






1.背景介绍
近年来,随着人工智能和机器学习技术的飞速发展,这些技术在心理健康领域的应用也逐渐受到广泛关注。心理健康是一个复杂的领域,涉及情绪、行为、认知等多方面因素,机器学习技术凭借其强大的数据分析和识别分类能力,为心理健康预测带来了新的机遇和突破。
2.数据介绍
数据集是自己收集制作的,该过程不在详细叙述。共制作了480个样本信息,包括15个特征,如性别、民族、出生地、适应性、人际关系、学习压力、恋爱压力、网络成瘾、进食问题、睡眠问题等。
3.机器学习模型和具体操作步骤
常用的机器学习算法包括:分类算法和回归算法。本实验利用随机森林、支持向量机、KNN分类模型进行预测心理健康状况。
本实验整体操作流程:1.制作数据集(已完成),是实验的前提条件。2.编程与算法部分。
①导入数据
②概述数据及统计
③构建模型:模型训练和预测
④评估算法
⑤特征重要性
3.1随机森林分类
首先,需要导入项目所需的类库和数据集,类库包括numpy、pandas、sklearn、matplotlib库,数据集为心理健康预测数据集,在这里将采用Pandas来导入数据。在接下来的部分将采用Pandas来对数据进行描述性统计分析。
概述数据
接下来对数据我们做一些理解,以便于选择合适的算法,我们会通过以下几个角度审查数据,并附上概述结果:
I.数据的维度
(480,16)
II.概述数据及统计
print(train.iloc[:,:].describe())#数值类型的包括均值,标准差,最大值,最小值,分位数等。
构建模型、训练和预测
定义随机森林模型、利用训练数据集进行模型训练,随后进行验证集测试。
# 使用随机森林对数据进行分类
rfc1 = RandomForestClassifier(n_estimators=100, # 树的数量
max_depth=8, # 子树最大深度)
rfc1.fit(X_train, y_train)
# 输出其在训练数据和验证数据集上的预测精度
rfc1_lab = rfc1.predict(X_train)
rfc1_pre = rfc1.predict(X_val)评估算法及ROC曲线图
print("随机森林的OOB score:", rfc1.oob_score_)
print("训练数据集上的精度:", accuracy_score(y_train, rfc1_lab))
print("验证数据集上的精度:", accuracy_score(y_val, rfc1_pre))
特征重要性
shap是可视化机器学习模型的一种方法,在使用shap之前,需要训练好特定的模型,然后导入shap库。接着,将模型输入shap解释器中,创建一个explainer对象,利用它计算每个观察对象的SHAP值,每个特征将对应一个SHAP值。
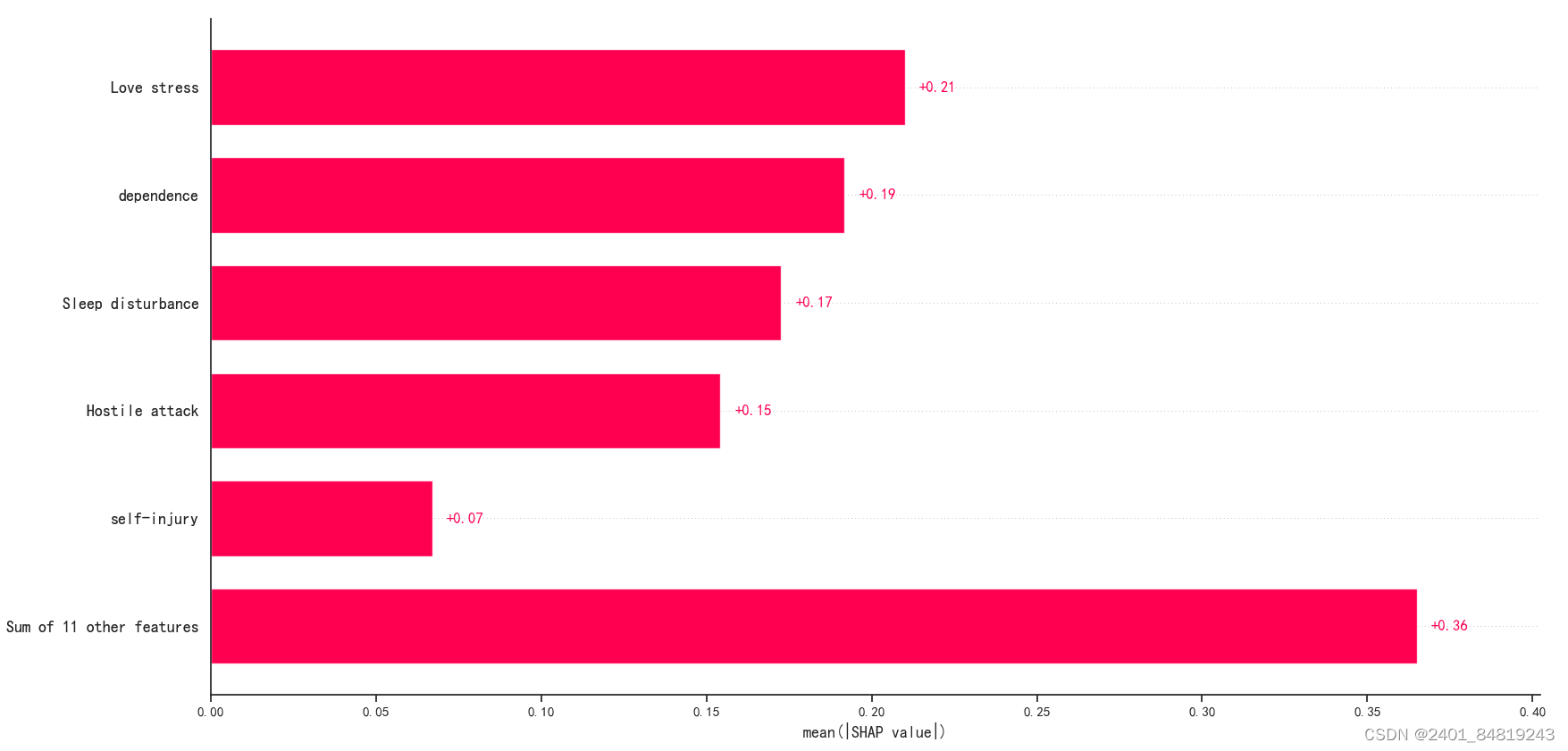
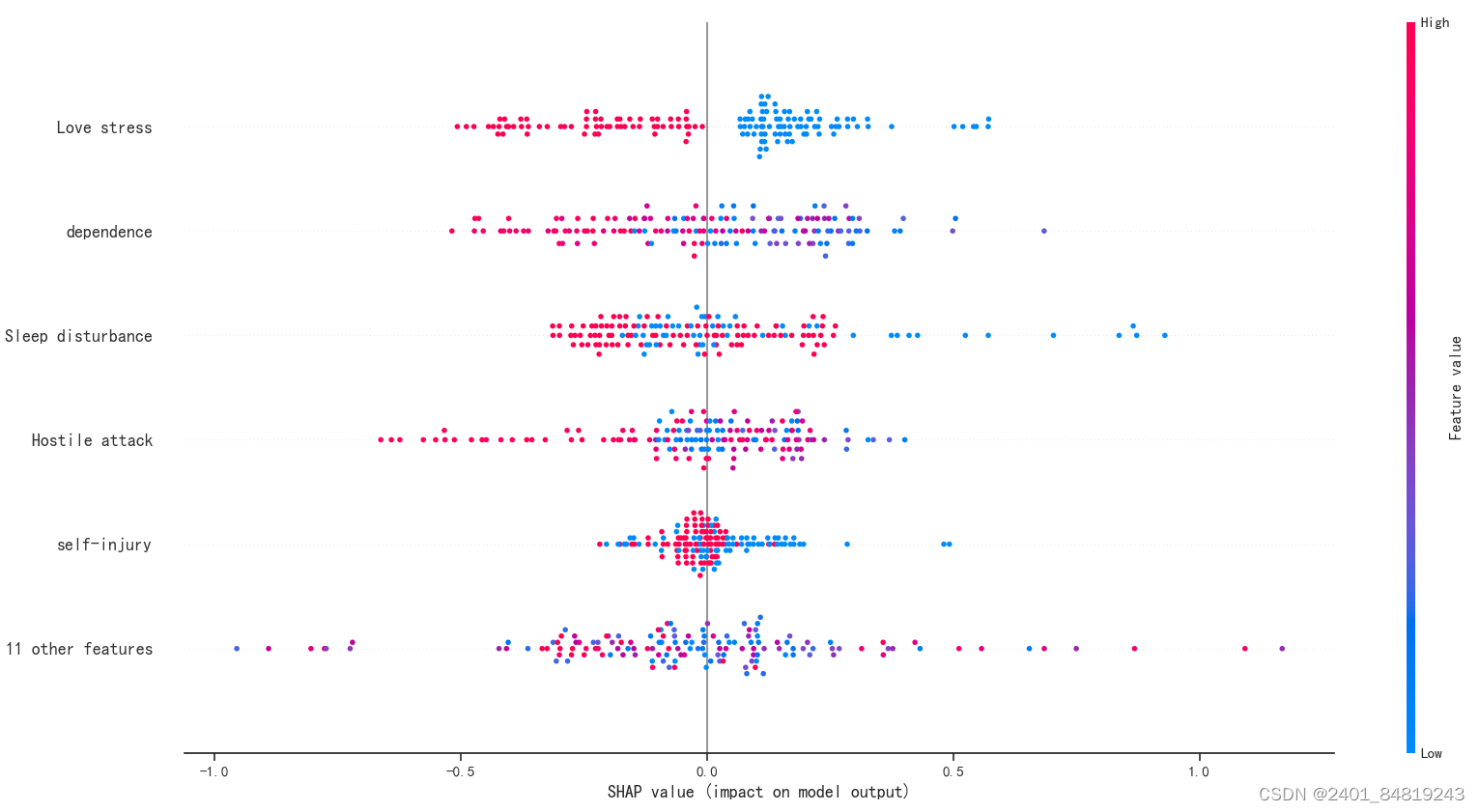
接下来,就是构建支持向量机分类模型和KNN分类模型,因其流程都一样,再次不再详细叙述。展示其分类结果。
3.2 SVM分类模型和KNN分类模型
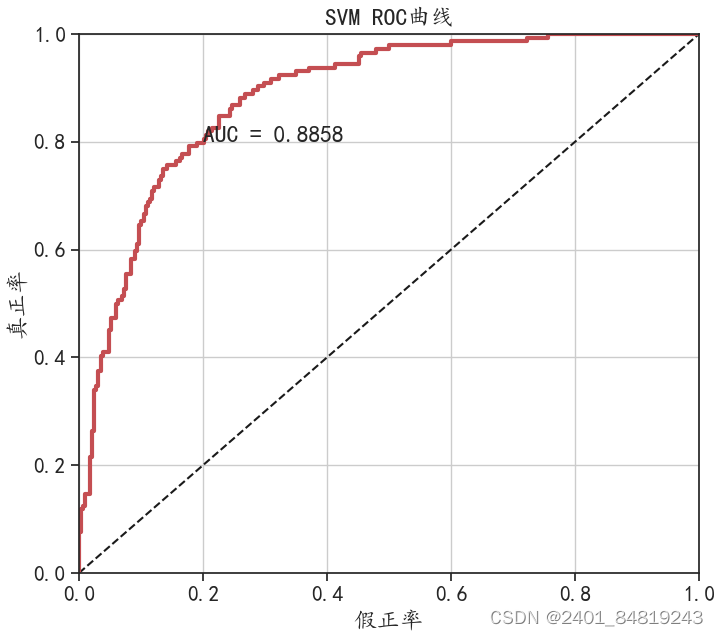
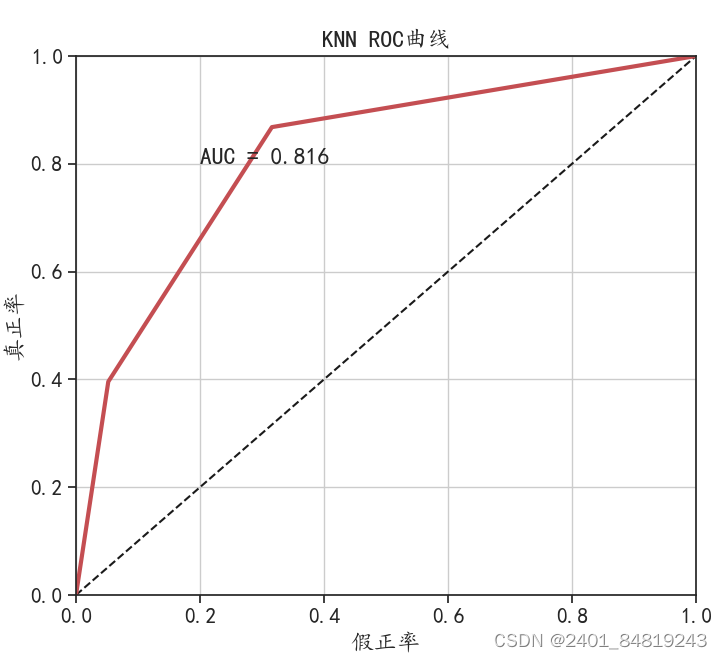
以上实验就介绍完了。获得实验数据和完整代码,请私我。

















 3570
3570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









