







第一步:创建MapReduce_Test项目 导入hdfs、mapreduce和yarn相关jar包
第二步:编写WordCountMapper类 代码如下:
package com.xjtuse;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
// 重写父类的map方法 循环调用 从split后的数据片段中 每读取一行 调用一次 以该行所在的下标为key 该行的内容为value
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String [] words = StringUtils.split(value.toString(), ' '); // 将文件的每一行中的单词 以空格进行分割 保存到数组中
// 循环遍历数组
for(String w : words)
{
context.write(new Text(w), new IntWritable(1)); // 以单词为key 1为value进行输出
}
}
}
第三步:编写WordCountReducer类 代码如下:
package com.xjtuse;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
// 循环调用reduce方法 进行洗牌后生成的每一组数据调用一次该方法 这一组数据key相同 value可能有很多
protected void reduce(Text arg0, Iterable<IntWritable> arg1, Context arg2)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
// 定义一个变量存放每一组中单词出现的总数
int sum = 0;
for(IntWritable i : arg1)
{
sum += i.get();
}
arg2.write(arg0, new IntWritable(sum)); // 以单词为key 出现的总次数为value输出
}
}
第四步:在hdfs下创建/wordcount/input目录 并将本地的wc.txt文件上传到该目录下

第五步:编写RunJob类 代码如下:
package com.xjtuse;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RunJob {
public static void main(String[] args) {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
try {
FileSystem fs =FileSystem.get(conf);
// 通过静态方法得到job对象
Job job = Job.getInstance(conf);
// 设置Job的执行类入口文件
job.setJarByClass(RunJob.class);
// 设置Job名称
job.setJobName("wordcount");
// 设置Mapper
job.setMapperClass(WordCountMapper.class);
// 设置Reducer
job.setReducerClass(WordCountReducer.class);
// 设置输出的key的类型
job.setMapOutputKeyClass(Text.class);
// 设置输出的value的类型
job.setMapOutputValueClass(IntWritable.class);
// 设置输入文件的目录
FileInputFormat.addInputPath(job, new Path("/wordcount/input/wc.txt"));
Path outputpath = new Path("/wordcount/output"); // 这个目录必须事先不存在
// 如果输出目录存在 则删掉它
if(fs.exists(outputpath))
{
fs.delete(outputpath, true); // true表示递归删除
}
// 设置输出文件的目录
FileOutputFormat.setOutputPath(job, outputpath);
// 执行
boolean b = job.waitForCompletion(true);
if(b)
{
System.out.println("Job任务执行成功!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
第六步:将程序打成jar包
在MapReduce_Test项目上右键->export->


第七步:将生成的jar包上传到master上(此处可以是任意一台虚拟机 因为每台虚拟机上的配置文件上都已经说明了Resource Manager是哪台机器 因此这个java程序在任意一台机器上都可以运行)

第八步:运行该程序
hadoop jar wc.jar com.xjtuse.RunJob(此处运行的主类需要带上其所在的包名)
报错如下:
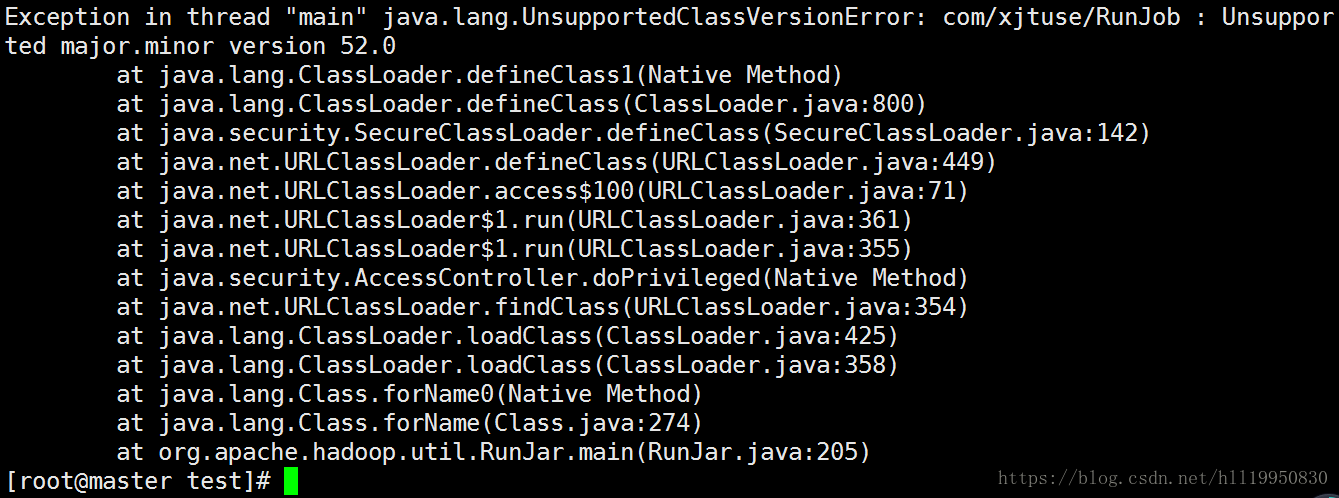
原因是我的windows本地jdk版本是1.8

而虚拟机上安装的jdk版本是1.7

在高版本的jdk下编译的jar包在低版本的jar包上运行 就会报这个错误 应该保证windows和虚拟机两个的jdk版本一致
可以在本地安装1.7版本的jdk 再重新打成jar包 上传到Linux上运行即可成功 可以通过浏览器查看task的执行进度














 1079
1079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









