







 本文介绍了Python中实现的几种聚类算法,包括Spectral Clustering和Hierarchical Clustering,详细讲解了算法原理、步骤及代码实现。通过实例展示了如何使用sklearn库进行数据生成、模型训练和结果可视化。最后讨论了DBSCAN算法,强调其在处理任意形状聚类和噪声点处理方面的优势和局限性。
本文介绍了Python中实现的几种聚类算法,包括Spectral Clustering和Hierarchical Clustering,详细讲解了算法原理、步骤及代码实现。通过实例展示了如何使用sklearn库进行数据生成、模型训练和结果可视化。最后讨论了DBSCAN算法,强调其在处理任意形状聚类和噪声点处理方面的优势和局限性。
gamma :affinity指定的核函数的内核系数,默认1.0
c)主要属性
labels_ :每个数据的分类标签
d)算法示例:代码中有详细讲解内容


from sklearn.datasets.samples_generator import make_blobs
from sklearn.cluster import spectral_clustering
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from itertools import cycle ##python自带的迭代器模块
##产生随机数据的中心
centers = [[1, 1], [-1, -1], [1, -1]]
##产生的数据个数
n_samples=3000
##生产数据
X, lables_true = make_blobs(n_samples=n_samples, centers= centers, cluster_std=0.6,
random_state =0)
##变换成矩阵,输入必须是对称矩阵
metrics_metrix = (-1 * metrics.pairwise.pairwise_distances(X)).astype(np.int32)
metrics_metrix += -1 * metrics_metrix.min()
##设置谱聚类函数
n_clusters_= 4
lables = spectral_clustering(metrics_metrix,n_clusters=n_clusters_)
##绘图
plt.figure(1)
plt.clf()
colors = cycle(‘bgrcmykbgrcmykbgrcmykbgrcmyk’)
for k, col in zip(range(n_clusters_), colors):
##根据lables中的值是否等于k,重新组成一个True、False的数组
my_members = lables == k
##X[my_members, 0] 取出my_members对应位置为True的值的横坐标
plt.plot(X[my_members, 0], X[my_members, 1], col + ‘.’)
plt.title(‘Estimated number of clusters: %d’ % n_clusters_)
plt.show()

e)效果图
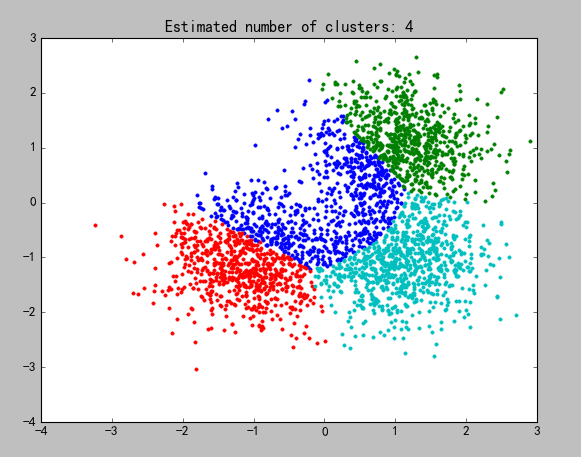
图5
5.Hierarchical Clustering
1)概述
Hierarchical Clustering(层次聚类):就是按照某种方法进行层次分类,直到满足某种条件为止。
主要分成两类:
a)凝聚:从下到上。首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有的对象都在一个簇中,或者某个终结条件被满足。
b)分裂:从上到下。首先将所有对象置于同一个簇中,然后逐渐细分为越来越小的簇,直到每
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









