






前言
第三十五部分 把SD融合进Photoshop
35.1 安装和配置
关于如何把SD融合进Photoshop,我们需要使用的是一个叫"Auto-Photoshop-StableDiffusion-Plugin"的插件。
项目
首先你需要确保你的Photoshop版本不低于V24,并且已经在本地或者局域网内部署了Stable Diffusion WebUI。然后打开Stable Diffusion WebUI的"启用API"功能。
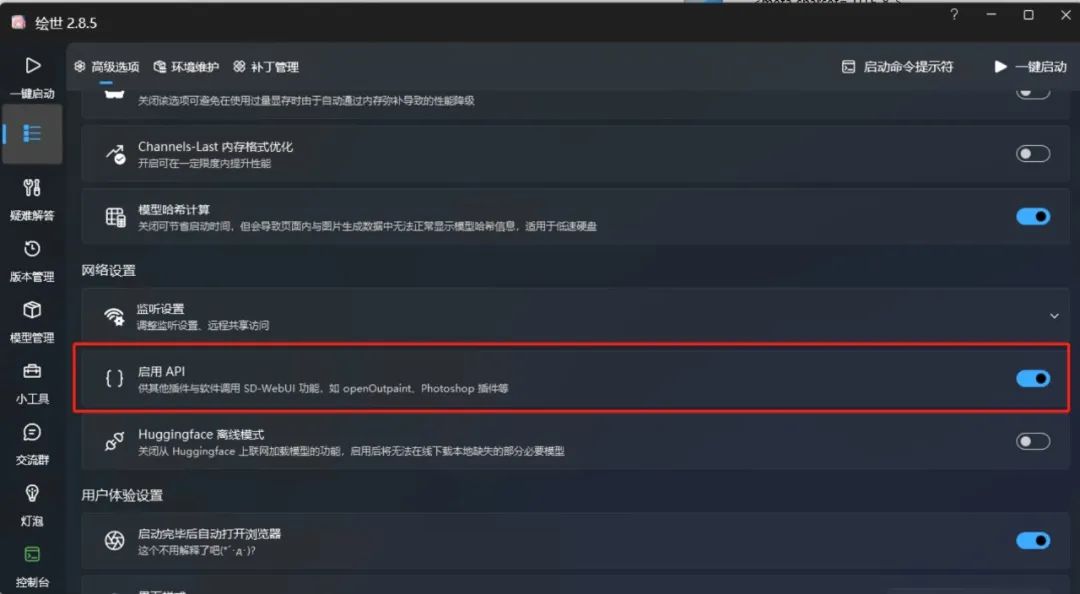
然后搜索并安装"Auto-Photoshop-StableDiffusion-Plugin"这个插件。
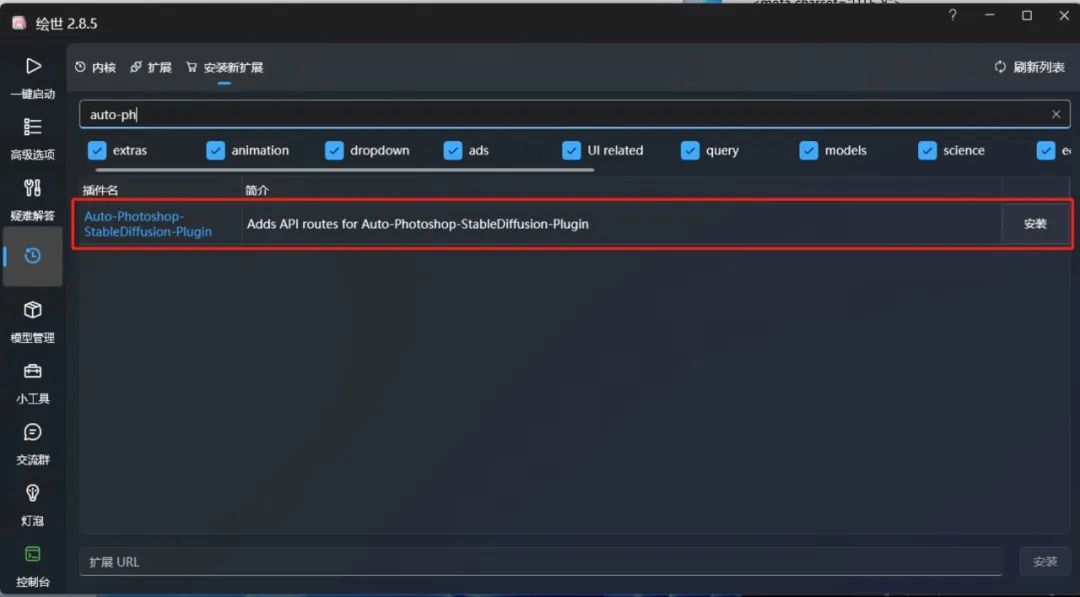
然后将项目地址中下载的插件压缩包解压缩到你的Photoshoop安装目录下的Plug-ins文件夹内。
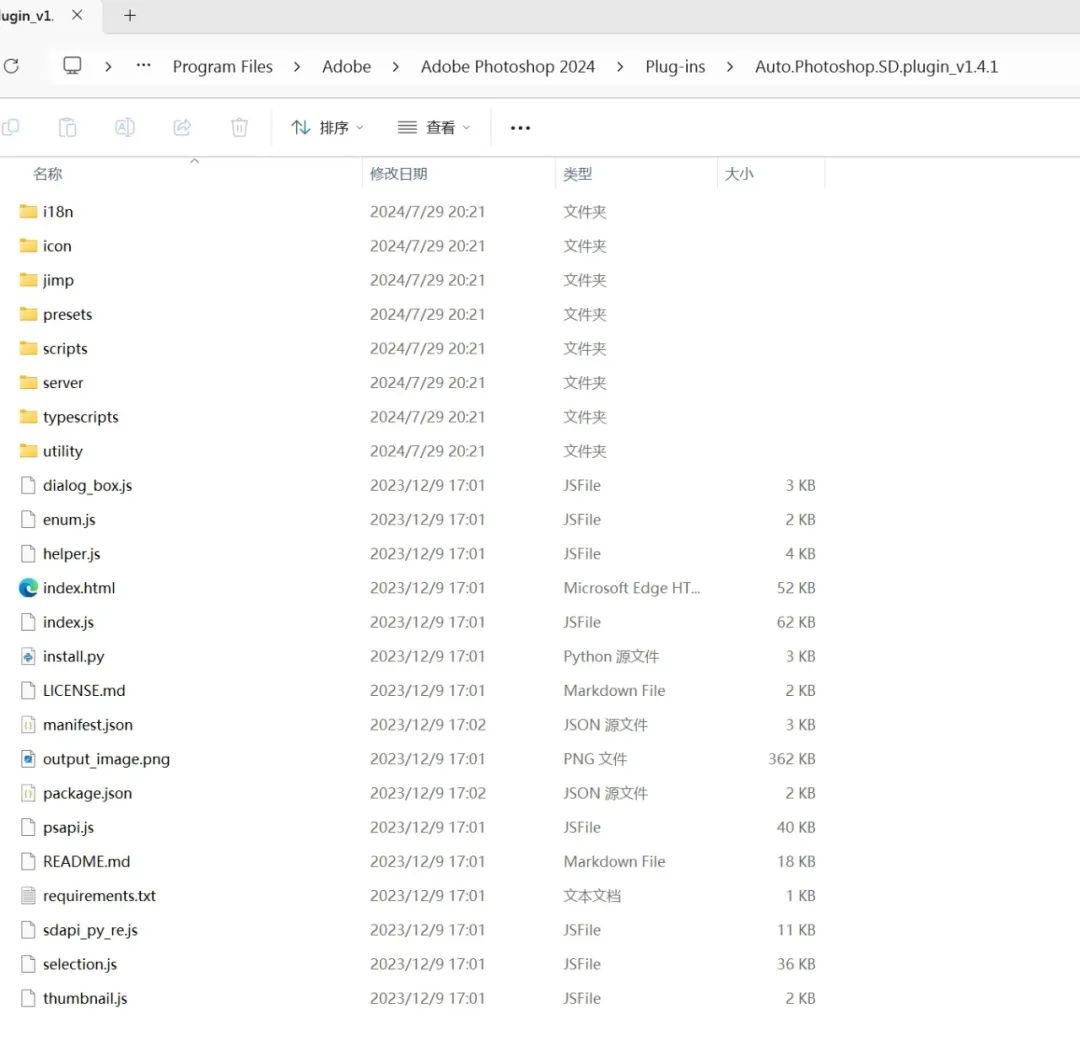
然后重新启动你的Photoshop,便可以在"增效工具"中看到你安装的"Auto-Photoshop-StableDiffusion-Plugin"插件了。
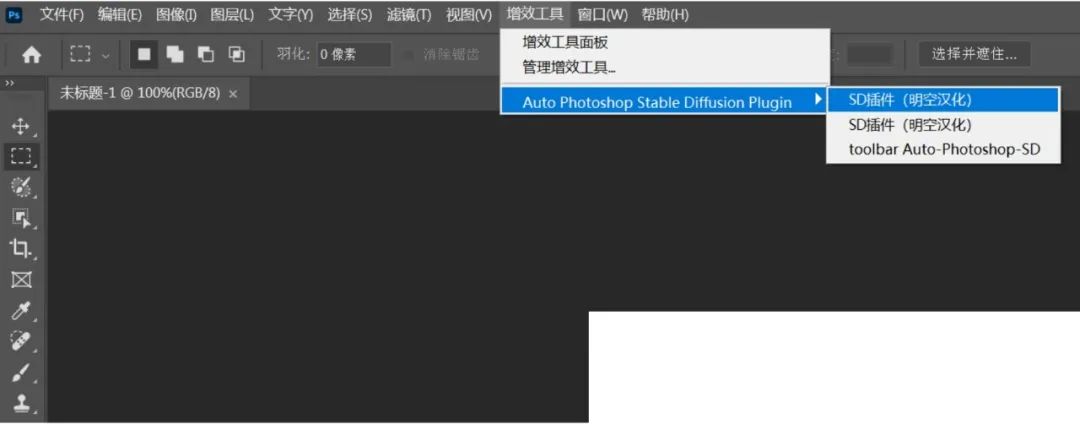
点击打开它便能在Photoshop中打开这个插件的操作面板了。
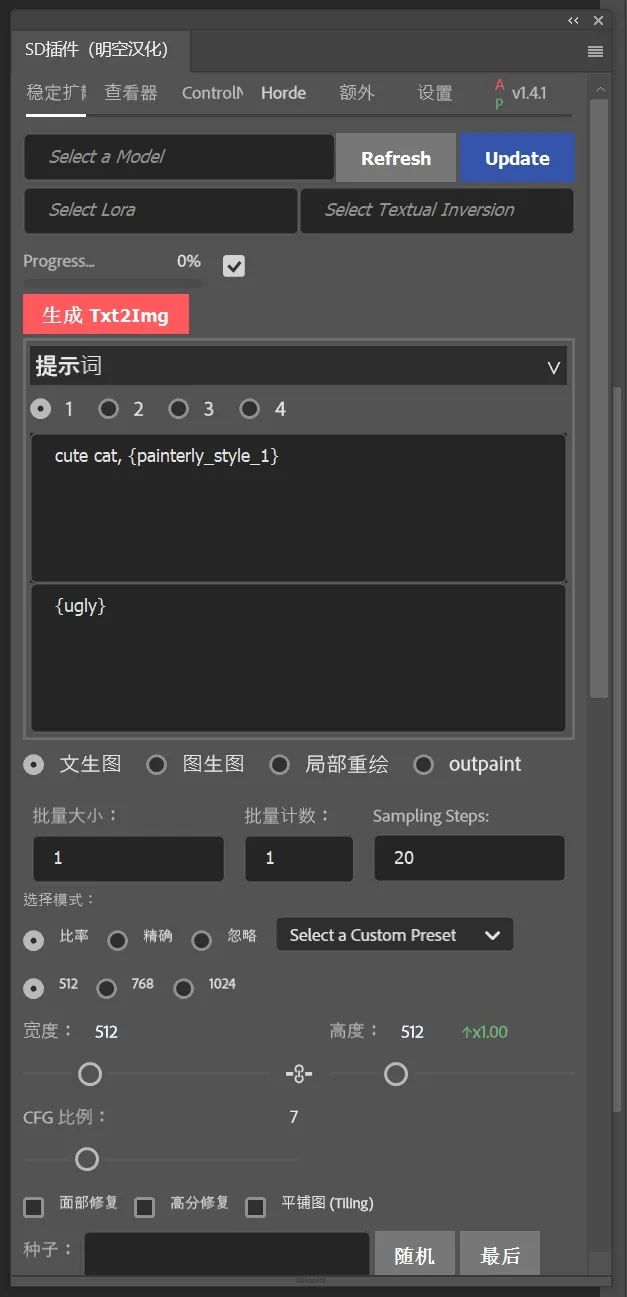
然后在面板的设置中的"SD URL"中输入你Stable Diffusion WebUI的具体地址、并选择"Automantic1111",然后保存。
35.2 文生图和图生图
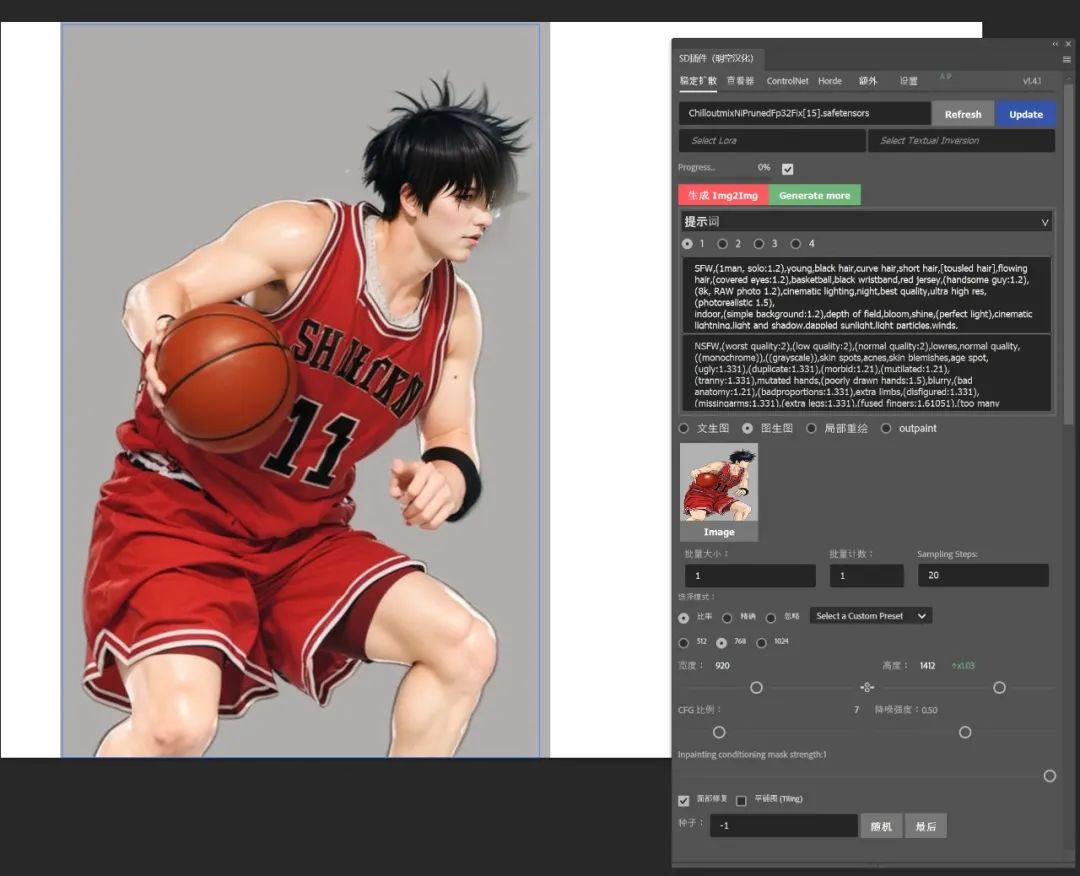
利用这个插件,我们可以很方便的在Photoshop中进行文生图。
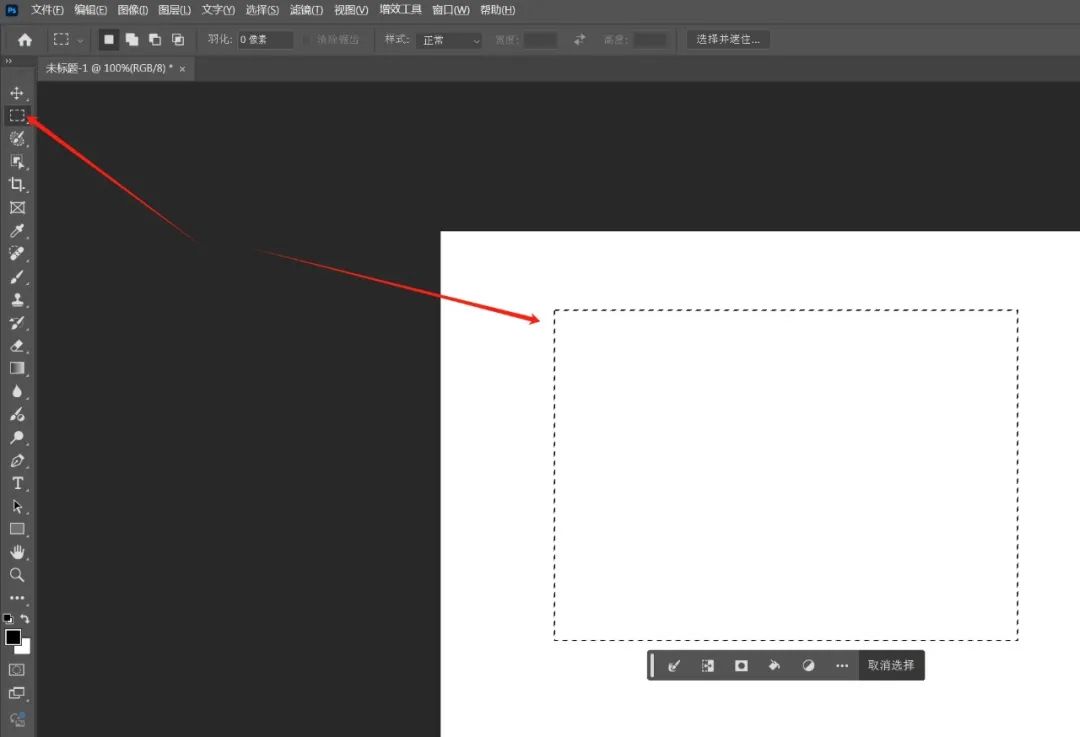
在Photoshop的画布中,利用选框工具画出你想要生成图像的位置和大小。
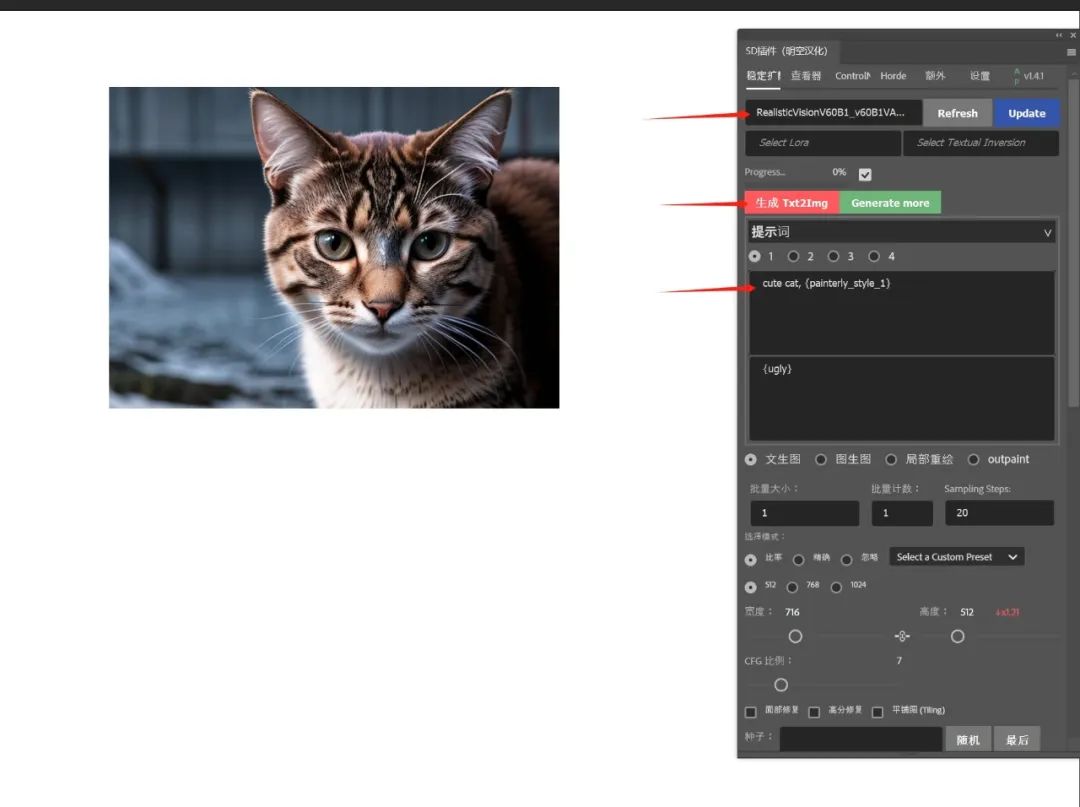
然后在插件面板中选择大模型、输入提示词,然后点击生成便成功了。
插件面板中的其他选项同样对应了SD WebUI的其他各项功能,具体的使用方法和SD WebUI一致,你可以参考我之前的教程。
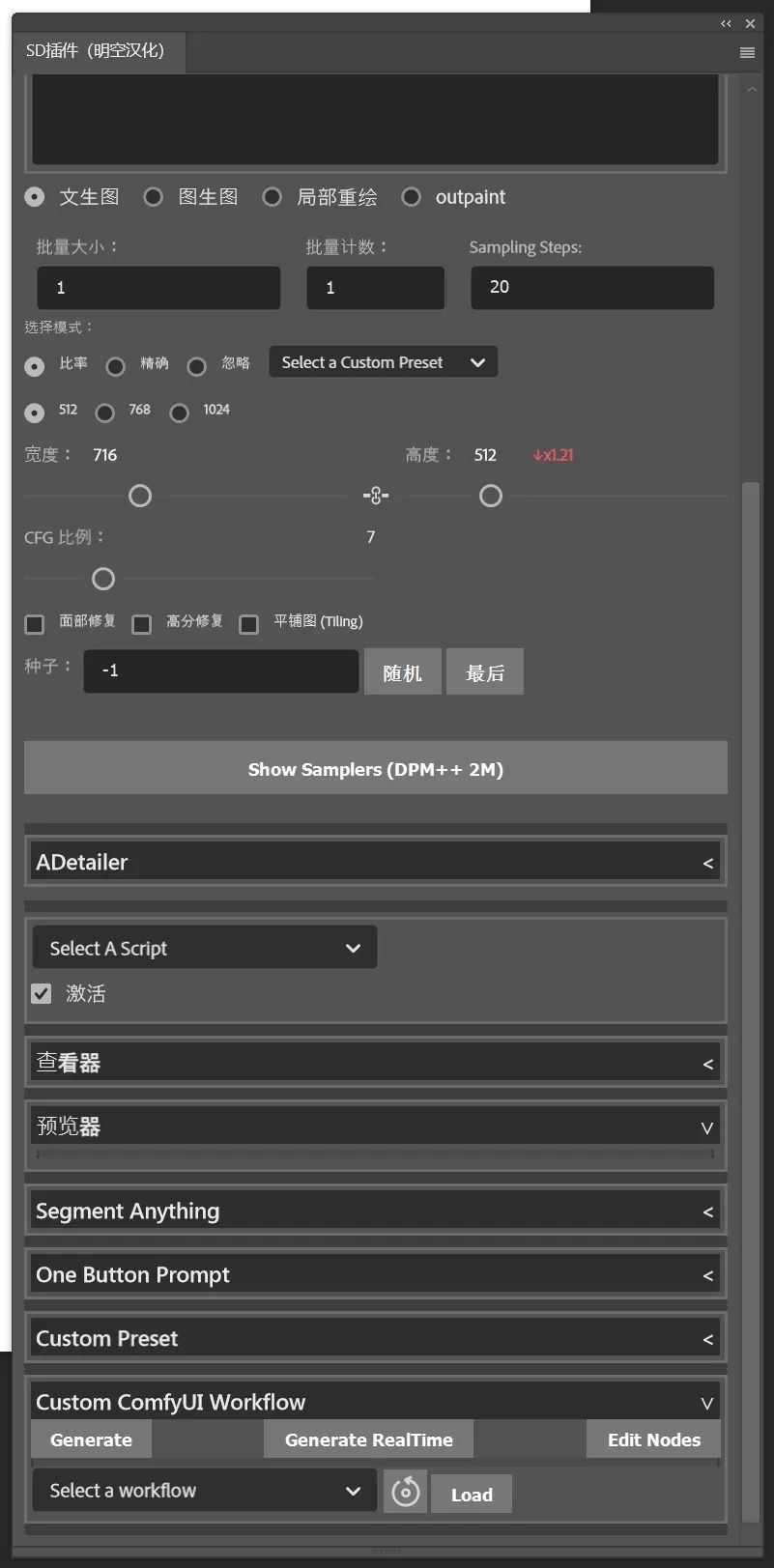
这里需要提到的是图片生成的三种模式,比率模式有512、768、1024三种分辨率,它们分别对应SD1.5、2.1、XL的基础模型尺寸。精准模式下不会自动换算尺寸,完全按照你选区的大小作为绘制尺寸。忽略模式则以你插件窗口中设置的尺寸为准,生成后填充至画面上的选区内。我们可以点击"Generate More"继续生成新的图片。
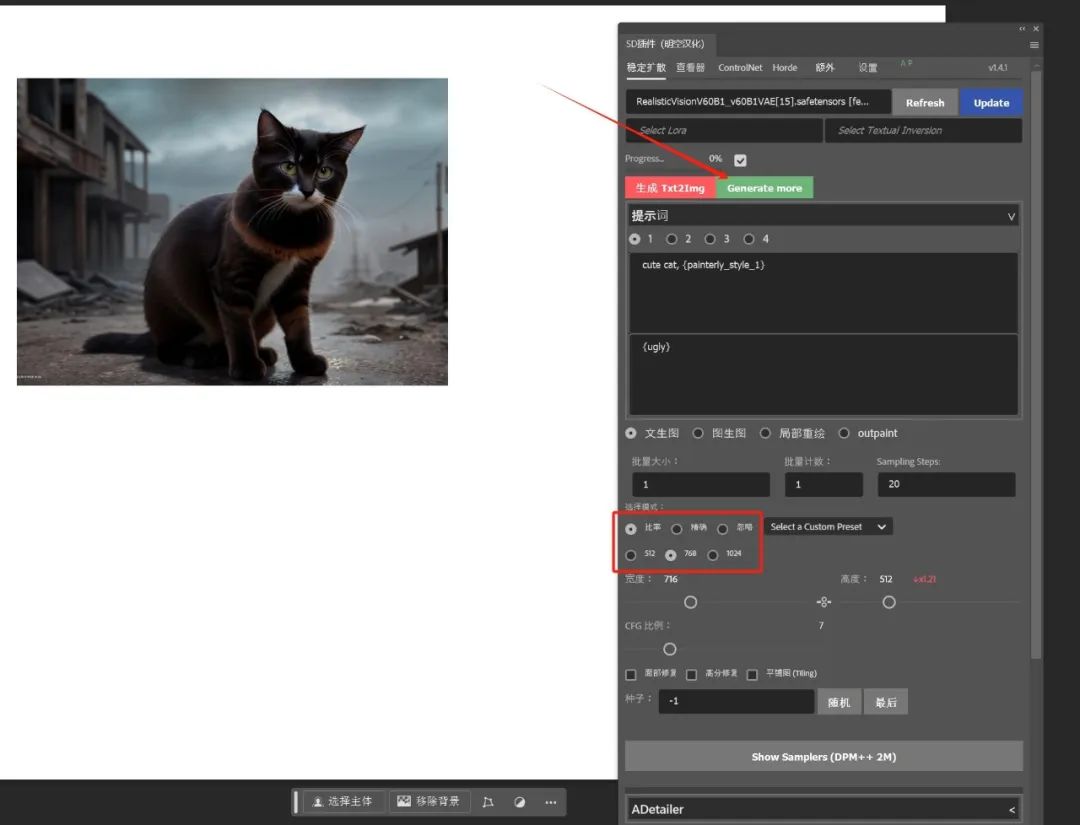
当我们批量生成了多张图片后,可以在下方选择我们需要的图片,并进行保留、删除等操作。
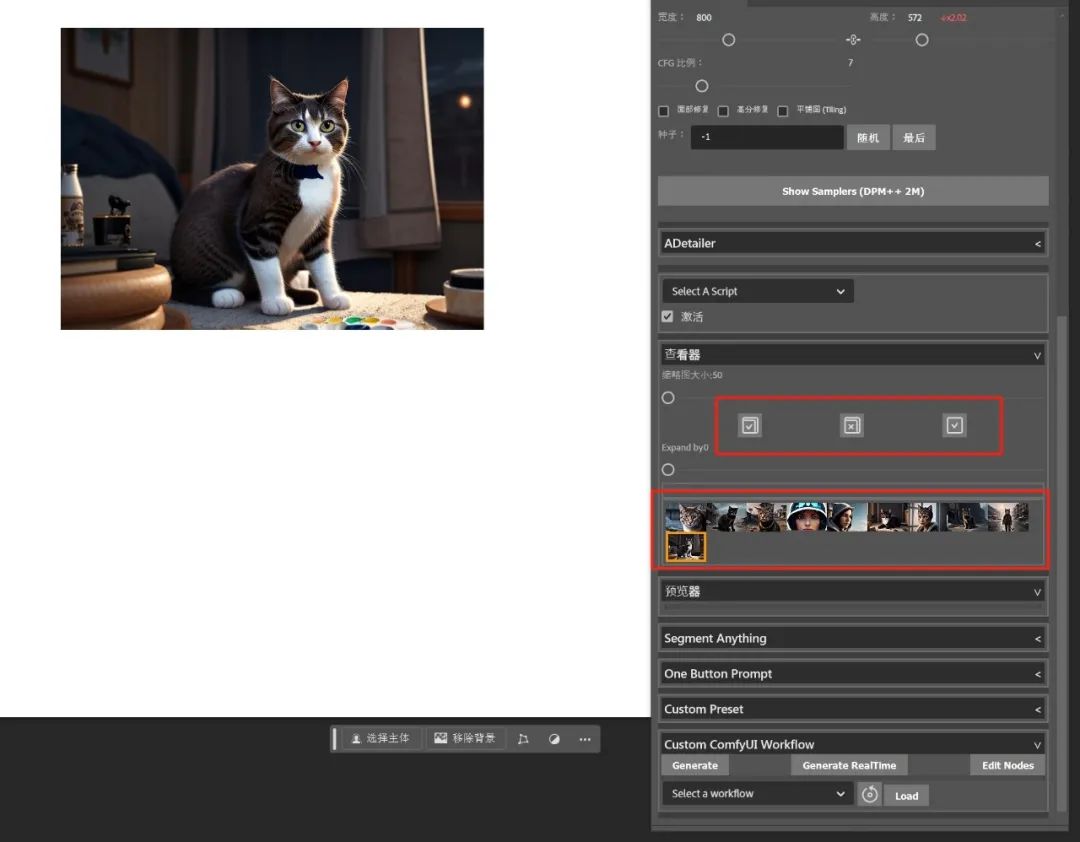
图生图的话,我们只要在插件面板中选择"图生图",然后在PS画布中导入一张图片,用选框工具选取你需要的部分,并输入相应的提示词,选择一个合适的降噪强度(重绘幅度)。
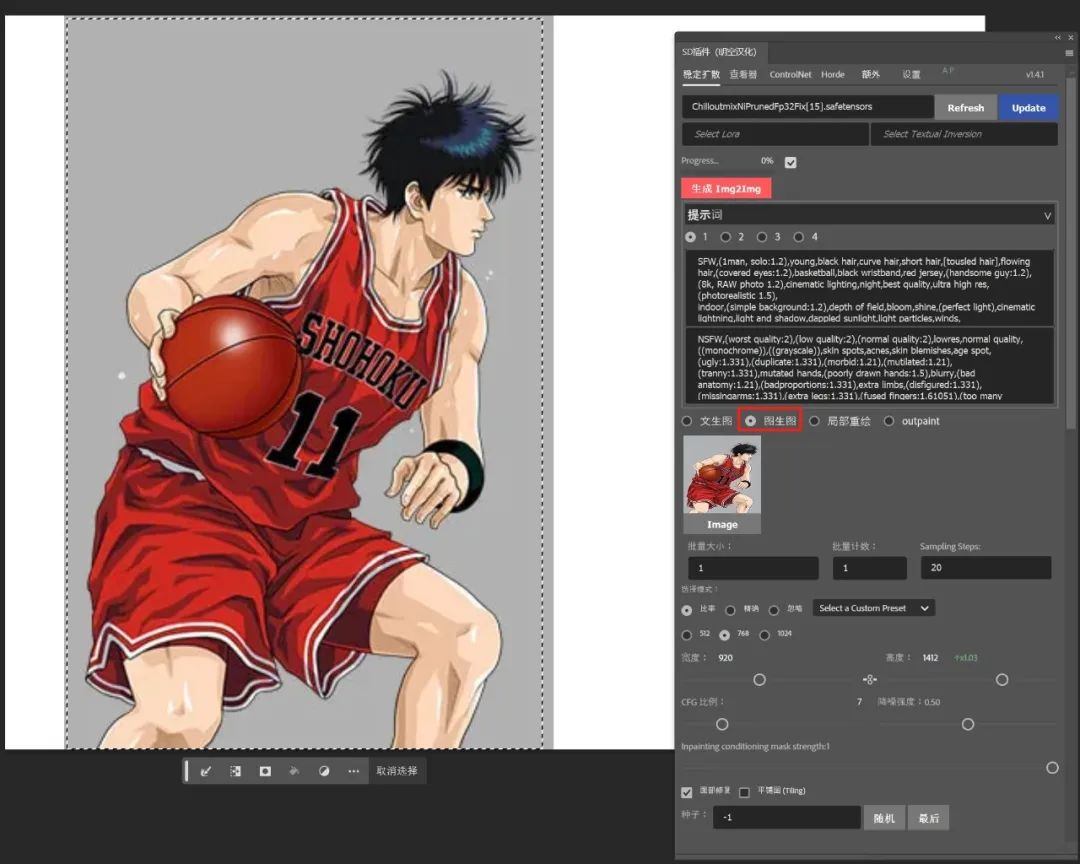
适当配置面部修复等其他选项后点击生成,便能通过图生图生成新的图片了。
整理和输出教程属实不易,觉得这篇教程对你有所帮助的话,可以点击👇二维码领取资料😘

35.3 局部重绘和外绘扩图
当我们选择"局部重绘"选项时,PS会自动创建一个半透明的图层。
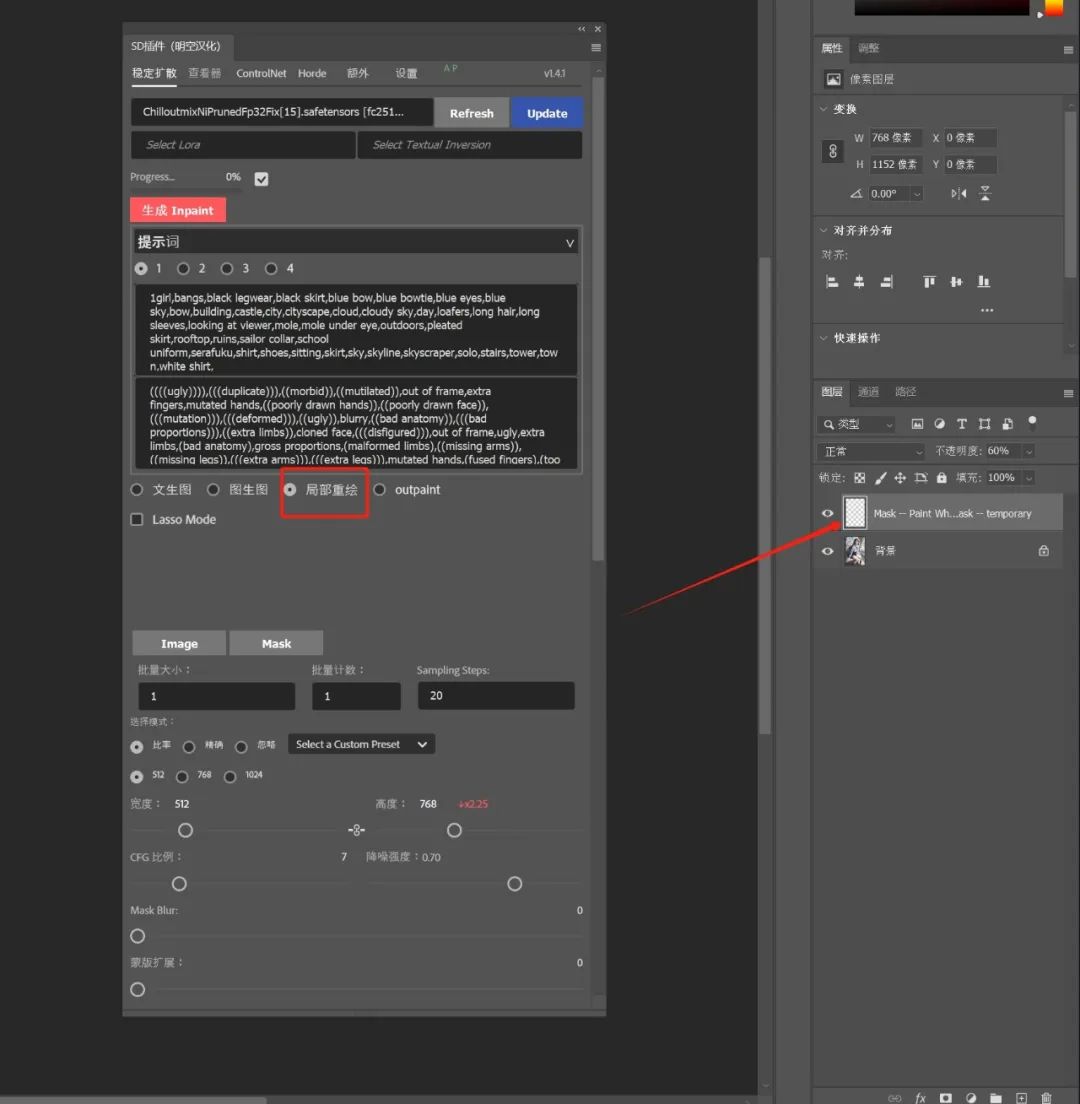
我们可以利用笔刷、选区等工具来选择并进行局部重绘。
我这里先点击原始图层,利用PS中独有的对象选择工具自动识别并选择人物。
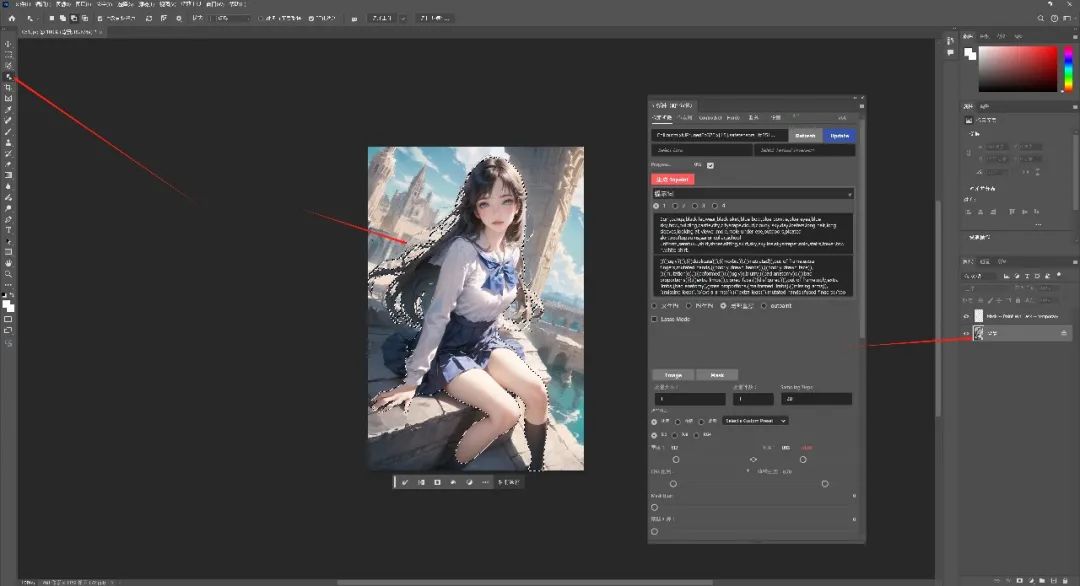
然后点击半透明图层,用笔刷工具将人物区域填满。

然后输入提示词等参数便可以对填充区域进行重绘了。
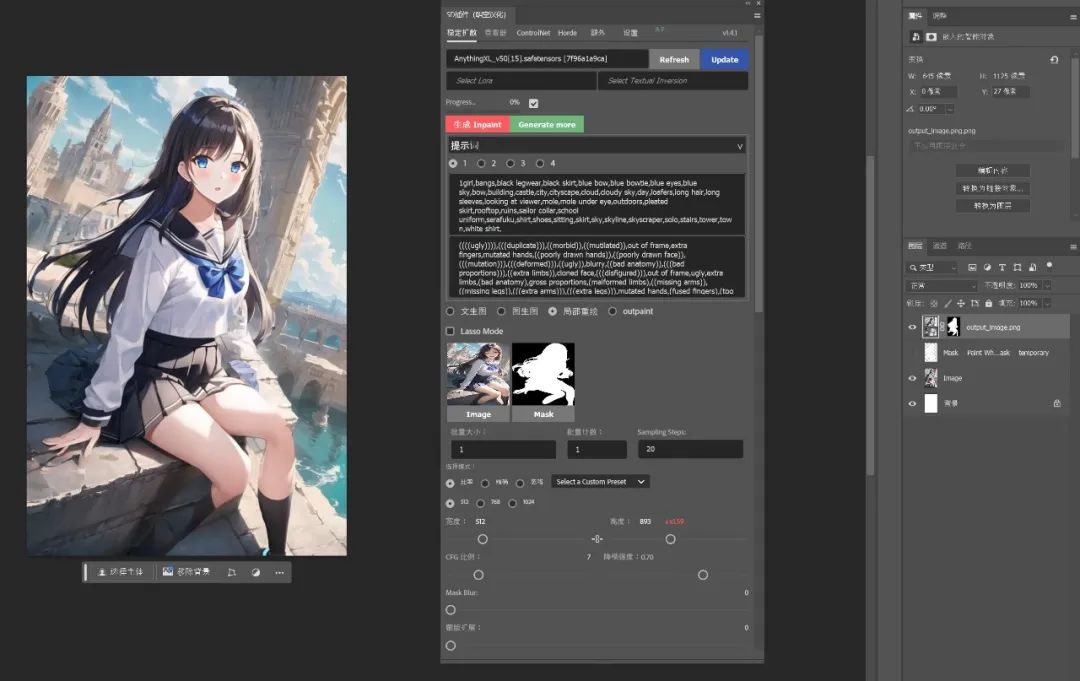
如果需要对背景进行重绘,只需要在原始图层识别对象后按"Ctrl+Shift+i"反向选择区域。
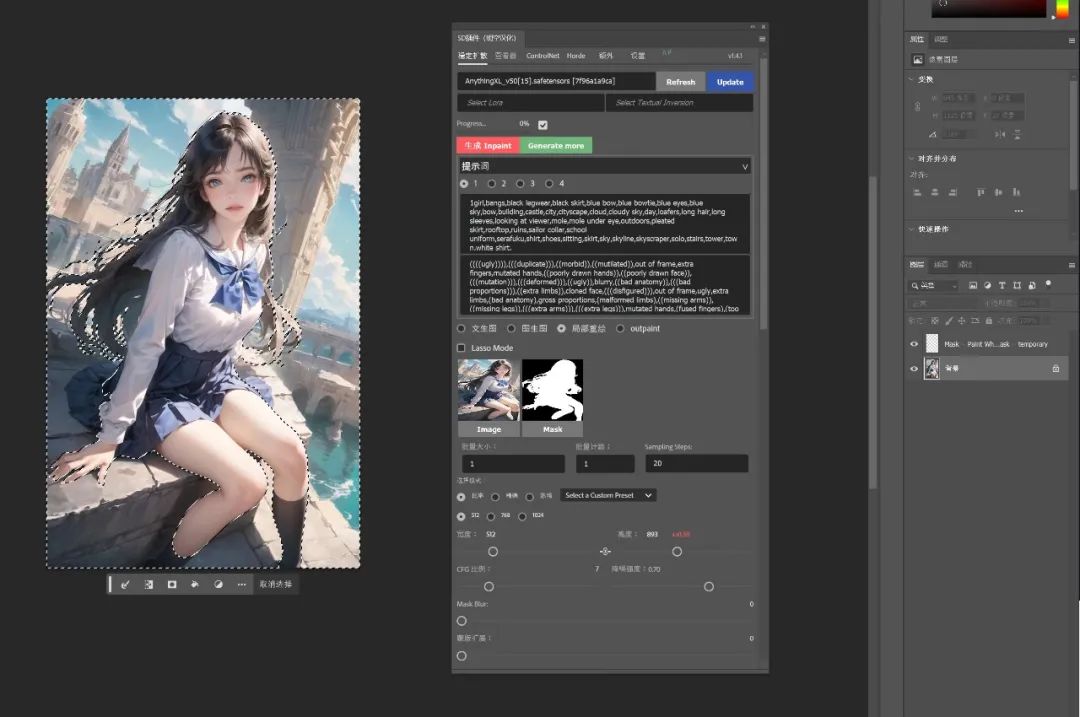
然后选中半透明图层,并将其填满。
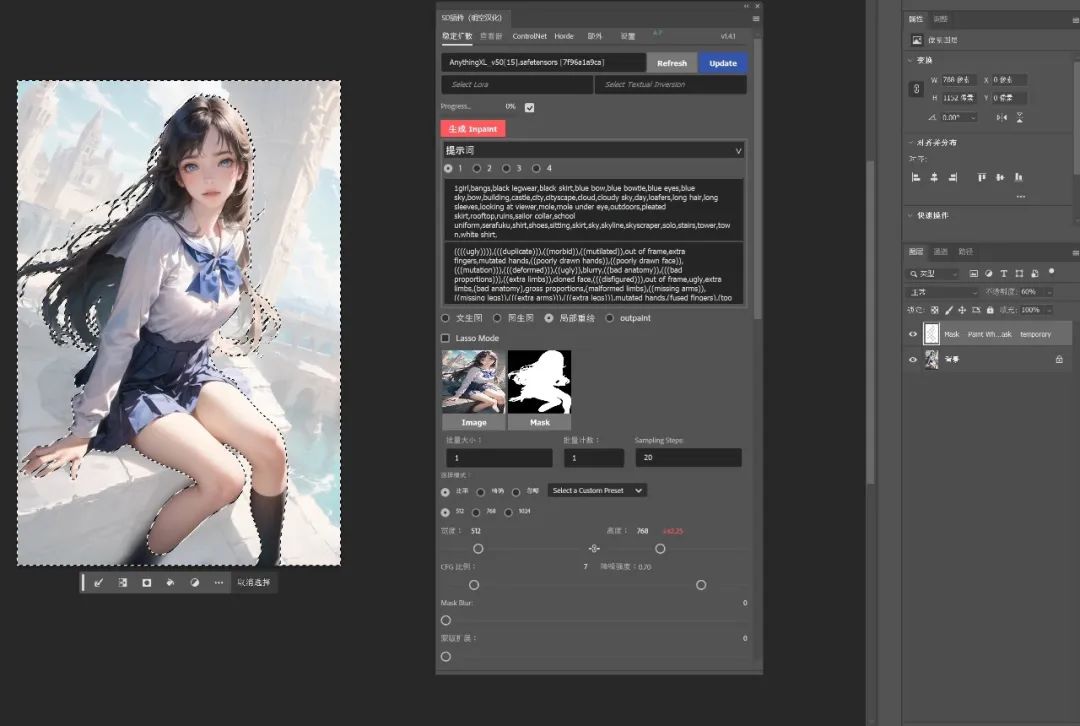
然后输入提示词并生成,便能看到背景被重绘了。
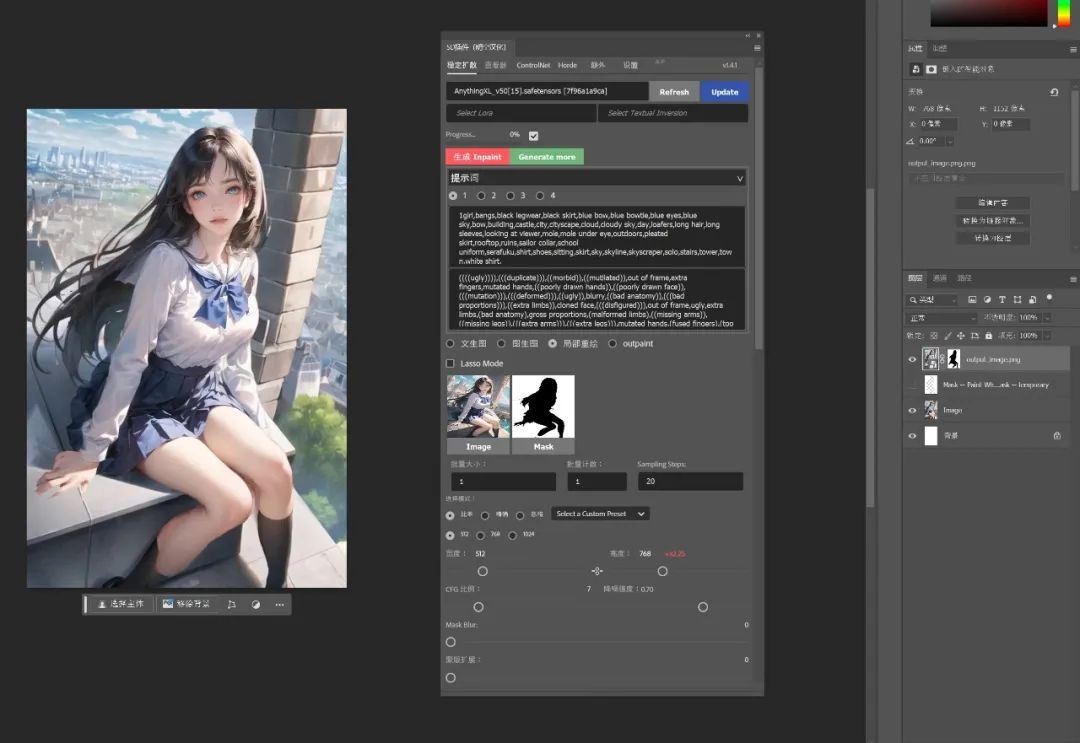
接下来要介绍的就是大名鼎鼎的创成式填充了,Adobe官方的创成式填充需要支付高昂的费用并且中国大陆地区还不能使用,我们只要一个插件便能让PS拥有这项功能。
首先我们需要在Stable Diffusion WebUI中安装"openOutpaint extension"这个插件。
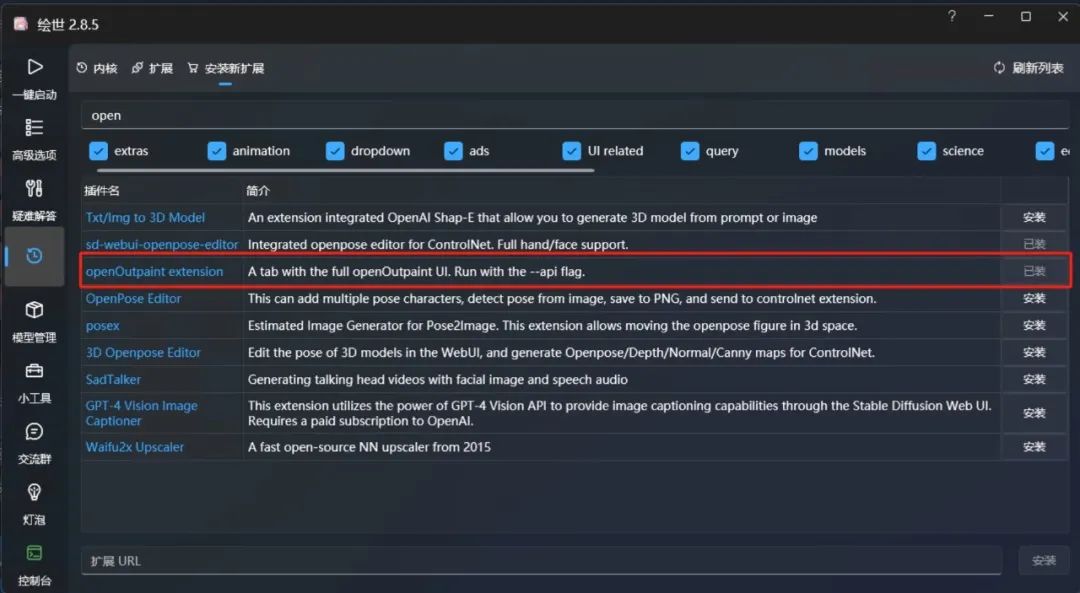
然后我们便可以使用Photoshop中SD面板中的Outpaint功能了。首先注意不要让图层锁定。

然后使用裁剪工具将图片扩大,留出你希望创成式填充的区域。
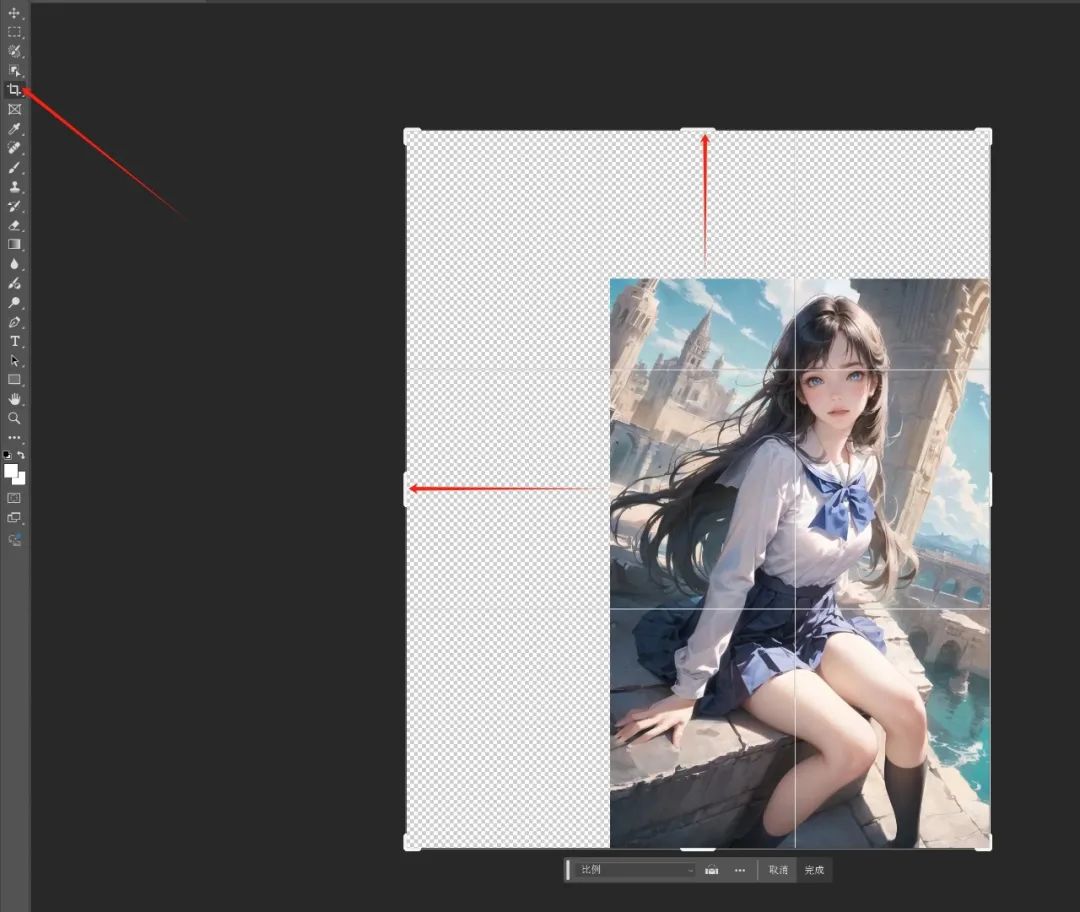
双击确认后(或点击"完成")后,按Ctrl+A全选图片,选择"Outpaint"功能,输入提示词(也可以不输)、调整蒙版扩展和羽化的数值。
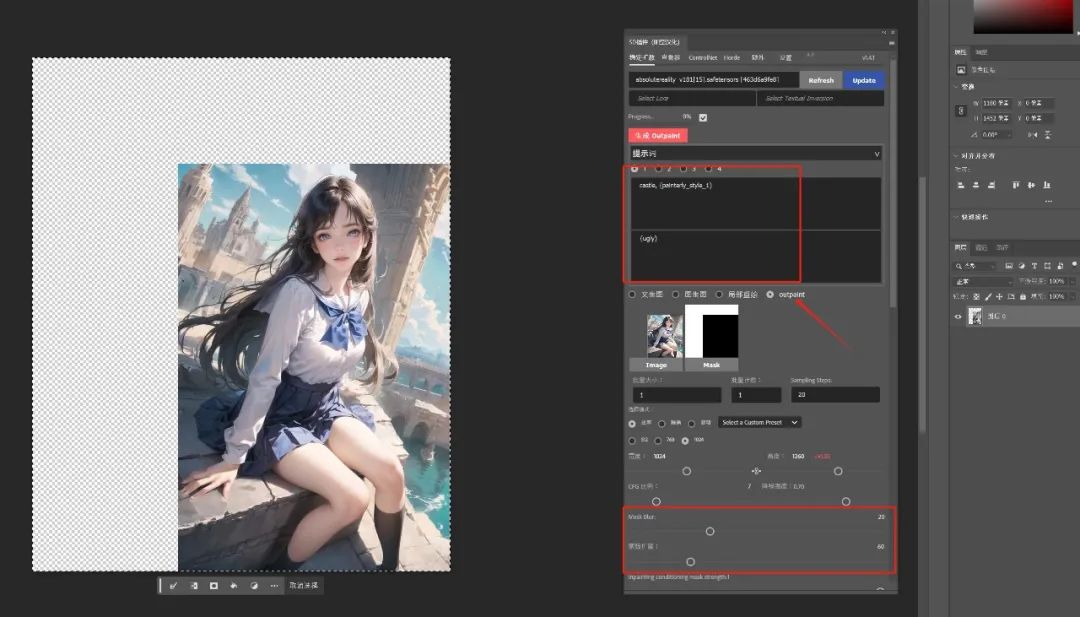
最后点击生成即可。
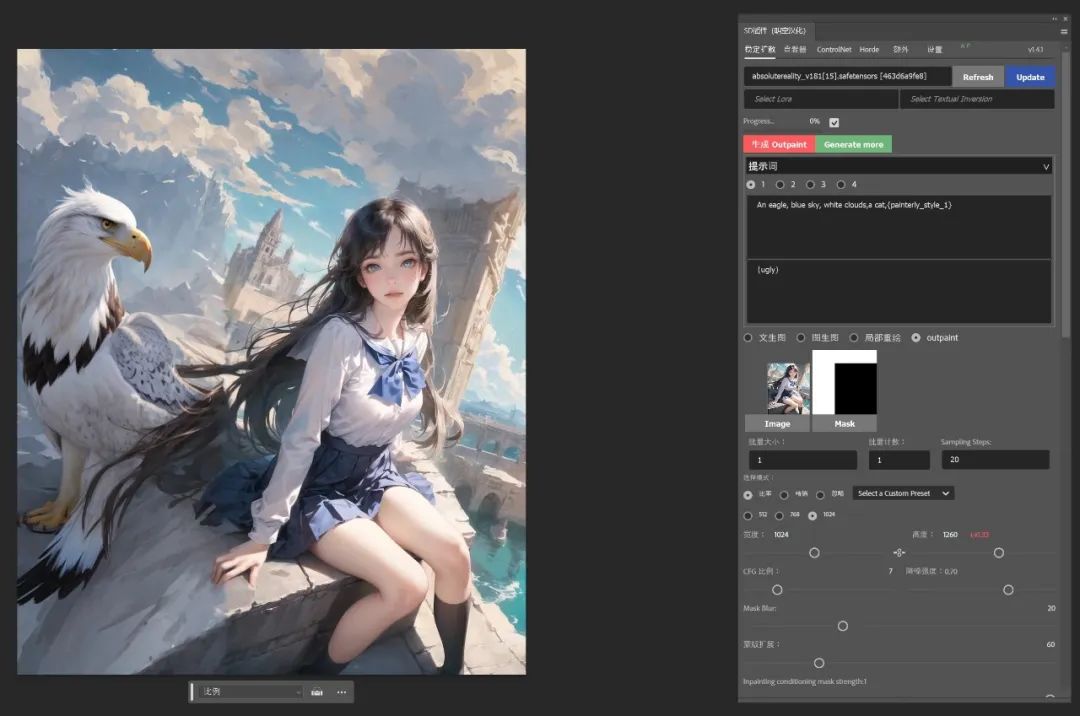
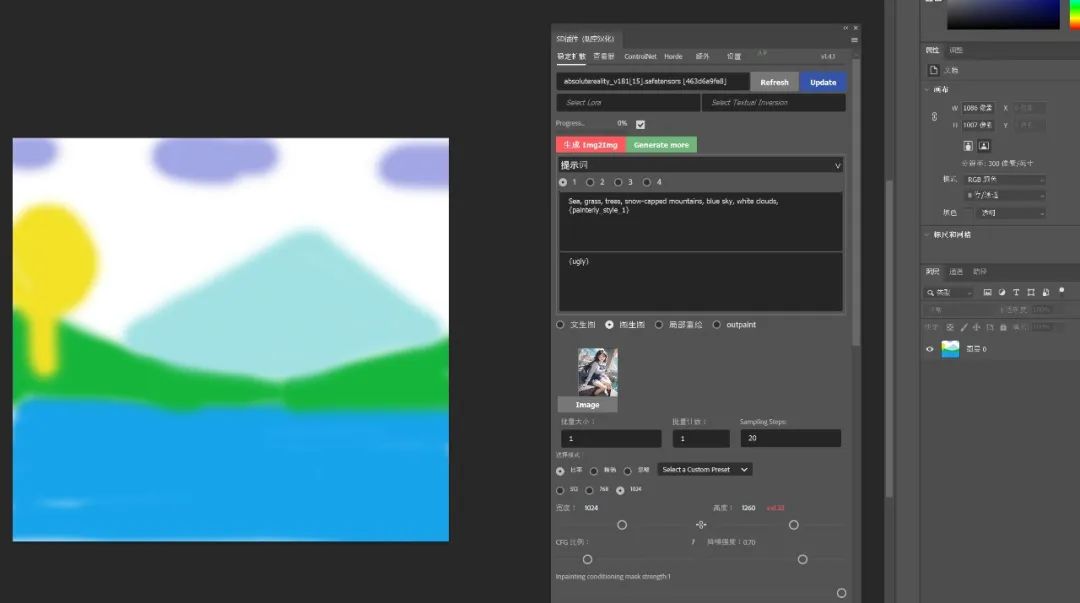
由于PS绘图的便利性,我们完全可以利用PS简单绘图后再直接图生图重绘。最关键的是它重绘的内容是在新的图层中,这样就方便了我们后期的进一步修改。
35.4 ControlNet基本用法
首先要说明的是,截至最新版本的PS插件1.4.1,它只支持最高版本为**1.1.447(版本号:1b94e47)**的ControlNet插件,所以请大家在SD WebUI中将ControlNet切换到此版本以下再使用。
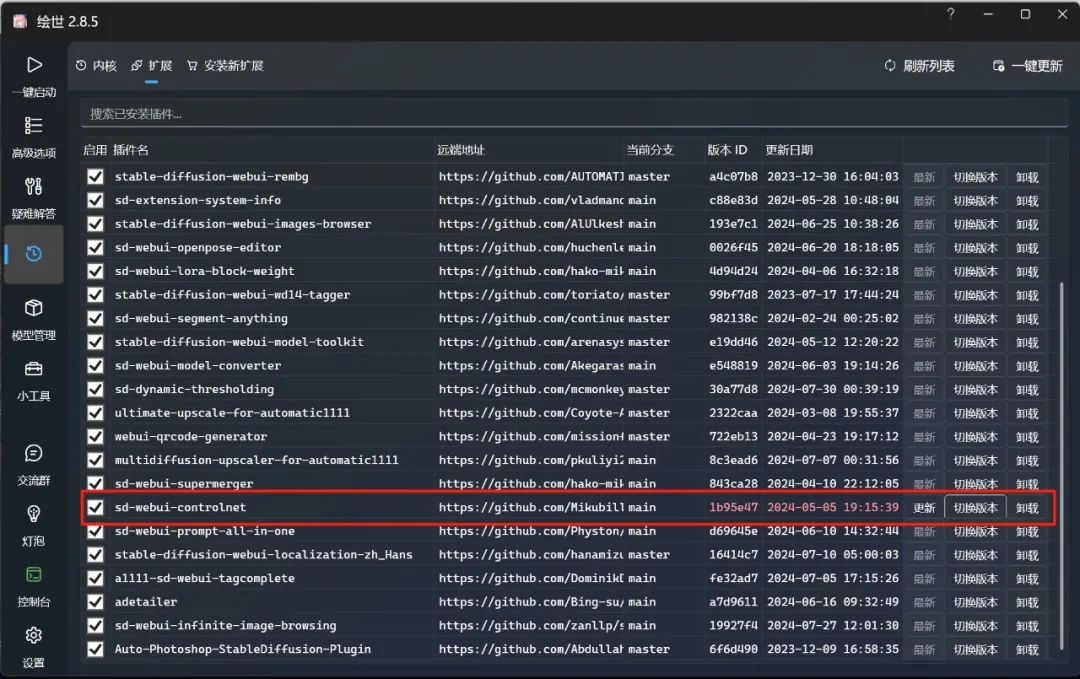
我们可以在Photoshop的SD插件中使用ControlNet,选择ControlNet卡片栏后,就可以和SD WebUI中一样使用ControlNet的功能了。比如我们导入一张图,在勾选启用ControlNet后选择Openpose的模型,框选画布中的图片后点击"设置原始图"和"预览注释器",便能看到ControlNet识别了图片中人物的姿态。
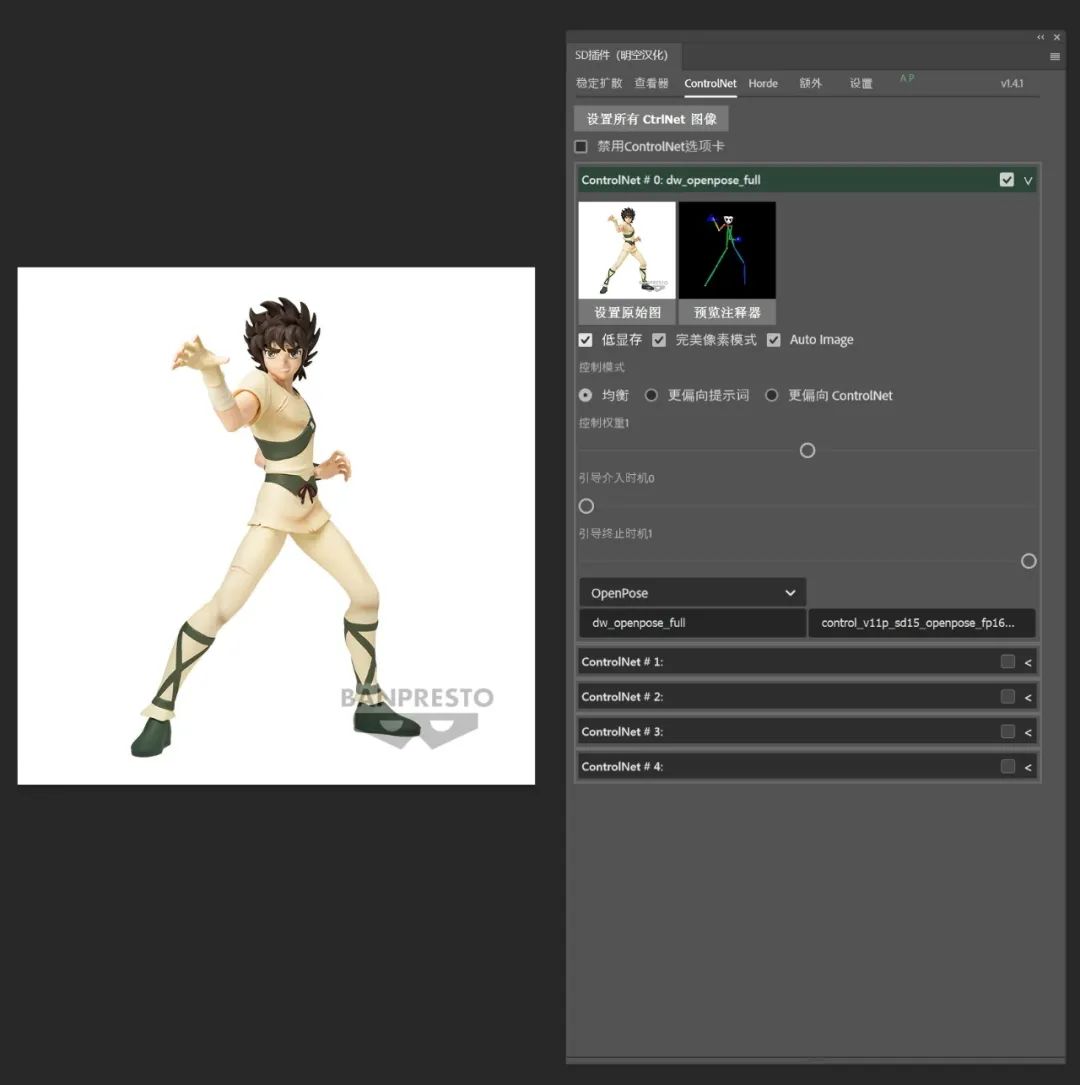
然后输入提示词后,便能在ControlNet的引导下生成你需要的人物图像了。

由于我们是在PS中调用ControlNet,所以我们可以更为方便的直接进行线稿的勾绘、上色,简直方便到爆炸。直接绘出一张线稿图,然后使用ControlNet中的Lineart预处理器。
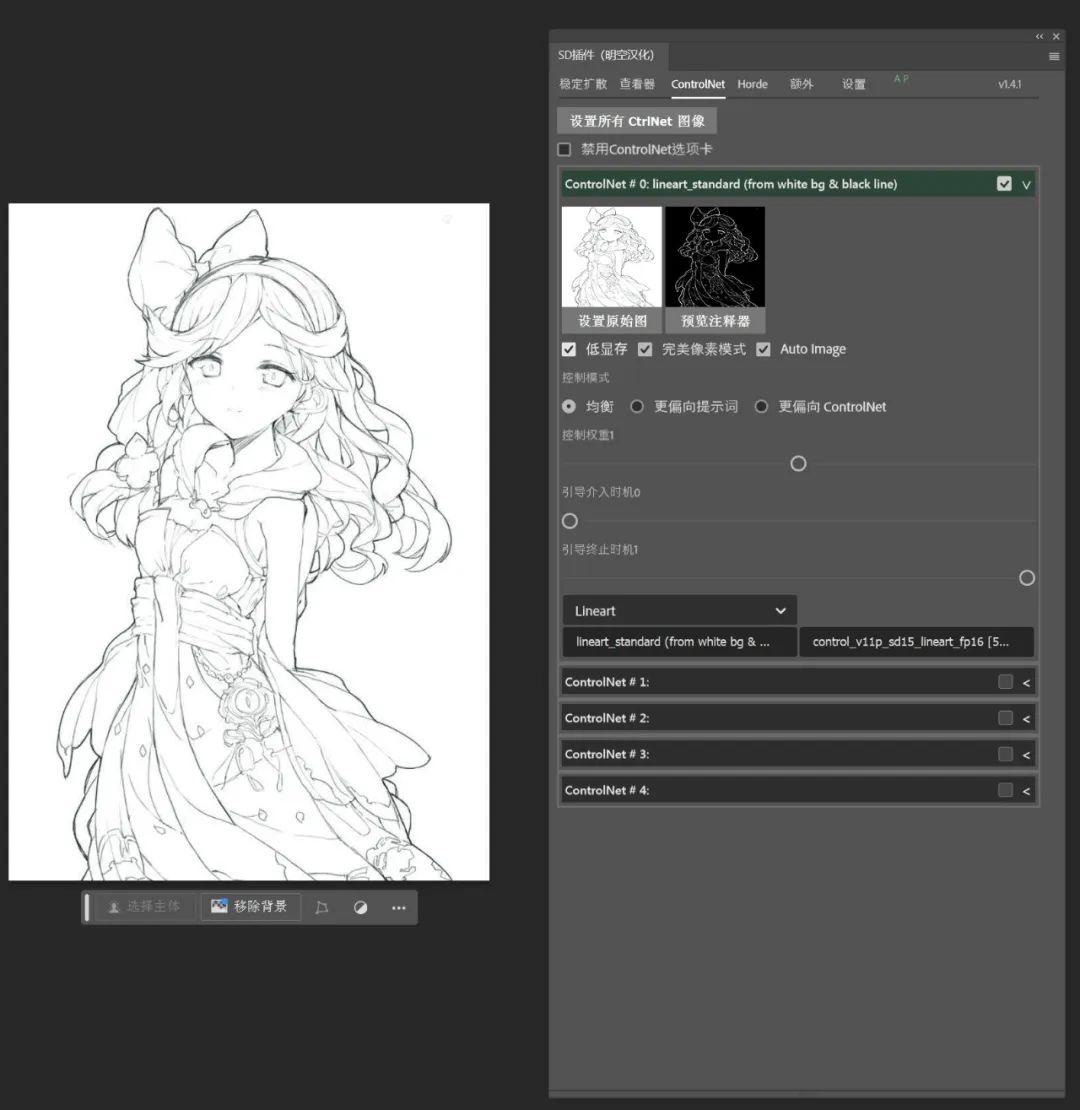
在文生图的提示词中输入相应提示词即可给这张图片上色。
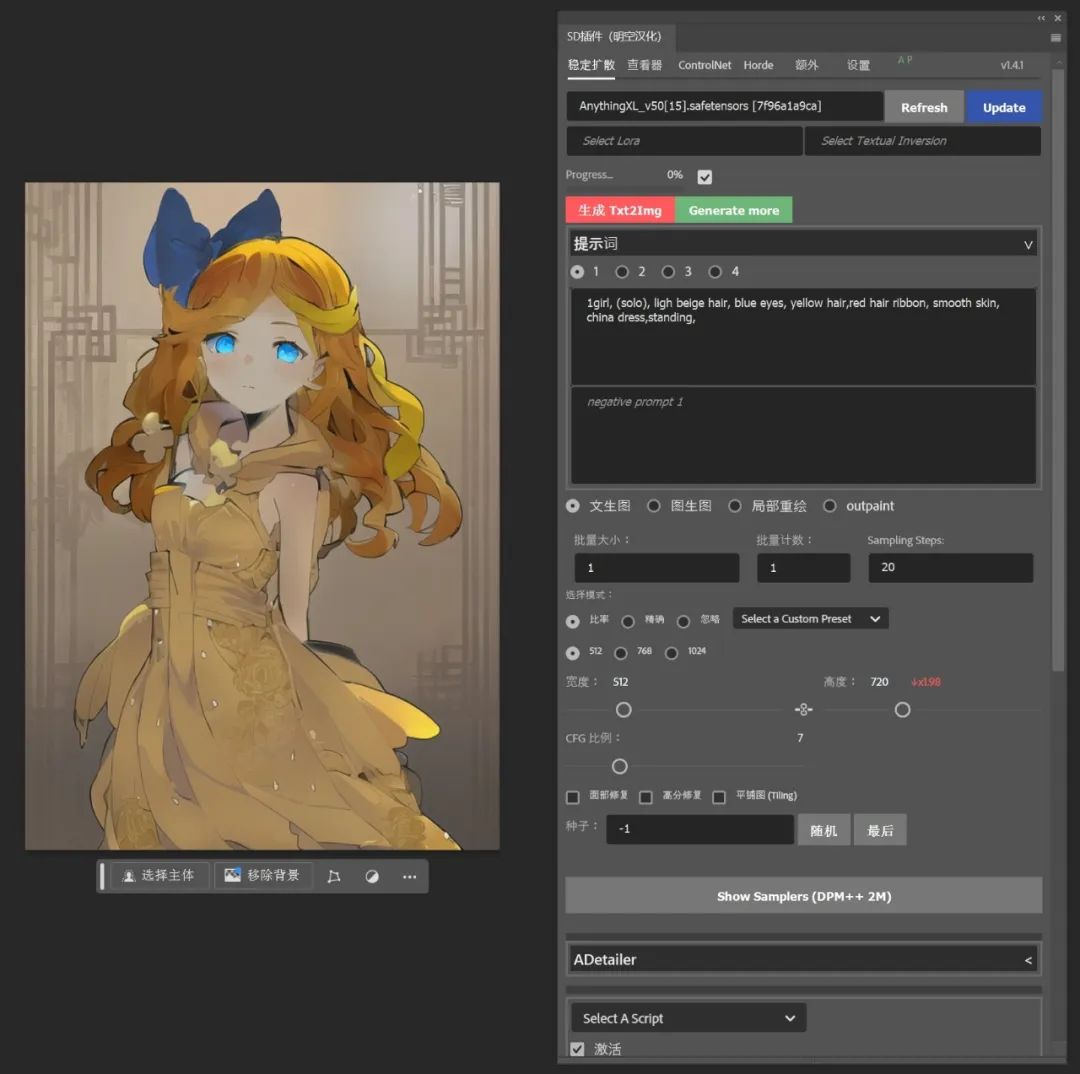
或者在图生图中对图片进行简单涂鸦上色点缀后让AI完成完整的上色。
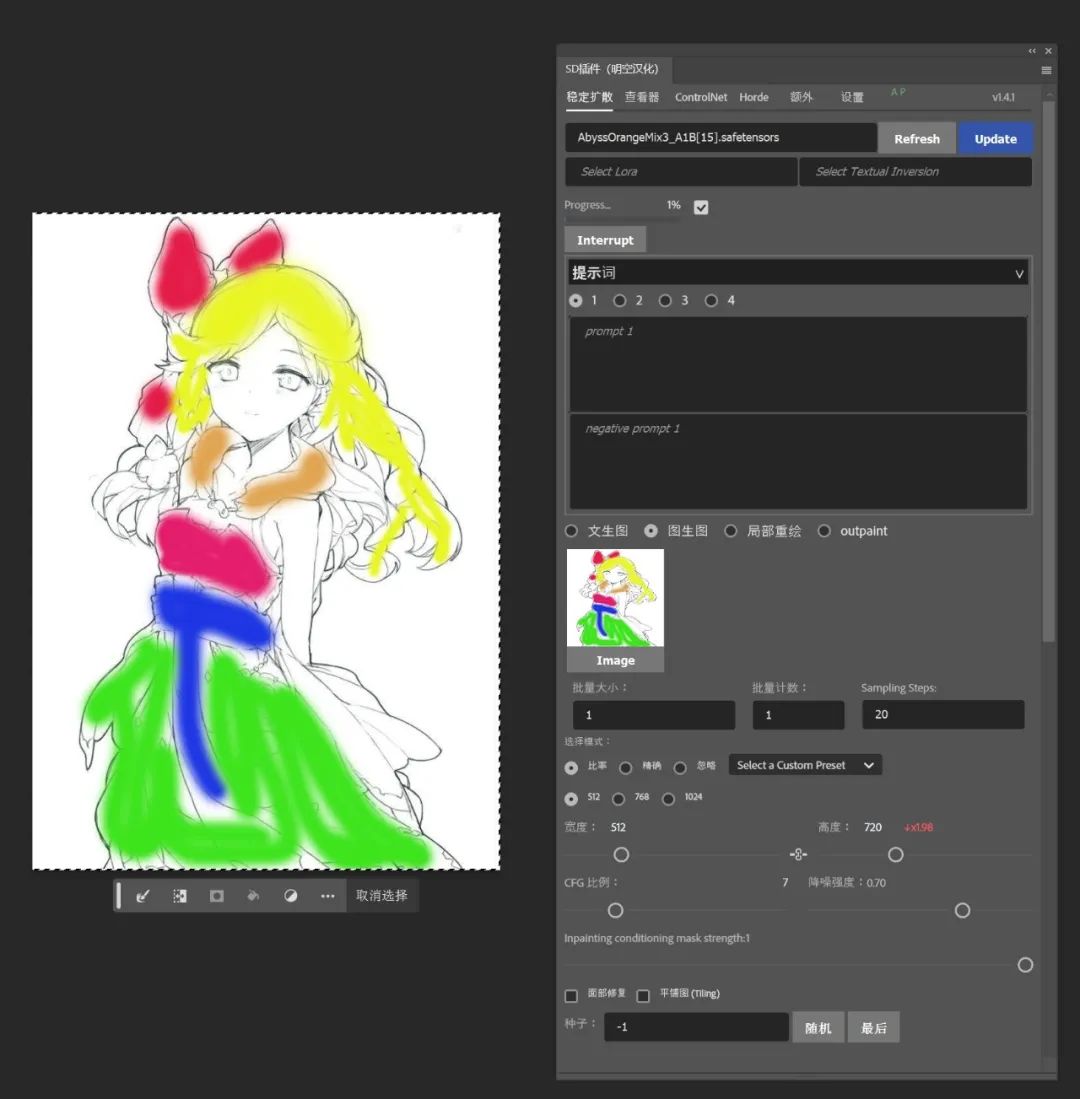
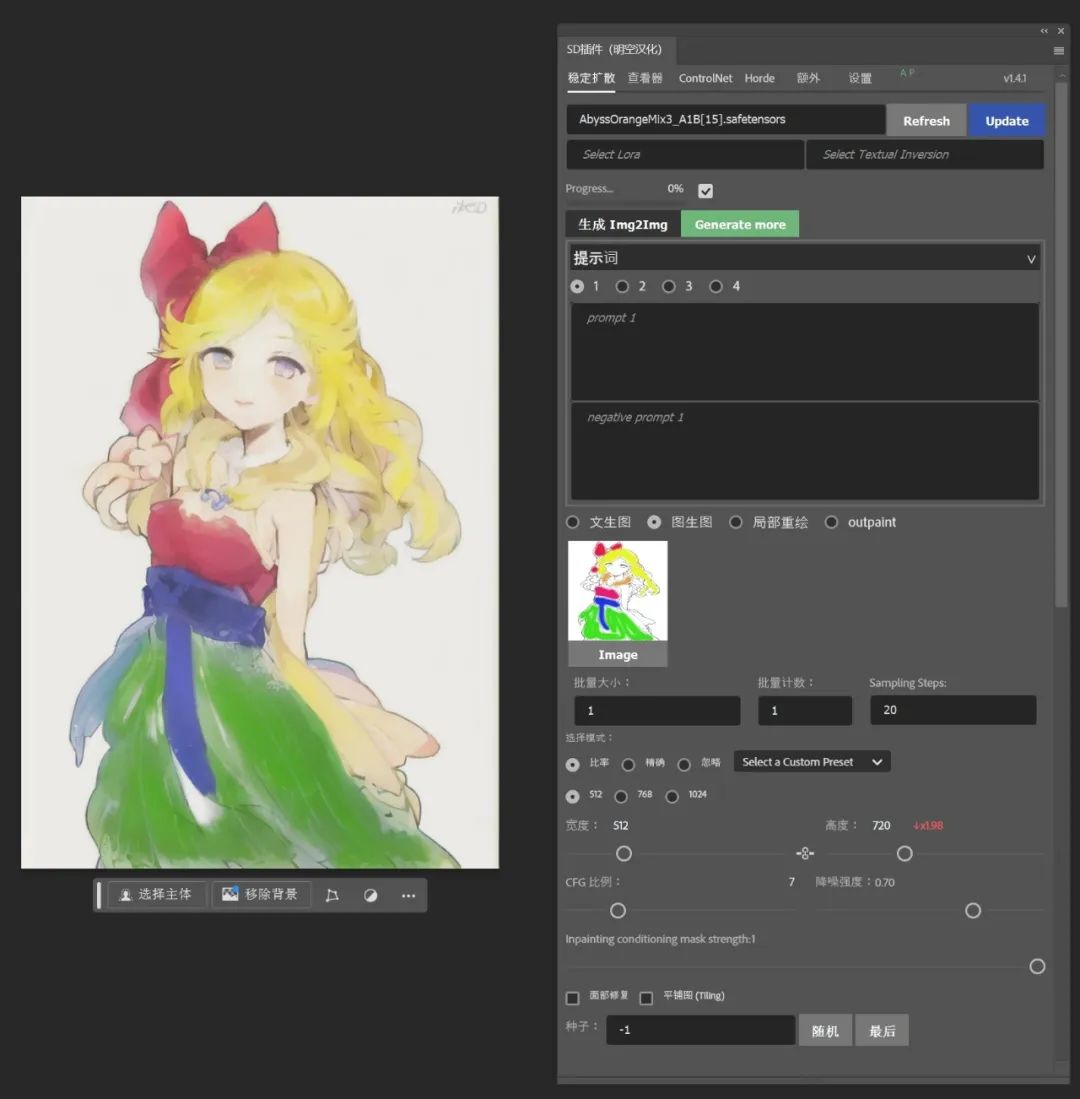
在图生图中甚至可以将其转换成真人照片。
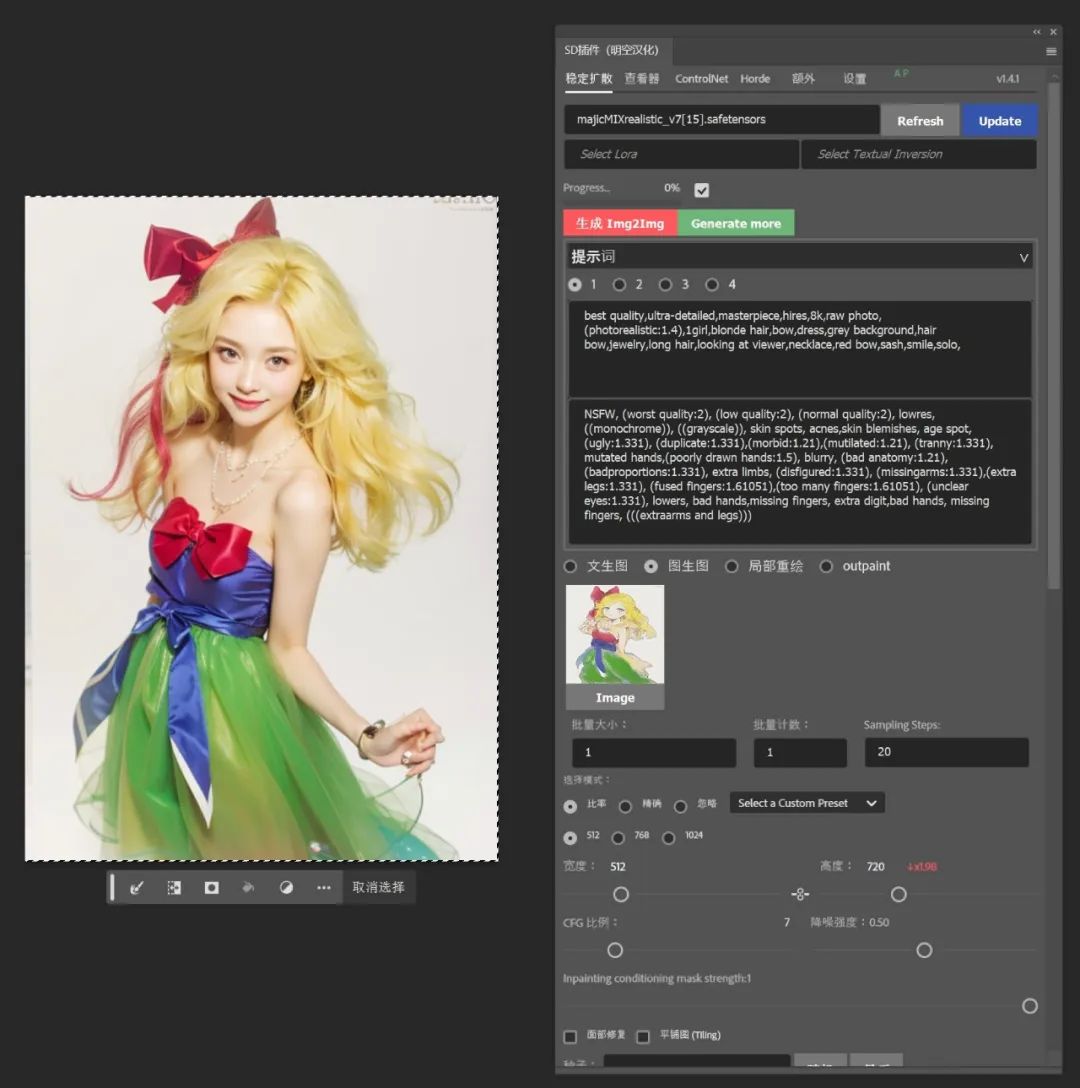
如果你觉得自己绘画能力不够出色也没关系,随便勾勒出大致的线条,然后使用Scribble预处理器,记得调低权重和引导结束时机。
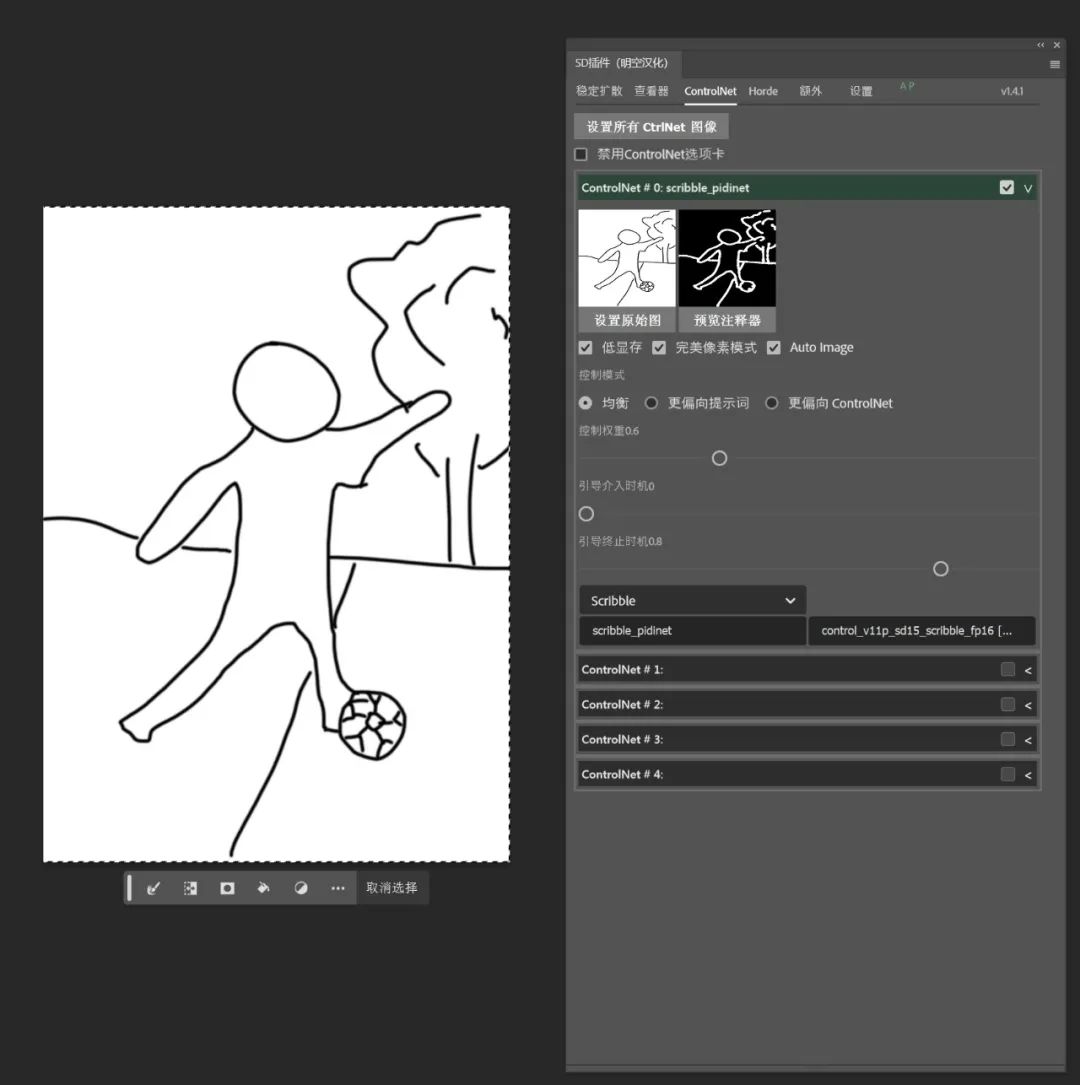
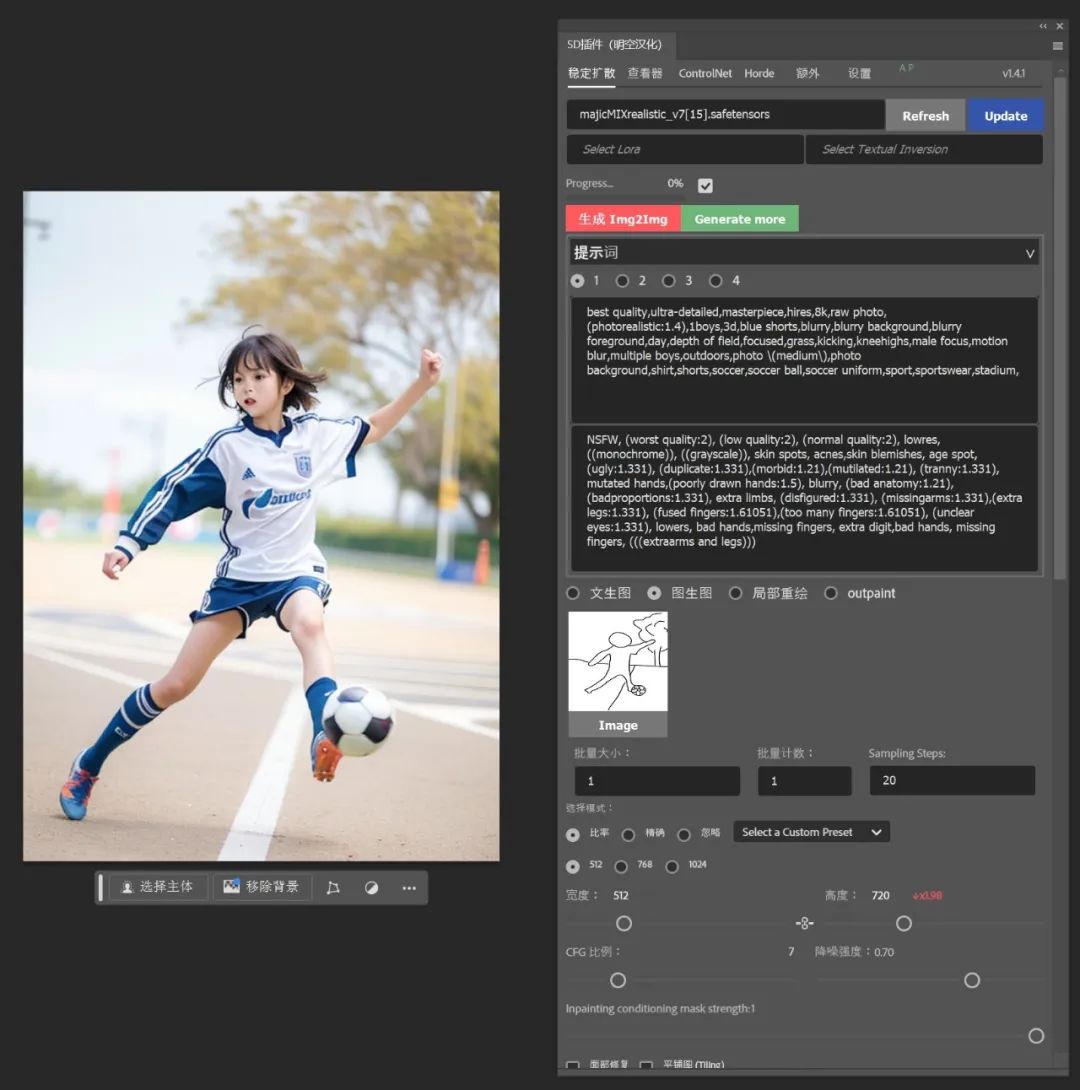
在图生图中输入提示词并提高重绘幅度,即可生成不错的图片啦,如果对脸部不满意记得开启ADetailer。
35.5 ControlNet Seg详解
Seg 是 ControlNet 的一个具体应用场景,其中 “Seg” 代表“Segmentation”(分割)。它通过分割图像来精确控制图像生成的各个部分,从而达到用户预期的效果。
ControlNet Seg 的主要特点:
**1.分割图像的控制:**ControlNet Seg 允许用户使用分割图像(通常是图像中的各个部分以不同颜色表示)来指导生成图像。这种方法使得用户可以明确地指定图像中不同区域的内容,例如背景、前景、物体等,从而生成符合分割图像布局的结果。
**2.高精度图像编辑:**利用 ControlNet Seg,用户可以对图像的各个部分进行精确的编辑,例如修改物体的形状、位置或添加新的元素,同时保持图像的整体风格和质量。
**3.与稳定扩散模型结合:**ControlNet Seg 基于稳定扩散模型(Stable Diffusion),这是一种广泛用于生成高质量图像的深度学习模型。通过添加 ControlNet,用户可以对图像生成过程进行更细粒度的控制,而不仅仅依赖随机生成的结果。
**4.灵活性和可扩展性:**ControlNet Seg 可以与其他控制条件(如边缘检测、姿态估计等)结合使用,从而提供更为灵活和多样化的图像生成方式。
ControlNet Seg可以将图中的物体识别成色块,然后通过色块来生成类似的物体。
示例:
导入一张图片,在ControlNet中选择Seg的预处理器,可以看到预览图中,Seg将图片中不同的物体识别为不同的色块,每一种色块即对应某种物体。
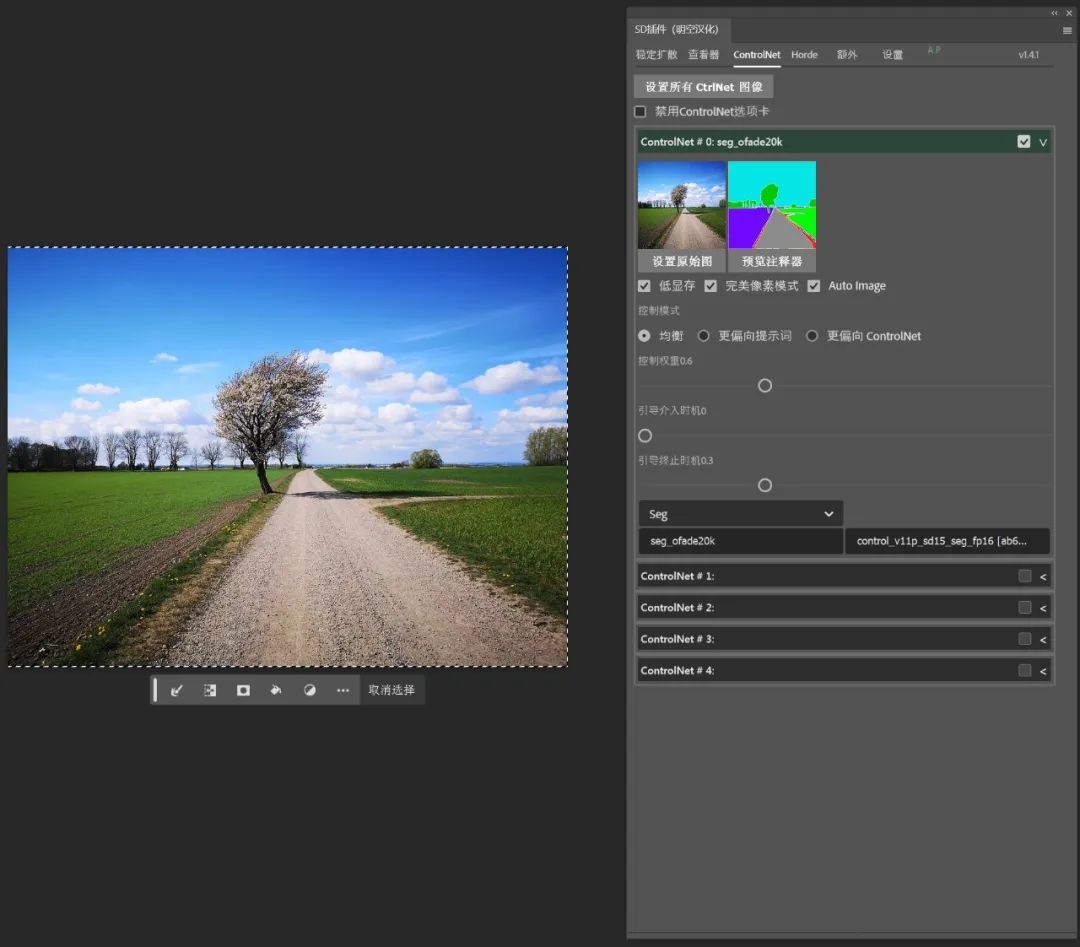
如果想知道每一种颜色具体对应的什么内容,我们可以通过ControlNet训练的来源网站ADE20K来获得。
也可以使用这份表格整理的具体色号来查询。
在保持所有色块不变的时候,我们可以通过调节权重和重绘幅度来生成和原图类似的图片。
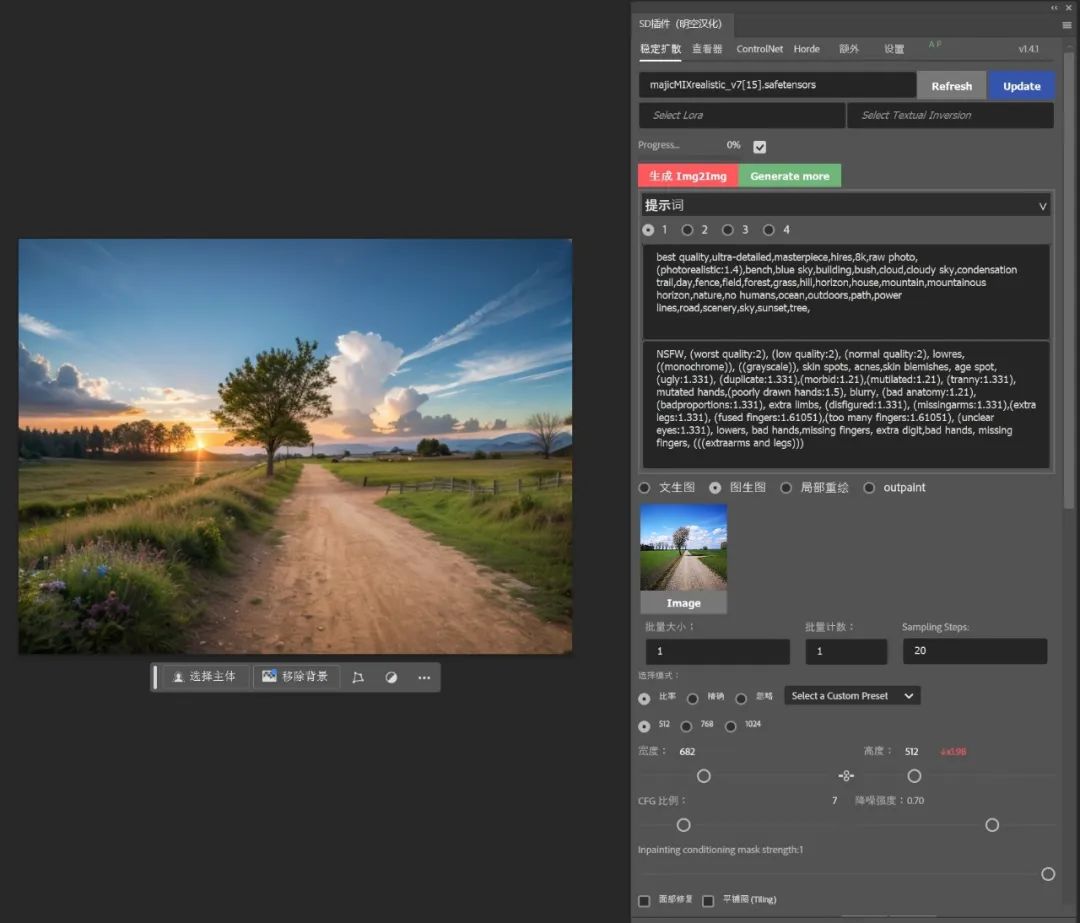
如果我们需要在这个图片中加入一辆汽车,我们只要在预览注释器中点击右下角的按钮将色块画发送到桌布上,然后查询获得bus的色块编号为"#FF00F5",于是使用该色号在图中画出汽车的位置和样子。
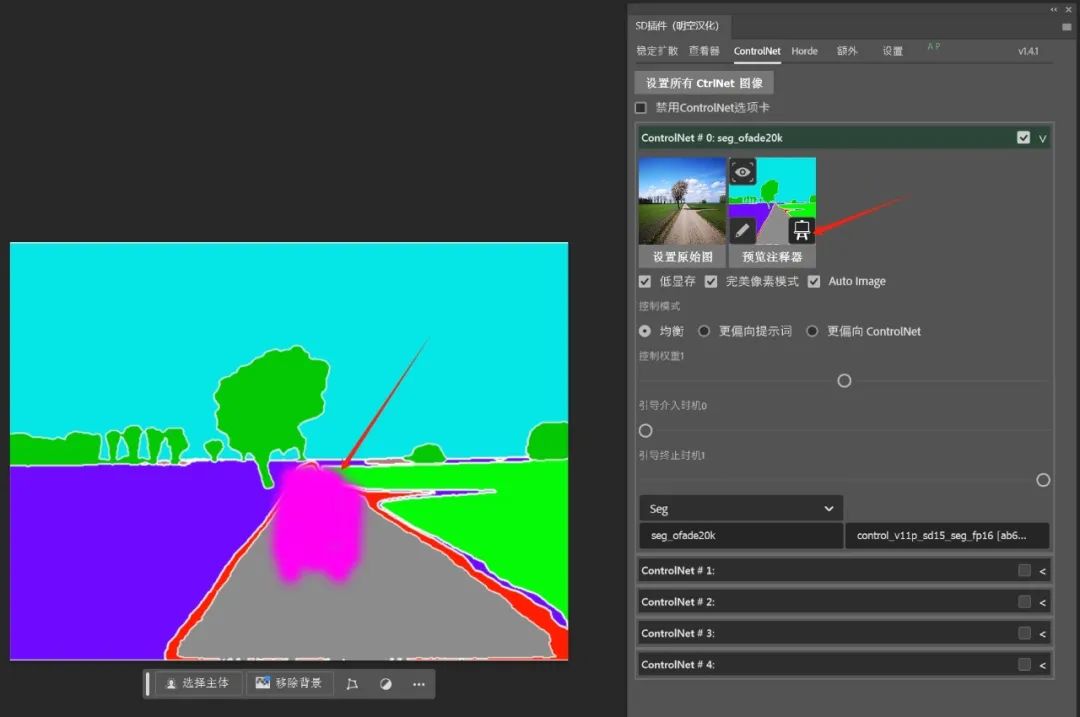
然后将画好的图设置成原始图,并将预处理器模型设置为none。
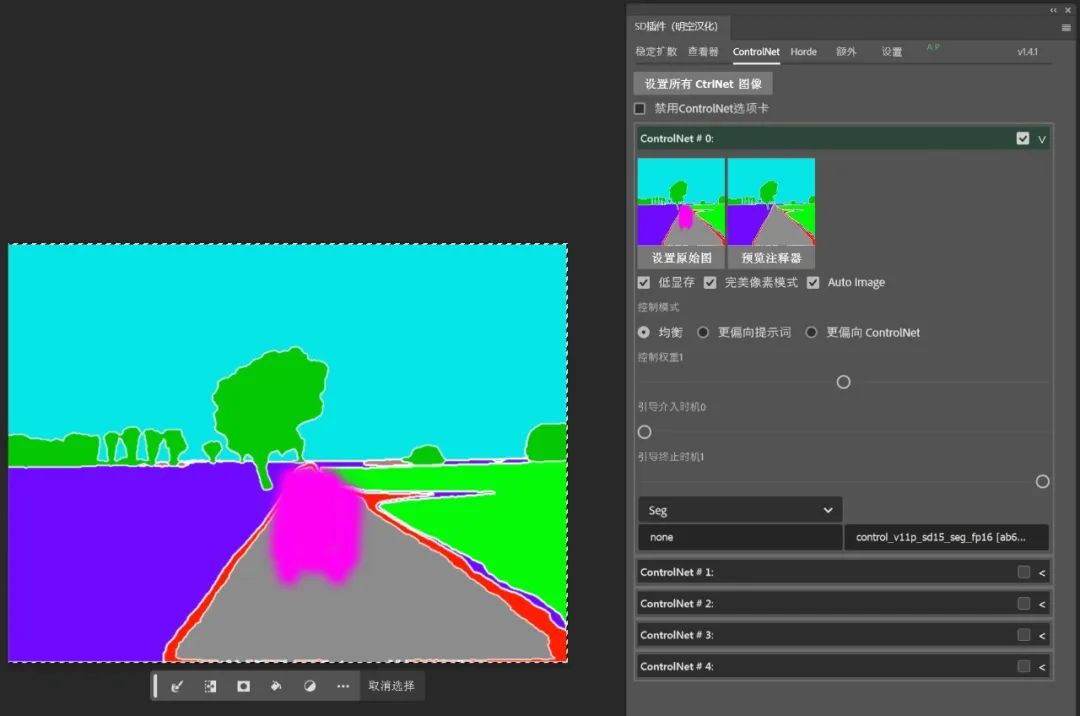
最后将新增的物体的提示词写上,并设置好重绘幅度,点击生成,便能看到画面中新增了一辆汽车。

根据这个特性,我们不仅可以添加物体,也可以删除物体或者改变物体。
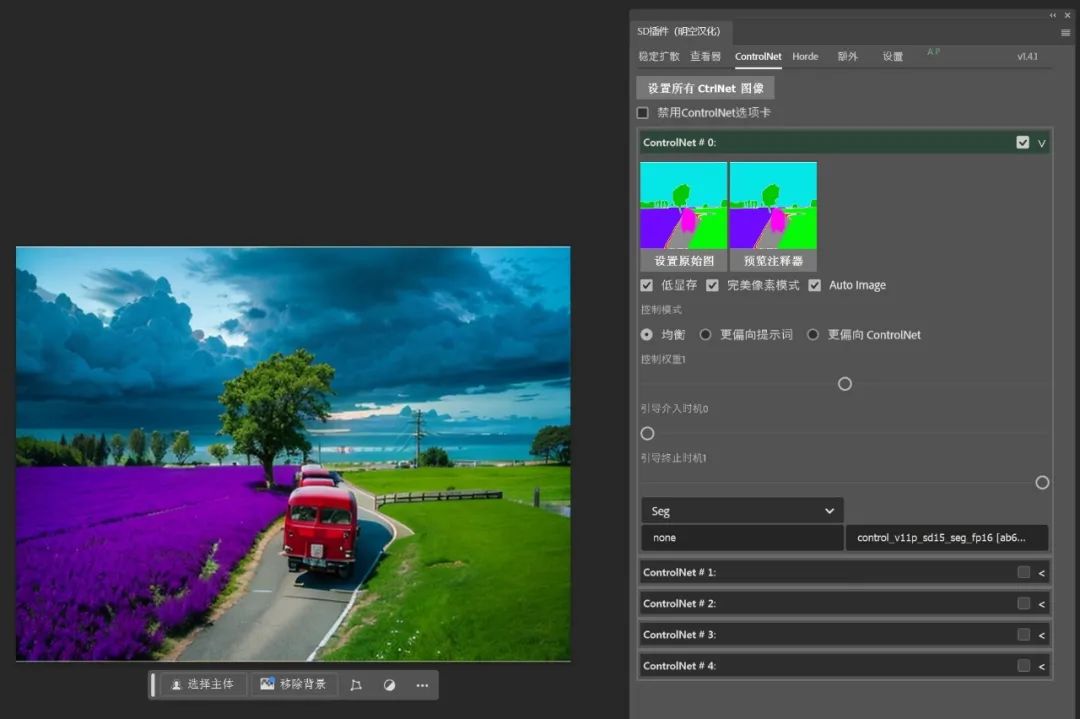
我们也可以完全使用表格中色号来徒手完成绘画、生图。
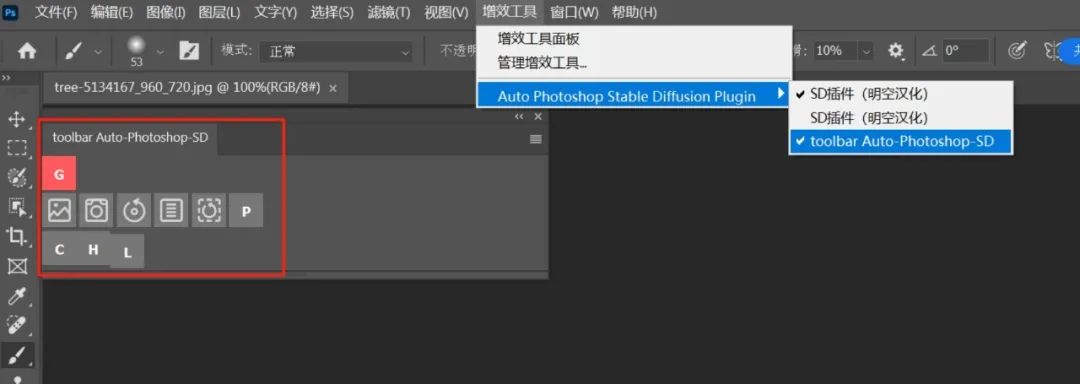
除了以上我们介绍的这些功能外,这个SD的插件还具备了很多功能,比如这个小工具栏,它可以快速的一键实现SD的各种功能。
还有它的智能预测功能,可以调用你在各种出图方式中保存好的常用参数,让你可以方便的在这个基础上微调出图。
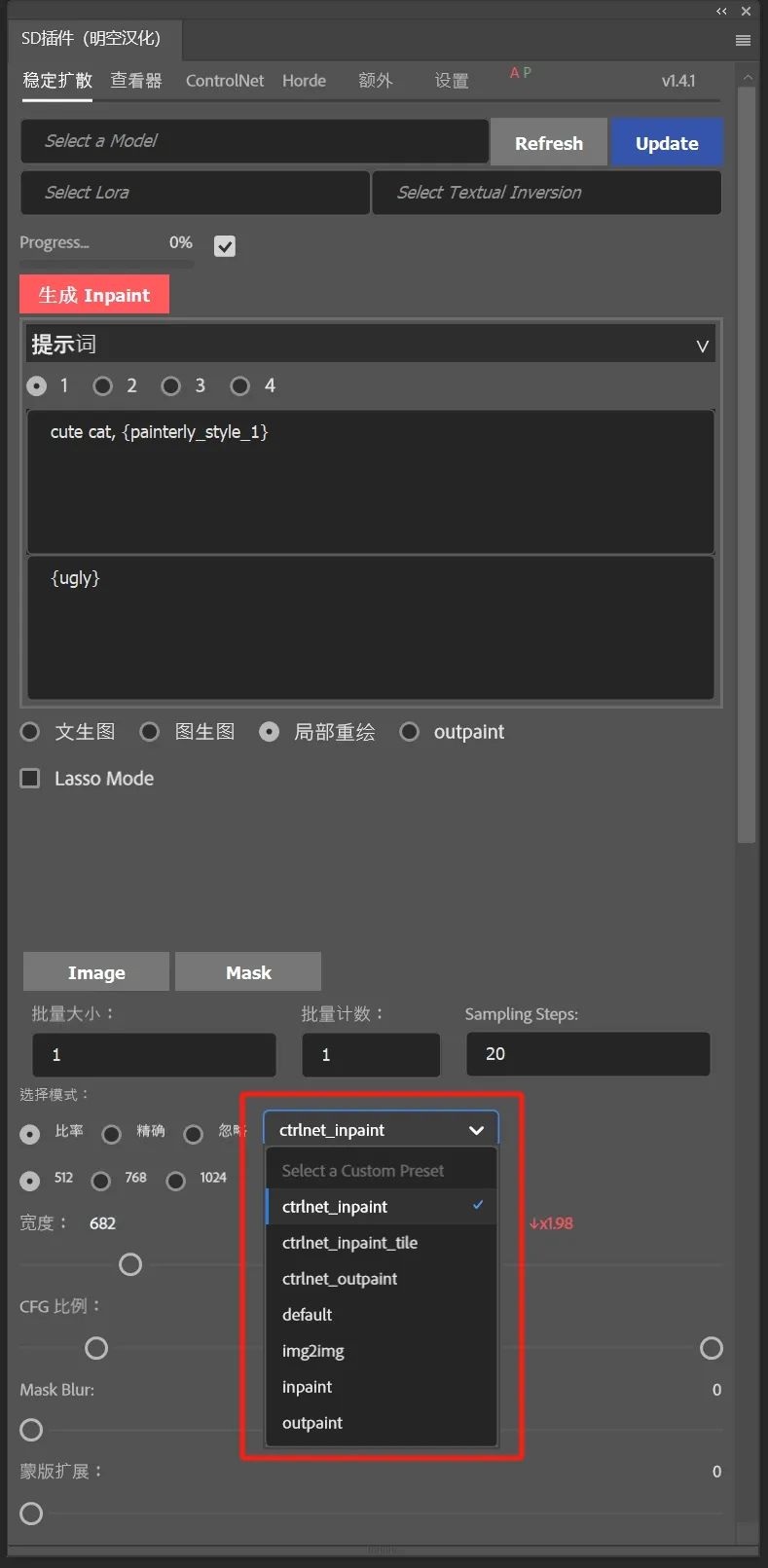
而在查看器的prompts library中可以快速调用保存的常用提示词,然后保存成类似embedding的关键词以便调用,让我们方便的一键输入提示词。
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!
















 1690
1690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









