







 本文讲述了剧本杀游戏的流行及其背后的商业分析,介绍了如何通过Python进行数据采集,包括应对反爬策略。同时,强调了Python在数据分析、机器学习等领域的广泛应用,以及提供了一套Python学习资源和求职面试准备指南。
本文讲述了剧本杀游戏的流行及其背后的商业分析,介绍了如何通过Python进行数据采集,包括应对反爬策略。同时,强调了Python在数据分析、机器学习等领域的广泛应用,以及提供了一套Python学习资源和求职面试准备指南。
伴随着《明星大侦探》等推理综艺走红,剧本杀游戏也成功出圈,成为年轻消费者偏好的休闲娱乐活动之一。同时随着体验经济的发展,人们对剧本杀这种新消费业态接受度比较高,从而推动其在国内的快速发展。
数据采集:
这节主要是讲解如何爬取数据。
由于大众点评反爬非常非常非常非常非常严格,因此使用了cookie池、ip代理等诸多防ban手段。
某点评反爬策略是字体反爬,需要解析评论、销量等字体才能拿到数据,我们通过在页面信息中解析出字体css文件,对加密字体进行映射从而拿到数据。
数据展示:
数据分析:
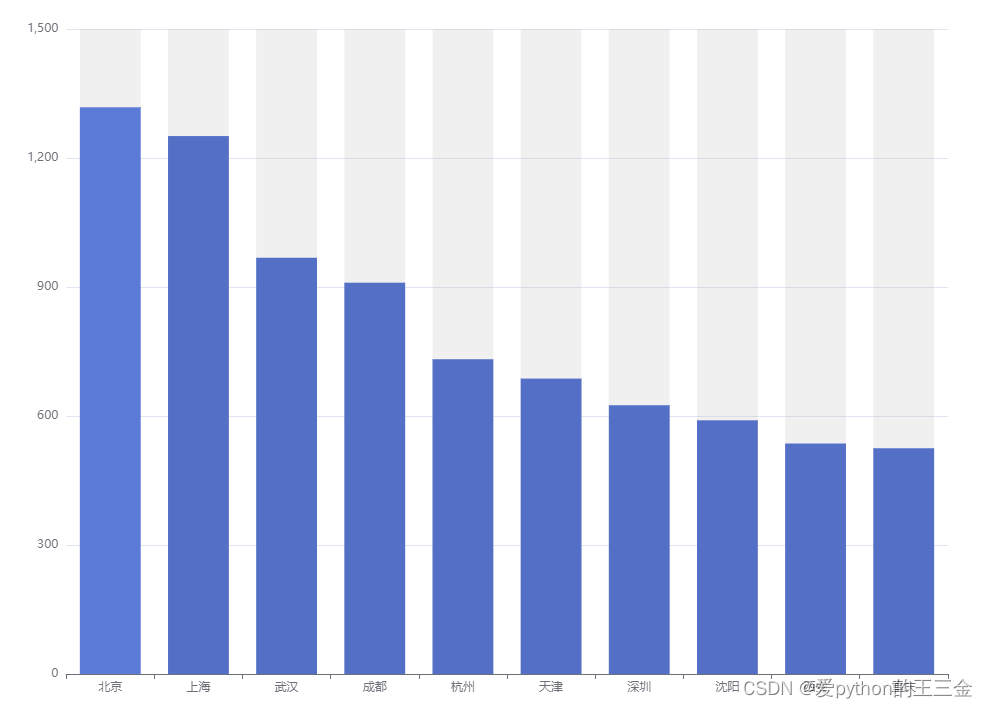
采集了全国不同地区剧本杀商家,进行地图分布统计。

可以看到排名前十的商家是北京、上海、武汉、成都、杭州、天津、深圳、沈阳、西安、重庆;
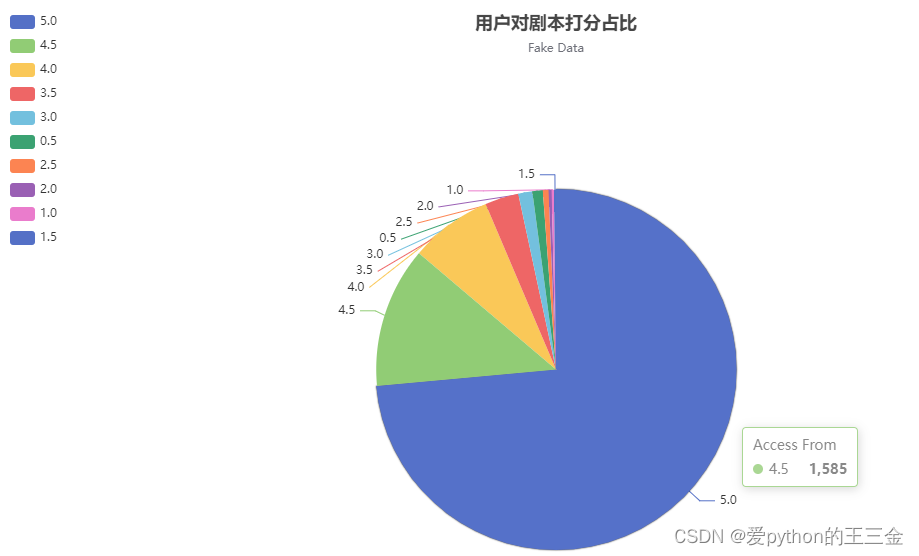
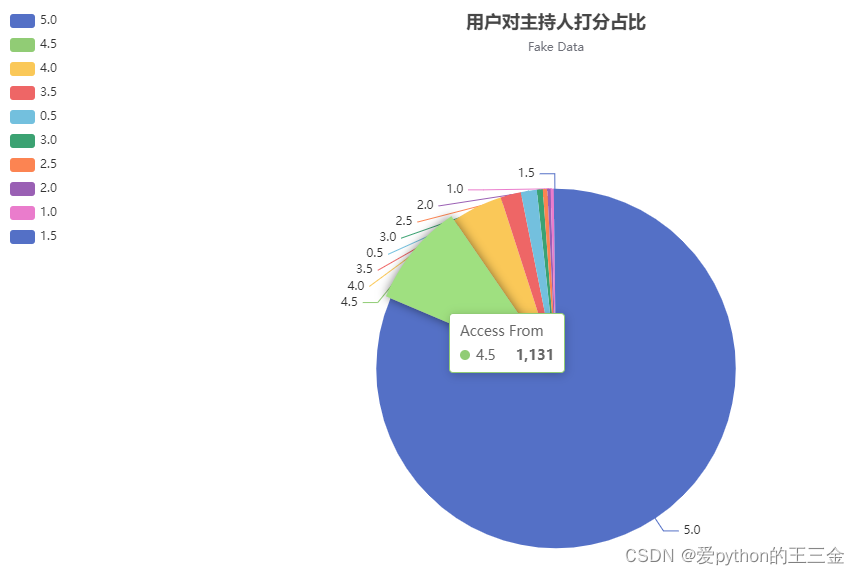
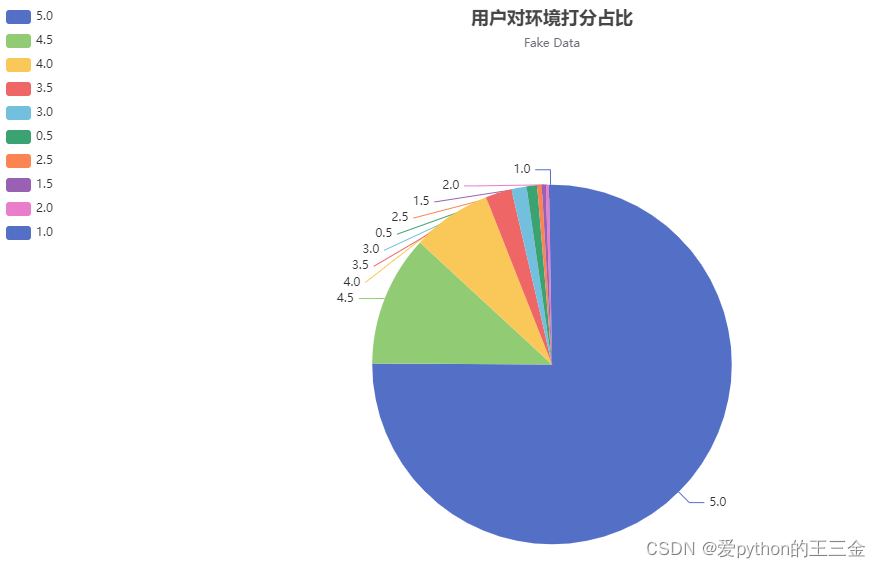
分别拿用户对剧本、对主持人、对环境的打分做了占比分析;
对广州剧本杀评价进行了词云统计,可以看到DM是剧本杀灵魂,带玩家穿越体验不同人生,用户对环境氛围、服务等方面比较注重;

这次的分享到这里就结束了,感谢观看,下期再见!
联系作者
最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









