







算法
-
冒泡排序
-
选择排序
-
快速排序
-
二叉树查找: 最大值、最小值、固定值
-
二叉树遍历
-
二叉树的最大深度
-
给予链表中的任一节点,把它删除掉
-
链表倒叙
-
如何判断一个单链表有环

由于篇幅限制小编,pdf文档的详解资料太全面,细节内容实在太多啦,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
如果你觉得对你有帮助,可以戳这里获取:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
-
单点故障:如果事务管理器出现了故障,整个系统将不可用
-
同步阻塞:延迟了提交事件,加长了资源阻塞事件,不适合高并发的场景
-
数据不一致:如果执行到第二阶段,依然存在commit结果未知的情况,只有部分参与者接收到 commit 消息,部分没有收到,那也只有部分参与者提交了事务,依然会导致数据不一致问题
方法二:三阶段提交
=========
既然两阶段提交解决不了问题,那我们就来三阶段提交。三阶段提交相对于两阶段提交来说增加了 ConCommit 阶段和超时机制。在一段规定时间内,如果服务器参与者没有接受到来自事务管理器的提交执行,那他们就会自己自动提交,这样子就能解决两阶段中单体故障问题。
我们来看看三阶段提交是哪三阶段:
-
CanCommit:准备阶段。这个阶段要做的事就和两阶段提交一样,先去询问参与者是否有条件接收这个事务,这样子不会太暴力,一开始就直接干活锁死资源。
-
PreCommit:这个阶段是事务管理器向各个参加者发送准备提交请求,各个参与者接到请求或,将处理结果记录到自己的资源管理器中,如果准备好了,就会想协调者反馈ACK表示我已经准备好提交了。
-
DoCommit:这个就断就是从 预提交状态 转为 提交状态。事务管理器向各个参与者发送 提交 请求,参与者接收到请求后,就会各自执行自己事务的提交操作。将处理结果记录到自己的资源管理器中,并向协调者反馈 ACK 表示自己已经完成事务,如果有一个参与者未完成PreCommit的反馈或者反馈超时,那么协调者都会向所有的参与者节点发送abort请求,从而中断事务。
其实三阶段提交看起来就是把两阶段提交中的提交阶段变成了 预提交阶段 和 提交阶段。
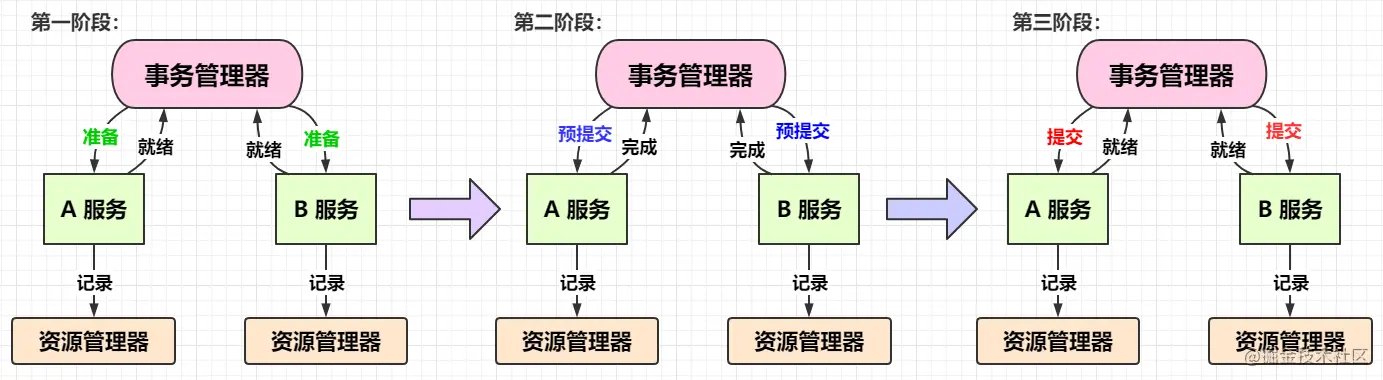
那其实从上面可以看到,三阶段提交解决的只是两阶段提交中 单体故障 的问题,因为加入了超时机制,这里的超时的机制作用于 预提交阶段 和 提交阶段。如果等待 预提交请求 超时,那参与者相当于说啥都没干,直接回到准备阶段之前。如果等到提交请求超时,那参与者就会提交事务了。
所以可以看到其实 三阶段提交还是没根本解决问题,虽然比两阶段提交进步了一点点~
方法三:TCC
=======
TCC(Try Confirm Cancel) ,它是属于补偿型分布式事务。它的核心思想是 针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。TCC 实现分布式事务一共有三个步骤:
- Try:尝试待执行的业务
这个过程并未执行业务,只是完成所有业务的一致性检查,并预留好执行所需的所有资源
- Confirm:确认执行业务
确认执行业务的操作,不做任何业务检查,只使用Try阶段预留的业务资源。通常情况下,采用TCC则会认为 Confirm 阶段是不会出错的。只要 Try 成功,则 Confirm 一定成功。如果 Confirm 出错了,则需要引入重试机制或人工处理
- Cancel:取消待执行的业务
取消 Try 阶段预留的业务资源。通常情况下,采用 TCC 则认为 Cancel 阶段也是一定能成功的,若 Cancel 阶段真的出错了,也要引入重试机制或人工处理
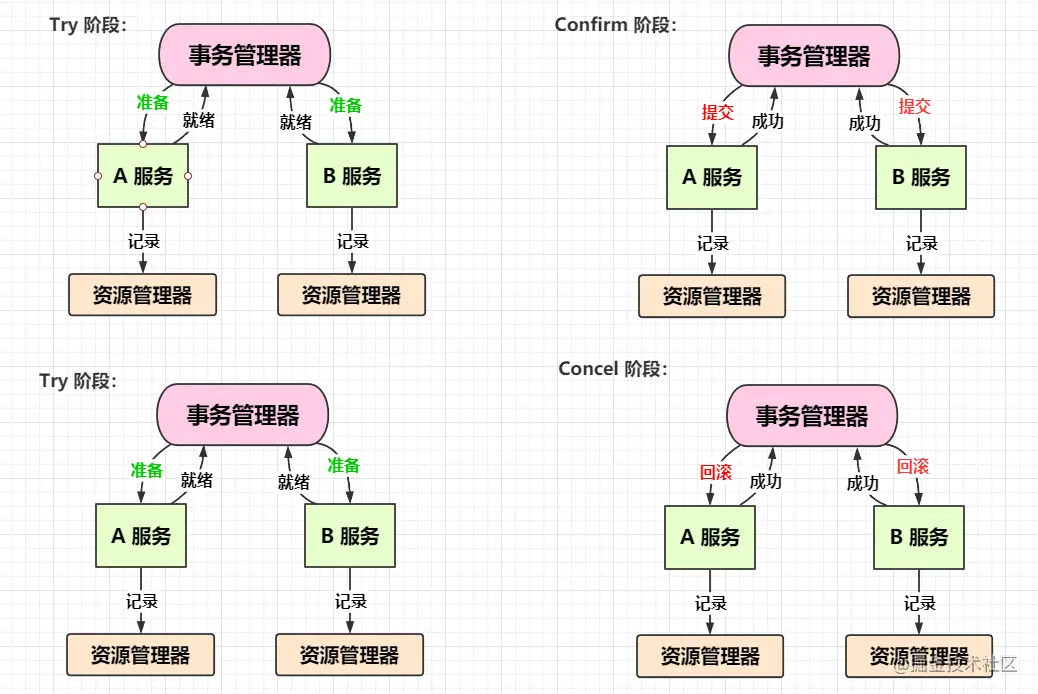
TCC 是业务层面的分布式事务,最终一致性,不会一直持有资源的锁。它的优缺点如下:
优点: 吧数据库层的二阶段提交上提到了应用层来实现,规避了数据库的 2PC 性能低下问题
缺点:TCC 的 Try、Confirm 和 Cancel 操作功能需业务提供,开发成本高。TCC 对业务的侵入较大和业务紧耦合,需要根据特定的场景和业务逻辑来设计相应的操作
方法五:可靠消息事务
==========
消息事务的原理是 将两个事务通过消息中间件来进行异步解耦。基于可靠消息服务的方案是通过消息中间件来保证上、下游应用数据操作的一致性。假设有 A、B两个服务,分布可以处理 A、B两个任务,此时需要存在一个业务流程,将任务 A和B 放到同一个事物中处理,这种方式就可以借助消息中间件来实现。
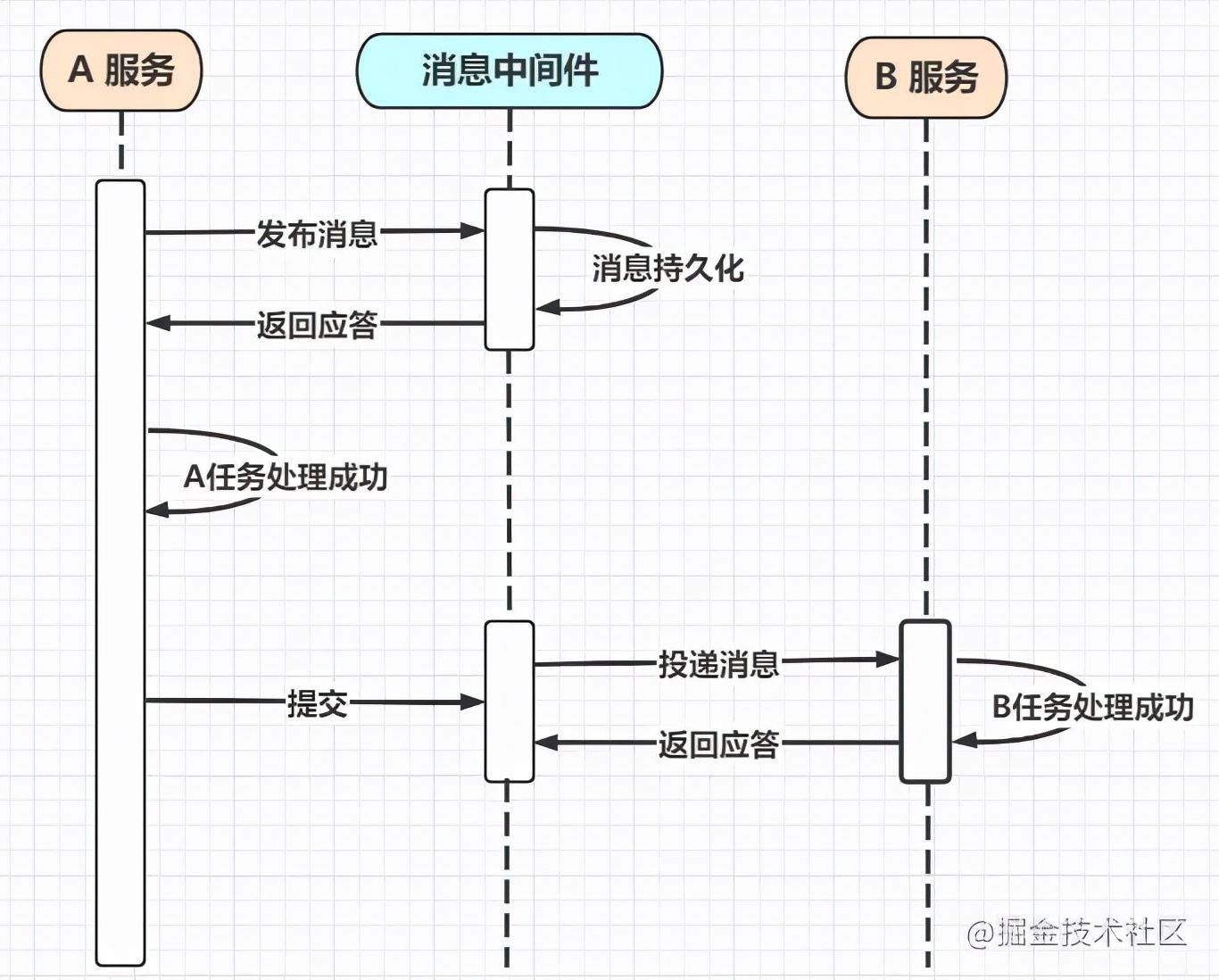
整体上可以分为两个大的步骤:A服务向消息中间件发布消息 和 消息向B服务投递消息
步骤一: A 服务向消息中间件发布消息
-
在服务A处理任务A前,首先向消息中间件发送一条半信息
-
消息中间件收到后将该消息持久化,但不进行投递。持久化成功后,向A服务返回确认应答
-
服务A收到确认应答后,便可以开始处理任务A
-
任务A处理完成后,服务A便会向消息中间件发送Commit 或者 Rollback 请求,该请求发送完成后,服务A的工作任务就结束了,该事务的处理过程也就结束了
-
在消息中间件收到 Commit 后,便会向 B 服务投递消息,如果收到 Rollback 便会直接丢弃消息
如果消息中间件在最后的过程中,长时间没有收到服务A 发送的 Commit 或 Rollback 指令,这个时候就需要依靠 超时询问机制
超时询问机制:
服务A除了实现正常的业务流程之外,还是需要提供一个可供消息中间件事务询问的接口。在消息中间件第一次收到消息后便会开始计时,如果超过规定的时间没有收到后续的指令,就会主动调用服务A提供的事务询问接口,询问当前服务的状态,通常来说该接口会返回三种结果,中间件需要根据这三种不同的结果做出不同的处理:
提交:直接将该消息投递给服务B 回滚:直接将该消息丢弃 处理中:继续等待,重新计时
步骤二: 消息中间件向B服务投递消息
消息中间件收到A服务的提交 Commit指令后便会将该消息投递给B服务,然后将自己的状态置为阻塞等待状态。B服务收到消息中间件发送的消息后便开始处理任务B,处理完成后便会向消息中间件发出回应。但是在消息中间件阻塞等待的时候同样会出现问题
-
正常情况:消息中间件投递完消息后,进入阻塞等待状态,在收到确认应答后便认为事务处理完成,该流程结束
-
等待超时情况:在等待确认应答超时之后就会重新进行投递,直到B服务器返回消费成功响应为止。而消息重试的次数和时间间隔都可以设置,如果最终还是不能成功进行投递,则需要人工干预。
可靠消息服务方案是实现了 最终一致性。对比本地消息表实现方案,不需要再建立消息表。不用依赖本地数据库事务,适用于高并发的场景。RocketMQ 就很好的支持了消息事务。
方法四:最大努力通知
==========
最大努力通知也成为定期校对,是对可靠消息服务的进一步优化。它引入了本地消息表来记录错误消息,然后加入失败消息的定期校对功能,来进一步保证消息会被下游服务消费。
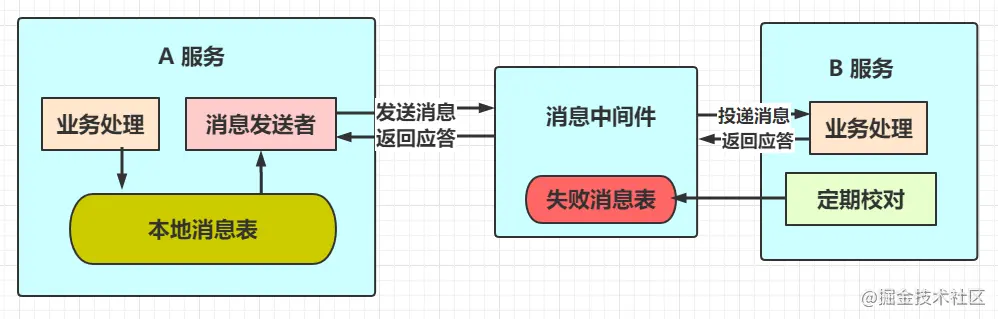
同样的这个跟消息事务一样可以分为两步:
步骤一: 服务A向消息中间件发送消息
-
在处理业务的同一个事务中,向本地消息表写入一条记录
-
消息发送者不断取出本地消息表中的消息发送到消息中间件,如果发送失败则进行重试
步骤二: 消息中间件向服务B投递消息
-
消息中间件收到消息后便会将消息投递到下游服务B,服务B收到消息后便会执行自己的业务
-
当服务B业务处理成功后,便会向消息中间件返回反馈应答,消息中间件便可将该消息删除,该流程结束
-
如果消息中间件向服务B投递消息失败,便会尝试重试,如果重试失败,便会将该消息接入失败消息表中
-
消息中间件同样需要提供查询失败消息的接口,服务B 定期查询失败信息,并进行消费
最大努力通知的方案实现比较简单,适用于一些最终一致性要求比较低的业务。
Seata
=====
Seata概念
=======
既然分布式事务处理起来这么麻烦,那能不能让分布式事务处理起来像本地事务那么简单。当然这是我们的愿景。当然这个愿景是所有开发人员所希望的。而阿里巴巴团队就为这个愿景做出了行动,发起了开源项目 Seata(Simple Extensible Autonomous Transaction Architecture) 。这是一套分布式事务解决方案,意在解决开发人员遇到的分布式事务各方面的难题。
Seata 的设计目标是对业务无侵入,因此它是从业务无侵入的两阶段提交(全局事务)着手,在传统的两阶段上进行改进,他把一个分布式事务理解成一个包含了若干分支事务的全局事务。而全局事务的职责是协调它管理的分支事务达成一致性,要么一起成功提交,要么一起失败回滚。也就是一荣俱荣一损俱损~
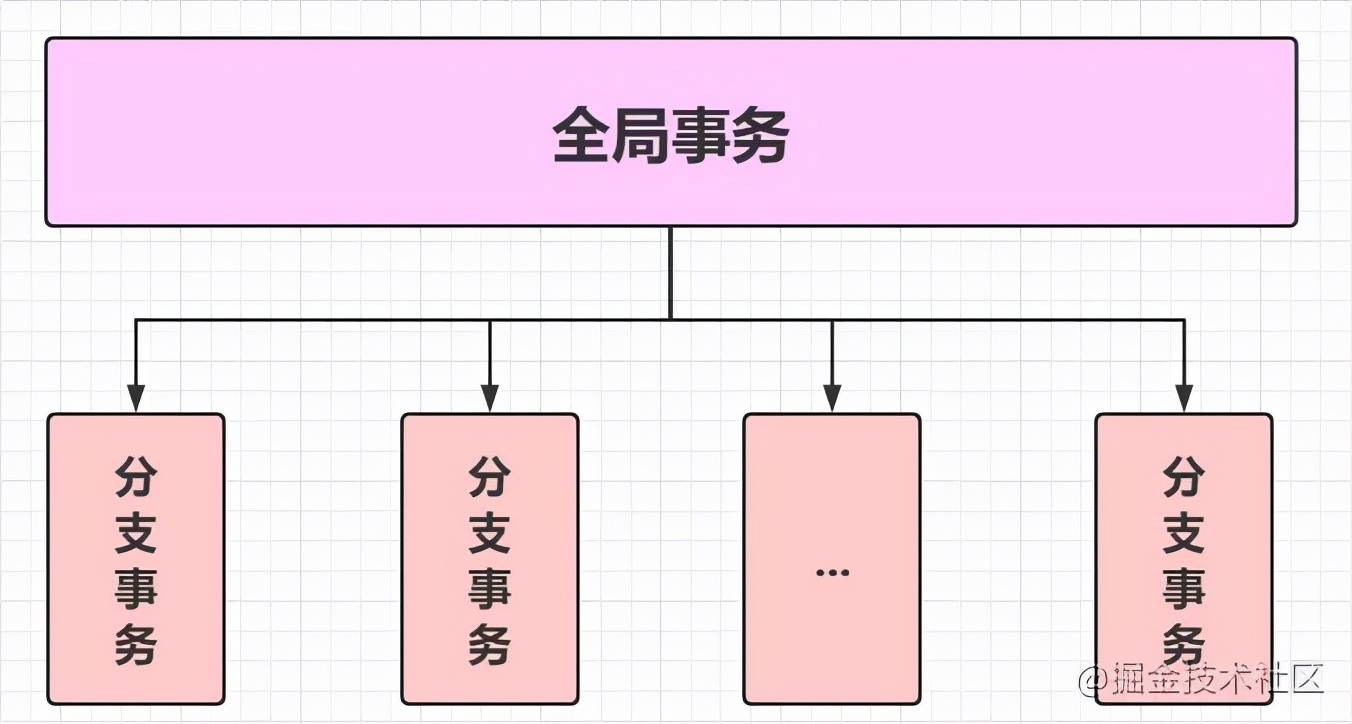
Seata 组成
========
我们看下 Seata 中存在几种重要角色:
-
TC(Transaction Coordinator):事务协调者。管理全局的分支事务的状态,用于全局性事务的提交和回滚。
-
TM(Transaction Manager):事务管理者。用于开启、提交或回滚事务。
-
RM(Resource Manager):资源管理器。用于分支事务上的资源管理,向 TC 注册分支事务,上报分支事务的状态,接收 TC 的命令来提交或者回滚分支事务。
这是一种很巧妙的设计,我们来看图:
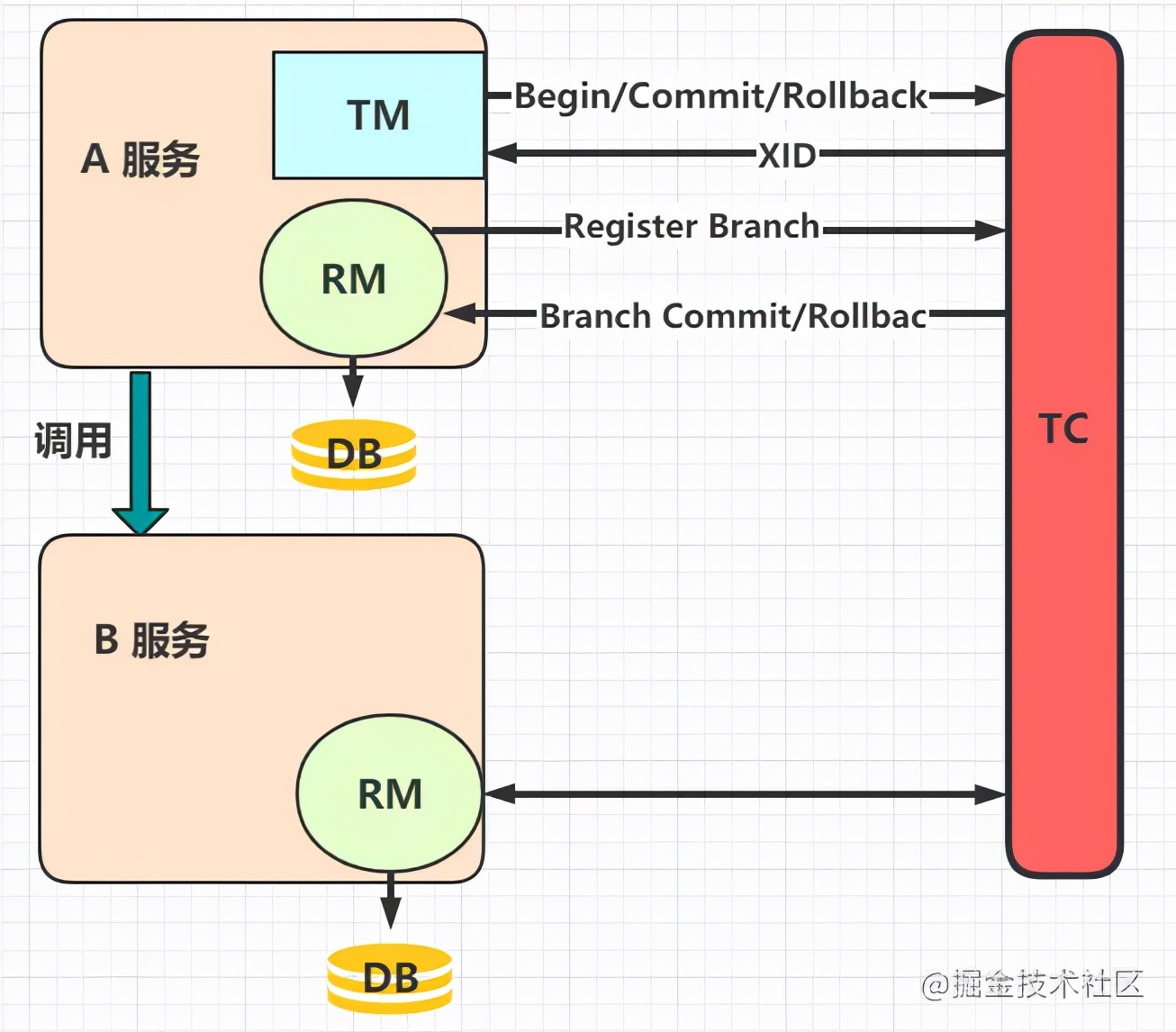
执行流程是这样的:
-
服务A中的 TM 向 TC 申请开启一个全局事务,TC 就会创建一个全局事务并返回一个唯一的 XID
-
服务A中的 RM 向 TC 注册分支事务,然后将这个分支事务纳入 XID 对应的全局事务管辖中
-
服务A开始执行分支事务
-
服务A开始远程调用B服务,此时 XID 会根据调用链传播
-
服务B中的 RM 也向 TC 注册分支事务,然后将这个分支事务纳入 XID 对应的全局事务管辖中
-
服务B开始执行分支事务
-
全局事务调用处理结束后,TM 会根据有误异常情况,向 TC 发起全局事务的提交或回滚
-
TC 协调其管辖之下的所有分支事务,决定是提交还是回滚
Seata使用
=======
我们从上面了解到了 Seata 的组成和执行流程,我们接下来就来实际的使用下 Seata。
示例演示
====
我们简单创建了一个微服务项目,其中有订单服务和库存服务。
我们这里采用了 nacos 作为注册中心,分别启动两个服务,我们在nacos控制台可以看到两个已经注册的服务:

号外:如果对nacos还不熟悉的小伙伴可以跳转查看 nacos讲解:微服务新秀之Nacos
我们接着创建了一个数据库,其中有两张表:c_order 和 c_product,其中商品表中有一条数据,而订单表中还未有数据,接下来我们将要对其进行操作!

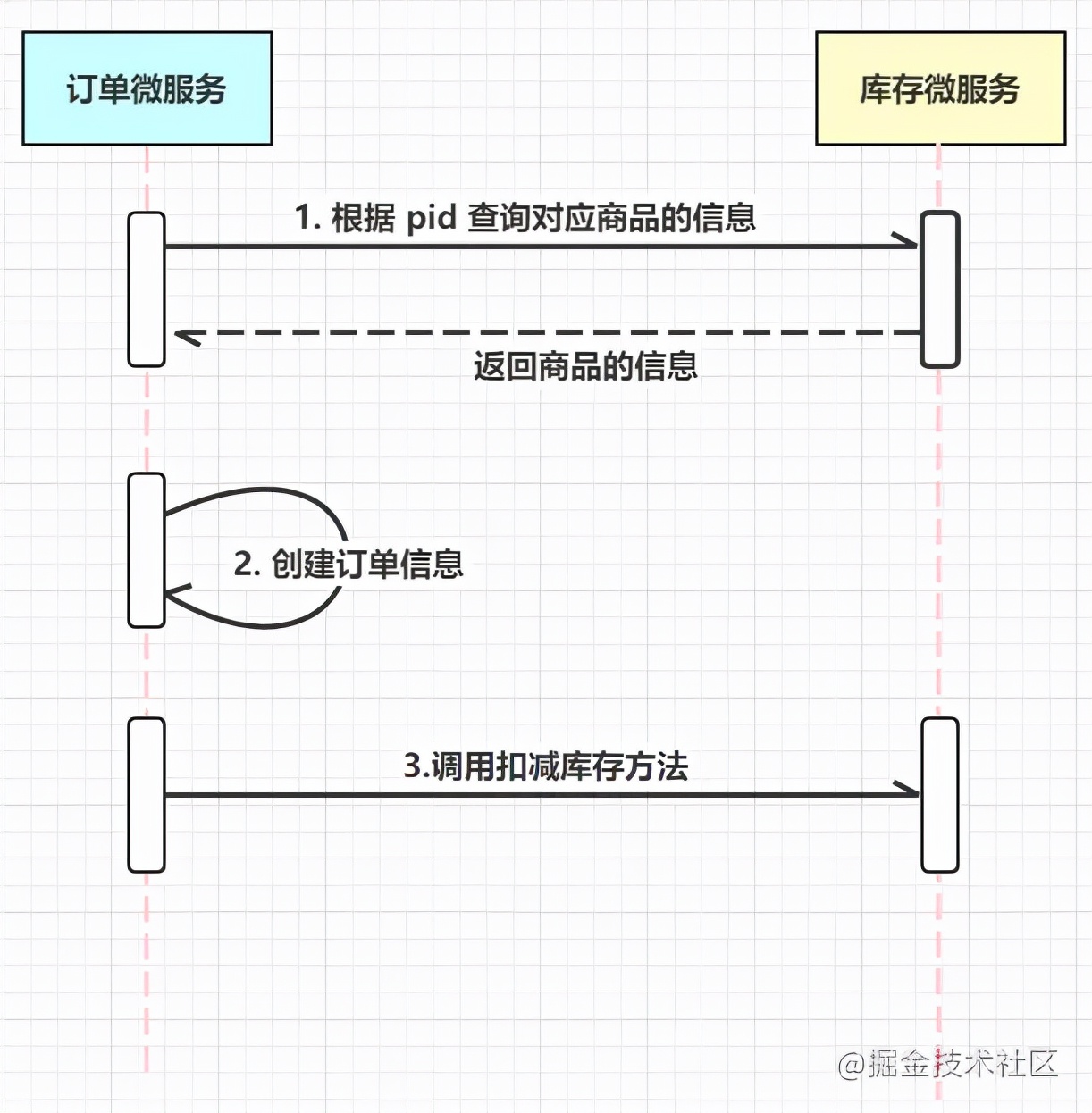
我们现在模拟一个下单的过程:
-
请求进来,通过商品 pid 往数据库中查商品的信息
-
创建一条该商品的订单
-
对应扣减该商品的库存量
-
流程结束
我们接下来就进入代码演示一下:
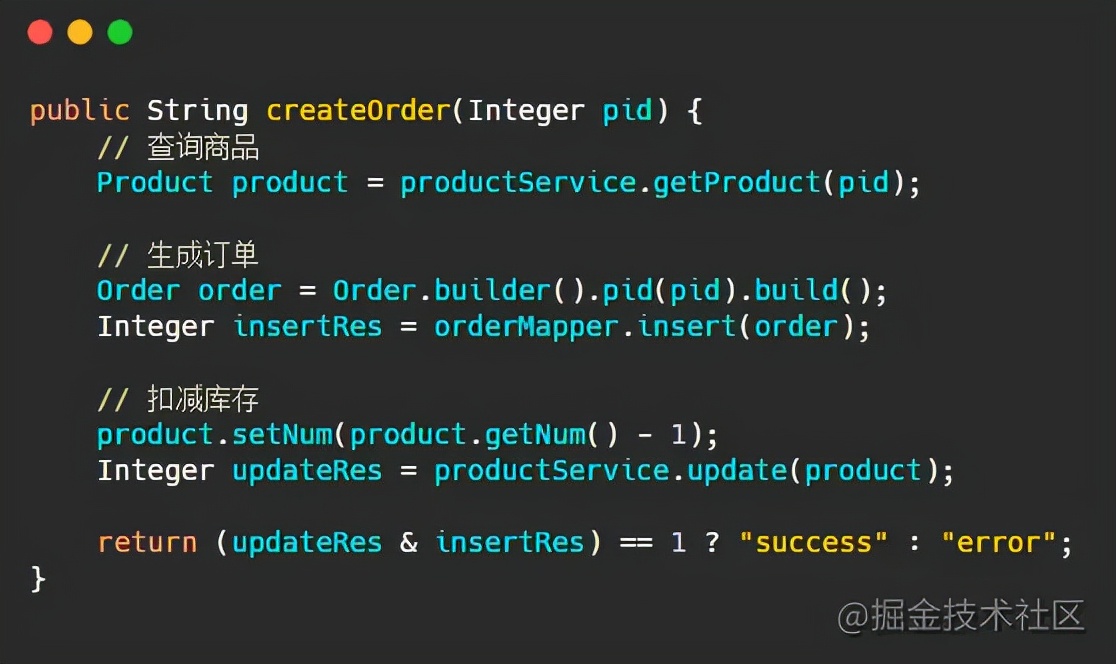
注意:这里 ProductService 并非是库存服务里面的类,而是利用 Feign 远程调用库存服务的接口
代码三步走,正常请况下肯定是没有问题的:
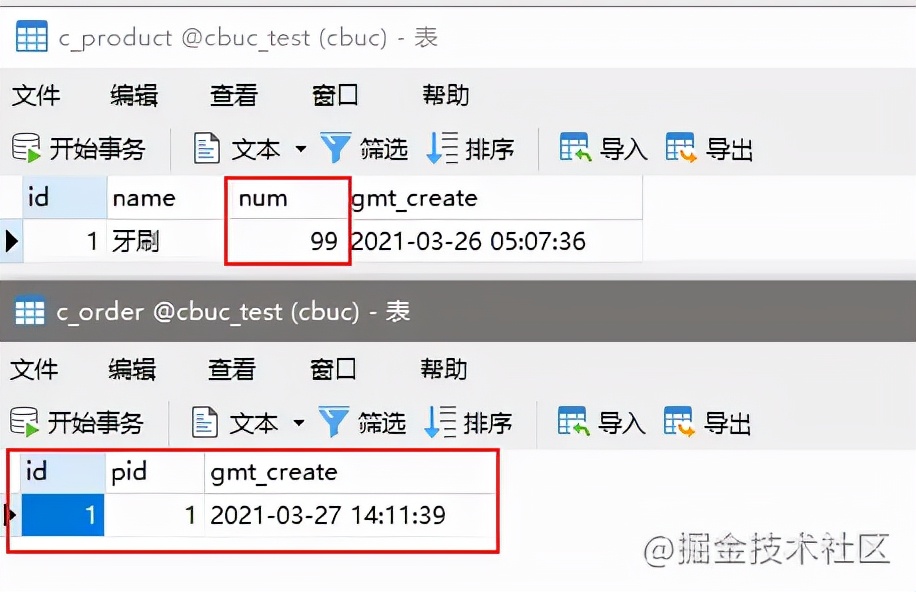
订单生成,库存也对应减少,感觉自己代码可以上线进入正轨的时候,我们来模拟一下库存中的异常,库存商品数量归为 100,订单表清空:

我们继续发送下单请求,可以看到库存服务已经抛出了异常

正常来说这个时候,库存表数量不应该减少,订单表不应该插入订单数据,但是事实真的是这样的吗?我们看数据:
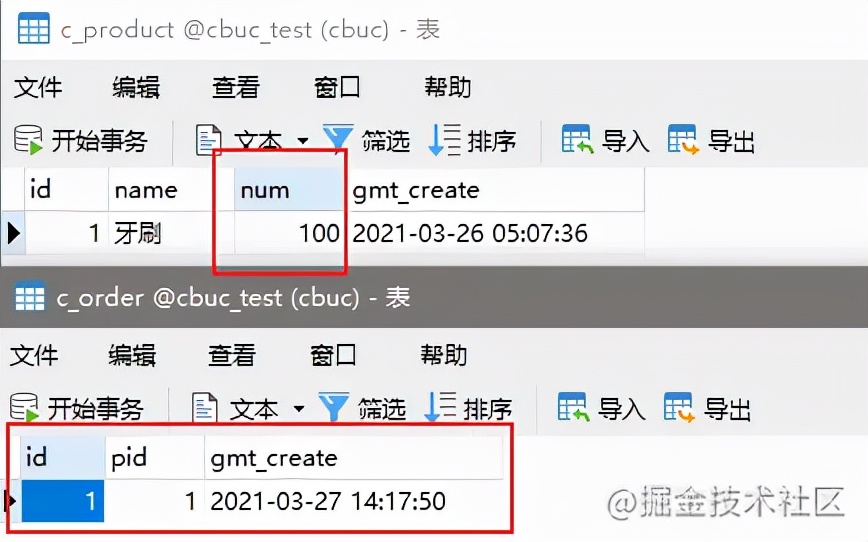
库存数量没减,但是订单却增加了。好了,到这里,你就已经见识到了分布式事务的灾难性危害。接下来主角登场!
Seata 安装
========
我们首先需要点击下载地址进行下载 Seata。
由于我们是使用 nacos 作为服务中心和配置中心,因此我们下载解压后需要做一些修改操作
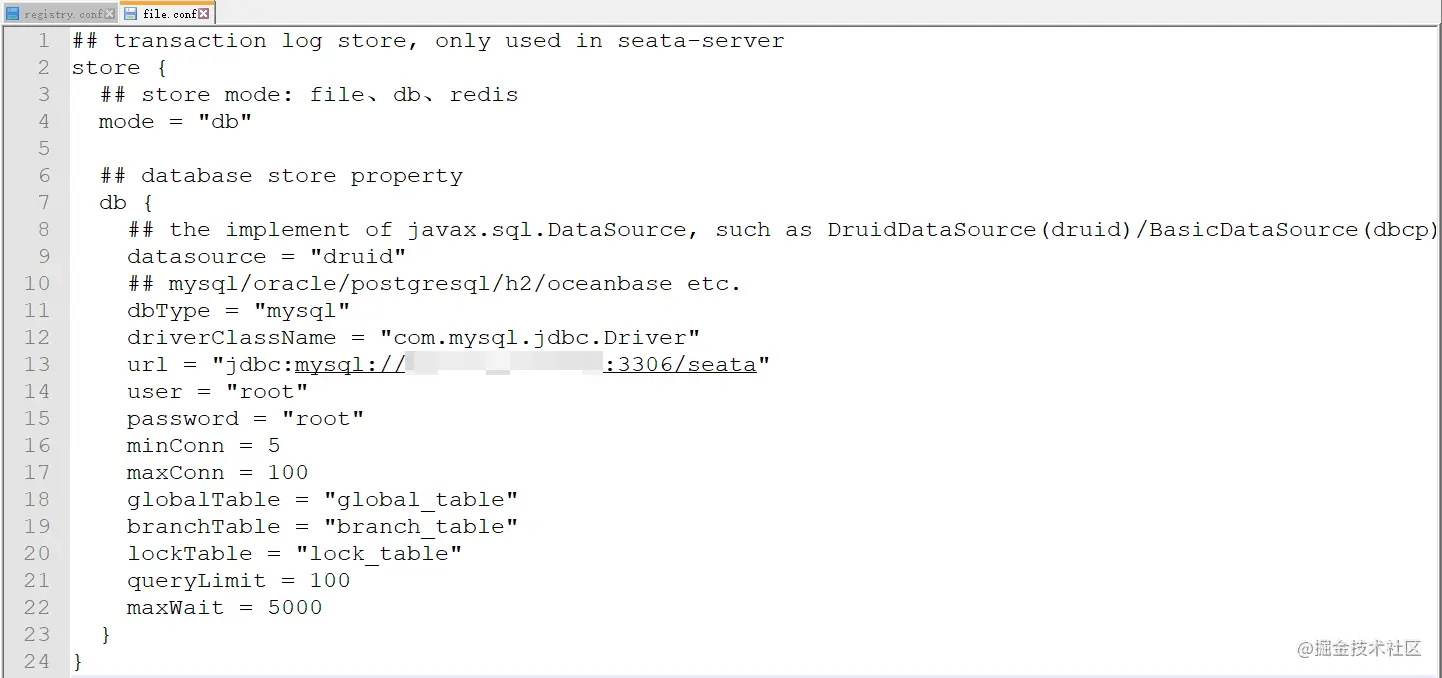
- 进入 conf 目录编辑 registry.conf 和 file.conf 两个文件,编辑后内容如下:

- 由于新版 Seata 中没有 nacos-conf.sh 和 config.txt 两个文件,因此我们需要独立下载:
nacos-config.sh 下载地址
config.txt 下载地址
我们需要将 config.txt 文件放到 seata 目录下,而非 conf 目录下,并且需要修改 config.txt 内容
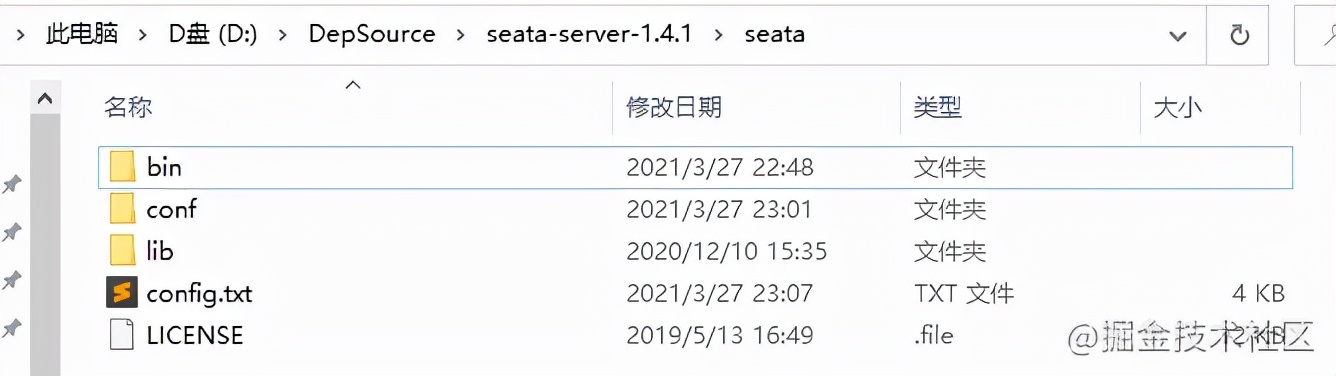

config.txt就是seata各种详细的配置,执行 nacos-config.sh 即可将这些配置导入到nacos,这样就不需要将file.conf和registry.conf放到我们的项目中了,需要什么配置就直接从nacos中读取。
- 执行导入
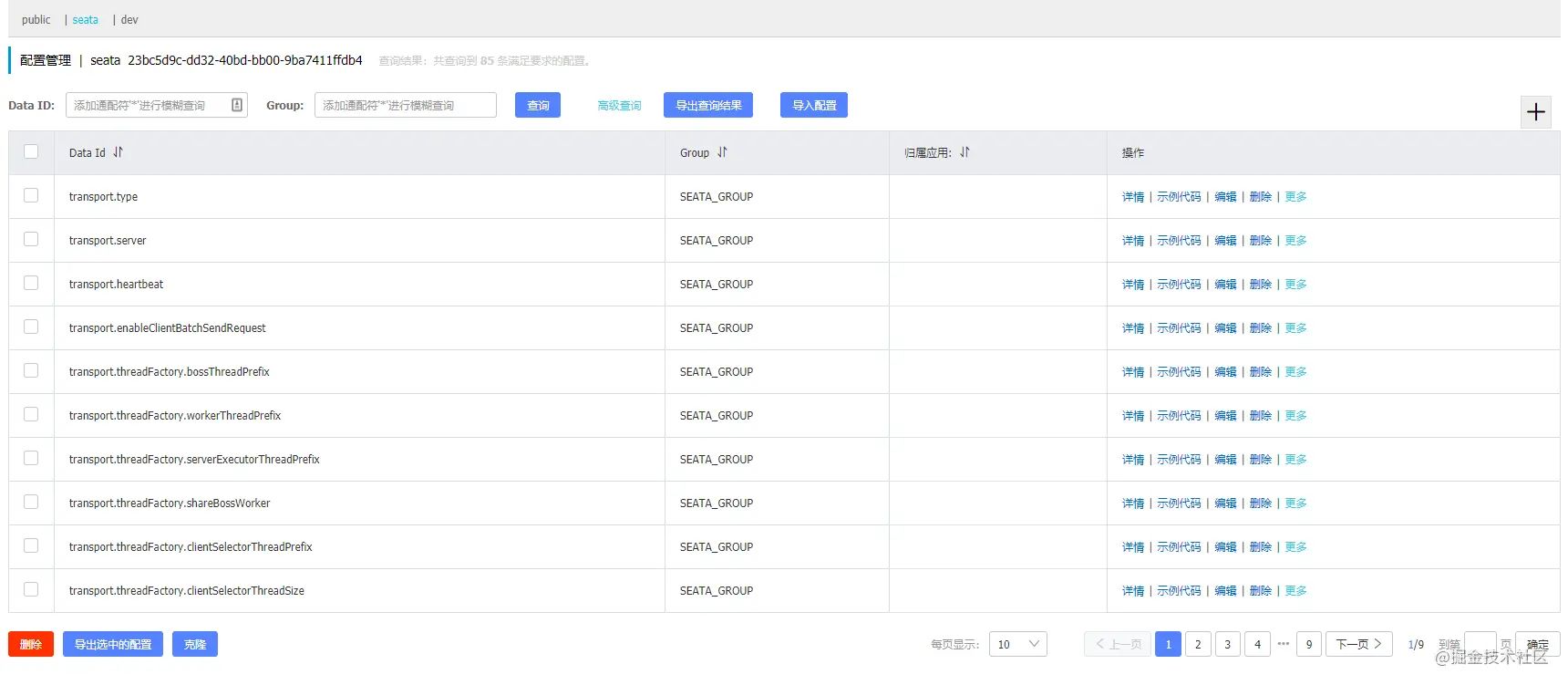
在 conf 目录下打开 git bash 窗口,执行以下命令:
sh nacos-config.sh -h localhost -p 8848 -g SEATA_GROUP -t namespace-id(需要替换) -u nacos -w nacos
复制代码
操作结束后,我们便可以在 nacos 控制台中看到配置列表,日后配置有需要修改便可以直接从这边修改,而不用修改目录文件:
- 数据库配置
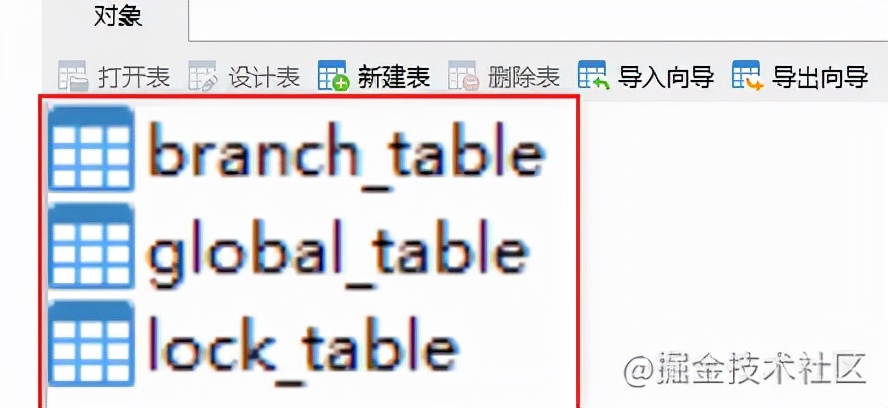
在 1.4.1 最新版中依然没有 sql 文件,所以我们还是需要另外下载:sql 下载地址
在 seata 数据中执行这个文件,生成三张表:
在我们的业务数据库中执行 undo_log 这张表:
CREATE TABLE undo_log
(
id BIGINT(20) NOT NULL AUTO_INCREMENT,
branch_id BIGINT(20) NOT NULL,
xid VARCHAR(100) NOT NULL,
context VARCHAR(128) NOT NULL,
rollback_info LONGBLOB NOT NULL,
log_status INT(11) NOT NULL,
log_created DATETIME NOT NULL,
log_modified DATETIME NOT NULL,
ext VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (id),
UNIQUE KEY ux_undo_log (xid, branch_id)
) ENGINE = INNODB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8;
复制代码
- 添加 log 文件
如果我们没有log输出文件,启动 seata 可能会报错,因此我们需要在 seata 目录下创建 logs 文件夹,在 logs 文件下创建 seata_gc.log 文件

- 启动
做好了以上准备,我们便可以启动 seata 了,直接在 bin 目录下 cmd 执行 bat 脚本即可,启动结束便可在 nacos 中看到 seata 服务:

Seata 集成
========
在 Seata 安装的步骤中我们便完成了 Seata 服务端 的启动安装,接下来就是在项目中集成 Seata 客户端
- 第一步:我们需要在 pom.xml 文件中添加两个依赖:seata 依赖 和 nacos 配置依赖
com.alibaba.cloud
spring-cloud-starter-alibaba-nacos-config
com.alibaba.cloud
spring-cloud-starter-alibaba-seata
io.seata
seata-all
io.seata
seata-spring-boot-starter
io.seata
seata-all
1.4.1
io.seata
最后
前端CSS面试题文档,JavaScript面试题文档,Vue面试题文档,大厂面试题文档
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】


oupId>io.seata
seata-all
io.seata
seata-spring-boot-starter
io.seata
seata-all
1.4.1
io.seata
最后
前端CSS面试题文档,JavaScript面试题文档,Vue面试题文档,大厂面试题文档
开源分享:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
[外链图片转存中…(img-t01E8ieg-1715479791487)]
[外链图片转存中…(img-zEhVBBoP-1715479791488)]















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









