






Kafka 工作流程及文件存储机制
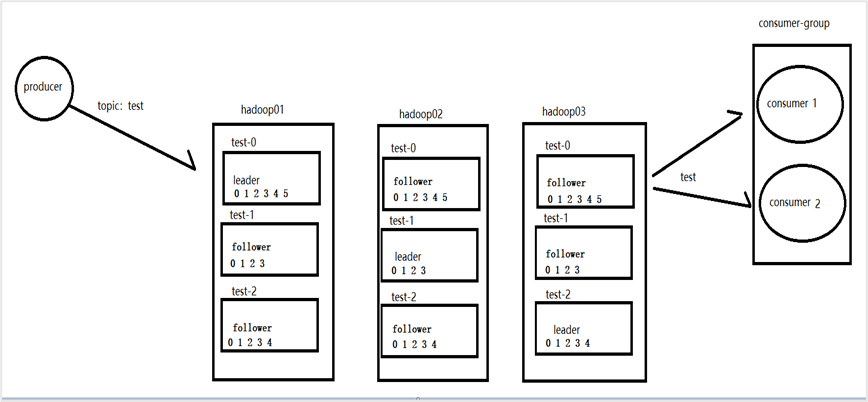
Kafka 中消息是以topic 进行分类的,生产者生产消息,消费者消费消息,都是面向topic 的。
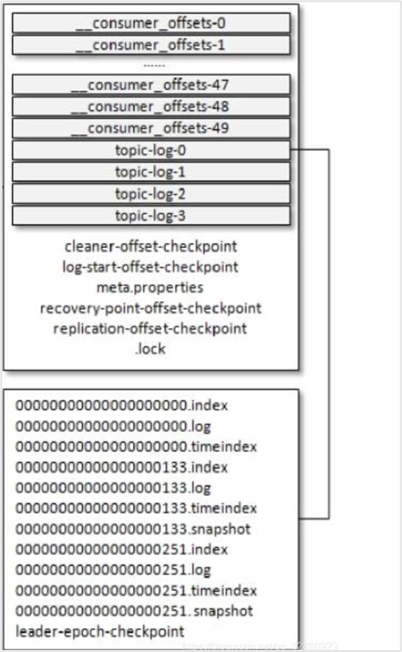
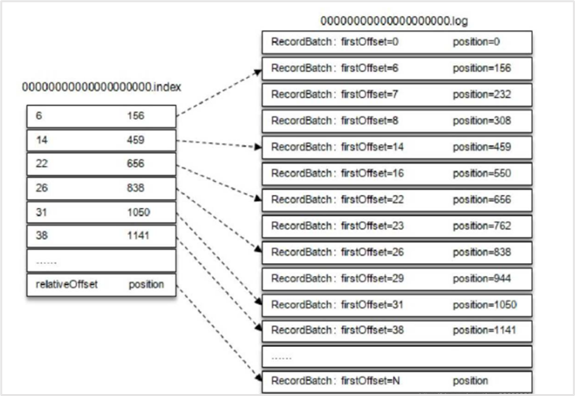
“.log”文件存储大量的数据,“.index”文件存储偏移量索引信息,“.timeindex”存储时间戳索引文件。日志文件和索引文件都是根据基本偏移量(LogSegment中的第一条消息的offset)来命名的。上图第2个LogSegment对应的基本偏移量是133,说明了第1个LogSegment中共有133条数据。
Kafka 生产者
作为生产者生成数据,并使用其他组件来采集数据。
分区的原则

(1)指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
(2)没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
(3)既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说的 round-robin (轮询)算法。
Kafka的ACKS机制
ACKS机制的三种级别:0、1和-1。
acks 参数配置:
0:producer 不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker 一接收到还没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
1:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower同步成功之前 leader 故障,那么将会丢失数据;
-1(all):producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盘成功后才返回 ack。但是如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会造成数据重复。
DStream转换
DStream 上的操作与 RDD 的类似,分为 Transformations(转换)和 Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种 Window 相关的原语。
无状态转换操作
无状态转换操作是对每个批次的RDD进行的一系列操作。(即对每个批次的数据进行相同的转换操作。)
常见的无状态转换操作示例,如map、flatMap、filter等。

Transform操作
Transform 允许 DStream 上执行任意的 RDD-to-RDD 函数。即使这些函数并没有在 DStream的 API 中暴露出来,通过该函数可以方便的扩展 Spark API。该函数每一批次调度一次。其实也就是对 DStream 中的 RDD 应用转换。
( Transform操作允许执行任意的RDD到RDD的函数。)
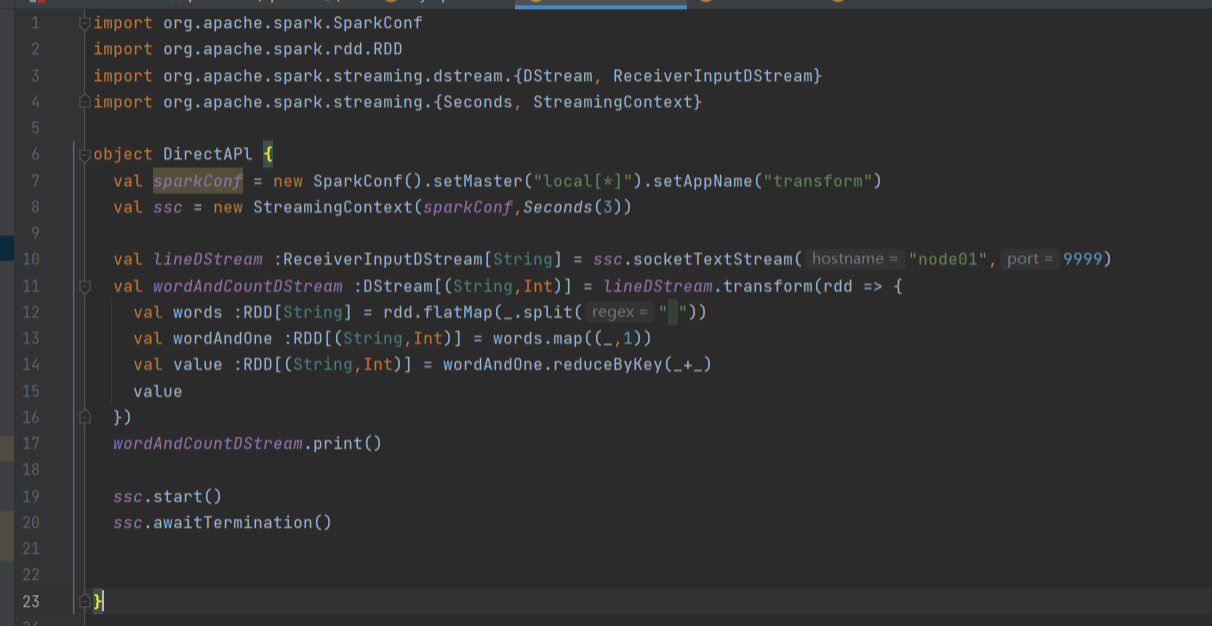

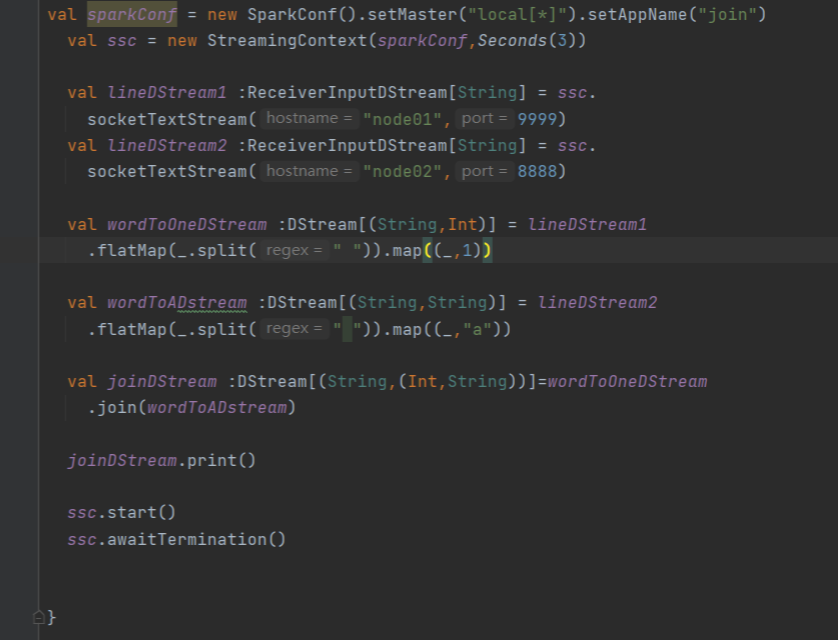
Join操作
Join操作是将两个流的RDD进行关联,并对相同键的值进行合并。
Join操作的硬性要求,即两个流的批次大小必须一致。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









