









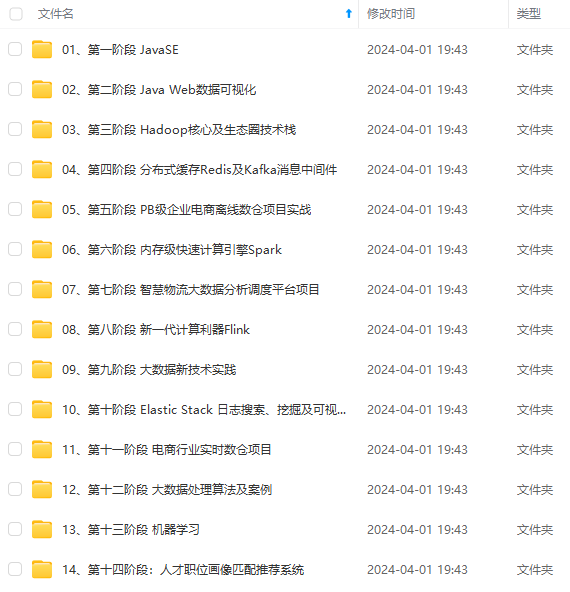
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
本栏目包含大数据OLAP分析场景技术选择、ClickHouse优秀特性分析、ClickHouse分布式集群搭建及实战应用、库表引擎、ClickHouse重点MergeTree引擎、视图、SQL语法、API、ClickHouse与其他大数据分析框架整合、实时场景下ClickHouse应用等内容,从多方面、多角度为大家呈现ClickHouse的“惊艳”之处,让大家学习技术少走弯路,事倍功半。
OLAP场景:

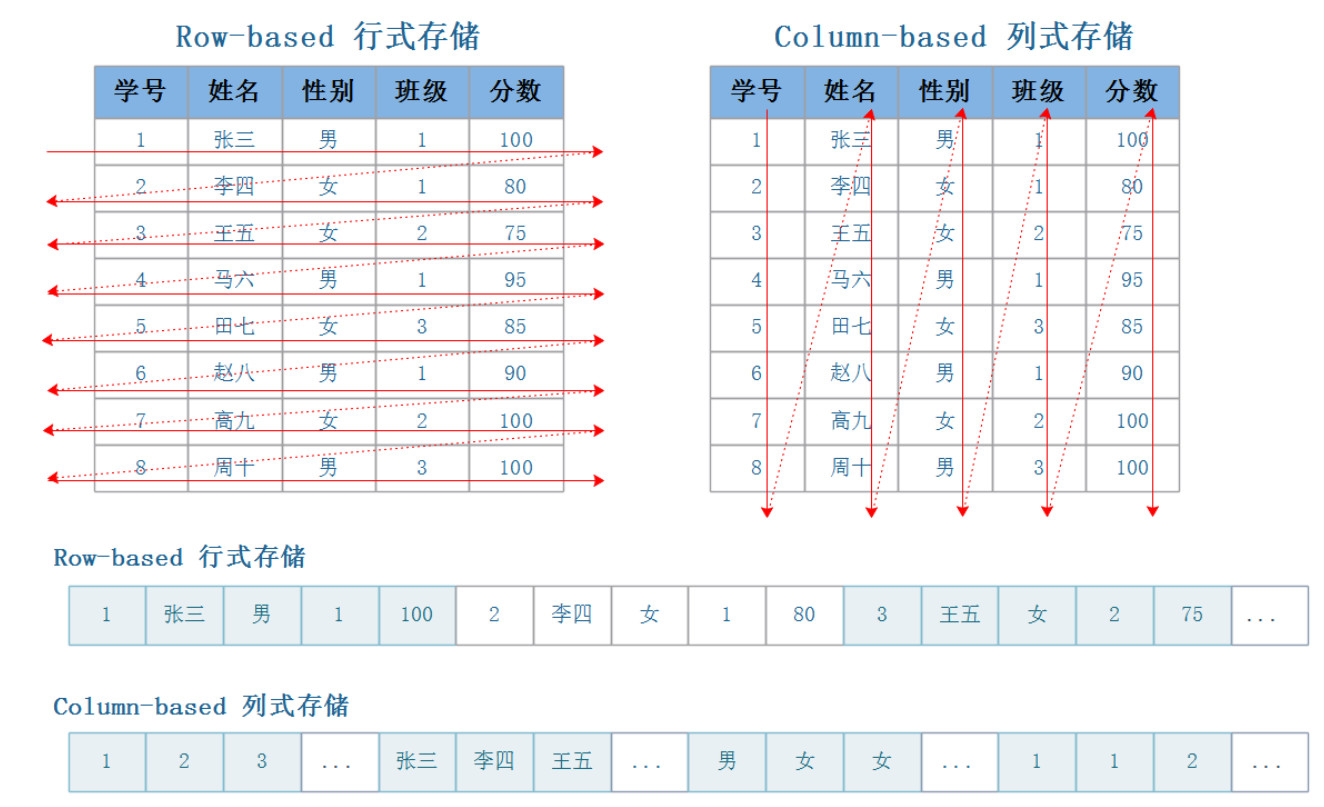
列式存储原理图:
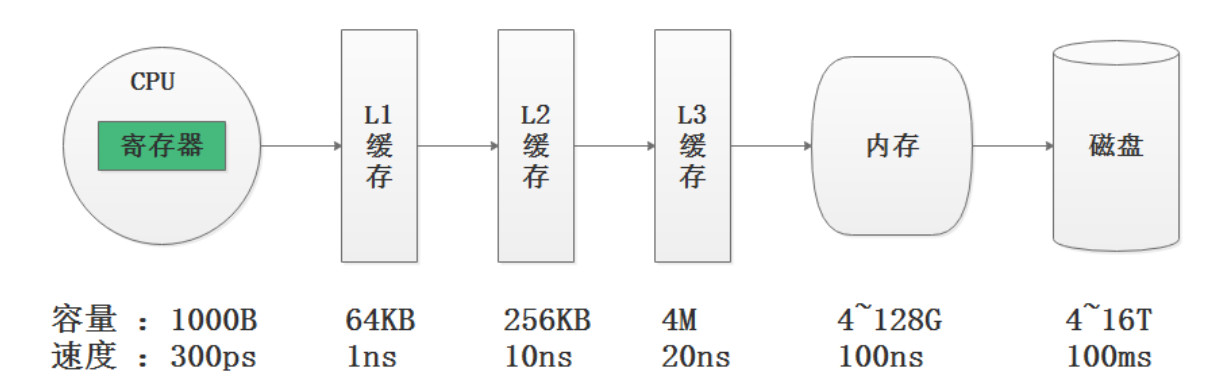
数据存储速度对比图:
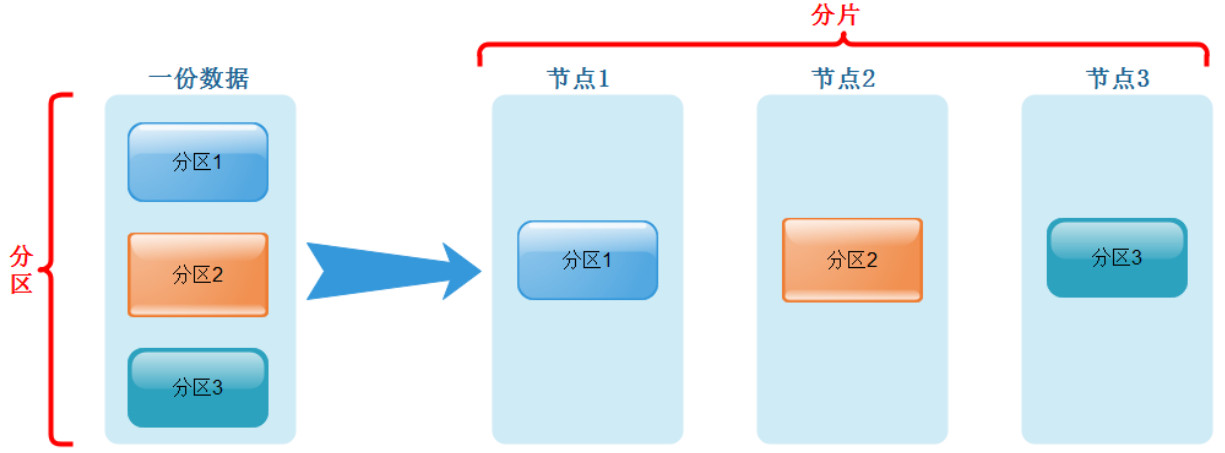
ClickHouse横纵数据存储划分:
三、Presto分布式查询引擎
在大数据中进行数据分析时,数据一般存储在Hive中,针对Hive中的数据进行分析底层转换成MapReduce任务执行,速度比较慢,就算使用SparkSQL框架针对Hive中的数据进行分析,当数据量很大底层转换成Spark 任务执行,但是避免不了资源过程,这个过程速度一般达不到即席查询要求。如果想要针对存储Hive中的数据进行快速OLAP分析时,可以选择Presto OLAP分析引擎,Presto可以针对Hive中的数据基于内存进行快速查询,海量数据秒级内可以相应。
在本栏目中将会带领大家学习Presto特点、架构原理、Presto Server、Prest命令行Cli、Presto Hive Connector、Presto MySQL Connector、Presto Kafka Connector、UDF、UDAF函数定义、Presto优化等技术点。如果你在面试和工作中遇到OLAP数据分析速度慢问题,选择本栏目,可以帮助你系统学习Presto,快速解决生产过程中数据分析效率慢问题。
Presto 架构:
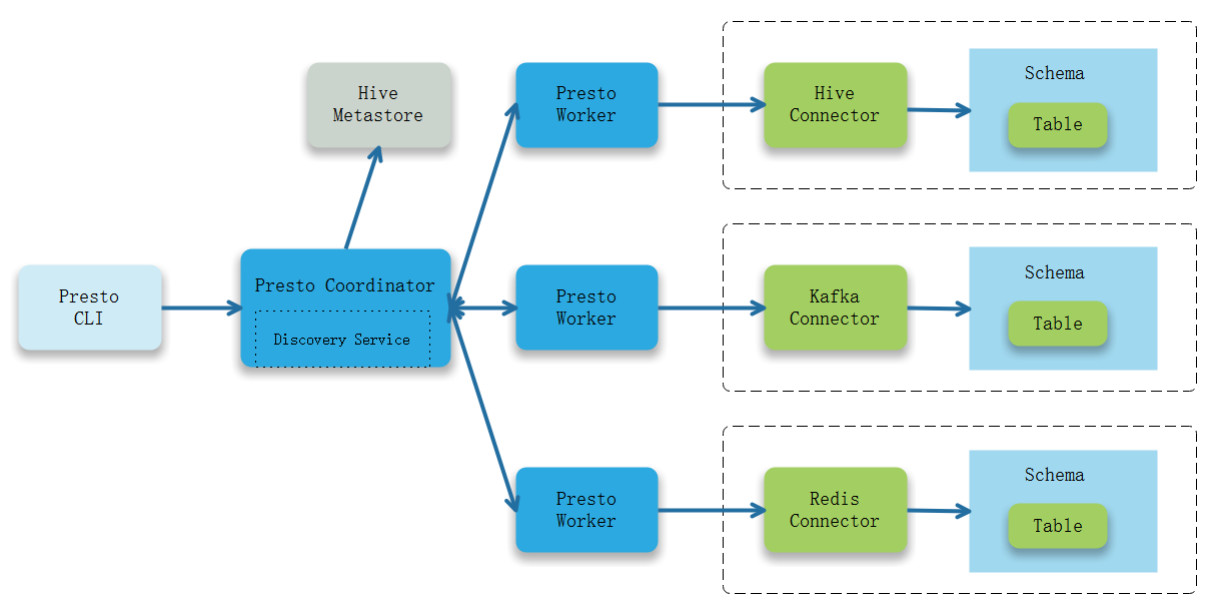
Presto页面:

四、Kudu分布式存储库
结构化数据存储在Hadoop生态系统中,分为静态数据和动态数据两类,静态数据指的是需要进行数据分析的固定数据,其特点是一次写入多次读取分析,会将此类数据存储在HDFS中,HDFS适合这种高吞吐连续访问场景。动态数据指的是低延迟、高效读写并同时支持更新的数据,这类数据会存储在HBase中,HBase的特点就是支持低延迟的随机读写并支持更新操作。以上两类数据处理各有优缺点,HDFS支持高吞吐量但是不支持随机读写更新,HBase支持随机读写、更新但是吞吐量不高,如果在处理数据场景中需要数据既可以高吞吐的随机读写,又可以支持更新,那么Kudu一定是不二之选。
本栏目中将会给大家介绍数据处理分析的场景、Kudu架构、Kudu读写数据过程、Kudu集群搭建、Kudu API 实战应用、Kudu分区、Kudu与其他框架深度整合等内容,如果你在工作中遇到既要吞吐量大,又要支持数据更新的场景那么选择此栏目,给你带来不一般的体验。
Kudu与其他框架对比:

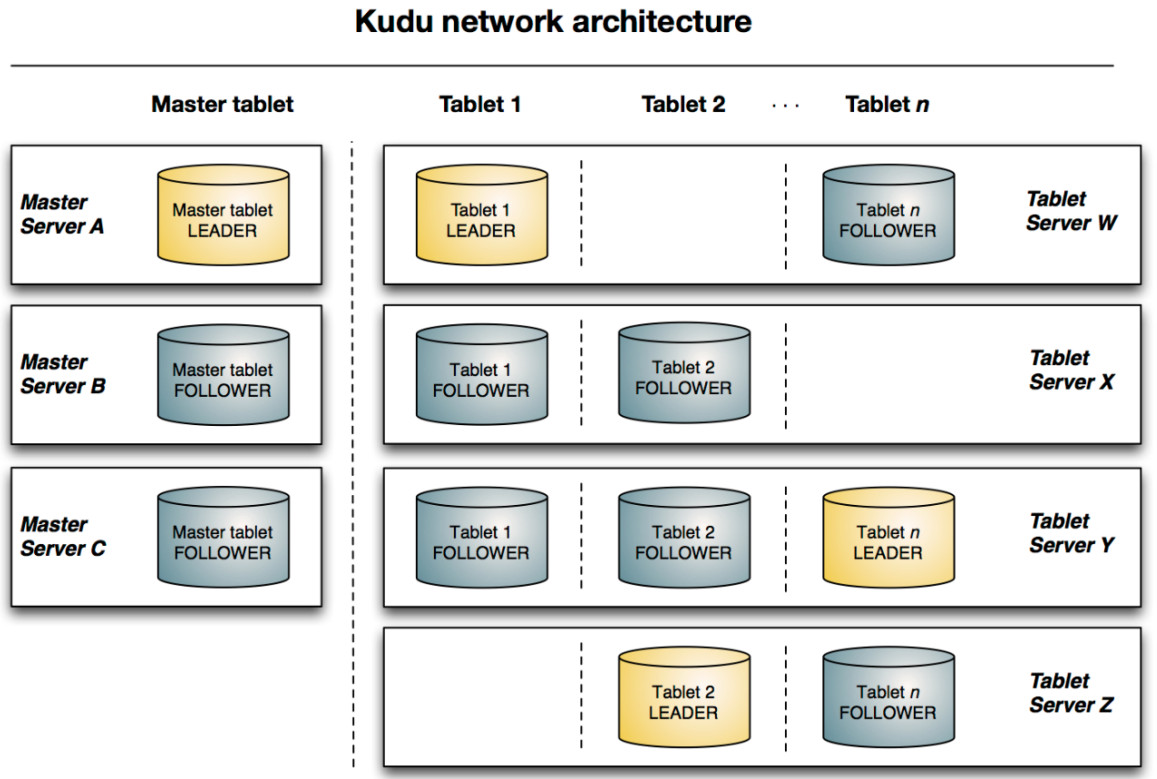
Kudu架构模型:
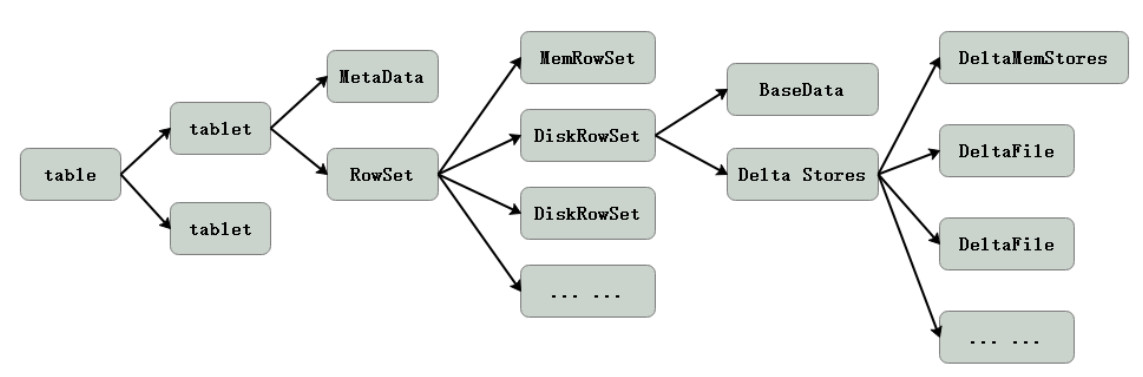
Kudu存储存储及底层原理:

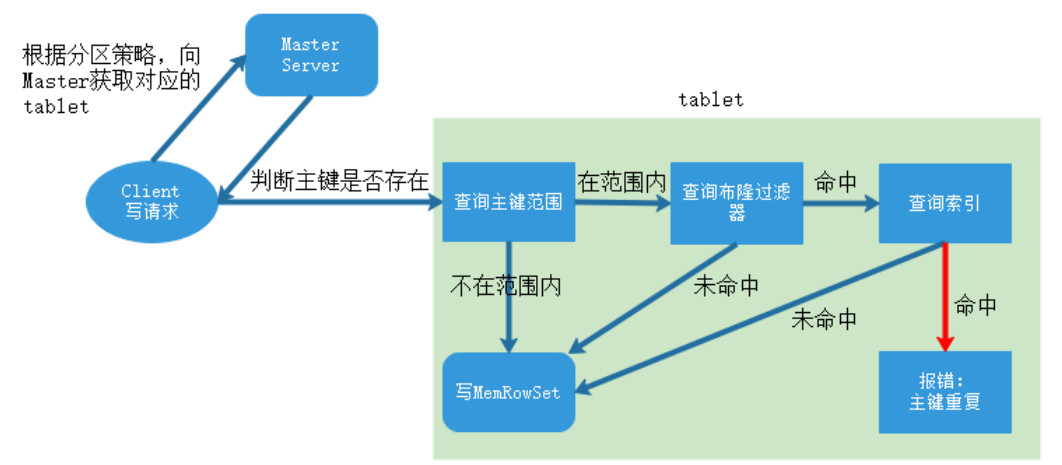
Kudu读写数据原理:
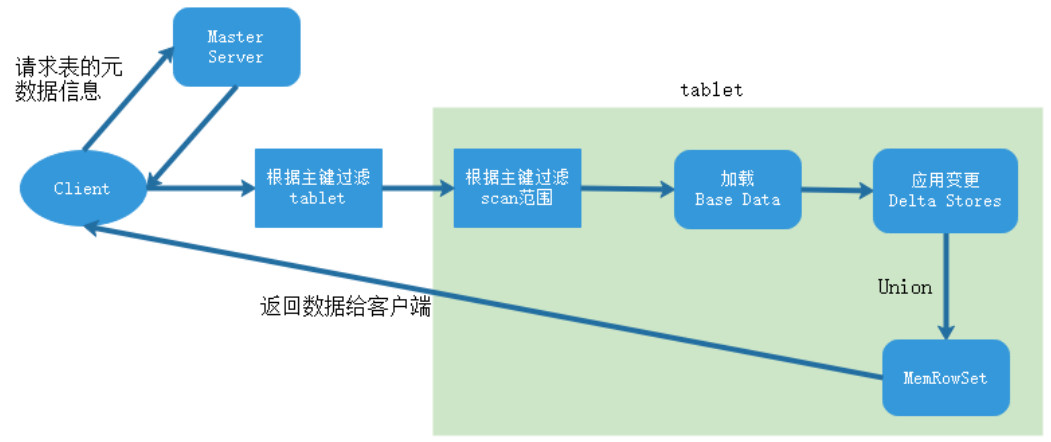
五、Kylin数据仓库分析引擎
在对公司海量数据进行分析过程中,大多数公司会将数据存储在Hive数据仓库中,在对Hive中的数据进行查询聚合获取决策结果时,默认Hive底层转换成MapReduce任务,数据分析的效率快则分钟级别,慢则十几分钟甚至几个小时,为了保证及时看到数据结果,很多公司在凌晨开始运行大数据任务,目的就是为了在工作时间及时看到数据分析结果。
随着公司体量的变大,数据量的增多,公司分析的任务也在增多,同时在开发过程中需要进行很多临时性需求分析,这些临时性的需求同样也会生成对应的MapReduce任务,在等待任务执行过程中浪费了大量时间,如何提高数据查询效率,减少白天工作时间集群资源占用问题成为很多公司头痛的问题。
本栏目所讲的Apache Kylin就解决了以上痛点问题,Kylin可以针对公司的数据按照开发人员的配置预先进行计算,将数据分析的结果存储在HBase中,这些结果包含公司内部所有场景使用到的数据分析结果,再查询数据时相当于直接从HBase中查询结果数据,大大提高了数据处理效率,既解决了临时性任务占用资源问题又解决了响应速度慢问题,可谓是数据OLAP分析中的一股清流。在本栏目中将会带领大家学习Kylin的原理、集群部署、Cube构建、OLAP事实、维度表关系、Cube配置、底层算法原理、Kylin与事实数据流整合等问题。如果你在工作中遇到数据体量大、数据分析慢,学习本栏目可以带你解决你的痛点问题。
OLAP操作场景:

Kylin架构:

Kylin集群部署原理:

Cube构架原理:
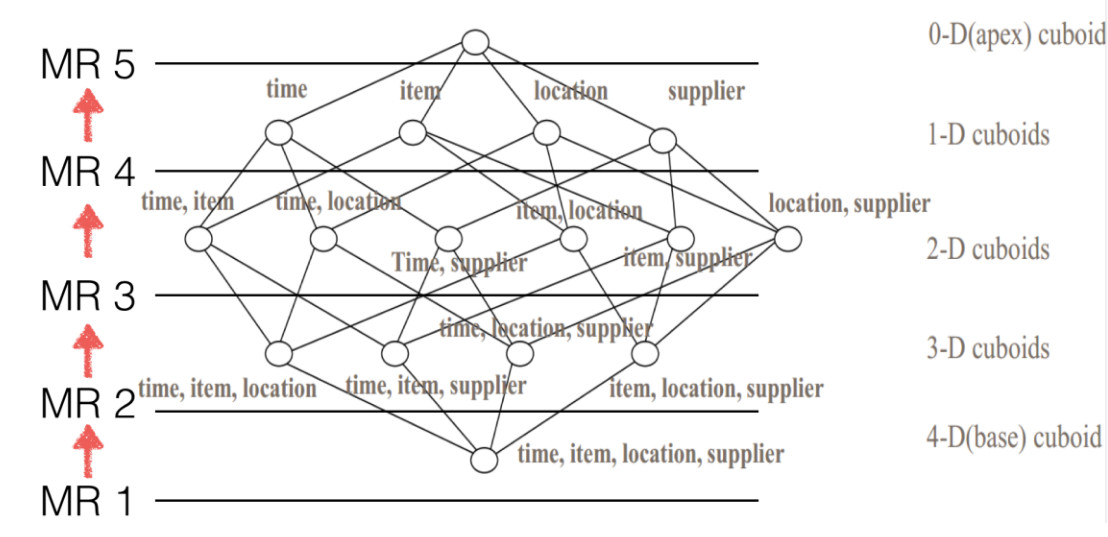
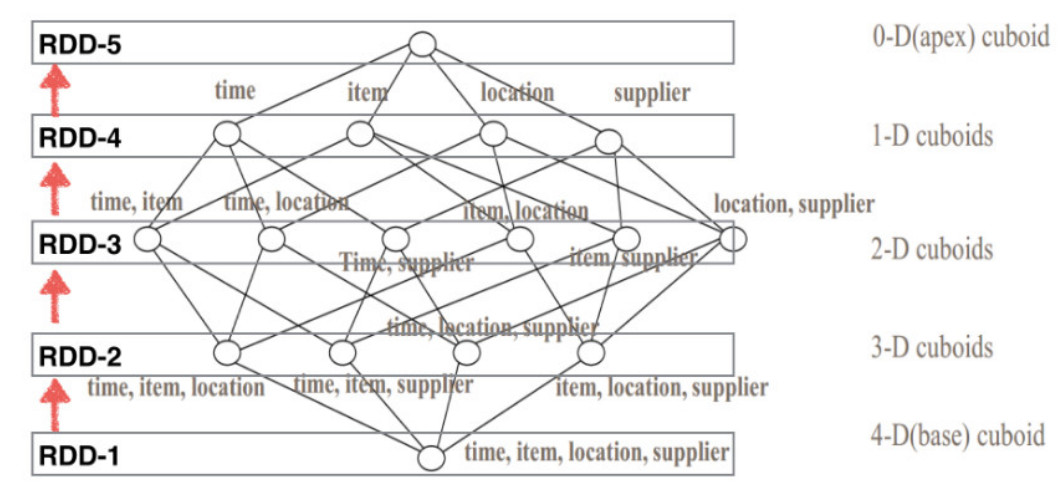
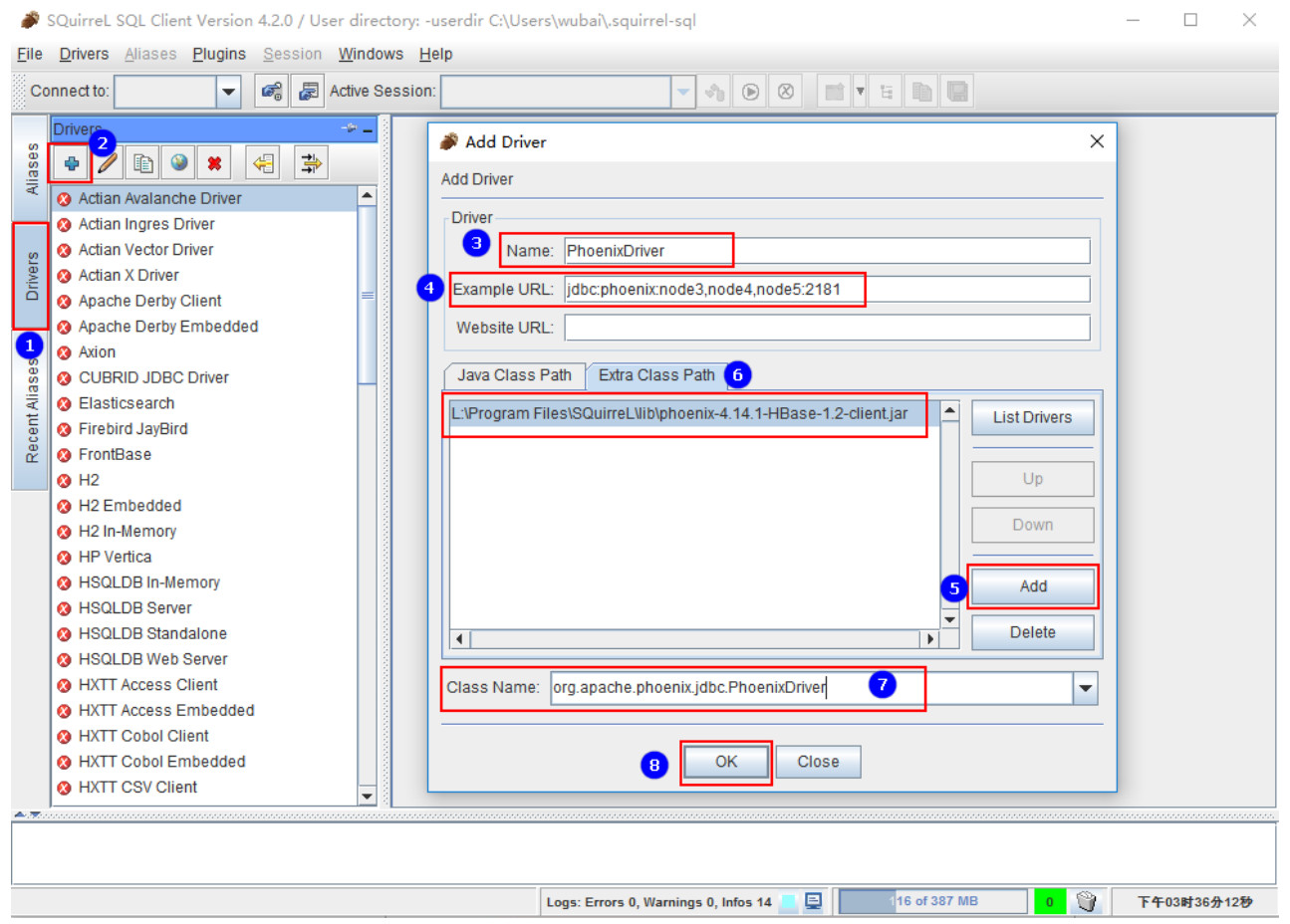
六、Phoenix数据分析引擎
在大数据中针对一些数据量大、需要频繁查询、需要修改更新的数据处理场景来说,一般会选择使用分布式数据库HBase,HBase不支持标准SQL查询,只支持API查询、更新操作,这给业务开发人员带来不小挑战,尤其是在实时数仓中,一般会选择使用HBase当做维度层,实时流数据需要和HBase中的维度数据进行关联,由于HBase不支持标准SQL开发,开发人员在实时业务开发时非常不便。可以通过Phoenix技术对HBase进行“包装”,让HBase支持标准SQL开发并且能有一定性能的提升,Phoenix是构建在HBase上的一个SQL层,是HBase的开源SQL皮肤。它不仅可以使用标准的JDBC API替代HBASE client API创建表、插入、查询HBASE表,也支持二级索引、事务以及多种SQL层优化。
在本栏目中将会带领大家学习Phoenix的架构特点、使用场景、企业级安装部署、Phoenix命令操作、Phoenix表映射、视图映射、二级索引、Phoenix加盐处理、JDBC API操作、优化等一系列Phoenix技术相关问题。如果你在工作中还在为HBase的API操作头疼,那么选择此栏目,从此告别复杂的HBase API编程,迈入轻松的HBase SQL编程。
Phoenix架构:
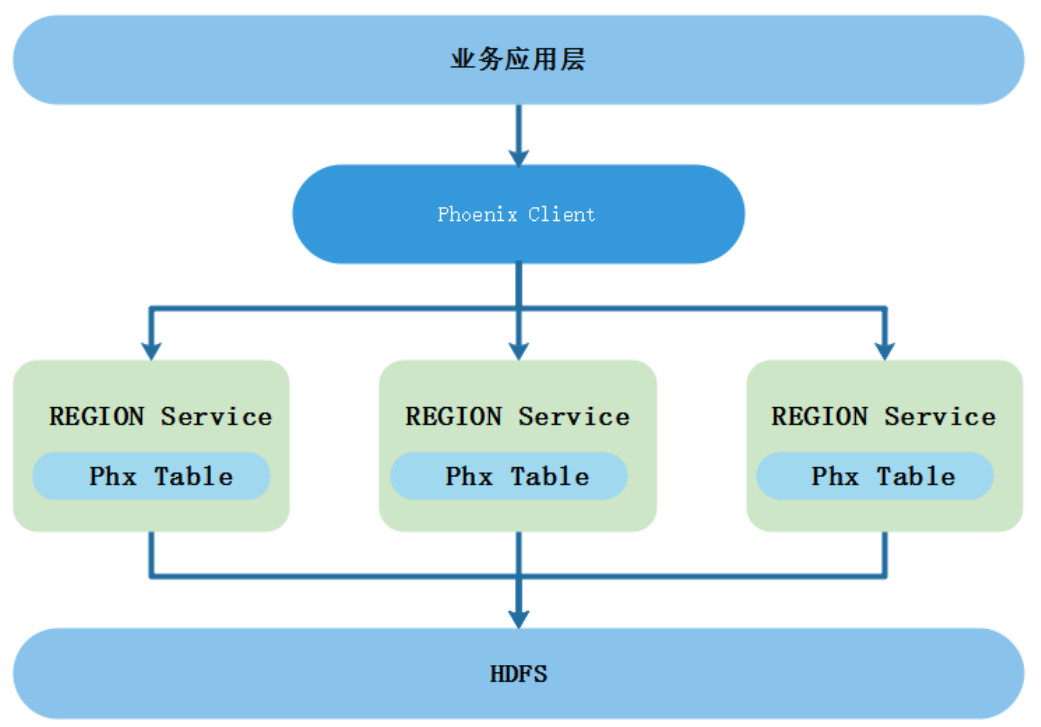
Phoenix图形化工具操作:

七、大规模并行分布式SQL数据库Doris
Apache Doris是一个现代化的MPP分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris的分布式架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集。Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。令您的数据分析工作更加简单高效!
在大数据数据分析中Doris作为新一代的OLAP分析引擎,在很多公司越来越重要,是大数据学习过程中必备技能之一。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









