






前言
第三十九部分 关于SD版本的进化
39.1 前言
自 Stable Diffusion 发布以来,它已迅速成为图像生成领域的一大亮点。随着每个新版本的发布,模型在图像质量、生成速度、文本理解能力和应用场景等方面都取得了显著进展。从 Stable Diffusion 1.4 到最新的 Stable Diffusion XL 1.0,这一系列模型不仅扩展了人工智能的创造力,也为各行各业提供了强大的工具。
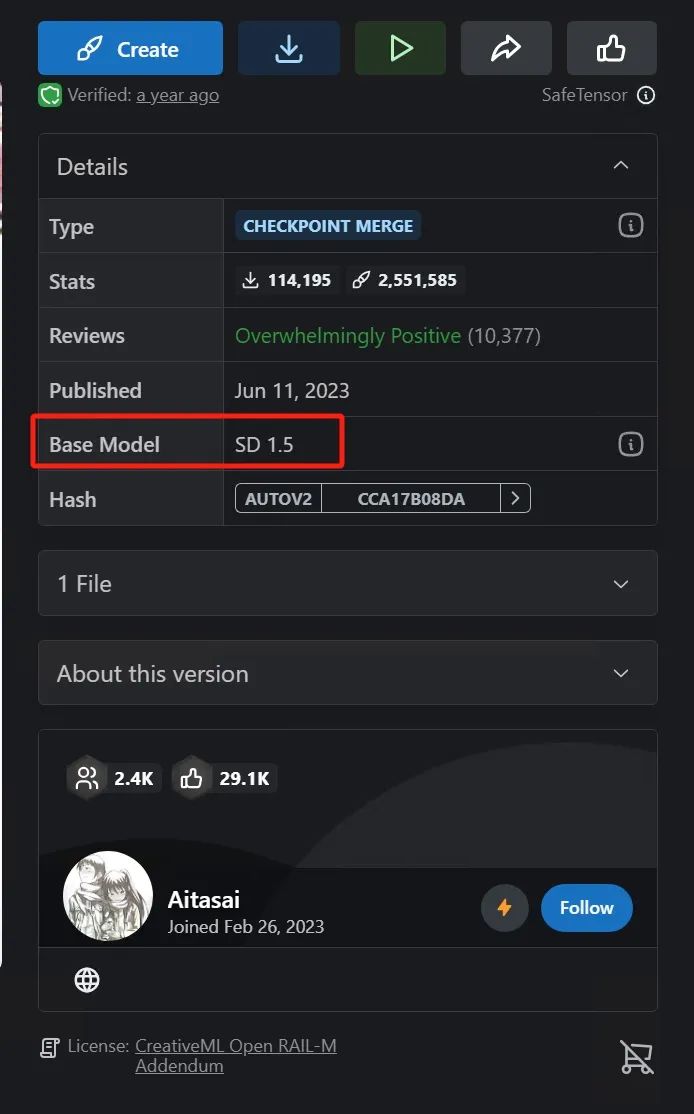
当我们在C站下载模型的时候,也可以在模型分类中看到每一种模型所基于的SD版本分类。

我们在具体每一个模型的页面可以看到其所属的SD版本号。
所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~
最常见的版本就是SD1.5,而最新的则是SDXL1.0,本章将带你回顾这些版本的进化历程,深入了解每个版本的特点和改进。
39.2 开端:SD 1.4
Stable Diffusion 1.4 是 Stable Diffusion 系列的早期版本,标志着这个强大模型的初次登场。它使用了大量的开源数据集进行训练,能够在相对较低的资源需求下生成高质量的图像。该版本的模型体量适中,能够处理 512x512 分辨率的图像,适合在普通的高端显卡上运行。尽管 1.4 版本在某些复杂场景的处理上表现得有限,但它当时为用户提供了广泛的图像生成能力,是许多早期用户的首选。现阶段已经被淘汰
39.3 稳步提升:SD 1.5
Stable Diffusion 1.5 在 1.4 版本的基础上做了显著的优化,以512分辨率作为训练集,特别是**在细节处理和图像质量方面有了较大提升。1.5 版本对文本提示的响应更加灵敏,生成的图像更加清晰和稳定,尤其在处理复杂场景和人物肖像时表现出色。关键是其对显存的压力和要求也大大减小。相比于 1.4 版本,1.5 版本减少了图像中的失真现象(如变形和额外肢体),使得生成的图像在视觉效果上更加自然**。这一改进使得 SD 1.5 成为许多创意工作者和艺术家创作的强大工具,即使发展到现在1.5版本的生态也是所有版本中最完善的,你可以找到基于1.5版本的丰富的各类模型。我们目前用到的绝大多数底模、Lora、插件都是基于SD1.5版本的。
39.4 迈向新高:SD 2.0
Stable Diffusion 2.0 是一个重要的升级版本,它在**模型架构、训练数据集和文本到图像的生成能力方面都做出了显著改进。2.0 版本引入了 OpenCLIP 文本编码器,这显著提高了模型对复杂文本提示的理解能力。此外,由于该版本以768分辨率**作为训练集,所以它为用户提供了更高质量的输出。然而,2.0 版本也面临一些挑战。例如,虽然它在生成逼真图像方面表现出色,但在艺术风格和人物肖像的生成中,有时可能会比 1.5 版本表现得略差。这个版本对硬件资源的要求也有所增加,尤其是在处理高分辨率图像时。
4. 稳健提升:SD 2.1
Stable Diffusion 2.1 在 2.0 版本的基础上做了进一步优化,解决了许多 2.0 版本中的问题,特别是**在人物肖像和艺术风格图像生成方面的表现有所提升。2.1 版本不仅保留了 2.0 版本的_768分辨率_的支持,还增强了模型在复杂场景下的稳定性和一致性**。此外,2.1 版本还_优化了生成速度_,使得即便在高分辨率下,图像生成的时间也得到了控制。这个版本对多语言支持也更为友好,适用于全球范围内的用户。
虽然从1.5到2.1,无论是分辨率、文本能力、生成能力还是对显卡的性能优化都有所改进,但它们在本质上并没有飞跃式的突破,所以也造成了大部分作者依然沿用或继续基于1.5版本进行训练,这也是为什么1.5版本的生态链远远大于2.0和2.1的原因。
39.5 巅峰之作:SDXL 1.0
Stable Diffusion XL 1.0 (SDXL 1.0) 是迄今为止该系列最先进的版本。它以_1024分辨率作为训练集,引入了多级生成方法_,即在不同分辨率层次上生成图像,使得最终输出的图像在**细节和清晰度上达到新的高度。SDXL 1.0 采用了更深和更宽的网络架构**,能够处理前所未有的复杂场景和高分辨率需求。可以说相比过去的版本,SDXL1.0有了里程碑式的飞跃,它有以下几大优势:
1.对提示词的包容度较高,不用再像过去那样输入大量繁琐的提示词了,通过简单的描述,同样可以生成高质量的图片。像以往一般需要加入masterpiece、highquality等起手式,但SDXL支持以简单、少量的提示词来生成高质量的图片。另外SDXL可以较好地识别自然语言,可以不需要像以往那样输入很多的单词了。
2.初始分辨率大幅提升,由于在过去的版本中,SD基础模型的训练样本尺寸为512或768,这导致在生成高分辨率图片时AI会误以为我们在生成多张图片,从而产生多人多头多肢体的现象,而SDXL的基础训练样本分辨率达到了1024,意味着可以直接生成高质量的更大尺寸的图。

3.图片精度大幅提升,由于其拥有创新性的"Refiner"结构,SDXL生成作品的精度和图片细节都有了大幅的提升,SDXL1.0基础大模型包含两个部分,一个是基础模型(base model),另一个是优化器(Refiner),我们用基础模型生成出一张自己想要的图片后,将图片发送到图生图,再使用优化器完善图片的细节水平(重绘幅度调至低于0.5)。
base model下载地址:
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
Refiner下载地址:
https://huggingface.co/grendarAI/stable-diffusion-xl-refiner-0.9/blob/main
4.生成准确度大幅提升,过去的SD版本对文字的识别能力一直是它的软件,但SDXL1.0则具备了初步的文字识别能力,我们可以用它来生成相应的文字。另外其生成的人体结构准确度大幅提升,过去的SD版本对画手不是很擅长,需要费九牛二虎之力来调整和修复,但SDXL1.0已经很好地改进了这一问题,你可以大胆的直接在提示词中加入"hands up"等提示词来展现人物的手指。

5.风格自由度大幅提升,SDXL的默认模型更接近真实系的照片风格,但根据官网(https://stablediffusionxl.com/)介绍我们可以通过提示词让它在十余种不同风格之间做无缝切换,包括数字插画、胶片摄影、3D建模、像素画、儿童绘本等。
但是质量的提升意味着你需要更久的出图时间,需要配置更好的显卡,需要更大的显存。所以其分支XL turbo就应运而生了,它对SDXL1.0进行了优化,在保证大部分出图质量的同时,大大减少了生成时间,其生图速度甚至比SD1.5还快。但我依然建议你配置一块12G显存以上的显卡。
39.6 版本对比与总结
通过对 SD 1.4、SD 1.5、SD 2.0、SD 2.1 和 SDXL 1.0 的比较,我们可以看到 Stable Diffusion 在图像生成技术上的不断进步。每个版本都在前一版本的基础上进行了重要改进,从基础应用到专业级应用,Stable Diffusion 系列不断扩展其适用性和图像生成质量。
SD 1.4 和 SD 1.5 是基础版本,适合资源有限的环境,且易于上手。
SD 2.0 和 SD 2.1 提供了更高的分辨率和改进的文本解析能力,适合更复杂的应用场景。
SDXL 1.0 是目前最强大的版本,适用于高端创意和专业图像生成需求。过去的SD必须要在各种包罗万象的大模型之间切换来生成理想中的作品,必须通过各种插件的调试来产出自己希望的效果,这也是相比MJ来说,SD门槛高的原因,但SDXL的出现,大大降低了SD的使用门槛,让大家可以在一套大模型中直接使用简单的提示词便能生成较为理想的结果。加上SD拥有诸如ControlNet等可控性插件,可以让我们进一步对出图的结果进行有效的把控。虽然SDXL1.0官方的底模还达不到那些SD1.5中各类老牌模型在各自特定画风领域的生成效果,但目前基于SDXL官方模型训练的各类大模型也在源源不断的创造出来,相信在不久的将来,SDXL一定会是比SD1.5更主流的存在。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!

AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!

精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。
















 1641
1641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









