







导读:随着人工智能技术的飞速发展,大模型在医学领域的应用已经展现出了巨大的潜力。特别是生成式人工智能(Generative AI),它通过深度学习算法不仅能够设计新的药物分子,还能优化药物属性,甚至在疾病预防和治疗方面提供前所未有的支持。尽管大模型在医学领域的应用带来了诸多好处,但也引发了一些思考,如数据隐私保护、算法偏见问题等。因此,未来的发展中,需要更多的研究和监管措施,以确保人工智能技术在医学领域的安全、有效和公平应用。本文对对大模型在医学上的应用做粗浅的讨论。

本文总结:
-
大模型正在革命性的重塑制药这个行业,将传统药物长达10年的研发周期缩短到几个月。
-
多模态大模型(visual-languange)在临床上的应用可以有效提高临床医生的效率,是一个有前景的技术路径。
-
大模型应用在实际临床上面对的困难:1)不可解释性;2)训练模型的过程中引入的偏见;3)将AI集成到临床点护理中也是一个时间消耗巨大的过程。
-
大模型训练在医学应用上的未来发展趋势:通用医学AI(GMAI)。GMAI模型将能够使用极少量或无需特定任务的标记数据来执行多种任务。
-
大模型正在革命性的重塑制药这个行业
2024年,一个巨大的改变在互联网上就是可能百分之50%的内容都不是由人类完成创作的,而是有generative AI 来完成创作。所以,在这个信息世界在巨大的变动的时候,制药企业首先收到了巨大的冲击。比如,Insilico,一家成立于2014年的全球领先的以深度学习为核心的临床阶段生成式AI和机器人技术公司,正在领导这一变革。他们开发的生成式AI平台支持多模态、多行业、多领域的学习,极大地提高了药物研发的效率和效果。传统的药物研发过程耗时长达10年,并需要超过20亿美元的投资,而现在,通过使用生成式张量强化学习技术,Insilico能够在短短46天内完成从理论模型到小鼠实验的转化。这种高效的研发模式不仅加快了新药的上市速度,也显著降低了研发成本。大家有兴趣可以访问这个网站:https://papers.insilicogpt.com
下面是几篇关于生成式AI在制药上面的应用:

图一:一种新型深度生成模型——生成式张量强化学习(GENTRL)。
在上面这篇文章中,作者开发了一种新型深度生成模型——生成式张量强化学习(GENTRL),用于全新小分子药物的设计。GENTRL优化了合成的可行性、新颖性和生物活性。我们利用GENTRL发现了强效的圆盘状域受体1(DDR1)抑制剂,DDR1是一种与纤维化及其他疾病相关的激酶靶标。在21天内,我们筛选出了多个候选化合物。其中四种化合物在生化试验中显示出活性,两种在细胞基础的试验中得到了验证。一个领先候选物已在小鼠中进行了药动学测试,并显示出了良好的性能。

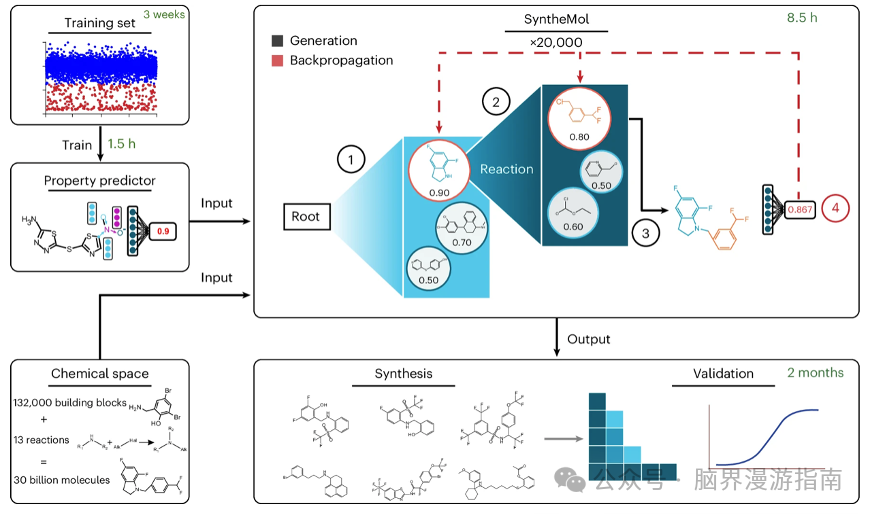
图二:一种名为SyntheMol的生成模型。
随着耐药性细菌的增多,迫切需要开发结构新颖的抗生素。虽然人工智能方法可以发现新的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









