







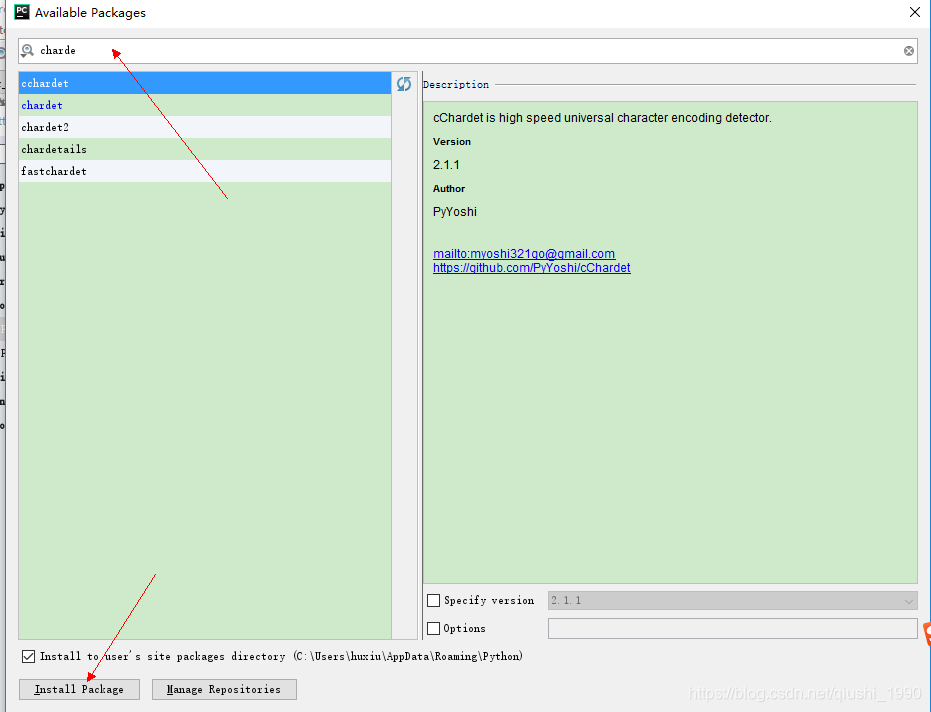
- 安装成功后就会出现在在安装列表中,到此就说明我们安装网络爬虫扩展库成功
我们这里以抓取简书首页为例:http://www.jianshu.com/
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
由于抓取的html文档比较长,这里简单贴出来一部分给大家看下
<!DOCTYPE html>
<!--[if IE 6]><html class="ie lt-ie8"><![endif]-->
<!--[if IE 7]><html class="ie lt-ie8"><![endif]-->
<!--[if IE 8]><html class="ie ie8"><![endif]-->
<!--[if IE 9]><html class="ie ie9"><![endif]-->
<!--[if !IE]><!--> <html> <!--<![endif]-->
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0,user-scalable=no">
<!-- Start of Baidu Transcode -->
<meta http-equiv="Cache-Control" content="no-siteapp" />
<meta http-equiv="Cache-Control" content="no-transform" />
<meta n 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









