






最后
针对最近很多人都在面试,我这边也整理了相当多的面试专题资料,也有其他大厂的面经。希望可以帮助到大家。

上述的面试题答案都整理成文档笔记。 也还整理了一些面试资料&最新2021收集的一些大厂的面试真题(都整理成文档,小部分截图)

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
人工智能是近几年非常火热的技术领域,而推动这个领域快速演进的原动力包括以英伟达 GPU 为代表的异构算力,以 TensorFlow,Pytorch 为代表的的机器学习框架,以及海量的数据集。除此之外我们也发现了一个趋势,就是以 Kubernetes 和 Docker 为代表的容器化基础架构也成为了数据科学家的首选,这主要有两个因素:分别是标准化和规模化。比如 TensorFlow,Pytorch 的软件发布过程中一定包含容器版本,这主要是仰仗容器的标准化特点。另一方面以 Kubernetes 为基础的集群调度技术使大规模的分布式训练成为了可能。
=======================================================================

首先我们观察下图,这是模拟数据下的深度学习模型训练速度,所谓模拟数据的意思就是这个测试中没有 IO 的影响。从这个图中我们可以得到两个发现:
-
GPU 硬件升级的加速效果显著。从单卡的算力看,pascal 架构为代表的 P100 一秒钟只能处理 300 张图片,而 volta 架构的 v100一秒钟可以处理 1200 张图片,提升了 4 倍。
-
分布式训练的也是有效加速的方式。从单卡 P100 到分布式 32 卡 v100,可以看到训练速度提升了 300 倍。
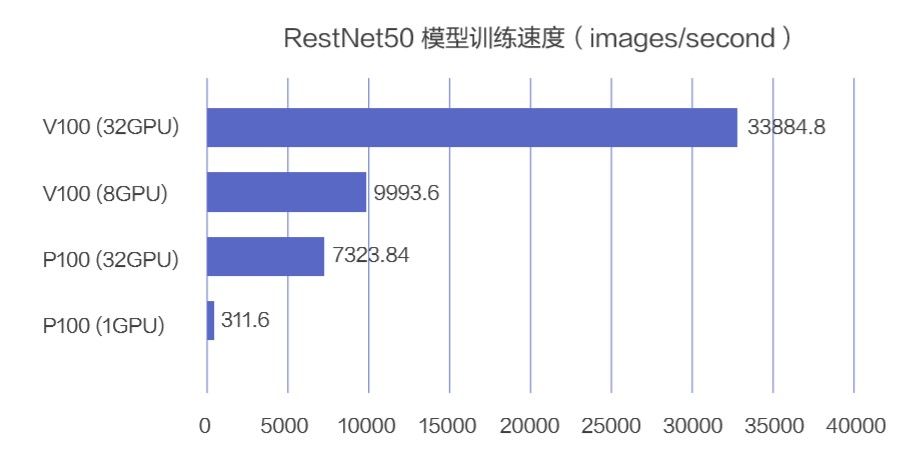
而从训练时间来看,同样的数据,同样的训练目标,单卡 P100 需要 108 个小时,4 天半的时间。而 V100 的 32 卡分布式训练只需要 1 小时。而从成本上来看,单卡 P100 的成本是接近 1400 元,而 8 卡 V 100 是 600 元,不到一半。
可以发现,更新的 GPU 硬件不但会更高效,实际上也会更省钱。这也许就是黄教主说的买的越多,省的越多。从云资源的角度来说还是有道理的。
但是之前的测试结果实际上是做了一些前提假设,就是没有数据延时的影响。而真实的情况下,模型训练是离不开海量数据的访问。而实际上:
-
强大的算力需要与之匹配的数据访问能力,不论是延时还是吞吐,都提出了更高的需求。下面的图可以看到,在云盘的数据读取的情况下,GPU 的训练速度直接降为了原来的三分之一。GPU 的使用率也很高。
-
在云环境下,计算和存储分离后,一旦没有了数据本地化,又明显恶化了 I/O 影响。
-
此时如果能够把数据直接加载到计算的节点上,比如ossutil把数据拷贝到 GPU 机器是不是可以满足计算的需求呢。实际上也还是不够的,因为一方面数据集无法全集控制,另一方面AI场景下是全量数据集,一旦引入驱逐机制,实际上性能影响也非常显著。因此我们意识到在 K8s 下使用分布式缓存的意义。
================================================================================
Alluxio 是一个面向 AI 以及大数据应用,开源的分布式内存级数据编排系统。在很多场景底下, Alluxio 非常适合作为一个分布式缓存来加速这些应用。这个项目是李浩源博士在加州大学 Berkeley 分校的 AMPLab 攻读博士的时候创立的,最早的名字 Tachyon。AMPLab 也是孵化出了 Spark 和 Mesos 等优秀开源项目的功勋实验室。2015 年,由顶级的风险投资 Andreessen Horowitz 投资,Alluxio 项目的主要贡献者在旧金山湾区成立了 Alluxio 这家公司。

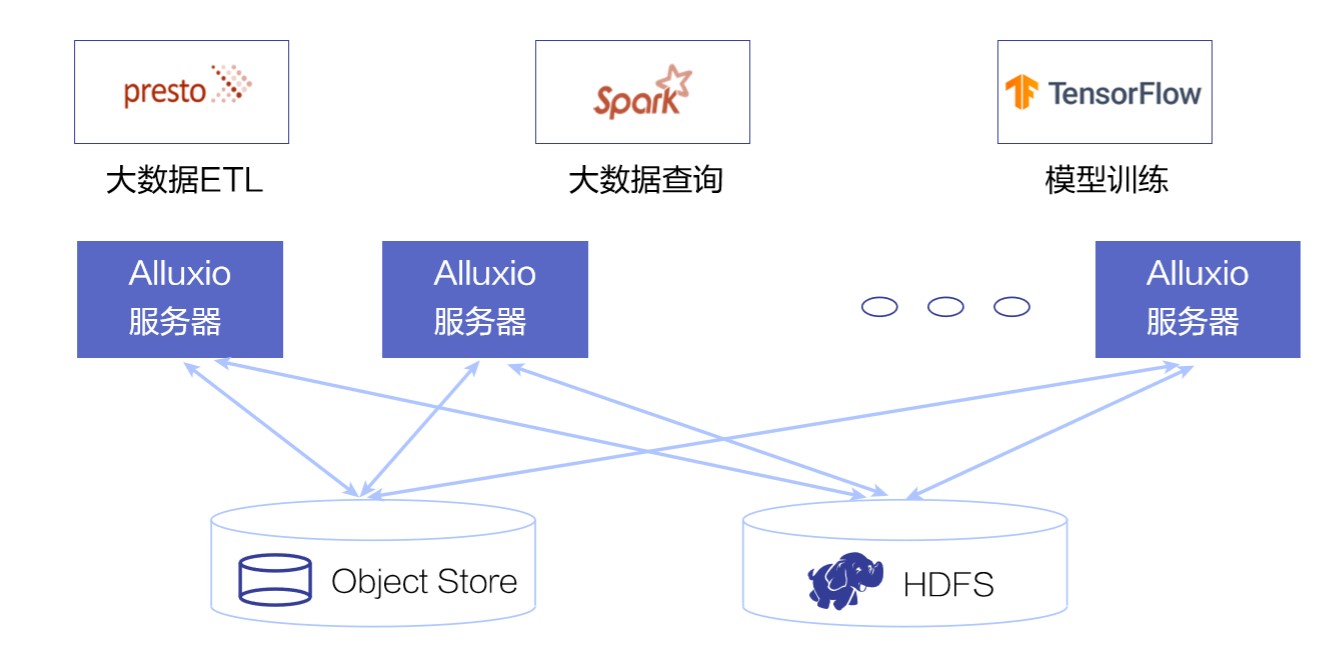
简单看一下在大数据和 AI 生态圈里, Alluxio 处于什么位置。在大数据软件栈里,Alluxio 是新的一层,我们称之为数据编排层。它向上对接计算应用,比如Spark, Presto,Hive,Tensorflow,向下对接不同的存储,比如阿里巴巴的 OSS,HDFS。我们希望通过这一层新加入的数据编排层,可以让计算和存储之间的强关联解耦。从而让计算和存储都可以独立而更敏捷的部署和演进。数据应用可以不必关心和维护数据存储的具体类型,协议,版本,地理位置等。而数据的存储也可以通过数据编排这一层更灵活更高效的被各种不同应用消费。

1)分布式数据缓存
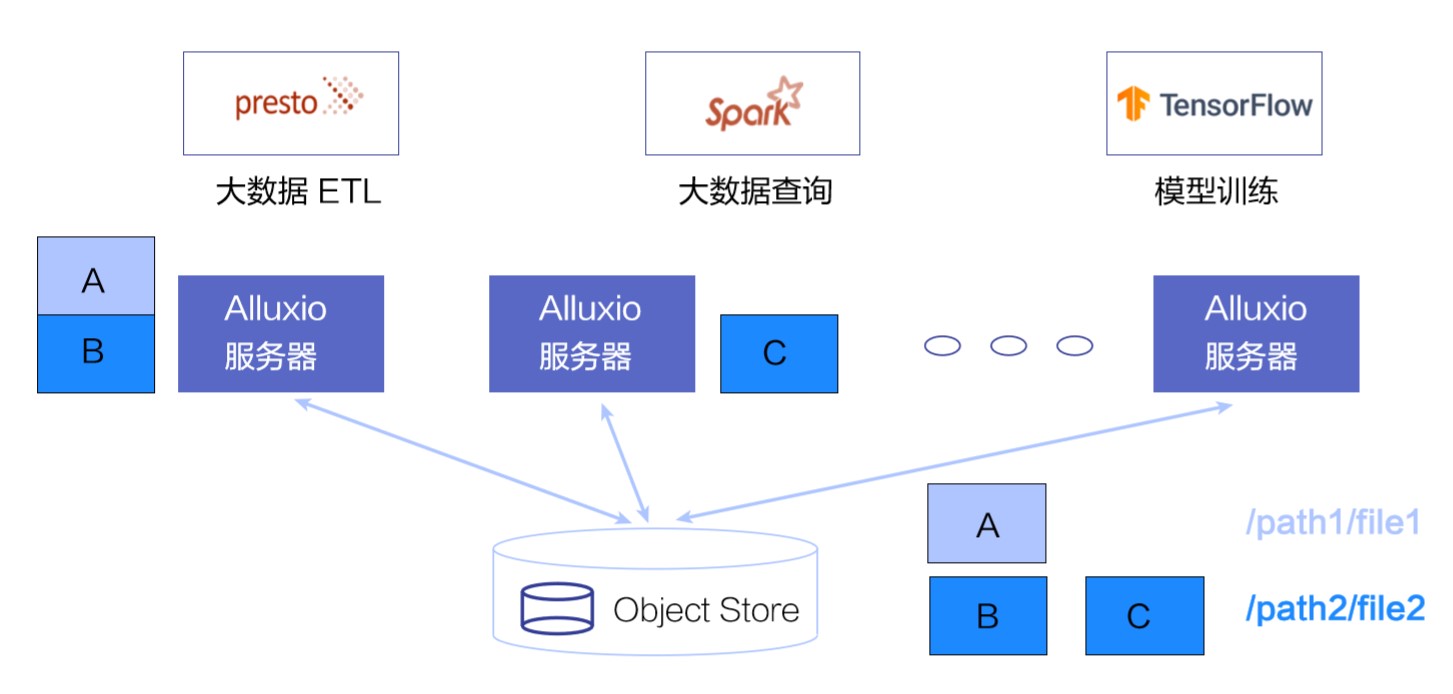
下面介绍一下 Alluxio 的核心功能。Alluxio 最核心的服务就是提供一个分布式的数据缓存用来加速数据应用。对于 Spark,Presto,Tensorflow 等数据密集型的应用,当读取非本地的数据源时,Alluxio 可以通过加载原始数据文件,将其分片以及打散,并存储在靠近应用的 Alluxio 服务器上, 增强这些应用的数据本地性。
比如在这个例子里, 文件 1 和文件 2 分别被分片后存储在不同的 Alluxio 服务器上,应用端可以就近从存储了对应的数据分片的服务器读取。当应用需要的读入有明显的热数据时, 添加缓存层可以显著的节省资源以及提升效率。
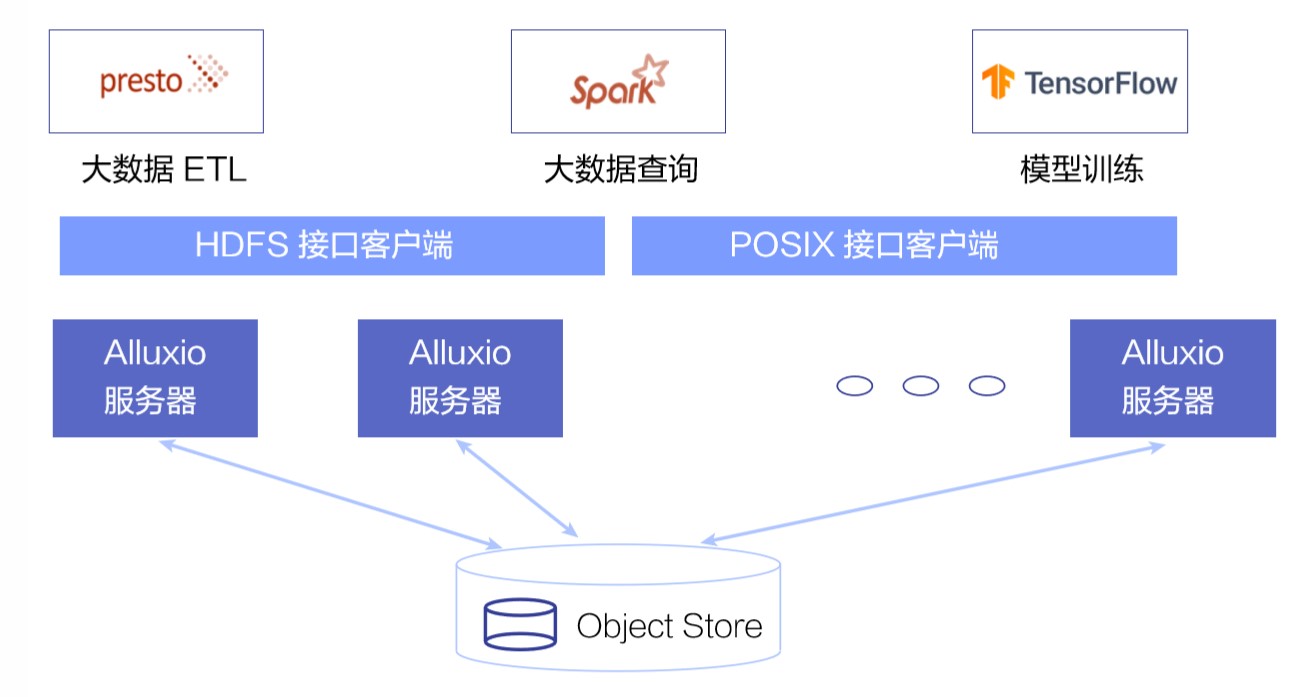
2)灵活多样的数据访问 API
Alluxio 的第二个核心应用,是对应用提供不同类型的数据接口,包括在大数据领域最常见的 HDFS 接口,以及在 ai 和模型训练场景下常用的 POSIX 标准文件系统接口。
这样同样的数据一旦准备完毕, 可以以不同的形式呈现给应用,而不用做多次处理或者 ETL。
3)统一文件系统抽象
Alluxio 的第三个核心功能,是把多个不同的存储系统,以对用户透明的方式,统一接入一个文件系统抽象中。这样使得复杂的数据平台变得简单而易于维护。数据消费者,只需要知道数据对应的逻辑地址,而不用去关心底层对接的时候什么存储系统。
举个例子, 如果一家公司同时有多个不同的 HDFS 部署,并且在线上接入了 Alibaba 的 OSS 服务, 那么我们完全可以使用 Alluxio 的挂载功能,把这些系统接入一个统一的逻辑上的 Alluxio 文件系统抽象中。每一个 HDFS 会对应到不同的 Alluxio 目录。
=============================================================================================
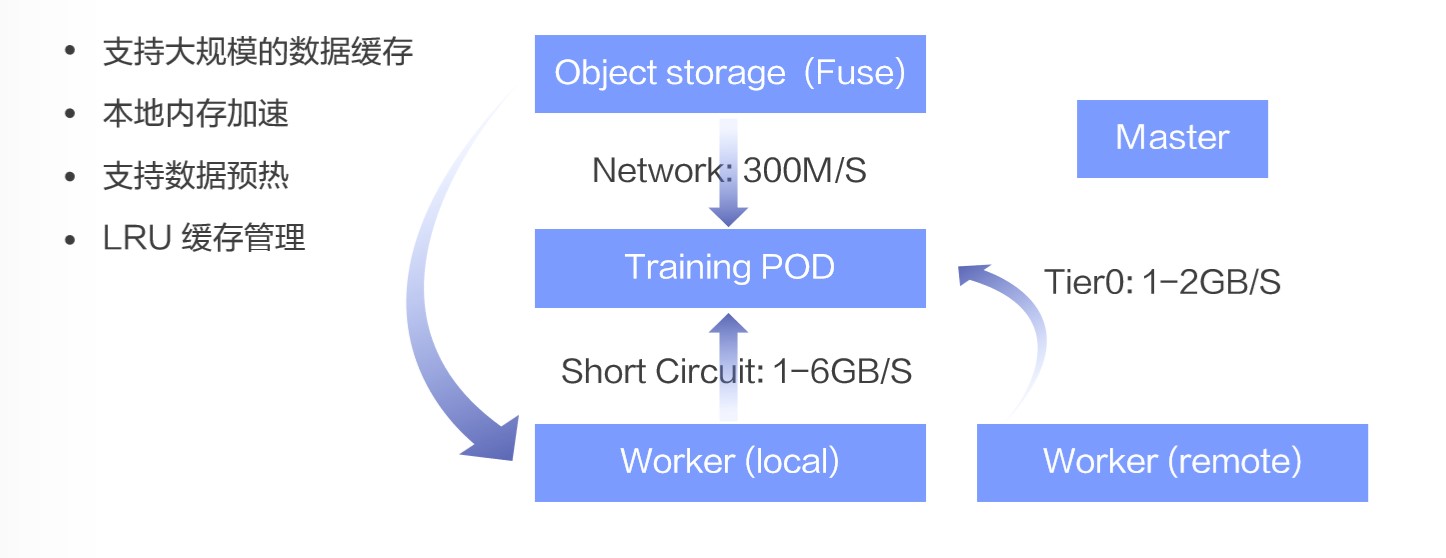
介绍完了 Alluxio 的核心功能,让我们聚焦在云端 AI 训练场景下,再来回顾一下 Alluxio 可能带来的好处。在模型训练场景下内存加速才能满足 GPU 需要的高吞吐。如果通过普通的网络从 Object store 传输数据, 大约能支撑 300MB/s, 这远远不能达到充分使用训练资源特别是 GPU 高吞吐的特性。但是一旦利用 Alluxio 构建了一层分布式的数据缓存,负责训练的容器进程和 alluxio worker 容器进程就可以以很高的速率交换数据。比如当两者在同一物理主机上的时候, 可以达到 1-6GB 每秒。从其他 alluxioworker 处读取也可以通常达到 1-2GB/s 。
此外,通过 Alluxio 可以实现非常简单便捷的分布式缓存管理,比如设置缓存替换策略,设置数据的过期时间,预读取或者驱逐特定目录下的数据等等操作。这些都可以给模型训练带来效率的提升和管理的便捷。
==============================================================================================
要在 Kubernetes 中原生的使用 Alluxio,首先就要把它部署到 K8s 中,因此我们的第一步工作和 Alluxio 团队一起提供一个 Helmchart,可以统一的配置用户身份,参数以及分层缓存配置。
从左图中看,这里 Alluxio 的 master 以 statefulset 的模式部署,这是因为 Alluxiomaster 首先需要稳定,唯一的网络 id,可以应对容灾等复杂场景。而 worker 和 Fuse 以 daemonset 的模式部署,并且二者通过 podaffinity 绑定,这样可以使用到数据亲和性。

通过将应用完成 helm 化之后,部署它就变成了非常简单的事情,只需要编写 cong.yaml,执行 helminstall 就可以一键式在 Kubernetes 中部署 Alluxio。大家感兴趣的话可以查看 alluxio 文档,或者借鉴阿里云容器服务的文档。
============================================================================================
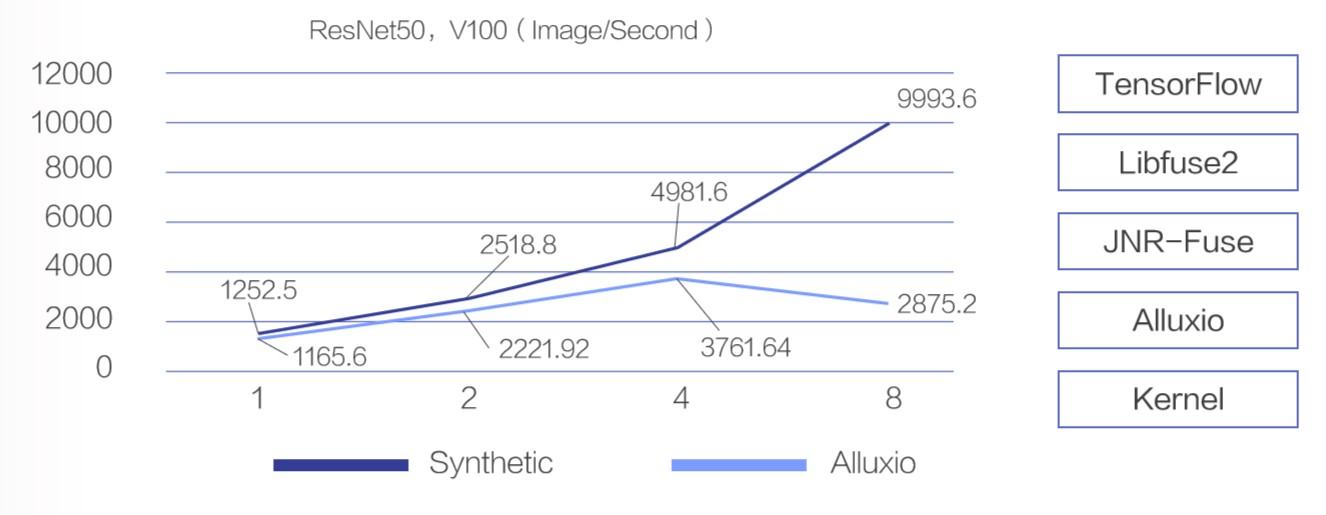
在性能评估中,我们发现当 GPU 硬件从 NVidia P100 升级到 NVidia V100 之后,单卡的计算训练速度得到了不止 3 倍的提升。计算性能的极大提升给数据存储访问的性能带来了压力。这也给 Alluxio 的 I/O 提出了新的挑战。
下图是在分别在合成数据 (Synthetic Data) 和使用 Alluxio 缓存的性能对比,横轴表示 GPU 的数量,纵轴表示每秒钟处理的图片数。合成数据指训练程序读取的数据有程序自身产生,没有 I/O 开销,代表模型训练性能的理论上限; 使用 Alluxio 缓存指训练程序读取的数据来自于 Alluxio 系统。在 GPU 数量为 1 和 2 时,使用 Alluxio 和合成数据对比,性能差距在可以接受的范围。但是当 GPU 的数量增大到 4 时,二者差距就比较明显了,Alluxio 的处理速度已经从 4981 images/second 降到了 3762 images/second。而当 GPU 的数量达到 8 的时候,Alluxio 上进行模型训练的性能不足合成数据的 30%。而此时通过系统监控,我们观察到整个系统的计算、内存和网络都远远没有达到瓶颈。这间接说明了简单使用 Alluxio 难以高效支持 V100 单机 8 卡的训练场景。
=========================================================================
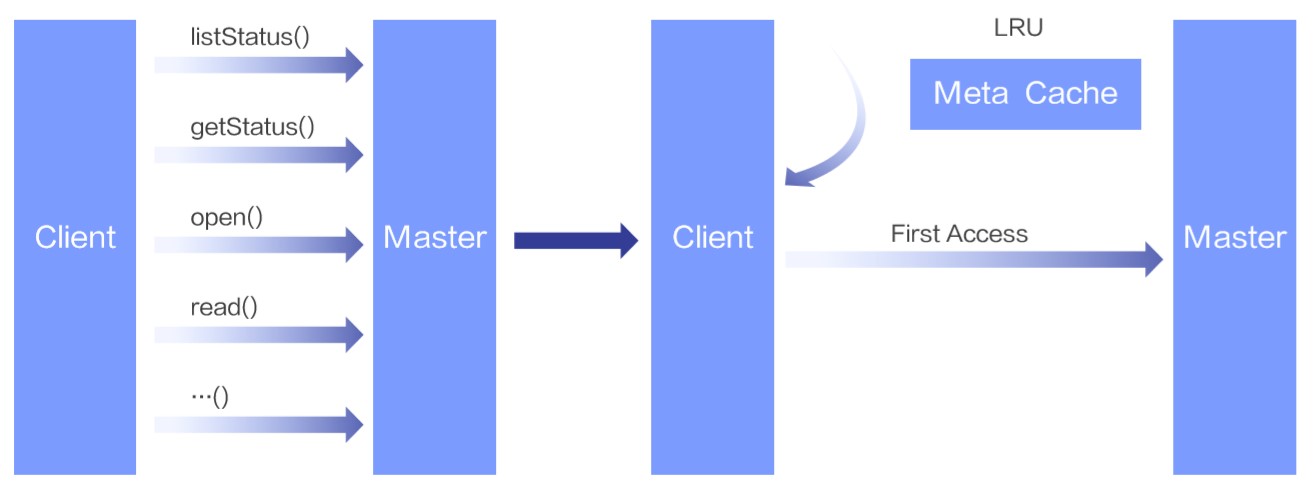
Alluxio 不只是一个单纯的缓存服务。它首先是一个分布式虚拟文件系统,包含完整的元数据管理、块数据管理、UFS 管理(UFS 是底层文件系统的简称)以及健康检查机制,尤其是它的元数据管理实现比很多底层文件系统更加强大。这些功能是 Alluxio 的优点和特色,但也意味着使用分布式系统带来的开销。例如,在默认设置下使用 Alluxio 客户端来读一个文件,即便数据已经缓存在本地的 Alluxio Worker 中,客户端也会和 Master 节点有多次 RPC 交互来获取文件元信息以保证数据的一致性。完成整个读操作的链路额外开销在传统大数据场景下并不明显,但是深度面对学习场景下高吞吐和低延时的需求就显得捉襟见肘了。因此我们要提供客户端的元数据缓存能力。
总结
面试建议是,一定要自信,敢于表达,面试的时候我们对知识的掌握有时候很难面面俱到,把自己的思路说出来,而不是直接告诉面试官自己不懂,这也是可以加分的。
以上就是蚂蚁技术四面和HR面试题目,以下最新总结的最全,范围包含最全MySQL、Spring、Redis、JVM等最全面试题和答案,仅用于参考

和HR面试题目,以下最新总结的最全,范围包含最全MySQL、Spring、Redis、JVM等最全面试题和答案,仅用于参考
[外链图片转存中…(img-3BOIs0us-1715807141021)]















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









