







pv_pay = behavior[behavior[‘user_id’].isin(user_pay)][‘type’].value_counts().pv
消费用户数占比
user_pay_rate = len(user_pay) / uv
消费用户访问量占比
pv_pay_rate = pv_pay / pv
消费用户人均访问量
pv_per_buy_user = pv_pay / len(user_pay)
复制代码
SQL
SELECT count(DISTINCT user_id) UV,
(SELECT count(*) PV from behavior_sql WHERE type = ‘pv’) PV
FROM behavior_sql;
SELECT count(DISTINCT user_id)
FROM behavior_sql
WHERE WHERE type = ‘pay’;
SELECT type, COUNT(*) FROM behavior_sql
WHERE
user_id IN
(SELECT DISTINCT user_id
FROM behavior_sql
WHERE type = ‘pay’)
AND type = ‘pv’
GROUP BY type;
复制代码
print(‘总访问量为 %i’ %pv)
print(‘总访客数为 %i’ %uv)
print(‘消费用户数为 %i’ %len(user_pay))
print(‘消费用户访问量为 %i’ %pv_pay)
print(‘日均访问量为 %.3f’ %pv_per_day)
print(‘人均访问量为 %.3f’ %pv_per_user)
print(‘消费用户人均访问量为 %.3f’ %pv_per_buy_user)
print(‘消费用户数占比为 %.3f%%’ %(user_pay_rate * 100))
print(‘消费用户访问量占比为 %.3f%%’ %(pv_pay_rate * 100))
复制代码
OUTPUT
总访问量为 6229177
总访客数为 728959
消费用户数为 395874
消费用户访问量为 3918000
日均访问量为 389323.562
人均访问量为 8.545
消费用户人均访问量为 9.897
消费用户数占比为 54.307%
消费用户访问量占比为 62.898%
复制代码
消费用户人均访问量和总访问量占比都在平均值以上,有过消费记录的用户更愿意在网站上花费更多时间,说明网站的购物体验尚可,老用户对网站有一定依赖性,对没有过消费记录的用户要让快速了解产品的使用方法和价值,加强用户和平台的黏连。
* 跳失率
跳失率:只进行了一次操作就离开的用户数/总用户数
attrition_rates = sum(behavior.groupby(‘user_id’)[‘type’].count() == 1) / (behavior[‘user_id’].nunique())
复制代码
SQL
SELECT
(SELECT COUNT(*)
FROM (SELECT user_id
FROM behavior_sql GROUP BY user_id
HAVING COUNT(type)=1) A) /
(SELECT COUNT(DISTINCT user_id) UV FROM behavior_sql) attrition_rates;
复制代码
print(‘跳失率为 %.3f%%’ %(attrition_rates * 100) )
复制代码
OUTPUT
跳失率为 22.585%
复制代码
整个计算周期内跳失率为22.585%,还是有较多的用户仅做了单次操作就离开了页面,需要从首页页面布局以及产品用户体验等方面加以改善,提高产品吸引力。
##### 2. 用户消费频次分析
单个用户消费总次数
total_buy_count = (behavior[behavior[‘type’]==‘pay’].groupby([‘user_id’])[‘type’].count()
.to_frame().rename(columns={‘type’:‘total’}))
消费次数前10客户
topbuyer10 = total_buy_count.sort_values(by=‘total’,ascending=False)[:10]
复购率
re_buy_rate = total_buy_count[total_buy_count>=2].count()/total_buy_count.count()
复制代码
SQL
#消费次数前10客户
SELECT user_id, COUNT(type) total_buy_count
FROM behavior_sql
WHERE type = ‘pay’
GROUP BY user_id
ORDER BY COUNT(type) DESC
LIMIT 10
#复购率
CREAT VIEW v_buy_count
AS SELECT user_id, COUNT(type) total_buy_count
FROM behavior_sql
WHERE type = ‘pay’
GROUP BY user_id;
SELECT CONCAT(ROUND((SUM(CASE WHEN total_buy_count>=2 THEN 1 ELSE 0 END)/
SUM(CASE WHEN total_buy_count>0 THEN 1 ELSE 0 END))*100,2),‘%’) AS re_buy_rate
FROM v_buy_count;
复制代码
topbuyer10.reset_index().style.bar(color=‘skyblue’,subset=[‘total’])
复制代码

单个用户消费总次数可视化
tbc_box = total_buy_count.reset_index()
fig, ax = plt.subplots(figsize=[16,6])
ax.set_yscale(“log”)
sns.countplot(x=tbc_box[‘total’],data=tbc_box,palette=‘Set1’)
for p in ax.patches:
ax.annotate(‘{:.2f}%’.format(100*p.get_height()/len(tbc_box[‘total’])), (p.get_x() - 0.1, p.get_height()))
plt.title(‘用户消费总次数’)
复制代码
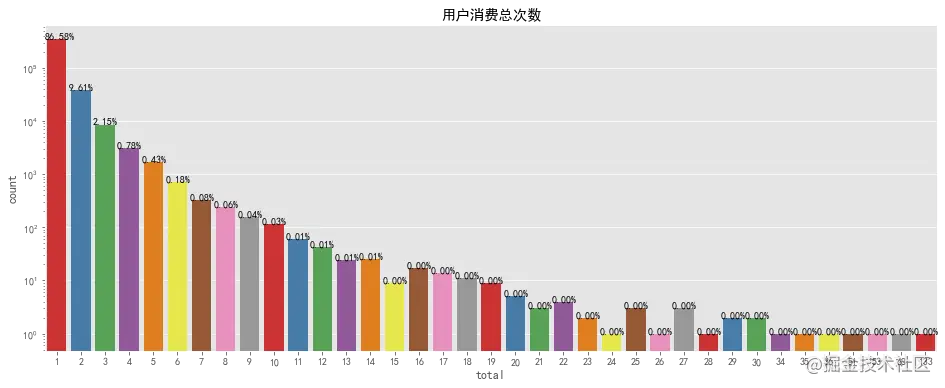
整个计算周期内,最高购物次数为133次,最低为1次,大部分用户的购物次数在6次以下,可适当增加推广,完善购物体验,提高用户消费次数。购物次数前10用户为1187177、502169等,应提高其满意度,增大留存率。
print(‘复购率为 %.3f%%’ %(re_buy_rate * 100) )
复制代码
OUTPUT
复购率为 13.419%
复制代码
复购率较低,应加强老用户召回机制,提升购物体验,也可能因数据量较少,统计周期之内的数据 无法解释完整的购物周期,从而得出结论有误。
##### 3. 用户行为在时间纬度的分布
* 日消费次数、日活跃人数、日消费人数、日消费人数占比、消费用户日人均消费次数
日活跃人数(有一次操作即视为活跃)
daily_active_user = behavior.groupby(‘date’)[‘user_id’].nunique()
日消费人数
daily_buy_user = behavior[behavior[‘type’] == ‘pay’].groupby(‘date’)[‘user_id’].nunique()
日消费人数占比
proportion_of_buyer = daily_buy_user / daily_active_user
日消费总次数
daily_buy_count = behavior[behavior[‘type’] == ‘pay’].groupby(‘date’)[‘type’].count()
消费用户日人均消费次数
consumption_per_buyer = daily_buy_count / daily_buy_user
复制代码
SQL
日消费总次数
SELECT date, COUNT(type) pay_daily FROM behavior_sql
WHERE type = ‘pay’
GROUP BY date;
日活跃人数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date;
日消费人数
SELECT date, COUNT(DISTINCT user_id) user_pay_daily FROM behavior_sql
WHERE type = ‘pay’
GROUP BY date;
日消费人数占比
SELECT
(SELECT date, COUNT(DISTINCT user_id) user_pay_daily FROM behavior_sql
WHERE type = ‘pay’
GROUP BY date) /
(SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date)
日人均消费次数
SELECT
(SELECT date, COUNT(type) pay_daily FROM behavior_sql
WHERE type = ‘pay’
GROUP BY date) /
(SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date)
复制代码
日消费人数占比可视化
柱状图数据
pob_bar = (pd.merge(daily_active_user,daily_buy_user,on=‘date’).reset_index()
.rename(columns={‘user_id_x’:‘日活跃人数’,‘user_id_y’:‘日消费人数’})
.set_index(‘date’).stack().reset_index().rename(columns={‘level_1’:‘Variable’,0: ‘Value’}))
线图数据
pob_line = proportion_of_buyer.reset_index().rename(columns={‘user_id’:‘Rate’})
fig1 = plt.figure(figsize=[16,6])
ax1 = fig1.add_subplot(111)
ax2 = ax1.twinx()
sns.barplot(x=‘date’, y=‘Value’, hue=‘Variable’, data=pob_bar, ax=ax1, alpha=0.8, palette=‘husl’)
ax1.legend().set_title(‘’)
ax1.legend().remove()
sns.pointplot(pob_line[‘date’], pob_line[‘Rate’], ax=ax2,markers=‘D’, linestyles=‘–’,color=‘teal’)
x=list(range(0,16))
for a,b in zip(x,pob_line[‘Rate’]):
plt.text(a+0.1, b + 0.001, ‘%.2f%%’ % (b*100), ha=‘center’, va= ‘bottom’,fontsize=12)
fig1.legend(loc=‘upper center’,ncol=2)
plt.title(‘日消费人数占比’)
复制代码
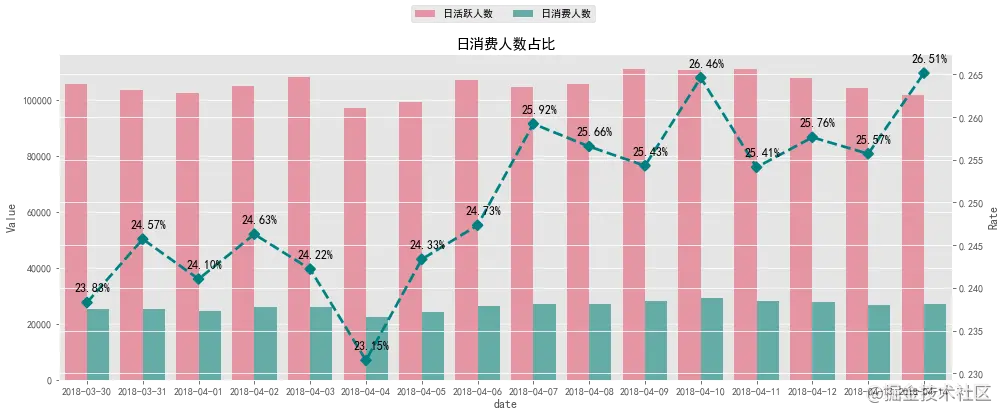
日活跃人数与日消费人数无明显波动,日消费人数占比均在20%以上。
消费用户日人均消费次数可视化
柱状图数据
cpb_bar = (daily_buy_count.reset_index().rename(columns={‘type’:‘Num’}))
线图数据
cpb_line = (consumption_per_buyer.reset_index().rename(columns={0:‘Frequency’}))
fig2 = plt.figure(figsize=[16,6])
ax3 = fig2.add_subplot(111)
ax4 = ax3.twinx()
sns.barplot(x=‘date’, y=‘Num’, data=cpb_bar, ax=ax3, alpha=0.8, palette=‘pastel’)
sns.pointplot(cpb_line[‘date’], cpb_line[‘Frequency’], ax=ax4, markers=‘D’, linestyles=‘–’,color=‘teal’)
x=list(range(0,16))
for a,b in zip(x,cpb_line[‘Frequency’]):
plt.text(a+0.1, b + 0.001, ‘%.2f’ % b, ha=‘center’, va= ‘bottom’,fontsize=12)
plt.title(‘消费用户日人均消费次数’)
复制代码
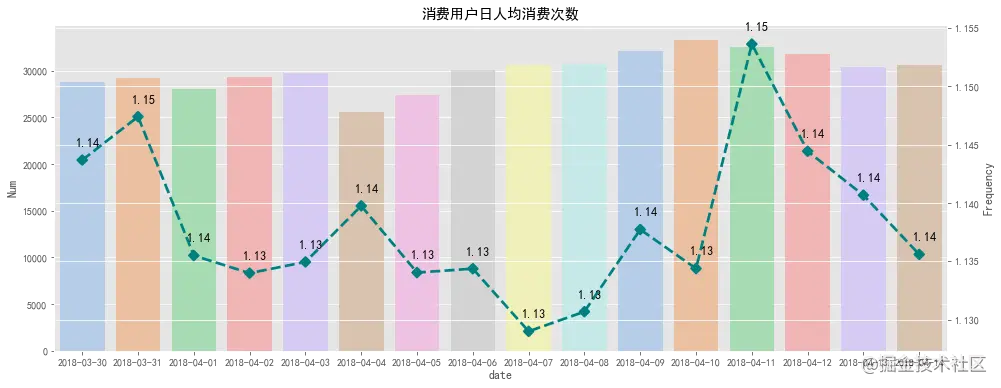
日消费人数在25000以上,日人均消费次数大于1次。
dau3_df = behavior.groupby([‘date’,‘user_id’])[‘type’].count().reset_index()
dau3_df = dau3_df[dau3_df[‘type’] >= 3]
复制代码
每日高活跃用户数(每日操作数大于3次)
dau3_num = dau3_df.groupby(‘date’)[‘user_id’].nunique()
复制代码
SQL
SELECT date, COUNT(DISTINCT user_id)
FROM
(SELECT date, user_id, COUNT(type)
FROM behavior_sql
GROUP BY date, user_id
HAVING COUNT(type) >= 3) dau3
GROUP BY date;
复制代码
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(dau3_num.index, dau3_num.values, markers=‘D’, linestyles=‘–’,color=‘teal’)
x=list(range(0,16))
for a,b in zip(x,dau3_num.values):
plt.text(a+0.1, b + 300 , ‘%i’ % b, ha=‘center’, va= ‘bottom’,fontsize=14)
plt.title(‘每日高活跃用户数’)
复制代码
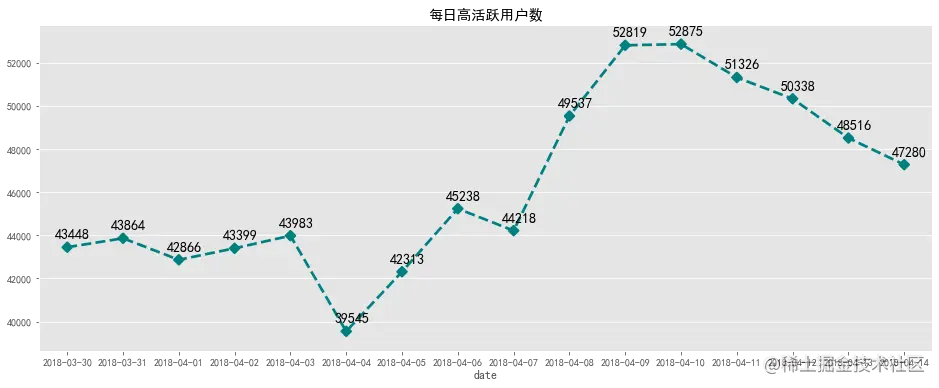
每日高活跃用户数在大部分4万以上,2018-04-04之前数量比较平稳,之后数量一直攀升,8号9号达到最高,随后下降,推测数据波动应为营销活动产生的。
高活跃用户累计活跃天数分布
dau3_cumsum = dau3_df.groupby(‘user_id’)[‘date’].count()
复制代码
SQL
SELECT user_id, COUNT(date)
FROM
(SELECT date, user_id, COUNT(type)
FROM behavior_sql
GROUP BY date, user_id
HAVING COUNT(type) >= 3) dau3
GROUP BY user_id;
复制代码
fig, ax = plt.subplots(figsize=[16,6])
ax.set_yscale(“log”)
sns.countplot(dau3_cumsum.values,palette=‘Set1’)
for p in ax.patches:
ax.annotate(‘{:.2f}%’.format(100*p.get_height()/len(dau3_cumsum.values)), (p.get_x() + 0.2, p.get_height() + 100))
plt.title(‘高活跃用户累计活跃天数分布’)
复制代码
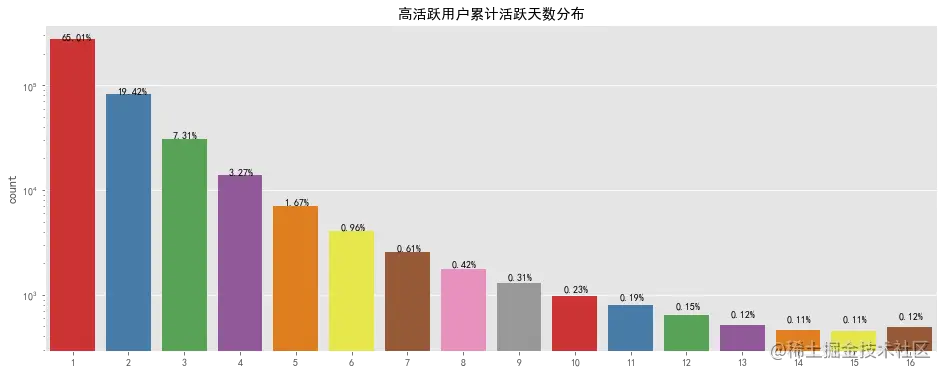
统计周期内,大部分高活跃用户累计活跃天数在六天以下,但也存在高达十六天的超级活跃用户数量,对累计天数较高的用户要推出连续登录奖励等继续维持其对平台的黏性,对累计天数较低的用户要适当进行推送活动消息等对其进行召回。
#每日浏览量
pv_daily = behavior[behavior[‘type’] == ‘pv’].groupby(‘date’)[‘user_id’].count()
#每日访客数
uv_daily = behavior.groupby(‘date’)[‘user_id’].nunique()
复制代码
SQL
#每日浏览量
SELECT date, COUNT(type) pv_daily FROM behavior_sql
WHERE type = ‘pv’
GROUP BY date;
#每日访客数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date;
复制代码
每日浏览量可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(pv_daily.index, pv_daily.values,markers=‘D’, linestyles=‘–’,color=‘dodgerblue’)
x=list(range(0,16))
for a,b in zip(x,pv_daily.values):
plt.text(a+0.1, b + 2000 , ‘%i’ % b, ha=‘center’, va= ‘bottom’,fontsize=14)
plt.title(‘每日浏览量’)
复制代码
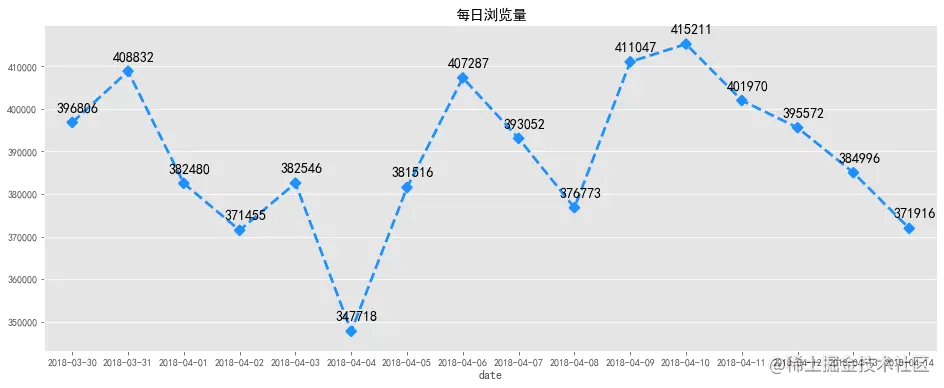
每日访客数可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(uv_daily.index, uv_daily.values, markers=‘H’, linestyles=‘–’,color=‘m’)
x=list(range(0,16))
for a,b in zip(x,uv_daily.values):
plt.text(a+0.1, b + 500 , ‘%i’ % b, ha=‘center’, va= ‘bottom’,fontsize=14)
plt.title(‘每日访客数’)
复制代码

浏览量和访客数每日变化趋势大致相同,2018-04-04日前后用户数量变化波动较大,4月4日为清明节假日前一天,各数据量在当天均有明显下降,但之后逐步回升,推测应为节假日营销活动或推广拉新活动带来的影响。
#每时浏览量
pv_hourly = behavior[behavior[‘type’] == ‘pv’].groupby(‘hour’)[‘user_id’].count()
#每时访客数
uv_hourly = behavior.groupby(‘hour’)[‘user_id’].nunique()
复制代码
SQL
每时浏览量
SELECT date, COUNT(type) pv_daily FROM behavior_sql
WHERE type = ‘pv’
GROUP BY hour;
每时访客数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY hour;
复制代码
浏览量随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(pv_hourly.index, pv_hourly.values, markers=‘H’, linestyles=‘–’,color=‘dodgerblue’)
for a,b in zip(pv_hourly.index,pv_hourly.values):
plt.text(a, b + 10000 , ‘%i’ % b, ha=‘center’, va= ‘bottom’,fontsize=12)
plt.title(‘浏览量随小时变化’)
复制代码
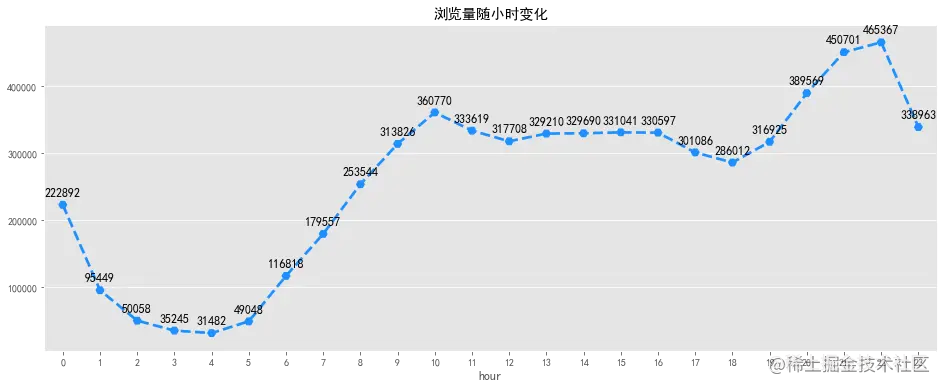
访客数随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(uv_hourly.index, uv_hourly.values, markers=‘H’, linestyles=‘–’,color=‘m’)
for a,b in zip(uv_hourly.index,uv_hourly.values):
plt.text(a, b + 1000 , ‘%i’ % b, ha=‘center’, va= ‘bottom’,fontsize=12)
plt.title(‘访客数随小时变化’)
复制代码
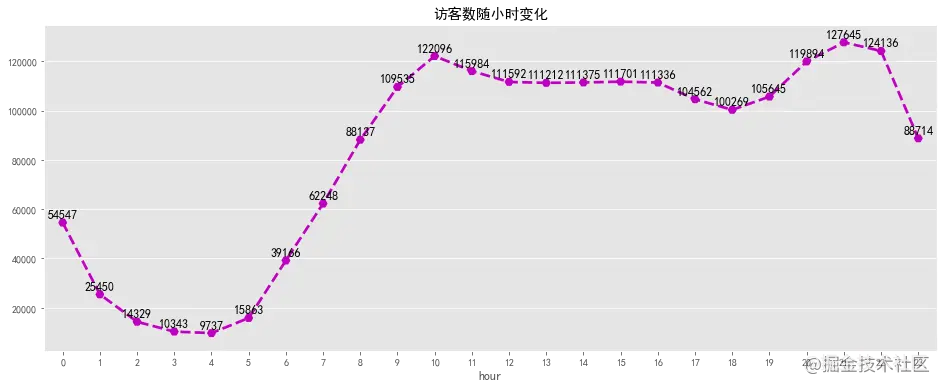
浏览量及访客数随小时变化趋势一致,在凌晨1点到凌晨5点之间,大部分用户正在休息,整体活跃度较低。凌晨5点到10点用户开始起床工作,活跃度逐渐增加,之后趋于平稳,下午6点之后大部分人恢复空闲,浏览量及访客数迎来了第二波攀升,在晚上8点中到达高峰,随后逐渐下降。可以考虑在上午9点及晚上8点增大商品推广力度,加大营销活动投入,可取的较好的收益,1点到5点之间适合做系统维护。
用户各操作随小时变化
type_detail_hour = pd.pivot_table(columns = ‘type’,index = ‘hour’, data = behavior,aggfunc=np.size,values = ‘user_id’)
用户各操作随星期变化
type_detail_weekday = pd.pivot_table(columns = ‘type’,index = ‘weekday’, data = behavior,aggfunc=np.size,values = ‘user_id’)
type_detail_weekday = type_detail_weekday.reindex([‘Monday’,‘Tuesday’,‘Wednesday’,‘Thursday’,‘Friday’,‘Saturday’,‘Sunday’])
复制代码
SQL
用户各操作随小时变化
SELECT hour,
SUM(CASE WHEN behavior=‘pv’ THEN 1 ELSE 0 END)AS ‘pv’,
SUM(CASE WHEN behavior=‘fav’ THEN 1 ELSE 0 END)AS ‘fav’,
SUM(CASE WHEN behavior=‘cart’ THEN 1 ELSE 0 END)AS ‘cart’,
SUM(CASE WHEN behavior=‘pay’ THEN 1 ELSE 0 END)AS ‘pay’
FROM behavior_sql
GROUP BY hour
ORDER BY hour
用户各操作随星期变化
SELECT weekday,
SUM(CASE WHEN behavior=‘pv’ THEN 1 ELSE 0 END)AS ‘pv’,
SUM(CASE WHEN behavior=‘fav’ THEN 1 ELSE 0 END)AS ‘fav’,
SUM(CASE WHEN behavior=‘cart’ THEN 1 ELSE 0 END)AS ‘cart’,
SUM(CASE WHEN behavior=‘pay’ THEN 1 ELSE 0 END)AS ‘pay’
FROM behavior_sql
GROUP BY weekday
ORDER BY weekday
复制代码
tdh_line = type_detail_hour.stack().reset_index().rename(columns={0: ‘Value’})
tdw_line = type_detail_weekday.stack().reset_index().rename(columns={0: ‘Value’})
tdh_line= tdh_line[~(tdh_line[‘type’] == ‘pv’)]
tdw_line= tdw_line[~(tdw_line[‘type’] == ‘pv’)]
复制代码
用户操作随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(x=‘hour’, y=‘Value’, hue=‘type’, data=tdh_line, linestyles=‘–’)
plt.title(‘用户操作随小时变化’)
复制代码

用户操作随小时变化规律与PV、UV随小时规律相似,与用户作息规律相关,加入购物车和付款两条曲线贴合比比较紧密,说明大部分用户习惯加入购物车后直接购买。关注数相对较少,可以根据用户购物车内商品进行精准推送。评论数也相对较少,说明大部分用户不是很热衷对购物体验进行反馈,可以设置一些奖励制度提高用户评论数,增大用用户粘性。
用户操作随星期变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(x=‘weekday’, y=‘Value’, hue=‘type’, data=tdw_line[~(tdw_line[‘type’] == ‘pv’)], linestyles=‘–’)
plt.title(‘用户操作随星期变化’)
复制代码
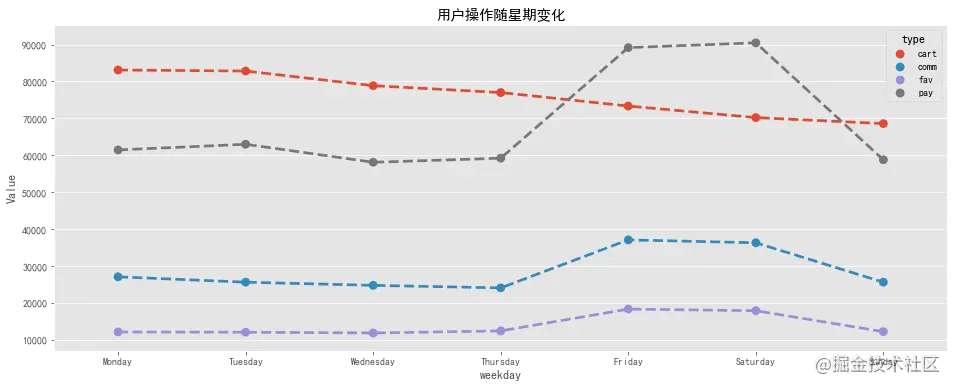
周一到周四工作日期间,用户操作随星期变化比较平稳,周五至周六进入休息日,用户操作明显增多,周日又恢复正常。
##### 4. 用户行为转化漏斗
导入相关包
from pyecharts import options as opts
from pyecharts.charts import Funnel
import math
复制代码
behavior[‘action_time’] = pd.to_datetime(behavior[‘action_time’],format =‘%Y-%m-%d %H:%M:%S’)
复制代码
用户整体行为分布
type_dis = behavior[‘type’].value_counts().reset_index()
type_dis[‘rate’] = round((type_dis[‘type’] / type_dis[‘type’].sum()),3)
复制代码
type_dis.style.bar(color=‘skyblue’,subset=[‘rate’])
复制代码
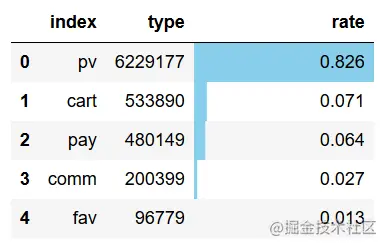
用户整体行为中,有82.6%行为为浏览,实际支付操作仅占6.4,除此之外,用户评论及收藏的行为占比也较低,应当增强网站有用户之间的互动,提高评论数量和收藏率。
df_con = behavior[[‘user_id’, ‘sku_id’, ‘action_time’, ‘type’]]
复制代码
df_pv = df_con[df_con[‘type’] == ‘pv’]
df_fav = df_con[df_con[‘type’] == ‘fav’]
df_cart = df_con[df_con[‘type’] == ‘cart’]
df_pay = df_con[df_con[‘type’] == ‘pay’]
df_pv_uid = df_con[df_con[‘type’] == ‘pv’][‘user_id’].unique()
df_fav_uid = df_con[df_con[‘type’] == ‘fav’][‘user_id’].unique()
df_cart_uid = df_con[df_con[‘type’] == ‘cart’][‘user_id’].unique()
df_pay_uid = df_con[df_con[‘type’] == ‘pay’][‘user_id’].unique()
复制代码
* pv - buy
fav_cart_list = set(df_fav_uid) | set(df_cart_uid)
复制代码
pv_pay_df = pd.merge(left=df_pv, right=df_pay, how=‘inner’, on=[‘user_id’, ‘sku_id’],
suffixes=(‘_pv’, ‘_pay’))
复制代码
pv_pay_df = pv_pay_df[(~pv_pay_df[‘user_id’].isin(fav_cart_list)) & (pv_pay_df[‘action_time_pv’] < pv_pay_df[‘action_time_pay’])]
复制代码
uv = behavior[‘user_id’].nunique()
pv_pay_num = pv_pay_df[‘user_id’].nunique()
pv_pay_data = pd.DataFrame({‘type’:[‘浏览’,‘付款’],‘num’:[uv,pv_pay_num]})
pv_pay_data[‘conversion_rates’] = (round((pv_pay_data[‘num’] / pv_pay_data[‘num’][0]),4) * 100)
复制代码
attr1 = list(pv_pay_data.type)
values1 = list(pv_pay_data.conversion_rates)
data1 = [[attr1[i], values1[i]] for i in range(len(attr1))]
复制代码
用户行为转化漏斗可视化
pv_pay=(Funnel(opts.InitOpts(width=“600px”, height=“300px”))
.add(
series_name=“”,
data_pair=data1,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger=“item”, formatter=“{b} : {c}%”),
label_opts=opts.LabelOpts(is_show=True, position=“inside”),
itemstyle_opts=opts.ItemStyleOpts(border_color=“#fff”, border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title=“用户行为转化漏斗图”))
)
pv_pay.render_notebook()
复制代码
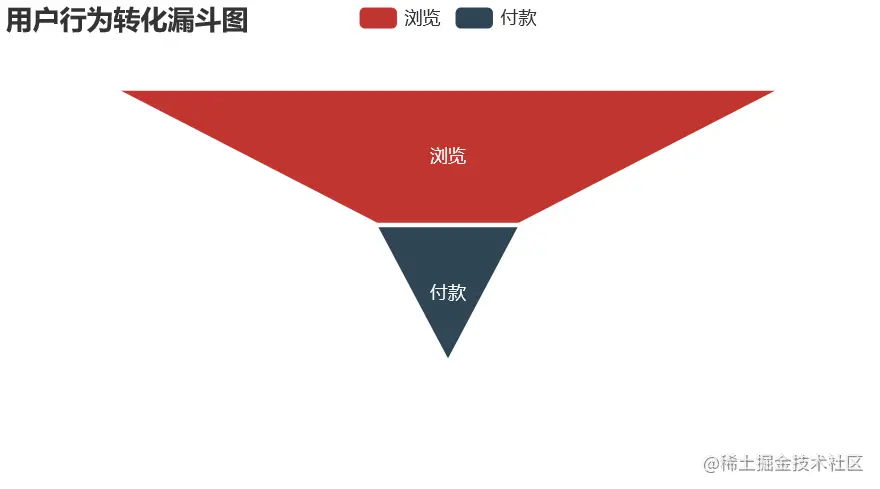
* pv - cart - pay
pv_cart_df = pd.merge(left=df_pv, right=df_cart, how=‘inner’, on=[‘user_id’, ‘sku_id’],
suffixes=(‘_pv’, ‘_cart’))
复制代码
pv_cart_df = pv_cart_df[pv_cart_df[‘action_time_pv’] < pv_cart_df[‘action_time_cart’]]
pv_cart_df = pv_cart_df[~pv_cart_df[‘user_id’].isin(df_fav_uid)]
复制代码
pv_cart_pay_df = pd.merge(left=pv_cart_df, right=df_pay, how=‘inner’, on=[‘user_id’, ‘sku_id’])
复制代码
pv_cart_pay_df = pv_cart_pay_df[pv_cart_pay_df[‘action_time_cart’] < pv_cart_pay_df[‘action_time’]]
复制代码
uv = behavior[‘user_id’].nunique()
pv_cart_num = pv_cart_df[‘user_id’].nunique()
pv_cart_pay_num = pv_cart_pay_df[‘user_id’].nunique()
pv_cart_pay_data = pd.DataFrame({‘type’:[‘浏览’,‘加购’,‘付款’],‘num’:[uv,pv_cart_num,pv_cart_pay_num]})
pv_cart_pay_data[‘conversion_rates’] = (round((pv_cart_pay_data[‘num’] / pv_cart_pay_data[‘num’][0]),4) * 100)
复制代码
attr2 = list(pv_cart_pay_data.type)
values2 = list(pv_cart_pay_data.conversion_rates)
data2 = [[attr2[i], values2[i]] for i in range(len(attr2))]
复制代码
用户行为转化漏斗可视化
pv_cart_buy=(Funnel(opts.InitOpts(width=“600px”, height=“300px”))
.add(
series_name=“”,
data_pair=data2,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger=“item”, formatter=“{b} : {c}%”),
label_opts=opts.LabelOpts(is_show=True, position=“inside”),
itemstyle_opts=opts.ItemStyleOpts(border_color=“#fff”, border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title=“用户行为转化漏斗图”))
)
pv_cart_buy.render_notebook()
复制代码
* pv - fav - pay
pv_fav_df = pd.merge(left=df_pv, right=df_fav, how=‘inner’, on=[‘user_id’, ‘sku_id’],
suffixes=(‘_pv’, ‘_fav’))
复制代码
pv_fav_df = pv_fav_df[pv_fav_df[‘action_time_pv’] < pv_fav_df[‘action_time_fav’]]
pv_fav_df = pv_fav_df[~pv_fav_df[‘user_id’].isin(df_cart_uid)]
复制代码
pv_fav_pay_df = pd.merge(left=pv_fav_df, right=df_pay, how=‘inner’, on=[‘user_id’, ‘sku_id’])
复制代码
pv_fav_pay_df = pv_fav_pay_df[pv_fav_pay_df[‘action_time_fav’] < pv_fav_pay_df[‘action_time’]]
复制代码
uv = behavior[‘user_id’].nunique()
pv_fav_num = pv_fav_df[‘user_id’].nunique()
pv_fav_pay_num = pv_fav_pay_df[‘user_id’].nunique()
pv_fav_pay_data = pd.DataFrame({‘type’:[‘浏览’,‘收藏’,‘付款’],‘num’:[uv,pv_fav_num,pv_fav_pay_num]})
pv_fav_pay_data[‘conversion_rates’] = (round((pv_fav_pay_data[‘num’] / pv_fav_pay_data[‘num’][0]),4) * 100)
复制代码
attr3 = list(pv_fav_pay_data.type)
values3 = list(pv_fav_pay_data.conversion_rates)
data3 = [[attr3[i], values3[i]] for i in range(len(attr3))]
复制代码
用户行为转化漏斗可视化
pv_fav_buy=(Funnel(opts.InitOpts(width=“600px”, height=“300px”))
.add(
series_name=“”,
data_pair=data3,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger=“item”, formatter=“{b} : {c}%”),
label_opts=opts.LabelOpts(is_show=True, position=“inside”),
itemstyle_opts=opts.ItemStyleOpts(border_color=“#fff”, border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title=“用户行为转化漏斗图”))
)
pv_fav_buy.render_notebook()
复制代码

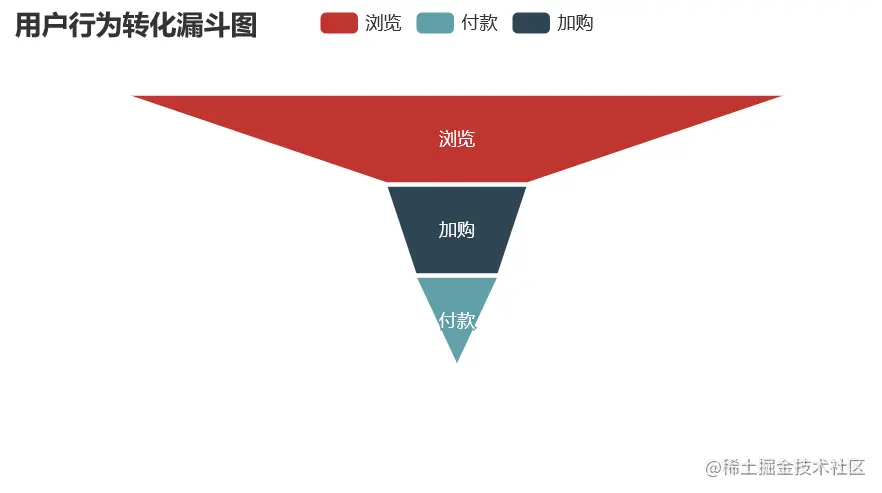
* pv - fav - cart - pay
pv_fav = pd.merge(left=df_pv, right=df_fav, how=‘inner’, on=[‘user_id’, ‘sku_id’],
suffixes=(‘_pv’, ‘_fav’))
复制代码
pv_fav = pv_fav[pv_fav[‘action_time_pv’] < pv_fav[‘action_time_fav’]]
复制代码
pv_fav_cart = pd.merge(left=pv_fav, right=df_cart, how=‘inner’, on=[‘user_id’, ‘sku_id’])
复制代码
pv_fav_cart = pv_fav_cart[pv_fav_cart[‘action_time_fav’]<pv_fav_cart[‘action_time’]]
复制代码
pv_fav_cart_pay = pd.merge(left=pv_fav_cart, right=df_pay, how=‘inner’, on=[‘user_id’, ‘sku_id’],
suffixes=(‘_cart’, ‘_pay’))
复制代码
pv_fav_cart_pay = pv_fav_cart_pay[pv_fav_cart_pay[‘action_time_cart’]<pv_fav_cart_pay[‘action_time_pay’]]
复制代码
uv = behavior[‘user_id’].nunique()
pv_fav_n = pv_fav[‘user_id’].nunique()
pv_fav_cart_n = pv_fav_cart[‘user_id’].nunique()
pv_fav_cart_pay_n = pv_fav_cart_pay[‘user_id’].nunique()
pv_fav_cart_pay_data = pd.DataFrame({‘type’:[‘浏览’,‘收藏’,‘加购’,‘付款’],‘num’:[uv,pv_fav_n,pv_fav_cart_n,pv_fav_cart_pay_n]})
pv_fav_cart_pay_data[‘conversion_rates’] = (round((pv_fav_cart_pay_data[‘num’] / pv_fav_cart_pay_data[‘num’][0]),4) * 100)
复制代码
attr4 = list(pv_fav_cart_pay_data.type)
values4 = list(pv_fav_cart_pay_data.conversion_rates)
data4 = [[attr4[i], values4[i]] for i in range(len(attr4))]
复制代码
用户行为转化漏斗可视化
pv_fav_buy=(Funnel(opts.InitOpts(width=“600px”, height=“300px”))
.add(
series_name=“”,
data_pair=data4,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger=“item”, formatter=“{b} : {c}%”),
label_opts=opts.LabelOpts(is_show=True, position=“inside”),
itemstyle_opts=opts.ItemStyleOpts(border_color=“#fff”, border_width=1)
)
.set_global_opts(title_opts=opts.TitleOpts(title=“用户行为转化漏斗图”))
)
pv_fav_buy.render_notebook()
复制代码
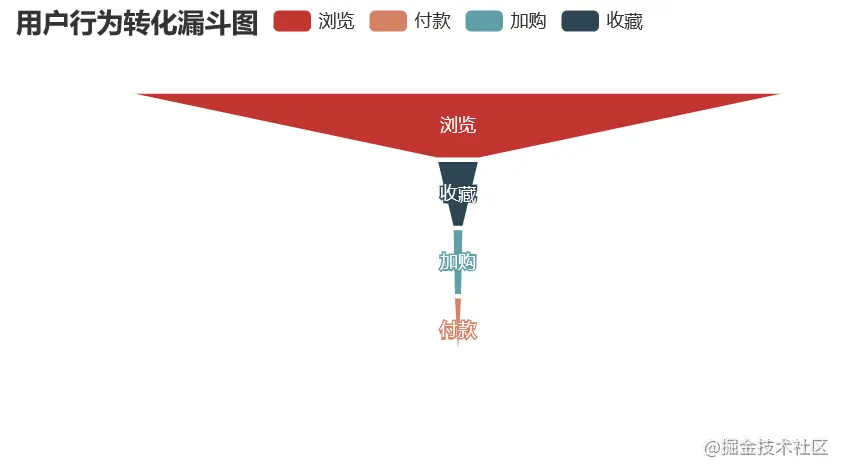
不同路径用户消费时间间隔分析
* pv - cart - pay
pcp_interval = pv_cart_pay_df.groupby([‘user_id’, ‘sku_id’]).apply(lambda x: (x.action_time.min() - x.action_time_cart.min())).reset_index()
复制代码
pcp_interval[‘interval’] = pcp_interval[0].apply(lambda x: x.seconds) / 3600
pcp_interval[‘interval’] = pcp_interval[‘interval’].apply(lambda x: math.ceil(x))
复制代码
fig, ax = plt.subplots(figsize=[16,6])
sns.countplot(pcp_interval[‘interval’],palette=‘Set1’)
for p in ax.patches:
ax.annotate(‘{:.2f}%’.format(100*p.get_height()/len(pcp_interval[‘interval’])), (p.get_x() + 0.1, p.get_height() + 100))
ax.set_yscale(“log”)
plt.title(‘pv-cart-pay路径用户消费时间间隔’)
复制代码

* pv - fav - pay
pfp_interval = pv_fav_pay_df.groupby([‘user_id’, ‘sku_id’]).apply(lambda x: (x.action_time.min() - x.action_time_fav.min())).reset_index()
复制代码
pfp_interval[‘interval’] = pfp_interval[0].apply(lambda x: x.seconds) / 3600
pfp_interval[‘interval’] = pfp_interval[‘interval’].apply(lambda x: math.ceil(x))
复制代码
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









