








要做分布式运算必须要启动yarn
start-yarn.sh
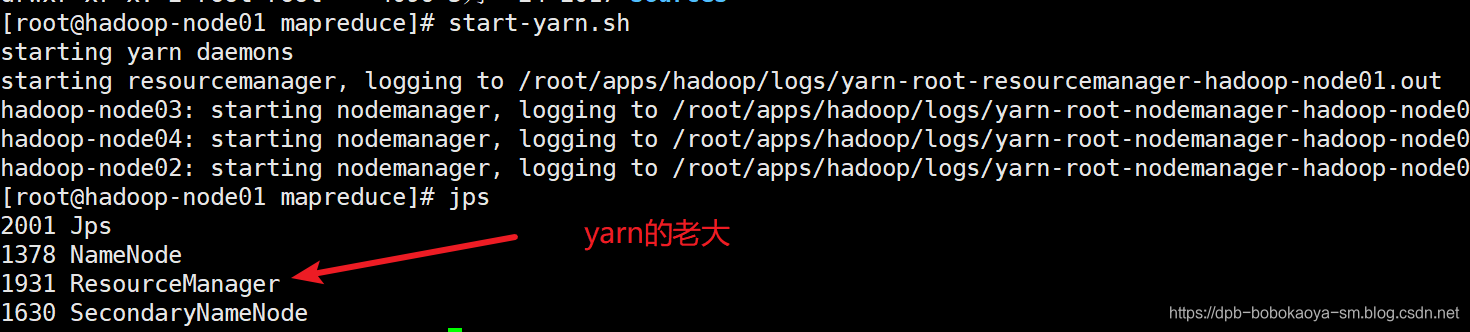
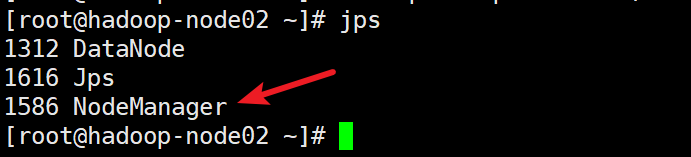
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /wordcount/input/ /wordcount/output
输出
[root@hadoop-node01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /wordcount/input/ /wordcount/output
19/04/02 23:06:03 INFO client.RMProxy: Connecting to ResourceManager at hadoop-node01/192.168.88.61:8032
19/04/02 23:06:07 INFO input.FileInputFormat: Total input paths to process : 1
19/04/02 23:06:09 INFO mapreduce.JobSubmitter: number of splits:1
19/04/02 23:06:09 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1554217397936_0001
19/04/02 23:06:10 INFO impl.YarnClientImpl: Submitted application application_1554217397936_0001
19/04/02 23:06:11 INFO mapreduce.Job: The url to track the job: http://hadoop-node01:8088/proxy/application_1554217397936_0001/
19/04/02 23:06:11 INFO mapreduce.Job: Running job: job_1554217397936_0001
19/04/02 23:06:30 INFO mapreduce.Job: Job job_1554217397936_0001 running in uber mode : false
19/04/02 23:06:30 INFO mapreduce.Job: map 0% reduce 0%
19/04/02 23:06:46 INFO mapreduce.Job: map 100% reduce 0%
19/04/02 23:06:57 INFO mapreduce.Job: map 100% reduce 100%
19/04/02 23:06:58 INFO mapreduce.Job: Job job_1554217397936_0001 completed successfully
19/04/02 23:06:59 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=133
FILE: Number of bytes written=214969
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=240
HDFS: Number of bytes written=79
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=11386
Total time spent by all reduces in occupied slots (ms)=9511
Total time spent by all map tasks (ms)=11386
Total time spent by all reduce tasks (ms)=9511
Total vcore-milliseconds taken by all map tasks=11386
Total vcore-milliseconds taken by all reduce tasks=9511
Total megabyte-milliseconds taken by all map tasks=11659264
Total megabyte-milliseconds taken by all reduce tasks=9739264
Map-Reduce Framework
Map input records=24
Map output records=27
Map output bytes=236
Map output materialized bytes=133
Input split bytes=112
Combine input records=27
Combine output records=12
Reduce input groups=12
Reduce shuffle bytes=133
Reduce input records=12
Reduce output records=12
Spilled Records=24
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=338
CPU time spent (ms)=2600
Physical memory (bytes) snapshot=283582464
Virtual memory (bytes) snapshot=4125011968
Total committed heap usage (bytes)=137363456
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=128
File Output Format Counters
Bytes Written=79
执行成功,查看结果

[root@hadoop-node01 mapreduce]# hadoop fs -cat /wordcount/output/part-r-00000
1 1
2 1
3 1
a 4
b 2
c 1
hadoop 3
hdfs 2
hello 2
java 7
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!**
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









