






最后
经过日积月累, 以下是小编归纳整理的深入了解Java虚拟机文档,希望可以帮助大家过关斩将顺利通过面试。
由于整个文档比较全面,内容比较多,篇幅不允许,下面以截图方式展示 。







由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!

简单看一下在大数据和 AI 生态圈里, Alluxio 处于什么位置。在大数据软件栈里,Alluxio 是新的一层,我们称之为数据编排层。它向上对接计算应用,比如Spark, Presto,Hive,Tensorflow,向下对接不同的存储,比如阿里巴巴的 OSS,HDFS。我们希望通过这一层新加入的数据编排层,可以让计算和存储之间的强关联解耦。从而让计算和存储都可以独立而更敏捷的部署和演进。数据应用可以不必关心和维护数据存储的具体类型,协议,版本,地理位置等。而数据的存储也可以通过数据编排这一层更灵活更高效的被各种不同应用消费。

1)分布式数据缓存
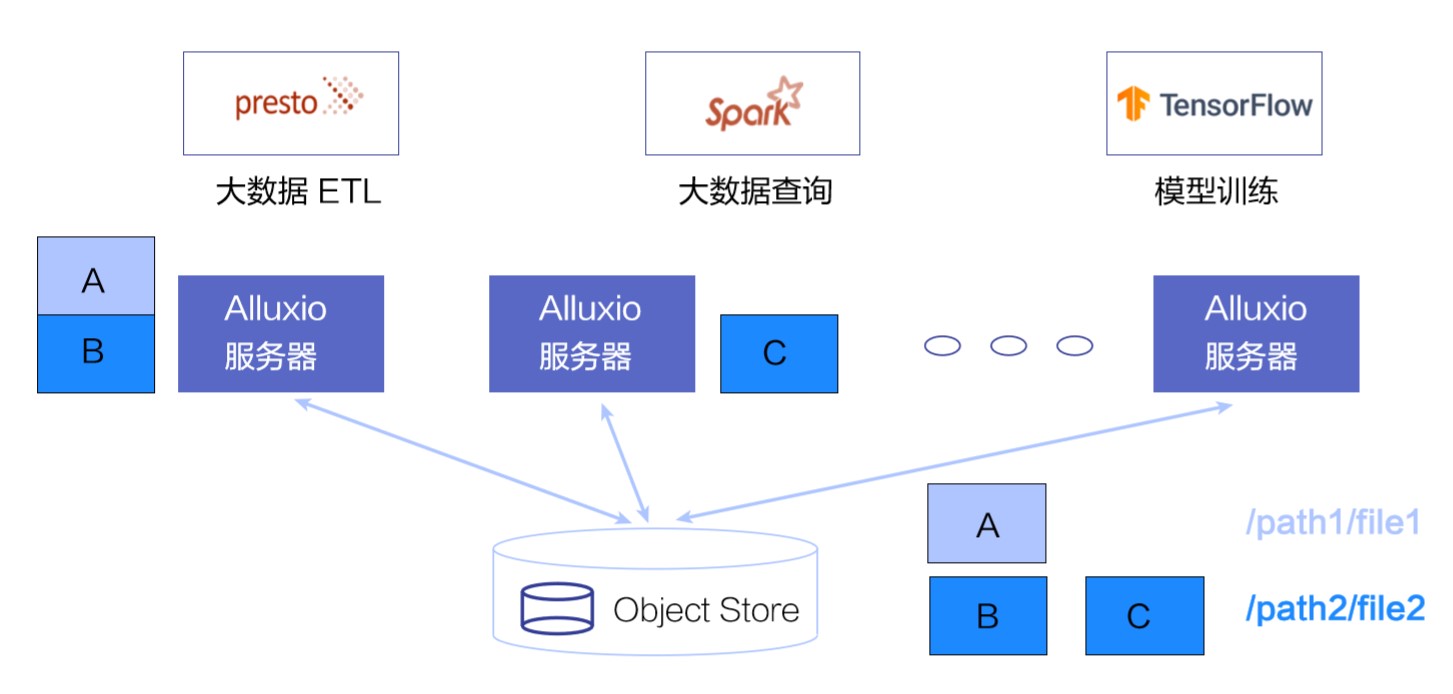
下面介绍一下 Alluxio 的核心功能。Alluxio 最核心的服务就是提供一个分布式的数据缓存用来加速数据应用。对于 Spark,Presto,Tensorflow 等数据密集型的应用,当读取非本地的数据源时,Alluxio 可以通过加载原始数据文件,将其分片以及打散,并存储在靠近应用的 Alluxio 服务器上, 增强这些应用的数据本地性。
比如在这个例子里, 文件 1 和文件 2 分别被分片后存储在不同的 Alluxio 服务器上,应用端可以就近从存储了对应的数据分片的服务器读取。当应用需要的读入有明显的热数据时, 添加缓存层可以显著的节省资源以及提升效率。
2)灵活多样的数据访问 API
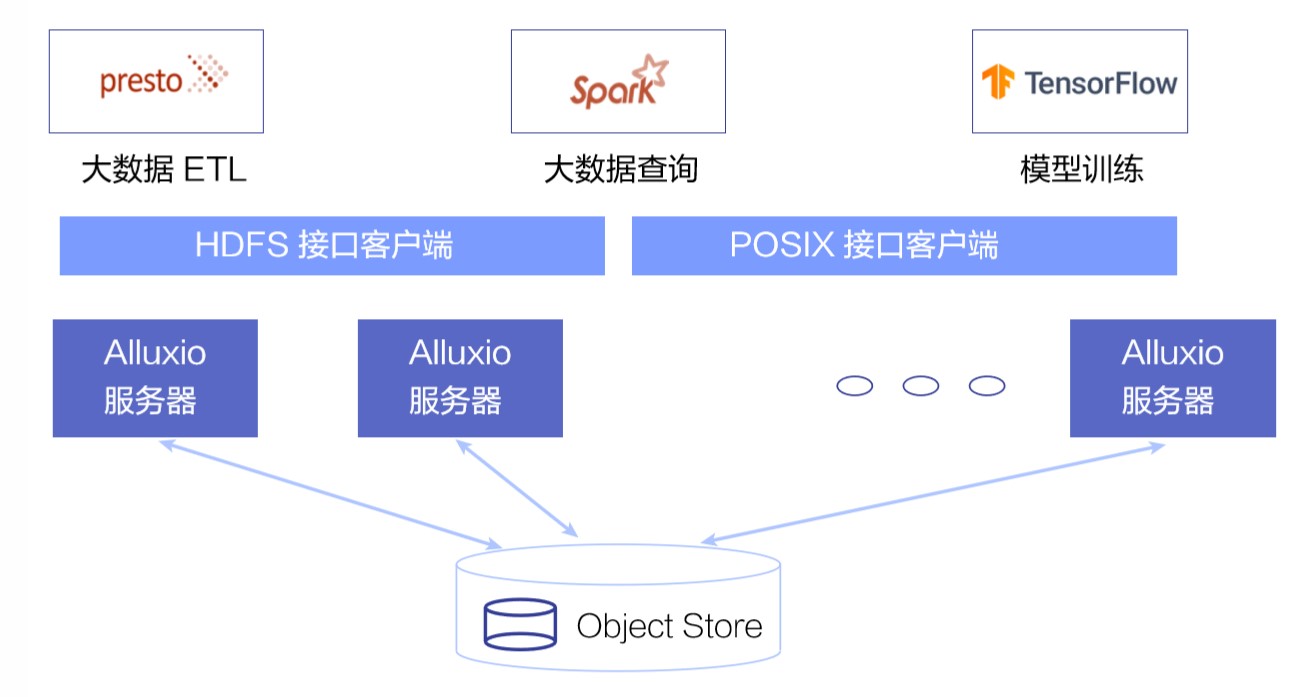
Alluxio 的第二个核心应用,是对应用提供不同类型的数据接口,包括在大数据领域最常见的 HDFS 接口,以及在 ai 和模型训练场景下常用的 POSIX 标准文件系统接口。
这样同样的数据一旦准备完毕, 可以以不同的形式呈现给应用,而不用做多次处理或者 ETL。
3)统一文件系统抽象
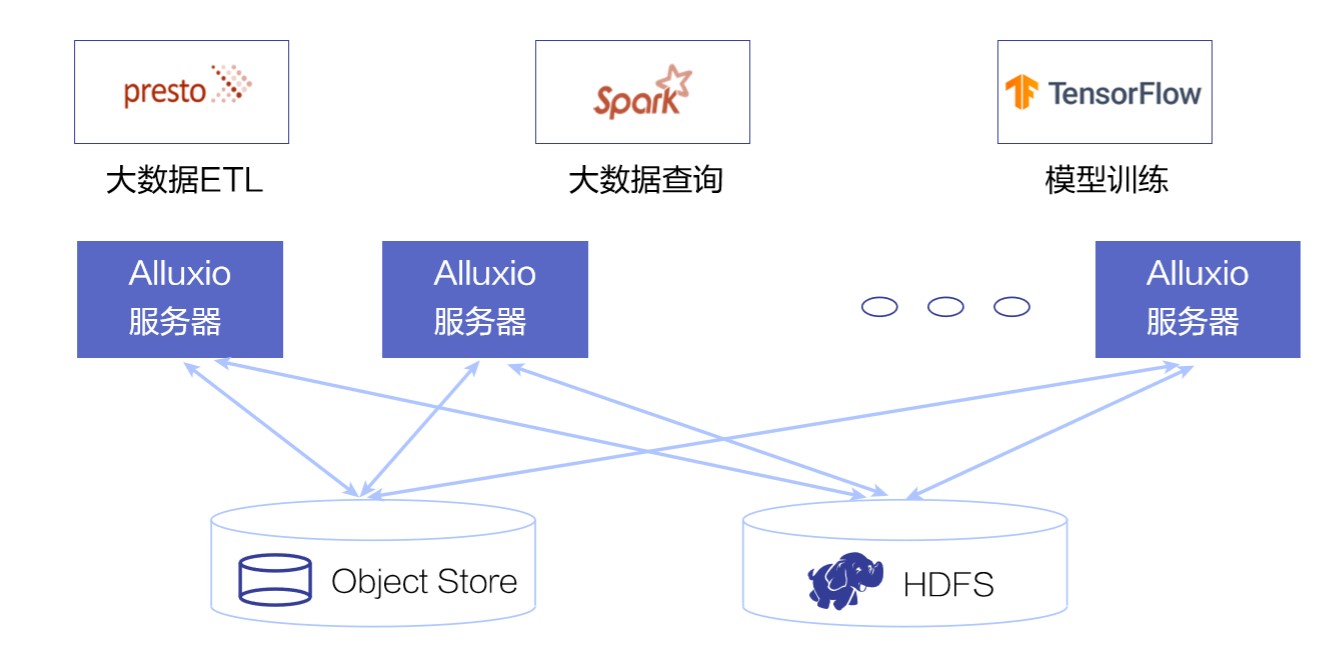
Alluxio 的第三个核心功能,是把多个不同的存储系统,以对用户透明的方式,统一接入一个文件系统抽象中。这样使得复杂的数据平台变得简单而易于维护。数据消费者,只需要知道数据对应的逻辑地址,而不用去关心底层对接的时候什么存储系统。
举个例子, 如果一家公司同时有多个不同的 HDFS 部署,并且在线上接入了 Alibaba 的 OSS 服务, 那么我们完全可以使用 Alluxio 的挂载功能,把这些系统接入一个统一的逻辑上的 Alluxio 文件系统抽象中。每一个 HDFS 会对应到不同的 Alluxio 目录。
=============================================================================================
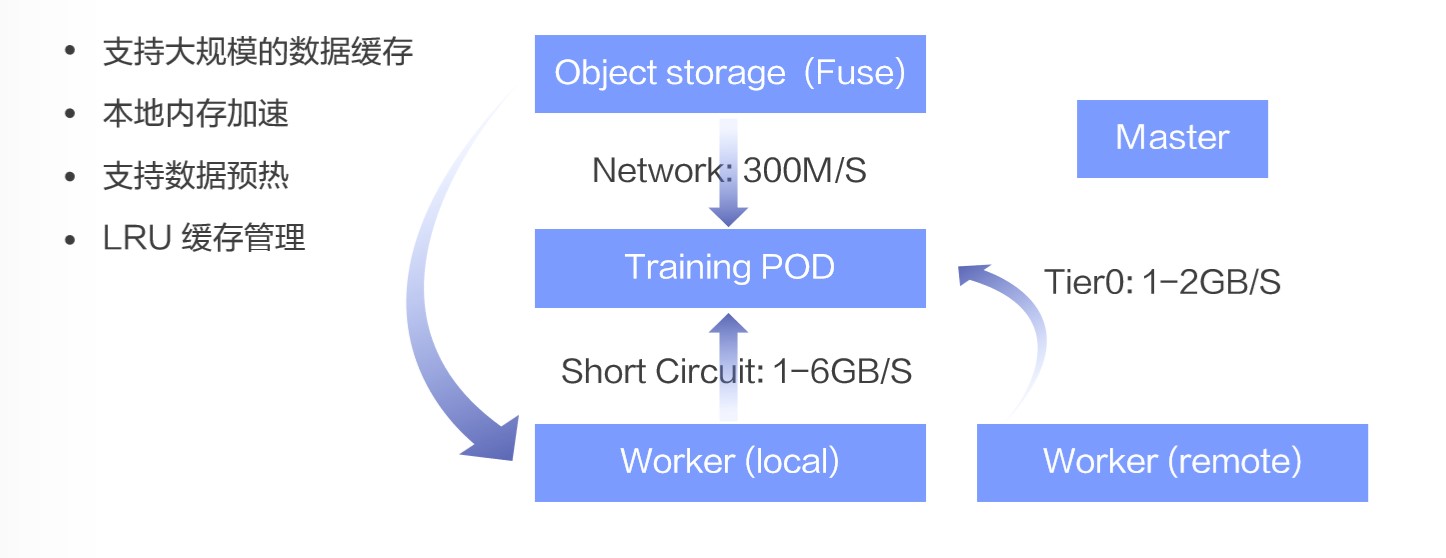
介绍完了 Alluxio 的核心功能,让我们聚焦在云端 AI 训练场景下,再来回顾一下 Alluxio 可能带来的好处。在模型训练场景下内存加速才能满足 GPU 需要的高吞吐。如果通过普通的网络从 Object store 传输数据, 大约能支撑 300MB/s, 这远远不能达到充分使用训练资源特别是 GPU 高吞吐的特性。但是一旦利用 Alluxio 构建了一层分布式的数据缓存,负责训练的容器进程和 alluxio worker 容器进程就可以以很高的速率交换数据。比如当两者在同一物理主机上的时候, 可以达到 1-6GB 每秒。从其他 alluxioworker 处读取也可以通常达到 1-2GB/s 。
此外,通过 Alluxio 可以实现非常简单便捷的分布式缓存管理,比如设置缓存替换策略,设置数据的过期时间,预读取或者驱逐特定目录下的数据等等操作。这些都可以给模型训练带来效率的提升和管理的便捷。
==============================================================================================
要在 Kubernetes 中原生的使用 Alluxio,首先就要把它部署到 K8s 中,因此我们的第一步工作和 Alluxio 团队一起提供一个 Helmchart,可以统一的配置用户身份,参数以及分层缓存配置。
从左图中看,这里 Alluxio 的 master 以 statefulset 的模式部署,这是因为 Alluxiomaster 首先需要稳定,唯一的网络 id,可以应对容灾等复杂场景。而 worker 和 Fuse 以 daemonset 的模式部署,并且二者通过 podaffinity 绑定,这样可以使用到数据亲和性。

通过将应用完成 helm 化之后,部署它就变成了非常简单的事情,只需要编写 cong.yaml,执行 helminstall 就可以一键式在 Kubernetes 中部署 Alluxio。大家感兴趣的话可以查看 alluxio 文档,或者借鉴阿里云容器服务的文档。
============================================================================================
在性能评估中,我们发现当 GPU 硬件从 NVidia P100 升级到 NVidia V100 之后,单卡的计算训练速度得到了不止 3 倍的提升。计算性能的极大提升给数据存储访问的性能带来了压力。这也给 Alluxio 的 I/O 提出了新的挑战。
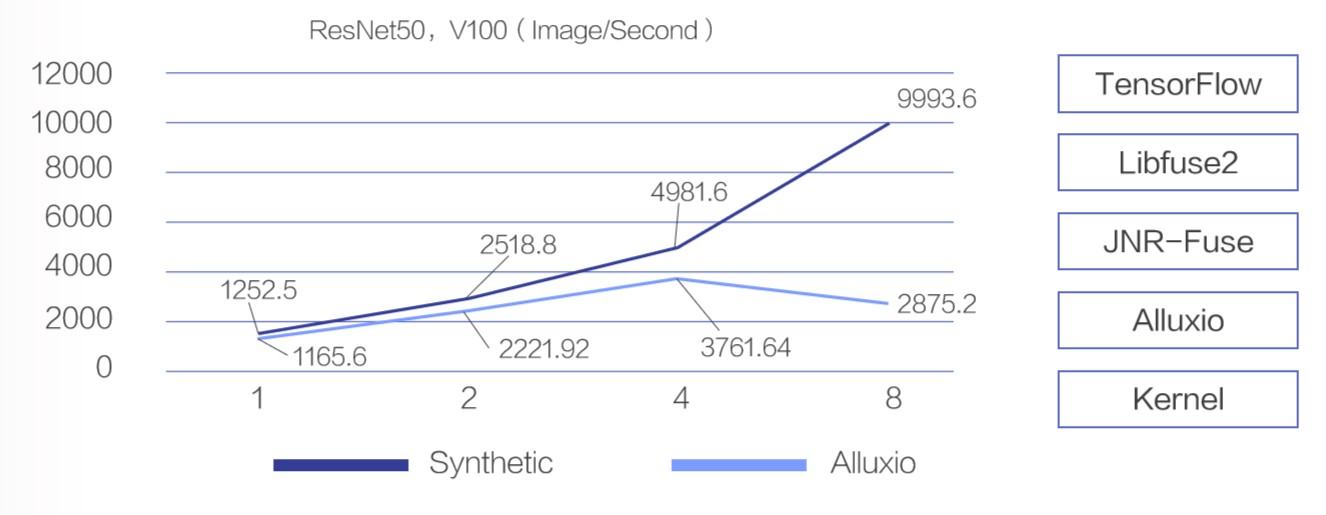
下图是在分别在合成数据 (Synthetic Data) 和使用 Alluxio 缓存的性能对比,横轴表示 GPU 的数量,纵轴表示每秒钟处理的图片数。合成数据指训练程序读取的数据有程序自身产生,没有 I/O 开销,代表模型训练性能的理论上限; 使用 Alluxio 缓存指训练程序读取的数据来自于 Alluxio 系统。在 GPU 数量为 1 和 2 时,使用 Alluxio 和合成数据对比,性能差距在可以接受的范围。但是当 GPU 的数量增大到 4 时,二者差距就比较明显了,Alluxio 的处理速度已经从 4981 images/second 降到了 3762 images/second。而当 GPU 的数量达到 8 的时候,Alluxio 上进行模型训练的性能不足合成数据的 30%。而此时通过系统监控,我们观察到整个系统的计算、内存和网络都远远没有达到瓶颈。这间接说明了简单使用 Alluxio 难以高效支持 V100 单机 8 卡的训练场景。
=========================================================================
Alluxio 不只是一个单纯的缓存服务。它首先是一个分布式虚拟文件系统,包含完整的元数据管理、块数据管理、UFS 管理(UFS 是底层文件系统的简称)以及健康检查机制,尤其是它的元数据管理实现比很多底层文件系统更加强大。这些功能是 Alluxio 的优点和特色,但也意味着使用分布式系统带来的开销。例如,在默认设置下使用 Alluxio 客户端来读一个文件,即便数据已经缓存在本地的 Alluxio Worker 中,客户端也会和 Master 节点有多次 RPC 交互来获取文件元信息以保证数据的一致性。完成整个读操作的链路额外开销在传统大数据场景下并不明显,但是深度面对学习场景下高吞吐和低延时的需求就显得捉襟见肘了。因此我们要提供客户端的元数据缓存能力。
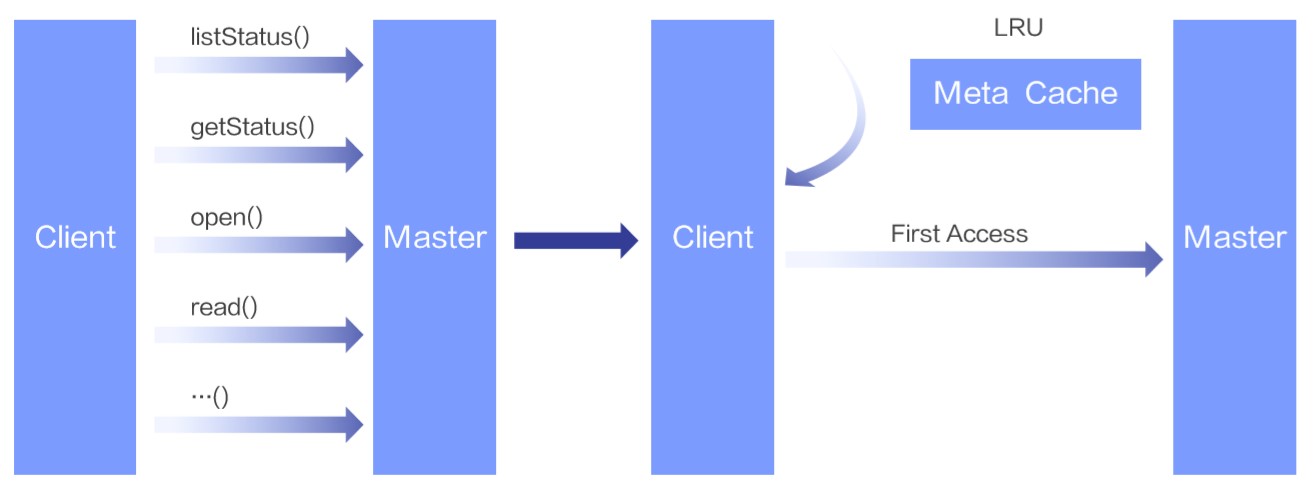
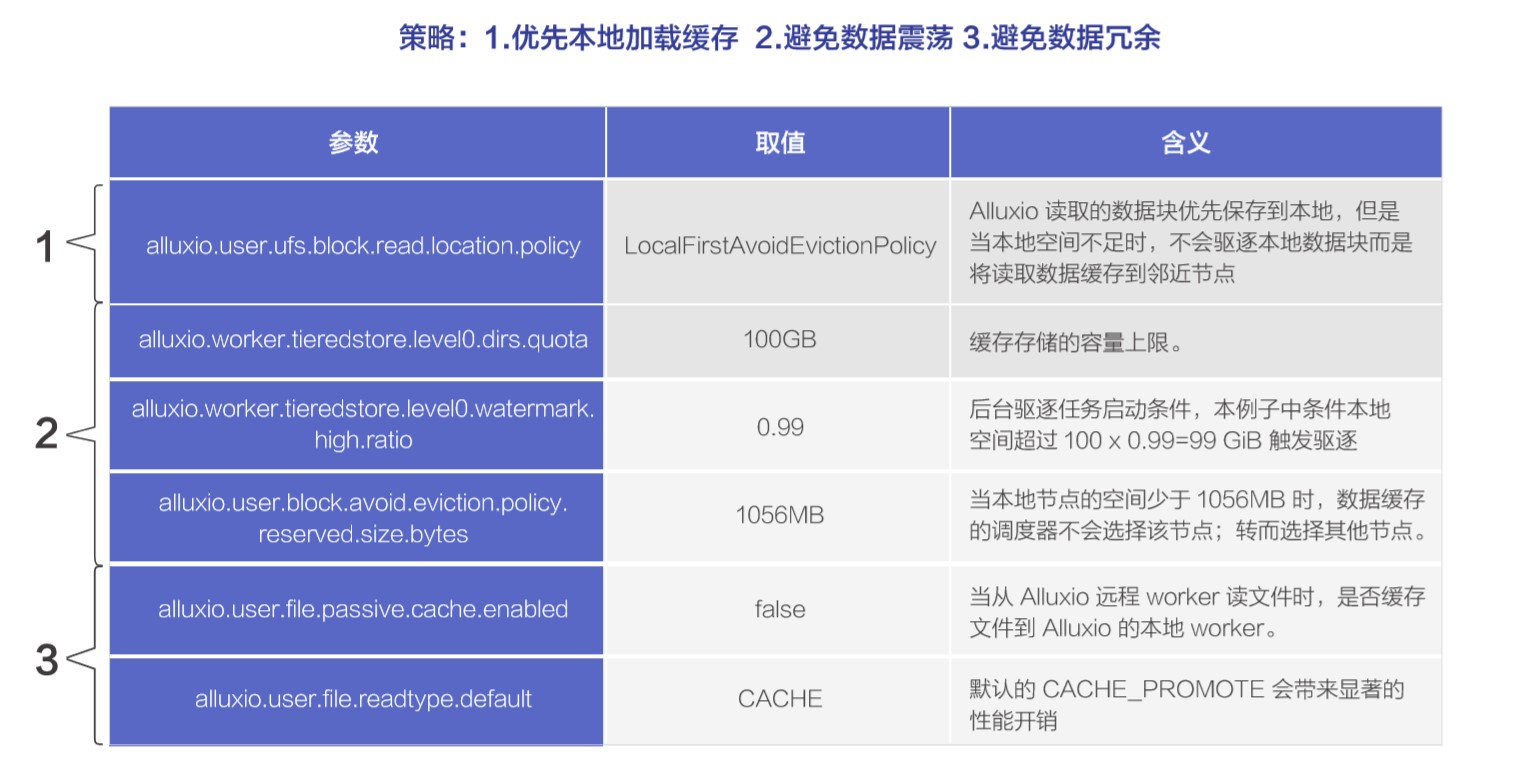
由于深度学习训练场景下,每次训练迭代都是全量数据集的迭代,缓存几个 TB 的数据集对于任何一个节点的存储空间来说都是捉襟见肘。而 Alluxio 的默认缓存策略是为大数据处理场景(例如查询)下的冷热数据分明的需求设计的,数据缓存会保存在 Alluxio 客户端所在的本地节点,用来保证下次读取的性能最优。具体来说:
-
alluxio.user.ufs.block.read.location.policy 默认值为 alluxio.client.block.policy.LocalFirstPolicy,这表示 Alluxio 会不断将数据保存到 Alluxio 客户端所在的本地节点,就会引发其缓存数据接近饱和时,该节点的缓存一直处于抖动状态,引发吞吐和延时极大的下降,同时对于 Master 节点的压力也非常大。因此需要 location.policy 设置为 alluxio.client.block.policy.LocalFirstAvoidEvictionPolicy 的同时,指定 alluxio.user.block.avoid.eviction.policy.reserved.size.bytes 参数,这个参数决定了当本地节点的缓存数据量到一定的程度后,预留一些数据量来保证本地缓存不会被驱逐。通常这个参数应该要大于节点缓存上限 X(100%-节点驱逐上限的百分比)。
-
alluxio.user.file.passive.cache.enabled 设置是否在 Alluxi 的本地节点中缓存额外的数据副本。这个属性是默认开启的。因此,在 Alluxio 客户端请求数据时,它所在的节点会缓存已经在其他 Worker 节点上存在的数据。可以将该属性设为 false,避免不必要的本地缓存。
-
alluxio.user.file.readtype.default 默认值为 CACHE_PROMOTE。这个配置会有两个潜在问题,首先是可能引发数据在同一个节点不同缓存层次之间的不断移动,其次是对数据块的大多数操作都需要加锁,而 Alluxio 源代码中加锁操作的实现不少地方还比较重量级,大量的加锁和解锁操作在并发较高时会带来不小的开销,即便数据没有迁移还是会引入额外开销。因此可以将其设置为 CACHE 以避免 moveBlock 操作带来的加锁开销,替换默认的 CACHE_PROMOTE。
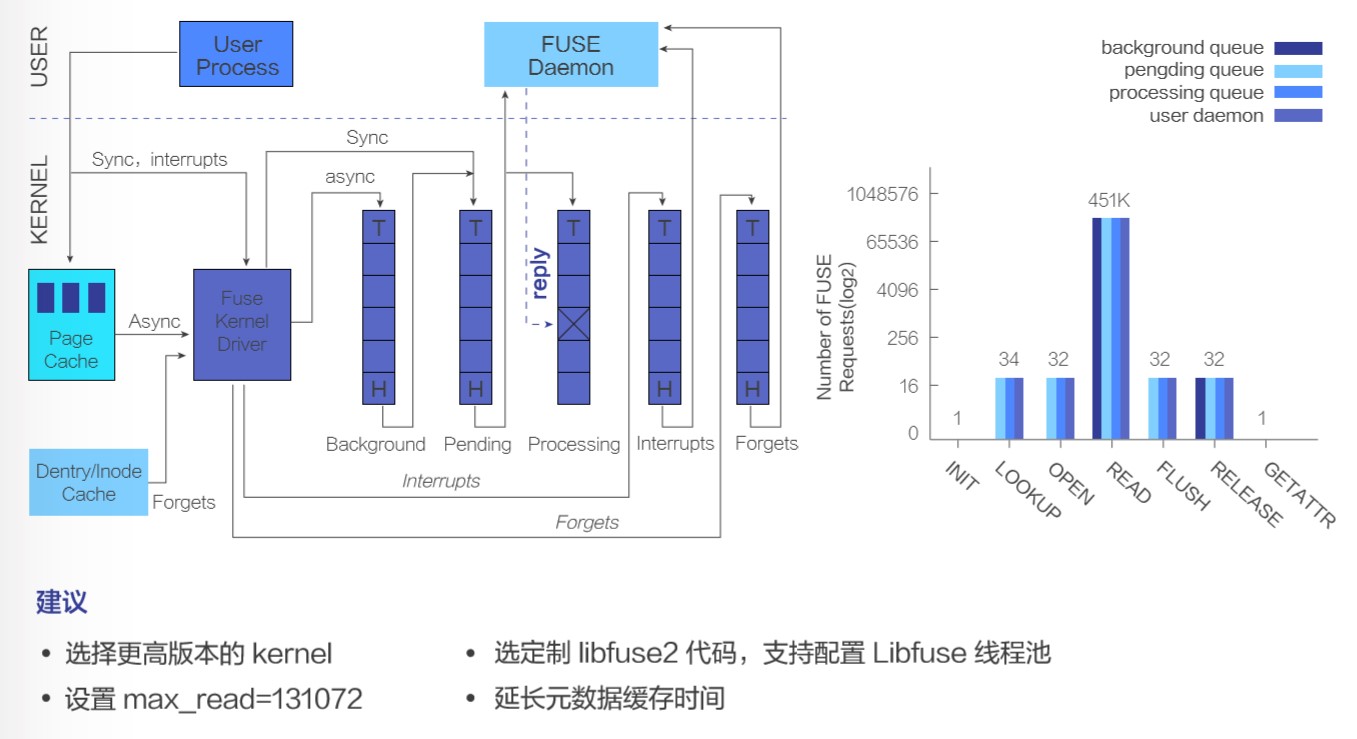
1)延长 FUSE 元数据有效时间
Linux 中每个打开文件在内核中拥有两种元数据信息:struct dentry和struct inode,它们是文件在内核的基础。所有对文件的操作,都需要先获取文件这两个结构。所以,每次获取文件/目录的 inode 以及 dentry 时,FUSE 内核模块都会从 libfuse 以及 Alluxio 文件系统进行完整操作,这样会带来数据访问的高延时和高并发下对于 Alluxio Master 的巨大压力。可以通过配置 –o entry_timeout=T –o attr_timeout=T 进行优化。
2)配置 max_idle_threads 避免频繁线程创建销毁引入 CPU 开销
这是由于 FUSE 在多线程模式下,以一个线程开始运行。当有两个以上的可用请求,则 FUSE 会自动生成其他线程。每个线程一次处理一个请求。处理完请求后,每个线程检查目前是否有超过max_idle_threads(默认 10)个线程;如果有,则该线程回收。而这个配置实际上要和用户进程生成的 I/O 活跃数相关,可以配置成用户读线程的数量。而不幸的是 max_idle_threads 本身只在 libfuse3 才支持,而 AlluxioFUSE 只支持 libfuse2,因此我们修改了 libfuse2 的代码支持了 max_idle_threads 的配置。
=======================================================================
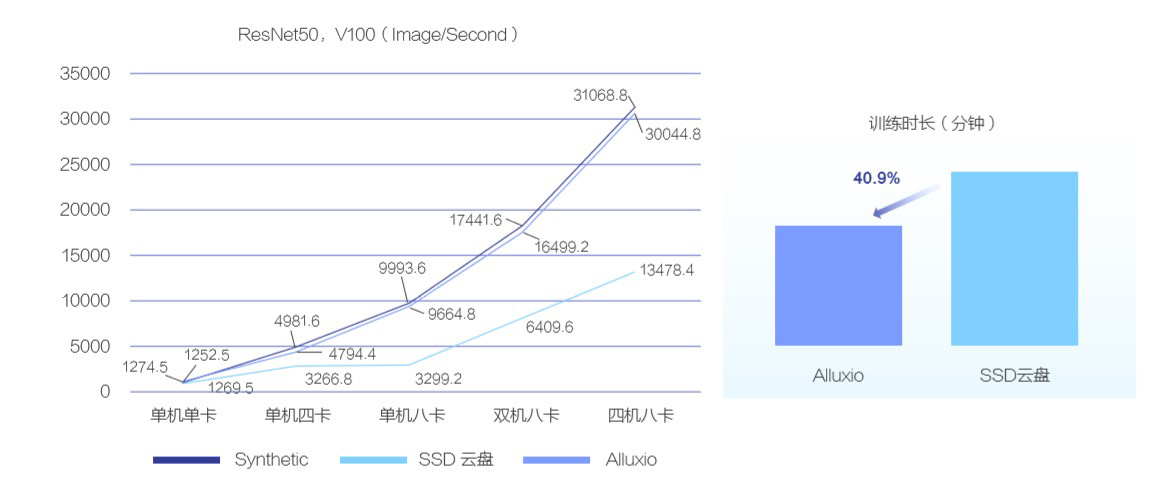
在优化 Alluxio 之后,ResNet50 的训练性能单机八卡性能提升了 236.1%,并且扩展性问题得到了解决,训练速度在不但可以扩展到了四机八卡,而且在此场景下和合成数据相比性能损失为 3.29%(31068.8images/s vs 30044.8 images/s)。相比于把数据保存到 SSD 云盘,在四机八卡的场景下,Alluxio 的性能提升了 70.1% (云 SSD 17667.2 images/s vs 30044.8 images/s)。
如果您对通过 Alluxio 在 Kubernetes 中加速深度学习感兴趣,欢迎钉钉扫码加入中国社区大群。我们一起来讨论您的场景和问题。

范斌,是 Alluxio 的创始成员,曾经就职于 Google,早期负责 Alluxio 的架构设计,现在关注于 Alluxio 开源社区的运营。
车漾,就职于阿里云容器服务团队,关注于云原生技术与 AI、大数据场景的结合。
最后
分享一套我整理的面试干货,这份文档结合了我多年的面试官经验,站在面试官的角度来告诉你,面试官提的那些问题他最想听到你给他的回答是什么,分享出来帮助那些对前途感到迷茫的朋友。
面试经验技巧篇
- 经验技巧1 如何巧妙地回答面试官的问题
- 经验技巧2 如何回答技术性的问题
- 经验技巧3 如何回答非技术性问题
- 经验技巧4 如何回答快速估算类问题
- 经验技巧5 如何回答算法设计问题
- 经验技巧6 如何回答系统设计题
- 经验技巧7 如何解决求职中的时间冲突问题
- 经验技巧8 如果面试问题曾经遇见过,是否要告知面试官
- 经验技巧9 在被企业拒绝后是否可以再申请
- 经验技巧10 如何应对自己不会回答的问题
- 经验技巧11 如何应对面试官的“激将法”语言
- 经验技巧12 如何处理与面试官持不同观点这个问题
- 经验技巧13 什么是职场暗语

面试真题篇
- 真题详解1 某知名互联网下载服务提供商软件工程师笔试题
- 真题详解2 某知名社交平台软件工程师笔试题
- 真题详解3 某知名安全软件服务提供商软件工程师笔试题
- 真题详解4 某知名互联网金融企业软件工程师笔试题
- 真题详解5 某知名搜索引擎提供商软件工程师笔试题
- 真题详解6 某初创公司软件工程师笔试题
- 真题详解7 某知名游戏软件开发公司软件工程师笔试题
- 真题详解8 某知名电子商务公司软件工程师笔试题
- 真题详解9 某顶级生活消费类网站软件工程师笔试题
- 真题详解10 某知名门户网站软件工程师笔试题
- 真题详解11 某知名互联网金融企业软件工程师笔试题
- 真题详解12 国内某知名网络设备提供商软件工程师笔试题
- 真题详解13 国内某顶级手机制造商软件工程师笔试题
- 真题详解14 某顶级大数据综合服务提供商软件工程师笔试题
- 真题详解15 某著名社交类上市公司软件工程师笔试题
- 真题详解16 某知名互联网公司软件工程师笔试题
- 真题详解17 某知名网络安全公司校园招聘技术类笔试题
- 真题详解18 某知名互联网游戏公司校园招聘运维开发岗笔试题

资料整理不易,点个关注再走吧
解16 某知名互联网公司软件工程师笔试题
- 真题详解17 某知名网络安全公司校园招聘技术类笔试题
- 真题详解18 某知名互联网游戏公司校园招聘运维开发岗笔试题
[外链图片转存中…(img-hKBEjXN9-1715807208672)]
资料整理不易,点个关注再走吧















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









