








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
cat > /etc/chrony.conf << EOF
pool 192.168.0.31 iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
allow 192.168.0.0/24
local stratum 10
keyfile /etc/chrony.keys
leapsectz right/UTC
logdir /var/log/chrony
EOF
客户端
cat > /etc/chrony.conf << EOF
pool 192.168.0.31 iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
keyfile /etc/chrony.keys
leapsectz right/UTC
logdir /var/log/chrony
EOF
客服端和服务端,重启chrony,开机自启动
systemctl restart chronyd
systemctl enable chronyd
#客户端进行验证
chronyc sources -v
参数解释
pool ntp.aliyun.com iburst
指定使用ntp.aliyun.com作为时间服务器池,iburst选项表示在初始同步时会发送多个请求以加快同步速度。
driftfile /var/lib/chrony/drift
指定用于保存时钟漂移信息的文件路径。
makestep 1.0 3
设置当系统时间与服务器时间偏差大于1秒时,会以1秒的步长进行调整。如果偏差超过3秒,则立即进行时间调整。
rtcsync
启用硬件时钟同步功能,可以提高时钟的准确性。
allow 192.168.0.0/24
允许192.168.0.0/24网段范围内的主机与chrony进行时间同步。
local stratum 10
将本地时钟设为stratum 10,stratum值表示时钟的准确度,值越小表示准确度越高。
keyfile /etc/chrony.keys
指定使用的密钥文件路径,用于对时间同步进行身份验证。
leapsectz right/UTC
指定时区为UTC。
logdir /var/log/chrony
指定日志文件存放目录。
### 2.配置用户、权限
创建用户需使用 root 登录
useradd dolphinscheduler
添加密码
echo “dolphinscheduler” | passwd --stdin dolphinscheduler
配置 sudo 免密
sed -i ‘$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL’ /etc/sudoers
sed -i ‘s/Defaults requirett/#Defaults requirett/g’ /etc/sudoers
修改目录权限,使得部署用户对二进制包解压后的 apache-dolphinscheduler-*-bin 目录有操作权限
chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler--bin
chmod -R 755 apache-dolphinscheduler--bin
### 3.配置集群免密登陆
使用创建的 dolphinscheduler 登陆,配置hadoop31到hadoop32、hadoop33免密登陆
su dolphinscheduler
hadoop31节点,生成密钥
ssh-keygen -t rsa
hadoop31节点操作,配置向hadoop31、hadoop32、hadoop33节点免密
ssh-copy-id hadoop31
ssh-copy-id hadoop32
ssh-copy-id hadoop33
### 4.ZK集群启动
ZK集群安装,参考教程:[ZooKeeper集群的安装]( ),本文安装 ZK 版本为 3.8.3。参考教程中是 3.4.14,安装步骤都是一样样儿的,对应着来就可以了。
启动zk集群
bin/zkServer.sh start
### 5.初始化数据库
>
> 此处以 `MySQL` 为例
>
>
>
#### 1.创建数据库、用户、授权
>
> 此处可使用`root`用户,推荐单独创建一个用户`dolphinscheduler`
>
>
>
– 进入MySQL命令行
[root@hadoop01]# mysql -u root -p
Enter password: xxxxxx
– 创建 dolphinscheduler 数据库用户和密码,并限定登陆范围
mysql > CREATE USER ‘dolphinscheduler’@‘%’ IDENTIFIED BY ‘dolphinscheduler’;
– 创建 dolphinscheduler 的元数据,并指定编码
mysql > CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
– 为dolphinscheduler数据库授权
mysql > grant all privileges on dolphinscheduler.* to ‘dolphinscheduler’@‘%’;
– 刷新权限
mysql > flush privileges;
#### 2.解压缩安装包
将apache-dolphinscheduler-3.2.0-bin.tar.gz上传至/opt/targz目录下
解压
[root@hadoop31 targz]# tar zxvf ./apache-dolphinscheduler-3.2.0-bin.tar.gz
修改目录权限,使得部署用户对解压缩后的文件有操作权限
[root@hadoop31 targz]# chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler-3.2.0-bin
#### 3.添加MySQL驱动至libs目录
此处使用 MySQL 8.2.0版本,对应使用 JDBC 驱动为 `mysql-connector-j-8.2.0.jar`,将该驱动移动至 DolphinScheduler 的每个模块下的 libs 目录下。共5个目录:
* api-server/libs
* alert-server/libs
* master-server/libs
* worker-server/libs
* tools/libs
### 6.配置文件修改
#### 1.dolphinscheduler\_env.sh 配置
修改dolphinscheduler_env.sh
vim apache-dolphinscheduler-3.2.0-bin/bin/env/dolphinscheduler_env.sh
在文末添加以下配置:
JAVA_HOME, will use it to start DolphinScheduler server
JDK配置
export JAVA_HOME=${JAVA_HOME:-/opt/soft/jdk8}
Database related configuration, set database type, username and password
MySQL数据库配置
export DATABASE=
D
A
T
A
B
A
S
E
:
−
m
y
s
q
l
e
x
p
o
r
t
S
P
R
I
N
G
_
P
R
O
F
I
L
E
S
_
A
C
T
I
V
E
=
{DATABASE:-mysql} export SPRING\_PROFILES\_ACTIVE=
DATABASE:−mysqlexportSPRING_PROFILES_ACTIVE={DATABASE}
export SPRING_DATASOURCE_URL=“jdbc:mysql://192.168.17.28:3307/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false”
export SPRING_DATASOURCE_USERNAME=
S
P
R
I
N
G
_
D
A
T
A
S
O
U
R
C
E
_
U
S
E
R
N
A
M
E
:
−
"
d
o
l
p
h
i
n
s
c
h
e
d
u
l
e
r
"
e
x
p
o
r
t
S
P
R
I
N
G
_
D
A
T
A
S
O
U
R
C
E
_
P
A
S
S
W
O
R
D
=
{SPRING\_DATASOURCE\_USERNAME:-"dolphinscheduler"} export SPRING\_DATASOURCE\_PASSWORD=
SPRING_DATASOURCE_USERNAME:−"dolphinscheduler"exportSPRING_DATASOURCE_PASSWORD={SPRING_DATASOURCE_PASSWORD:-“dolphinscheduler”}
DolphinScheduler server related configuration
export SPRING_CACHE_TYPE=
S
P
R
I
N
G
_
C
A
C
H
E
_
T
Y
P
E
:
−
n
o
n
e
e
x
p
o
r
t
S
P
R
I
N
G
_
J
A
C
K
S
O
N
_
T
I
M
E
_
Z
O
N
E
=
{SPRING\_CACHE\_TYPE:-none} export SPRING\_JACKSON\_TIME\_ZONE=
SPRING_CACHE_TYPE:−noneexportSPRING_JACKSON_TIME_ZONE={SPRING_JACKSON_TIME_ZONE:-UTC}
export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}
Registry center configuration, determines the type and link of the registry center
zk注册中心
export REGISTRY_TYPE= R E G I S T R Y _ T Y P E : − z o o k e e p e r e x p o r t R E G I S T R Y _ Z O O K E E P E R _ C O N N E C T _ S T R I N G = {REGISTRY\_TYPE:-zookeeper} export REGISTRY\_ZOOKEEPER\_CONNECT\_STRING= REGISTRY_TYPE:−zookeeperexportREGISTRY_ZOOKEEPER_CONNECT_STRING={REGISTRY_ZOOKEEPER_CONNECT_STRING:-hadoop31:2181,hadoop32:2181,hadoop33:2181}
Tasks related configurations, need to change the configuration if you use the related tasks.
其他环境配置(此处只配置了hadoop、hive,其他环境未部署)
如果你不使用某些任务类型,可以忽略不做配置,使用默认即可。比如Flink不使用,不做处理即可
export HADOOP_HOME=
H
A
D
O
O
P
_
H
O
M
E
:
−
/
o
p
t
/
s
o
f
t
/
h
a
d
o
o
p
−
3.3.6
e
x
p
o
r
t
H
A
D
O
O
P
_
C
O
N
F
_
D
I
R
=
{HADOOP\_HOME:-/opt/soft/hadoop-3.3.6} export HADOOP\_CONF\_DIR=
HADOOP_HOME:−/opt/soft/hadoop−3.3.6exportHADOOP_CONF_DIR={HADOOP_CONF_DIR:-/opt/soft/hadoop-3.3.6/etc/hadoop}
export SPARK_HOME=
S
P
A
R
K
_
H
O
M
E
:
−
/
o
p
t
/
s
o
f
t
/
s
p
a
r
k
e
x
p
o
r
t
P
Y
T
H
O
N
_
L
A
U
N
C
H
E
R
=
{SPARK\_HOME:-/opt/soft/spark} export PYTHON\_LAUNCHER=
SPARK_HOME:−/opt/soft/sparkexportPYTHON_LAUNCHER={PYTHON_LAUNCHER:-/opt/soft/python}
export HIVE_HOME=
H
I
V
E
_
H
O
M
E
:
−
/
o
p
t
/
s
o
f
t
/
h
i
v
e
−
3.1.3
e
x
p
o
r
t
F
L
I
N
K
_
H
O
M
E
=
{HIVE\_HOME:-/opt/soft/hive-3.1.3} export FLINK\_HOME=
HIVE_HOME:−/opt/soft/hive−3.1.3exportFLINK_HOME={FLINK_HOME:-/opt/soft/flink}
export DATAX_LAUNCHER=${DATAX_LAUNCHER:-/opt/soft/datax/bin/python3}
export PATH= H A D O O P _ H O M E / b i n : HADOOP\_HOME/bin: HADOOP_HOME/bin:SPARK_HOME/bin: P Y T H O N _ L A U N C H E R : PYTHON\_LAUNCHER: PYTHON_LAUNCHER:JAVA_HOME/bin: H I V E _ H O M E / b i n : HIVE\_HOME/bin: HIVE_HOME/bin:FLINK_HOME/bin: D A T A X _ L A U N C H E R : DATAX\_LAUNCHER: DATAX_LAUNCHER:PATH
#### 2.install\_env.sh文件修改
修改install_env.sh
vim apache-dolphinscheduler-3.2.0-bin/bin/env/install_env.sh
按照集群部署方案,内容如下:
集群节点
ips=${ips:-“hadoop31,hadoop32,hadoop33”}
ssh免密端口,使用默认
sshPort=${sshPort:-“22”}
master节点
masters=${masters:-“hadoop31,hadoop32”}
worker节点
workers=${workers:-“hadoop31:default,hadoop32:default,hadoop33:default”}
alert节点
alertServer=${alertServer:-“hadoop33”}
api节点
apiServers=${apiServers:-“hadoop31”}
dolphinscheduler实际安装路径
installPath=${installPath:-“/opt/soft/dolphinscheduler-3.2.0”}
部署dolphinscheduler使用的用户名
deployUser=${deployUser:-“dolphinscheduler”}
zk根节点
zkRoot=${zkRoot:-“/dolphinscheduler”}
### 7.初始化元数据
切换到apache-dolphinscheduler-3.2.0-bin目录下,执行命令
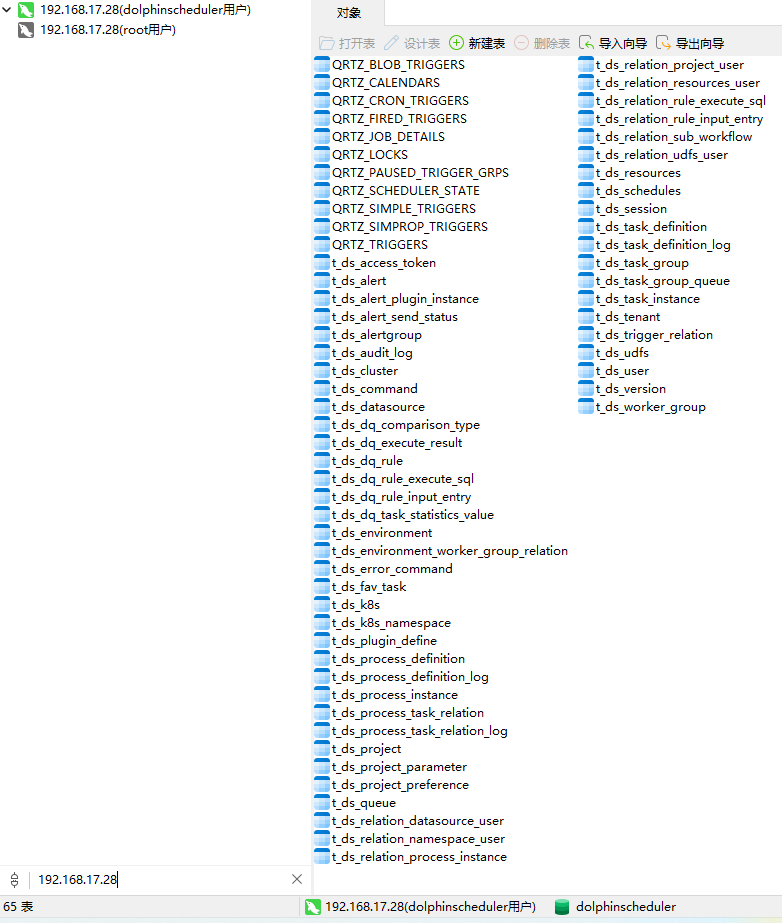
[root@hadoop31 apache-dolphinscheduler-3.2.0-bin]# sh ./tools/bin/upgrade-schema.sh
此操作,会向MySQL数据库写入元数据,共计65张表,如图所示:
### 8.安装DS
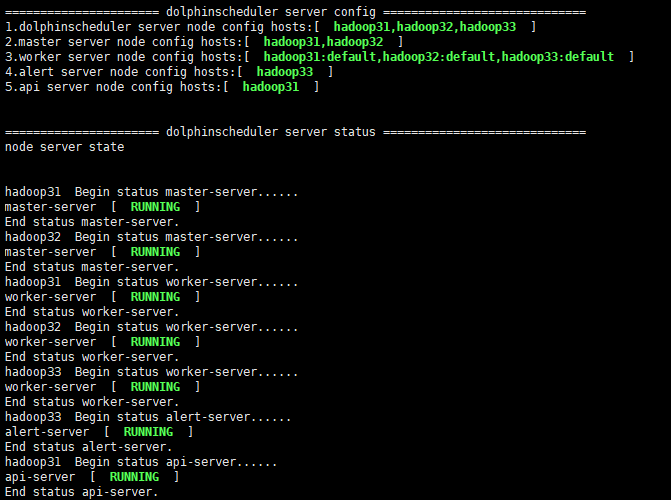
执行install.sh部署命令
[root@hadoop31 apache-dolphinscheduler-3.2.0-bin]# ./bin/install.sh
当看到下图时,说明 DS 安装完成
**提示:**



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
7m3Cv5-1715745510527)]
[外链图片转存中...(img-oZEz7yBt-1715745510527)]
[外链图片转存中...(img-nZwuk25N-1715745510528)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









