







< …FOLDER> 路径自定义即可 , 可在后面加上portia的版本
docker run -i -t --rm -v <PROJECTS_FOLDER>:/app/data/projects:rw -p 9001:9001 scrapinghub/portia
git上是如下语句
docker run -v ~/portia_projects:/app/data/projects:rw -p 9001:9001 scrapinghub/portia
具体可参考[官方文档](https://bbs.csdn.net/topics/618317507)
##### 使用Portia包
###### 新建project
Portia安装完成以后使用浏览器打开`http://localhost:9001`, 在create a new project 中输入项目名
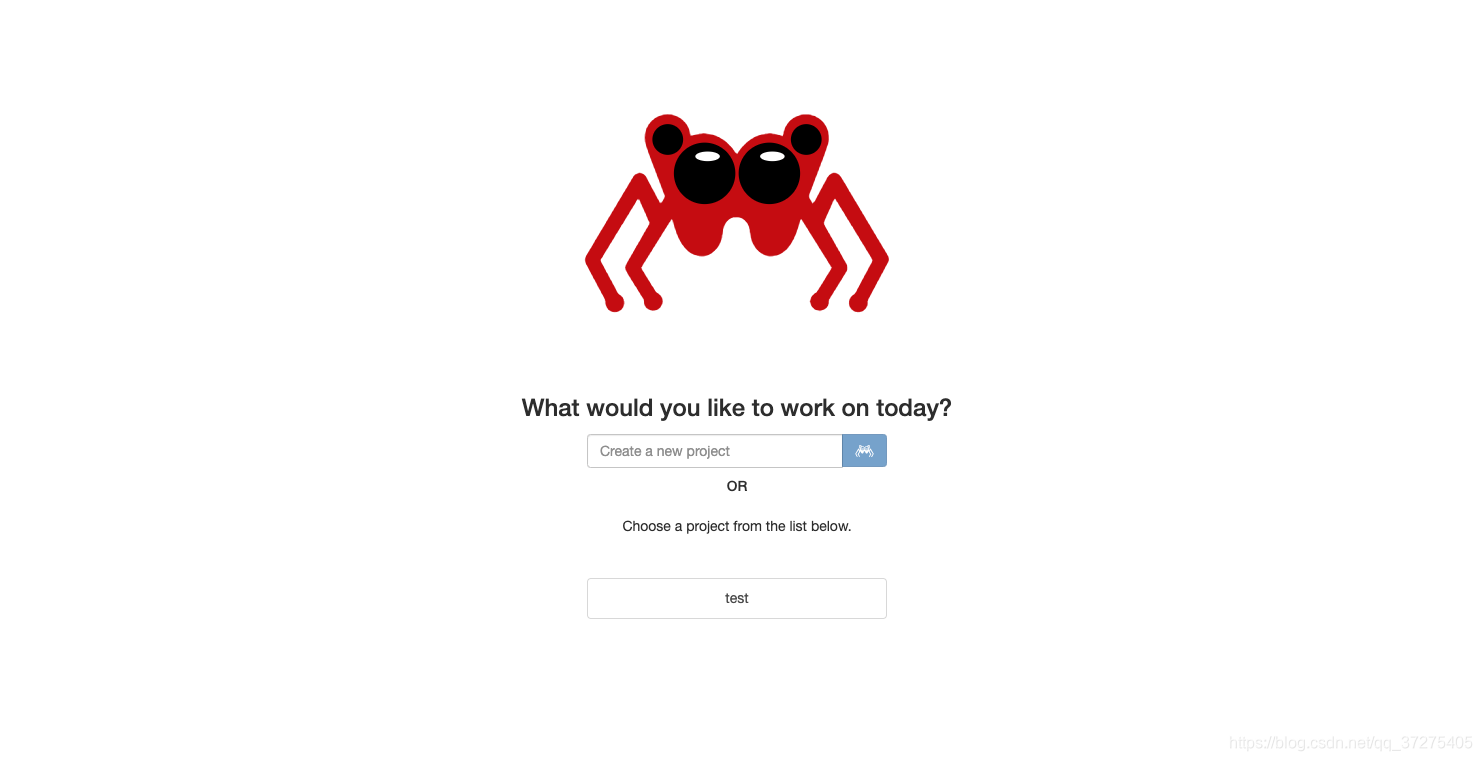
点击 New spider 创建一个新的spider
右边侧栏会提示你输入一个url,Portia会将网页的url作为一个start page。
这个start page一般被用来当做seek(种子),用来获得更多的链接。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









