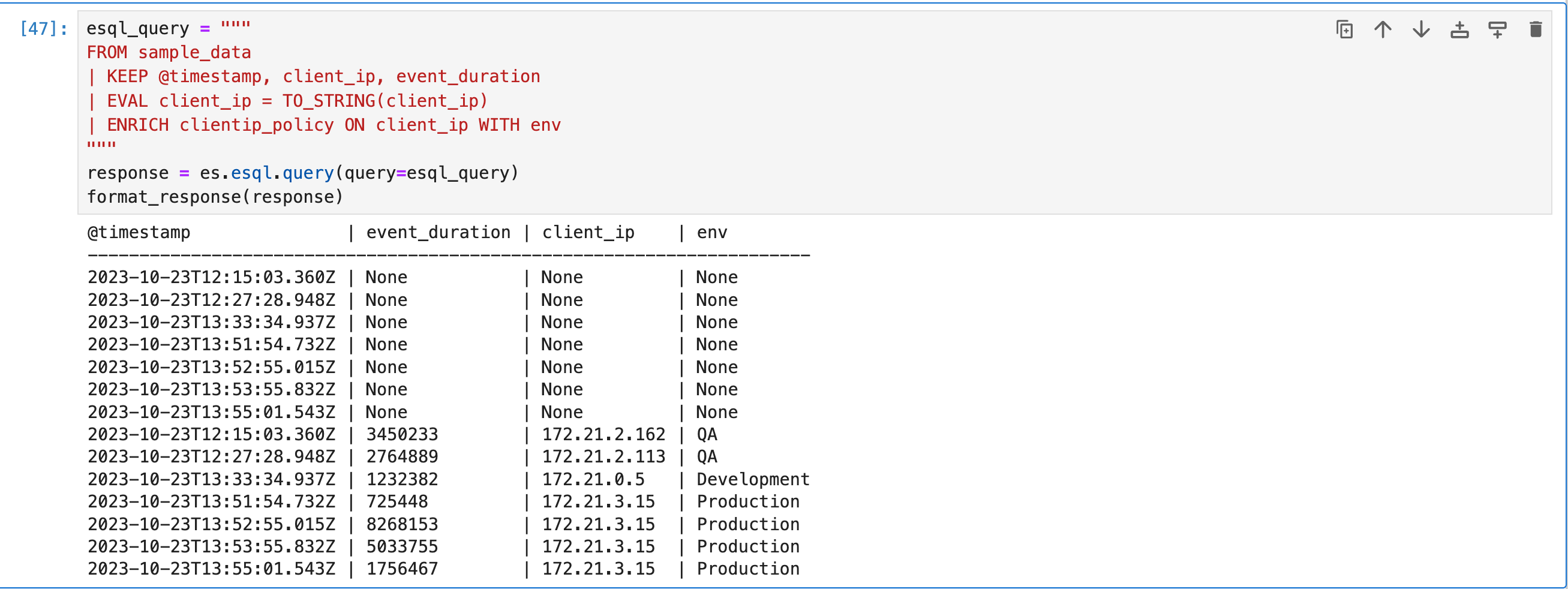
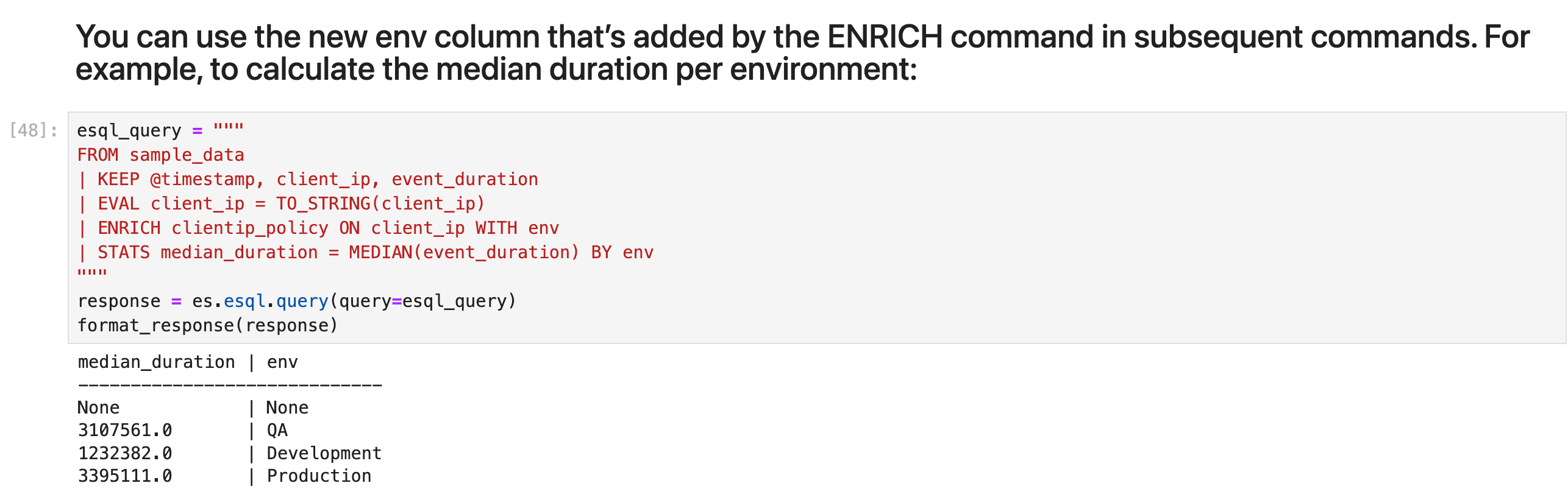
你可以在后续命令中使用 ENRICH 命令添加的新 env 列。 例如,要计算每个环境的中位持续时间:
esql_query = """
FROM sample_data
| KEEP @timestamp, client_ip, event_duration
| EVAL client_ip = TO_STRING(client_ip)
| ENRICH clientip_policy ON client_ip WITH env
| STATS median_duration = MEDIAN(event_duration) BY env
"""
response = es.esql.query(query=esql_query)
format_response(response)
有关使用 ES|QL 进行数据丰富的更多信息,请参阅数据丰富。
处理数据
你的数据可能包含非结构化字符串,你希望对其进行结构化以便更轻松地分析数据。 例如,示例数据包含如下日志消息:
Connected to 10.1.0.3
通过从这些消息中提取 IP 地址,你可以确定哪个 IP 接受了最多的客户端连接。
要在查询时构建非结构化字符串,你可以使用 ES|QL DISSECT 和 GROK 命令。 DISSECT 的工作原理是使用基于分隔符的模式分解字符串。 GROK 的工作原理类似,但使用正则表达式。 这使得 GROK 更强大,但通常也更慢。
在这种情况下,不需要正则表达式,因为 message 很简单:“Connected to ”,后跟服务器 IP。 要匹配此字符串,你可以使用以下 DISSECT 命令:
esql_query = """
FROM sample_data
| DISSECT message "Connected to %{server_ip}"
"""
response = es.esql.query(query=esql_query)
format_response(response)
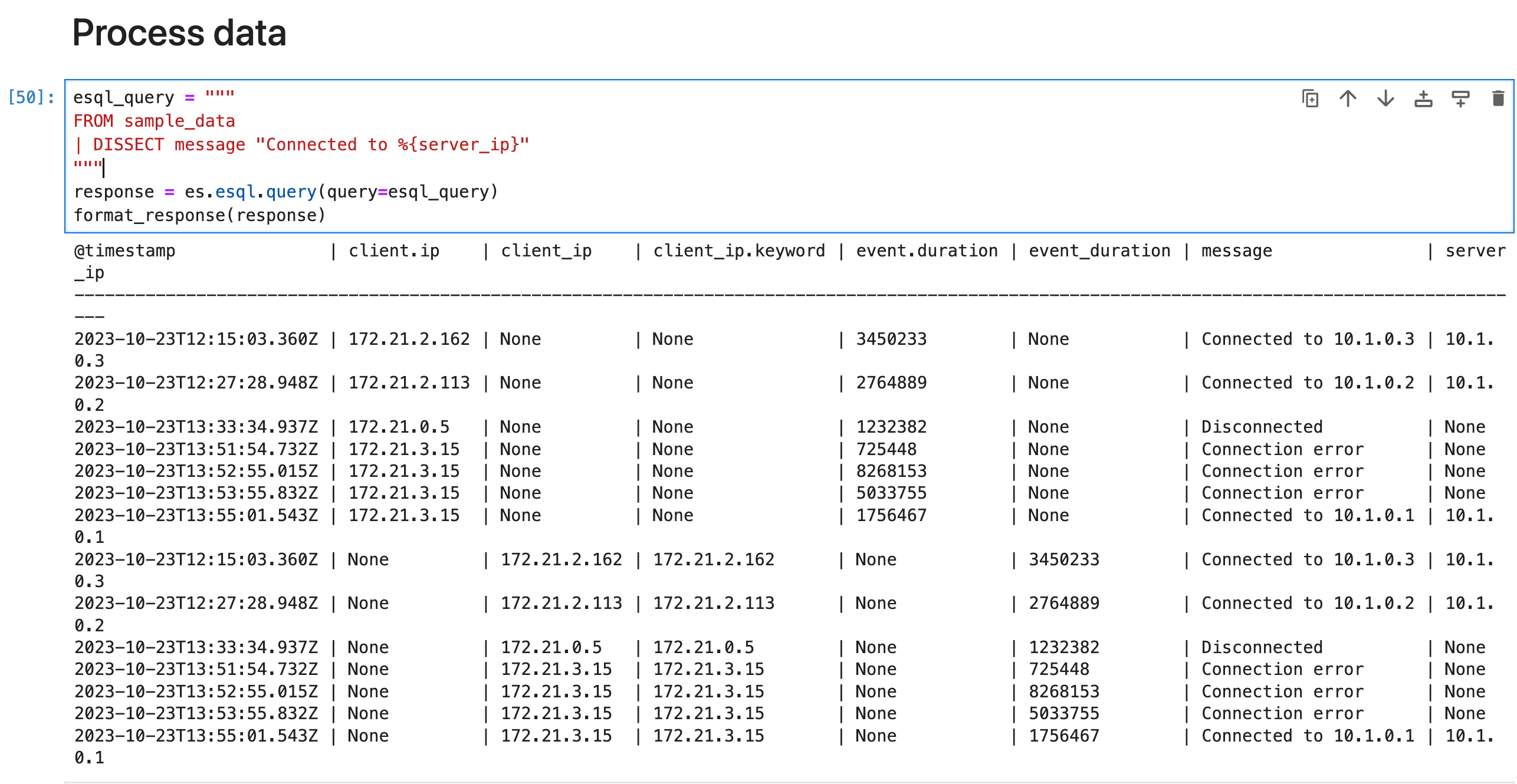
这会将 server_ip 列添加到具有与此模式匹配的 message 的那些行。 对于其他行,server_ip 的值为空。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









