







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
基本面的量化分析与投资的回报 - 上篇
基本面分析
百度上给出的定义:基本分析法是从影响证券价格变动的敏感因素出发,分析研究证券市场的价格变动的一般规律,为投资者作出正确决策提供科学依据的分析方法。主要有三个层次:一是宏观社会经济类影响因素; 二是行业(或产业)类影响因素; 三是公司类影响因素。三类影响证券价格的因素构成证券投资基本分析的三个部分,即宏观经济分析、行业分析和微观企业 (公司) 分析。我的以下分析主要集中在企业的数据上。
公司的基本面分析和打分
我的打分系统主要涉及到10个方面:营收,营利增长率,毛利率,期间费用,库存周转率,经营性现金流,净资产收益率,总资产收益率,市净率,市盈率。满分为一百分,分数越高,代表着公司的整体基本面越优秀(前提假设是公司没有做假账)。整套打分系统的源代码是由我的量化导师Cutehand所制作,我只是后期加工而已,如有需要请关注联系我的导师。所有的数据都是从Tushare上获取的,请自行去其官网进行注册,按照自己的需求来进行购买充值。
代码及分析 - 基础数据
首先说一下本代码是.ipynb格式,也就是我们说的Jupyter Notebook格式。另外我的代码分析不构成任何的投资推荐,请斟酌!
import pandas as pd
import numpy as np
import tushare as ts
# import talib
# import moduleigh as ml
import time
from datetime import datetime as dt
from pyfinance import TSeries
token = '你的tushare密钥'
ts.set_token(token)
pro = ts.pro_api(token)
- 首先我们来读取我过去根据我导师的加工后的代码所获取的每个季度,A股上市公司的经营情况的打分。
df_20214 = pd.DataFrame(pd.read_csv("D:\\BaiduNetdiskWorkspace\\股票候选\\季度3连涨候选人\_2021年第肆季.csv", encoding='GBK', index_col=0))
df_20221 = pd.DataFrame(pd.read_csv("D:\\BaiduNetdiskWorkspace\\股票候选\\季度3连涨候选人\_2022年第壹季.csv", encoding='GBK', index_col=0))
df_20222 = pd.DataFrame(pd.read_csv("D:\\BaiduNetdiskWorkspace\\股票候选\\季度3连涨候选人\_2022年第贰季.csv", encoding='GBK', index_col=0))
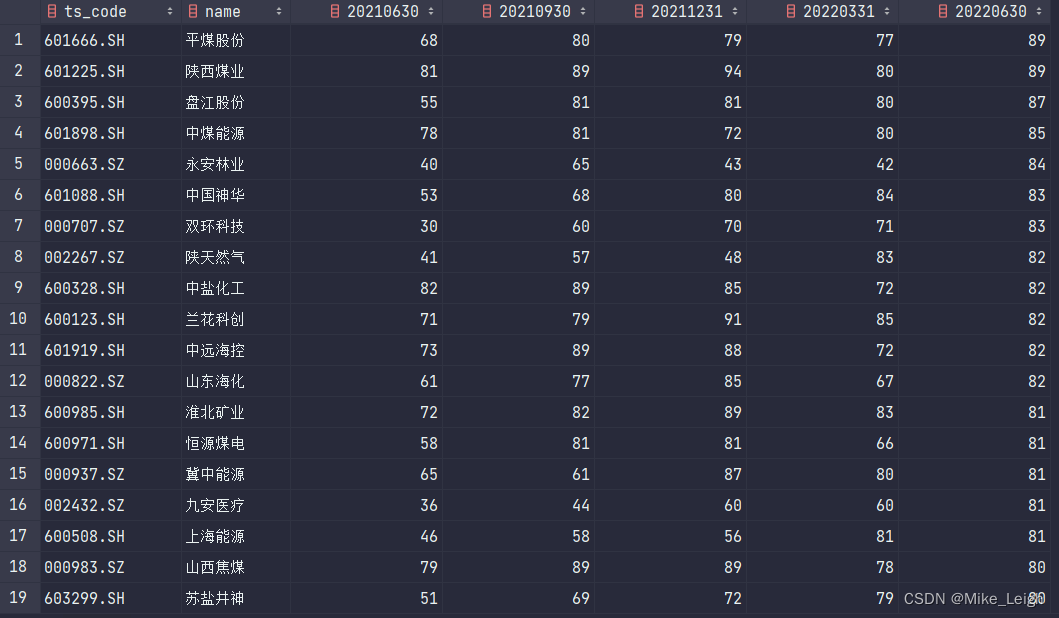
2. 其次我们看看这三张表里面,每张表大概有多少只股票。len(df_20214),len(df_20221),len(df_20222)输出分别为179,509,594。
3. 当我们把分值缩小至66分以上,它们的输出缩小为55,105,132。
df_20214_66 = df_20214[df_20214[df_20214.columns[-1]] > 66]
df_20221_66 = df_20221[df_20221[df_20221.columns[-1]] > 66]
df_20222_66 = df_20222[df_20222[df_20222.columns[-1]] > 66]
- 我们来看看在过去的半年里表现一直很亮眼的候选人的名单:
set_stocklist = set(list_20214) & set(list_20221) & set(list_20222) # 看看哪些股票同时在这3张表内
df_result_list = pd.DataFrame({'ts\_code':list(set_stocklist)}) # 创建一个列名为ts\_code的dataframe
df_result = pd.merge(df_result_list, df_20222, on='ts\_code') # 与最后一期表合并筛选出这几支股票都是哪些
df_result = df_result.sort_values(by=df_result.columns[-1], ascending=False).reset_index(drop=True) # 排序整理一下
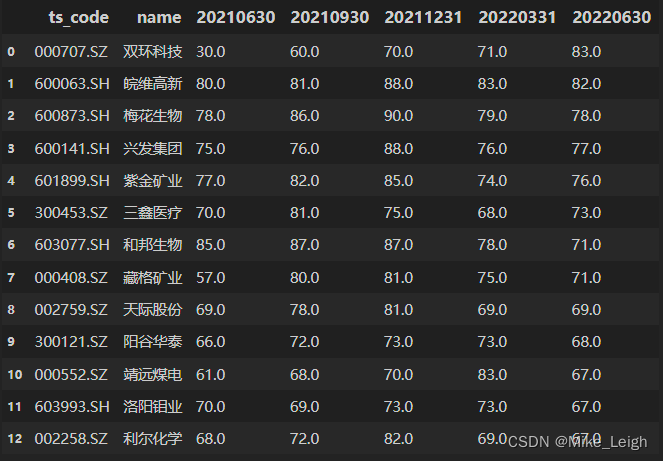
5. 截至到这里我们发现,在2021年~2022年中的表现来看,我们的候选人从我的3张表中筛选出来的概率只有10%
代码及分析 - 股票行情
- 以下的展示代码可以通过导师的这个帖子来学习获得,请自行阅读获取。
- 首先我们来封装一个从tushare上获取数据的并以时间排序的数据。
def get\_data(code,start='2021-01-01',end=''):
if code.startswith('399'): # 399开头的指数数据,用于区分股票数据
df=pro.index_daily(ts_code=code,start_date=start,end_date=end)
else:
df=ts.pro_bar(code,start_date=start,end_date=end,adj='qfq',freq='D')
df=df.sort_values('trade\_date', ascending=True) # 按照时间正序排列,因为tushare给我们的是倒序排列
df.index=pd.to_datetime(df.trade_date) # 以时间轴为index
ret=df.close/df.close.shift(1)-1 # 计算每日收益率
#返回TSeries序列
return TSeries(ret.dropna())
- 将重要的指标进行封装,有什么不明白的地方请参阅本贴。还有一个可能大家会遇到的问题就是计算标准差这里,很多指标会用到它,但是设计的时候又不让大家传
freq=的参数。建议大家pip install pyfinance库后,去pyfinance的文件夹找一个叫做returns.py的文件,把牵扯到anlzd_stdev()的公式,统统将参数freq=250进行固定年化设置。
def performance(code):
tss=get_data(code)
benchmark=get_data('399300.SZ').loc[tss.index]
dd={}
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

















 3091
3091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









