








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
引言
今年秋招之前,我曾以为我以后会是一名Java开发,但是在真正的秋招过程中,我出轨了大数据(呵呵,男人!),既然将它作为第一份职业,那就要好好来了解下它,要对现有的大数据的生态有个直观的理解,所以在此基础上列出自己的学习计划和自己的职业规划。在这里,要特别感谢韩顺平老师B站2020大数据公开课,受益匪浅,视频链接在参考文献中,感兴趣的小伙伴可以看看。
这篇文章是我在查阅了大量的资料后进行的总结,以自身小白的角度讲述,如有不正确的地方,还望读者不吝提出。
适合人群
- 想整体把握大数据生态的大数据从业的者
- 对大数据感兴趣的Java从业者
- 什么都不懂,但是想从事大数据开发的学生
Java开发者的自白
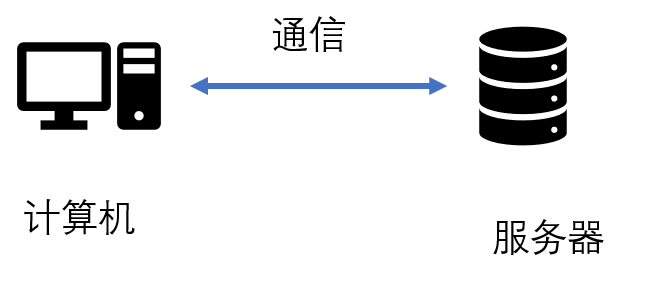
作为一名Java Developer,曾经我以为,BS架构就是我在浏览器中向服务器提交一个资源申请,然后服务器返回相应的资源就好了,那这个结构就好简单,就是下面这样的。
慢慢的,当服务器压力过大,我们就会考虑到扩容,设置主从服务等操作,这时的架构就变这样了
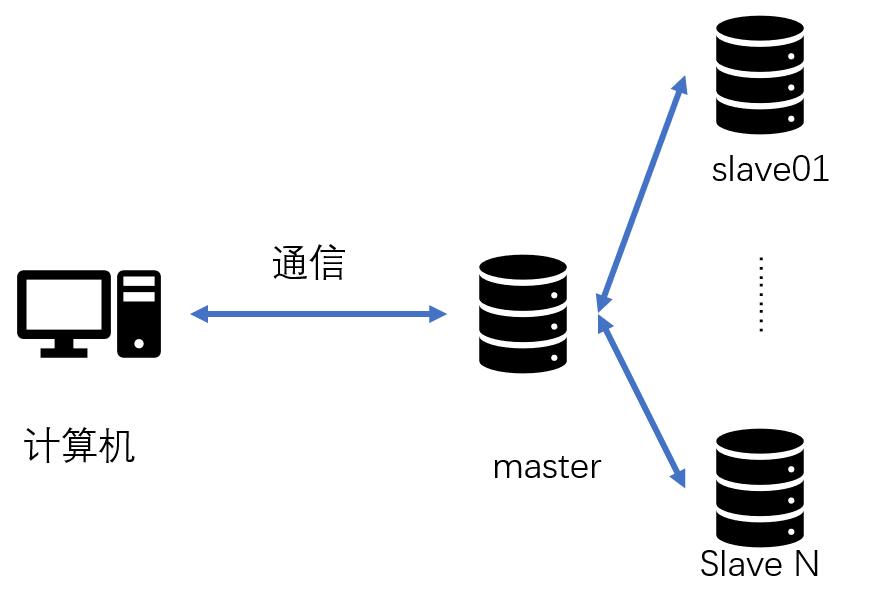
哎,我关心的层面永远是实现某个业务的逻辑,至于数据,我理解的也仅仅是业务数据,只要保证它们能够正常入库,正常获取即可,也就是我们常说的增删改查;当然,除正常的业务数据外,还会有很多的日志数据,可以利用他们定位错误。
如果仅从这个层面上看待,我也许永远不会理解马爸爸口中所说的数据就是财富,为了拥抱财富,我窥探了下业务数据之外的数据,然后,没忍住,我好像变心了~。
那么,什么是大数据呢?
什么是大数据?
随着科技的发展,我们在网上留下的数据越来越多,大到网上购物、商品交易,小到浏览网页、微信聊天、手机自动记录日常行程等,可以说,在如今的生活里,只要你还在,你就会每时每刻产生数据,但是这些数据能称为大数据么?不,这些还不能称为大数据,那么大数据数据到底是什么呢?
我的个人理解是这样的,大数据可以认为是数据的集合,我们可以从这些数据中推理出一个近似客观的规律,利用这个规律可以预测产生数据的本体下一次要发生的概率。如一个用户经常在某电影网站上观看成龙的电影,那么当该用户下一次访问电影网站时,将有关成龙的电影放在推荐列表中比较靠前的位置,因为我们通过用户的浏览的数据发现他很喜欢成龙的电影,并且相信相信该用户的兴趣短时内不会发生变化。这时我们就会有疑问,用户的行为数据存到哪里了?怎样使用这些数据判断(计算)产生数据数据的本体下一次发生的概率。这就引出了大数据的最核心的两个概念:存储和计算
大数据技术初探
我们接着上面分析,想知道这些数据可以具体做什么,那么我们就从数据本身出发。试想一下,要想使用数据,是不是要先采集数据,采集的数据传输过程中如果数据流量太大,还要考虑下对数据缓冲,如果采集的数据不是那么特别着急的需要(变现),我们可以考虑以离线的形式先存储起来,如果数据放起来就没有价值了啊,所以我们还是是要分析、计算、挖掘数据里面的价值,但是数据的最终价值是要变现啊,money! money! money! ,怎么变现?当然是提供给业务方喽,那么谁是业务代码的编写者,好像是曾经的我,Java Developer。
MMP,搞了半天,这是闭环啊,又回到了老本行,有点懵?别慌,来张图
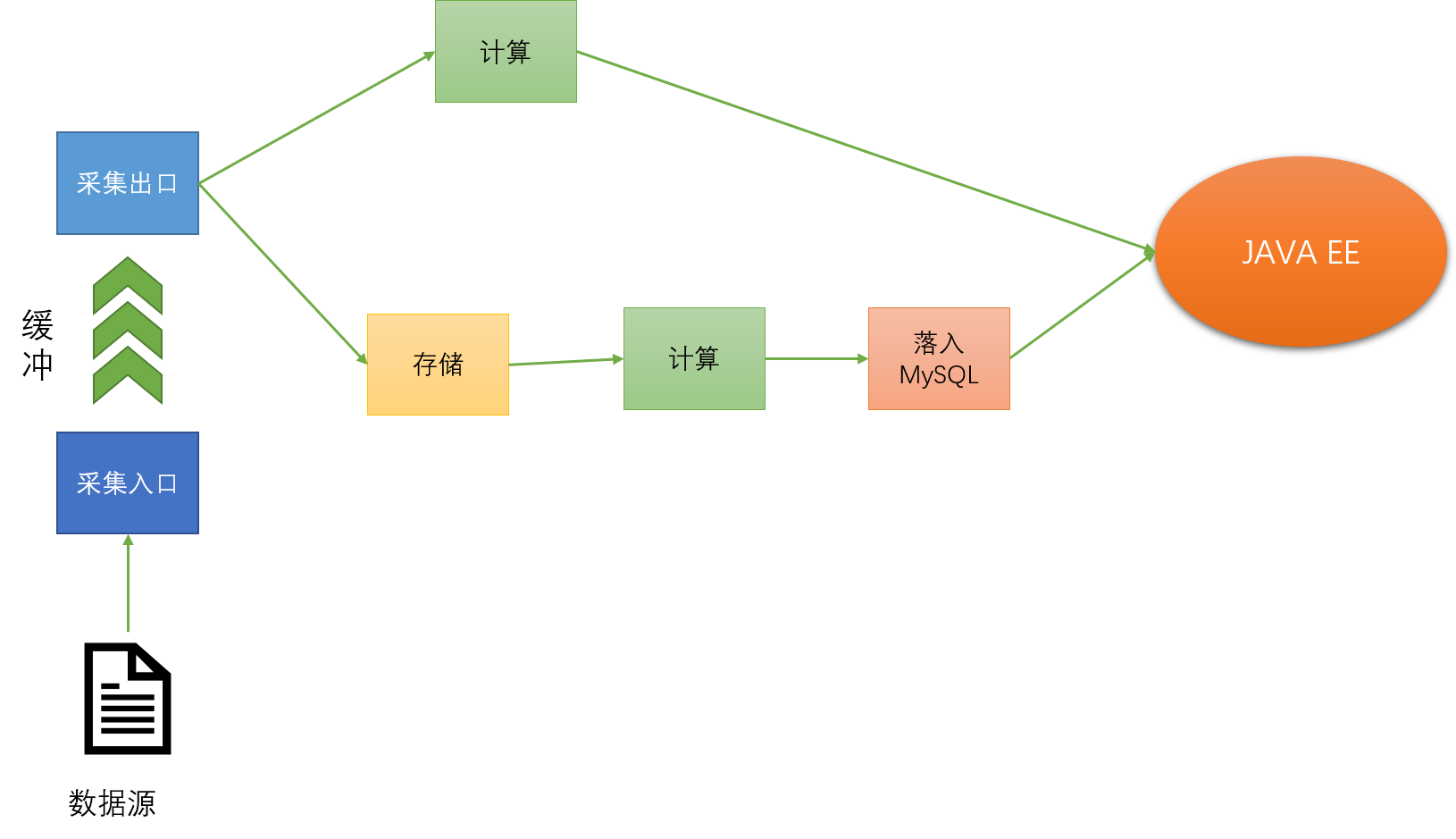
这张图简要分析了数据的实时/离线处理过程,乍一看这个流程,这有啥难的,不就是五个流程么,

- 数据源
数据源可以是多种多样的,按照结构划分可以分为三类:
- 非结构化数据:图片视频
- 半结构化数据:日志数据
- 结构化数据:关系数据
- 数据采集
数据采集常用的是Flume,但是考虑数据流量过大,我们通常使用Kafka做缓冲。
数据采集肯定是一端进数据,一端出数据,找了官方的一张图,结构如下:
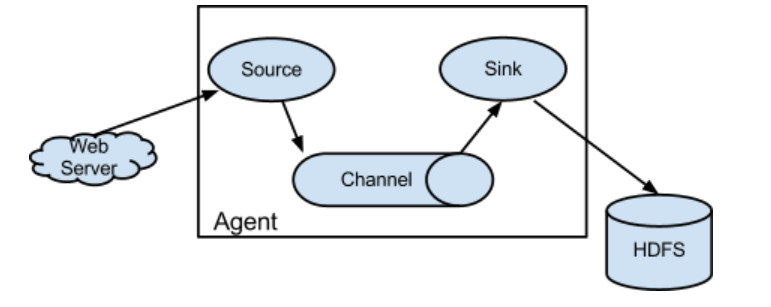
Source端是数据的入口,Sink端是数据的出口。中间的Channel是进行数据的清理的管道。
上面分析中我们提到过,当数据量过大的时候,我们通常会对数据进行缓冲,保证数据的进出适配。我们可以使用Kafka这个组件,Kafka是一个非常优秀的数据队列与缓冲组件。
- 数据存储
既然是大数据,那肯定不是一台服务器能够解决的,肯定是分布式存储HDFS,在大数据刚出来,就有人很多人认为大数据=hadoop,可见当时的hadoop的火热程度,实时上,这是因为hadoop同时具备了数据的存储与计算。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
- 数据计算
除了Hadoop自身的计算组件,有一款专门进行数据内存计算的组件–Spark,它可以同时提供离线计算和在线计算。
- 数据应用
数据的应用就比较广泛了,我们可以把处理好的数据放入MySQL,使用Java EE那套技术根据业务的需要具体操作即可;举一个简单的例子,我们可以把处理好的数据可视化(Echarts、D3),这也算是发挥它的价值。
上面仅仅是粗略的介绍,并没有详细的介绍每个步骤所对应的技术,要想学好大数据,自己必须要规划一个清晰的学习路线,坚持下去。下面,我们就聊一聊如何学习大数据,这个路线适合任何阶段的学习者。
大数据技术路线
大数据的技术路线还是非常庞大的,在这里,我要特别感谢尚硅谷韩顺平老师提供的技术路线,基本上包含了:入门–>进阶–>精通–>成神。
话不多说,先看下总体学习路线:
路线总体与分支
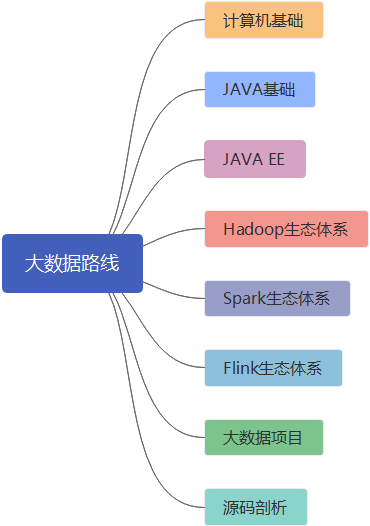
上面这张思维导图包含了我们学习大数据路线所需要的全部知识,可能除了计算机基础、JAVA基础,对其它技术体系可能有一点点感到迷茫,不要慌下面我们一一分析:
路线分支庖丁解牛
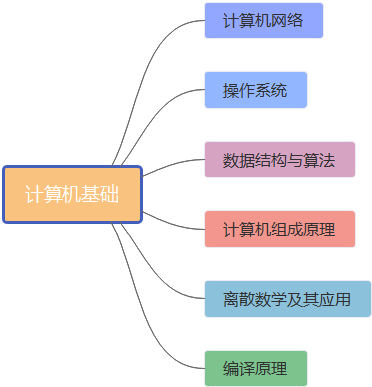
计算机基础
按照正常情况下,如果你想当个普通的程序员,这部分内容其实不学也行,因为技术的天花板很低,当达到一定水平后,就会原地踏步,停滞不前。但是如果你想在这个领域有所建树,发光发热,就得好好学习这些基础知识,这是为啥呢?你想想看,在这个文科可以使用Python来进行数据分析的时代,不搞点技能怎么傍身。当然,这是次要的,最主要的原因是当我们把某个领域学的一定阶段的时候,这时你接触的就会越接近于底层,举个例子:当你学习Java中的内存管理、线程、进程和锁的知识点时,如果你不了解操作系统的知识,理解起来还是挺难的。
下面,我们介绍下具体学习那些基础,这里只列出书籍,每个人根据自己的学习情况具体学习即可
- 计算机网络
- 操作系统
- 数据结构与算法
- 计算机组成原理
- 离散数学及其应用
- 编译原理
JAVA基础路线
学习大数据是必须要学JAVA的,为什么这么说呢?学习大数据,我们或多或少都听说过Hadoop,很多同学甚至将Hadoop和大数据画了等号,可见Hadoop是必须要学的,而且我们知道Hadoop和其他大数据处理技术很多的部分都是由Java语言来实现的,所以在学习Hadoop的一个前提条件,就是掌握Java语言。
那么,我们应该学习Java的那些内容呢,别单担心,贴心的Simon郎为你画了张思维导图。

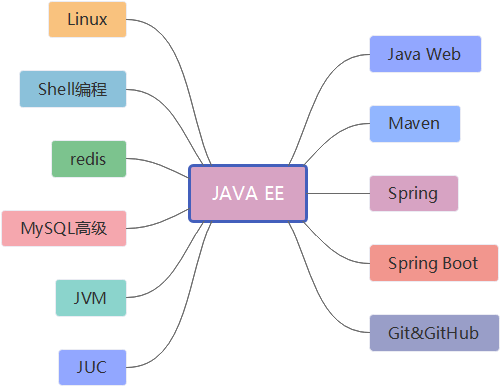
JAVA EE核心路线
作为一个大数据工程师,理论上讲,JAVA EE的技术不是必须的,为什么说呢,你想啊,JAVA EE开发是Java语言中的一个应用领域,比如开发WEB程序;大数据开发也是Java语言中的一个应用领域,比如开发海量数据处理程序。两者就好比是学习了中文,一个用于写段子,一个英语写诗,两者没太大关系啊,都要依赖语言(Java)。
但是问题来了,既然两者都是Java语言的应用,那么为什么大数据路线中还要学习JAVA EE呢,我的理由很简单,大数据处理的数据是供给具体的业务使用的,如果你一点都不懂,说的过去么?再说了,JAVA EE中有很多框架的思想都是挺值得借鉴的,所以,我觉得,学习大数据路线上适当的学习JAVA EE,会有着不错的效果,至于具体学习到什么程度,自己可以把握。
Hadoop生态体系学习路线
学习大数据肯定绕不开Hadoop,可见Hadoop的地位是多么重要,但是对于接触大数据时间较短或者尚未接触过大数据的同学来说,如果问他们我们应该学习Hadoop的那些内容,分布式存储和计算一定会说出来,但是仅仅这两个概念还是太笼统了,那么我们应该怎样把控Hadoop的学习呢,莫慌,且听Simon郎慢慢道来。
话不多说,先看一张Hadoop生态体系的脑图。
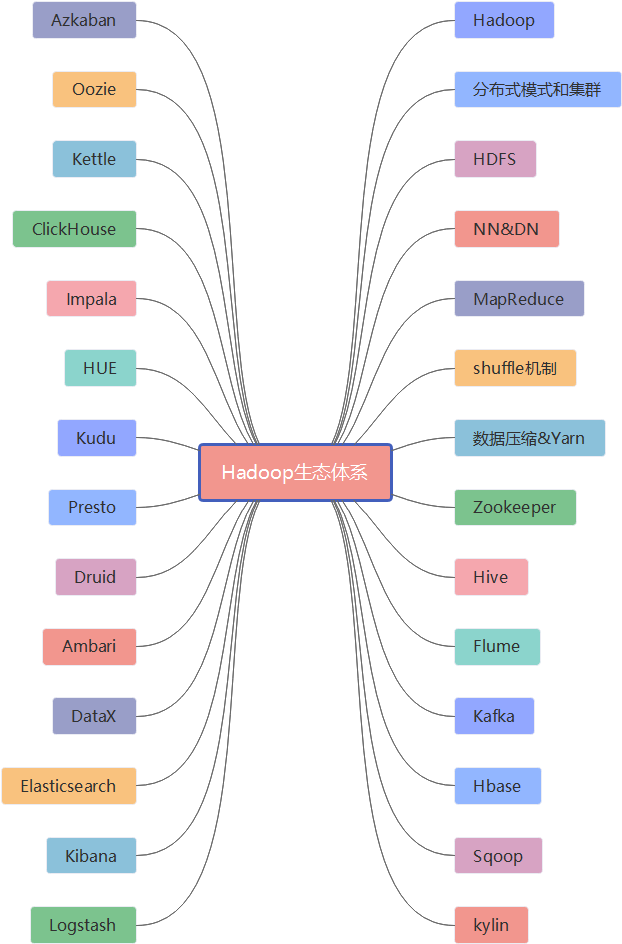
妈耶,咋那么多内容啊,快把我干懵逼了。千万别懵,虽然看起来很多,但是可以用一句总结:Hadoop是一个分布式计算开源框架,提供了一个分布式系统子项目(HDFS)和支持MapReduce分布式计算软件架构。既然脑图的内容有点多,咱们就介绍几个在Hadoop家组中占有地位较高的几个组件,如果小伙伴对其它组件感兴趣,可以自行查阅。
- Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- Hbase
Hbase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建起大规模结构化存储集群。
- Sqoop
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中
- Zookeeper
Zookeeper 是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务。
- Ambari
Ambari是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。
- Oozie
Oozie是一个工作流引擎服务器, 用于管理和协调运行在Hadoop平台上(HDFS、Pig和MapReduce)的任务。
- Hue
Hue是一个基于WEB的监控和管理系统,实现对HDFS,MapReduce/YARN, HBase, Hive, Pig的web化操作和管理。
…
Hadoop生态体系先介绍这么多,对其它内容感兴趣的同学自行补充
Spark生态体系学习路线
学习完Hadoop后,稍作调整后,就可以学习Spark了,这时,可能就有同学会问,Spark和Hadoop有啥区别呢?我们为什么还要学Spark呢?要学习Spark那些内容呢?
别慌,咱么一一解决
1. Spark和Hadoop有什么区别?
简单理解,Spark是在Hadoop基础上的改进,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
2.为什么要学Spark
基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错。出于任务管道承接的考虑,当一些查询翻译到MapReduce任务时,往往会产生多个Stage,而这些串联的Stage又依赖于底层文件系统(如HDFS)来存储每一个Stage的输出结果。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
要学习Spark的那些内容呢?
首先要学的就是Scala,因为Spark就是Scala写的,所以要好好学,这对于我们分析源码非常有帮助。这时你又有疑问,不是已经学了Java了么,怎么还学Scala,你个骗子!

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
…(img-jlkDJIPg-1715311734404)]
[外链图片转存中…(img-TWNPEZfq-1715311734404)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









