







深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
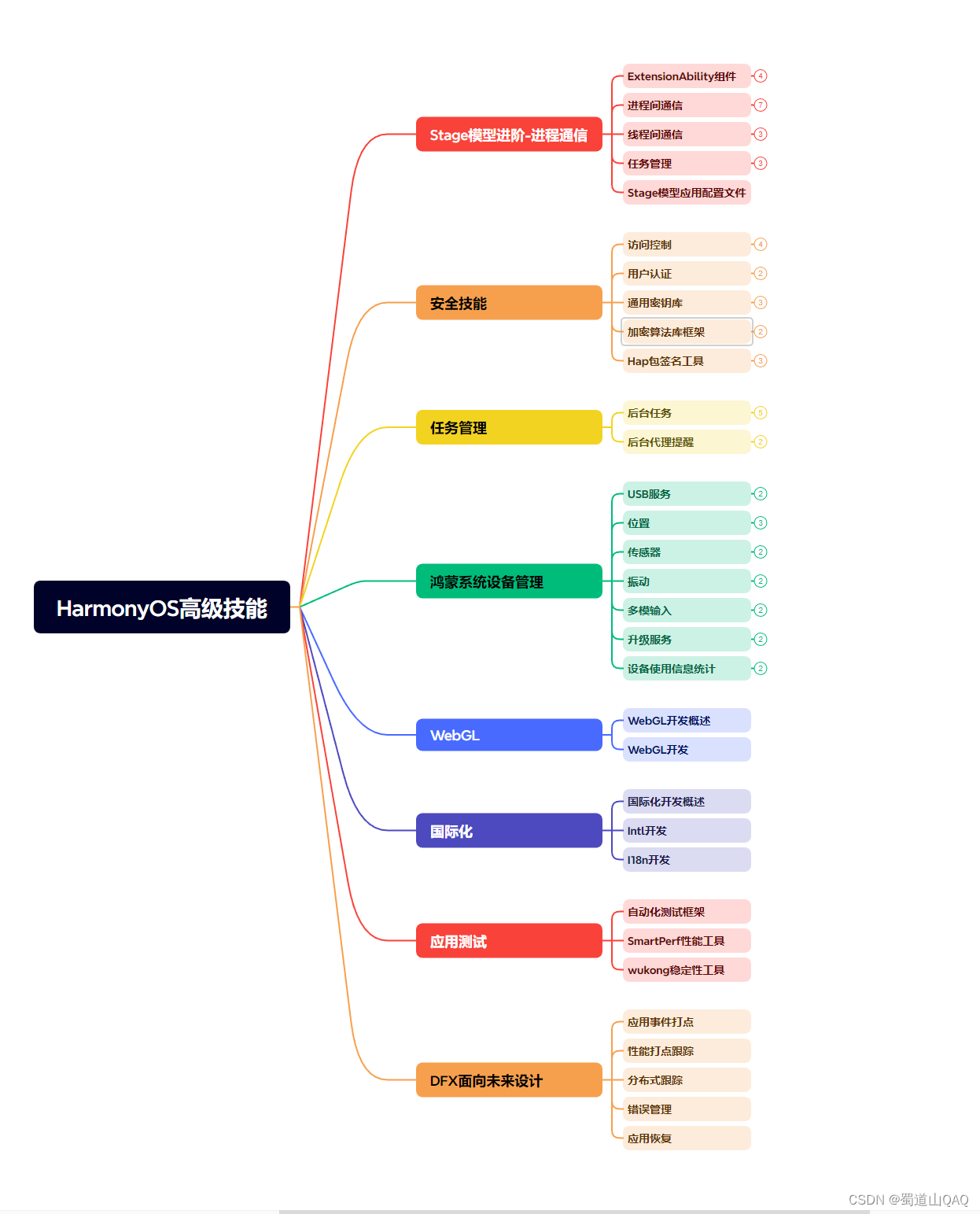

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
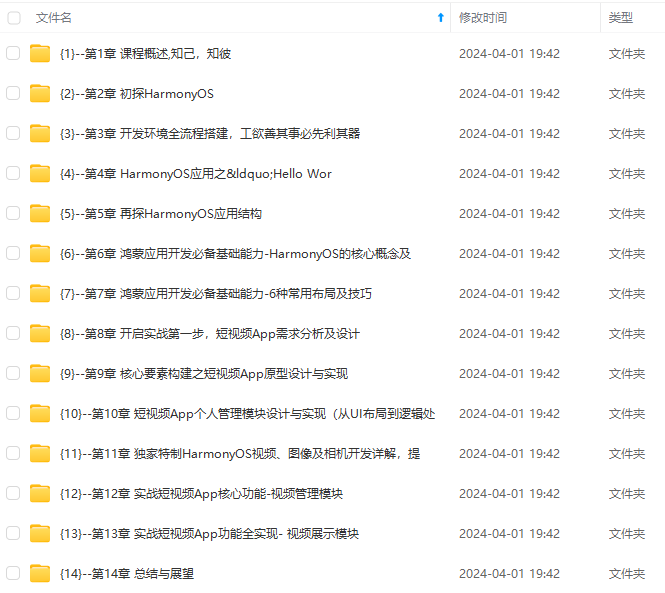
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
CSS
- 层叠样式表(Cascading Style Sheets)
| 👉CSS能够对网页中元素位置的排版进行像素级精确控制,实现美化页面的效果,能够做到页面的样式和结构分离. |
- css控制页面的展示效果
- html 决定页面结构
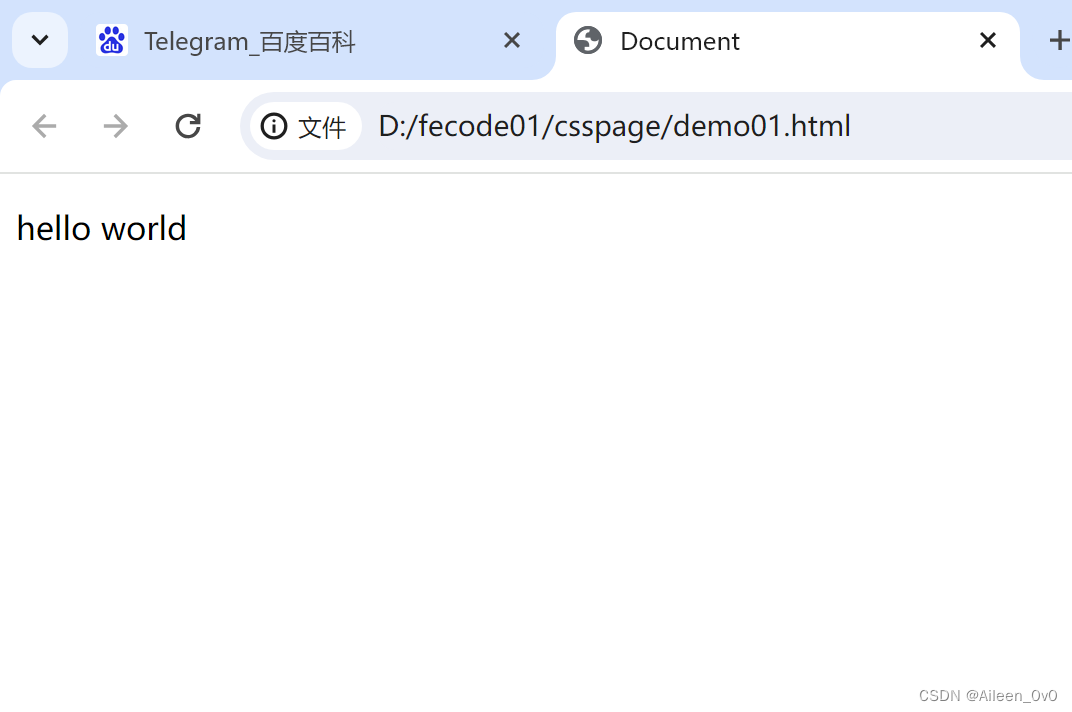
hello world
hello world
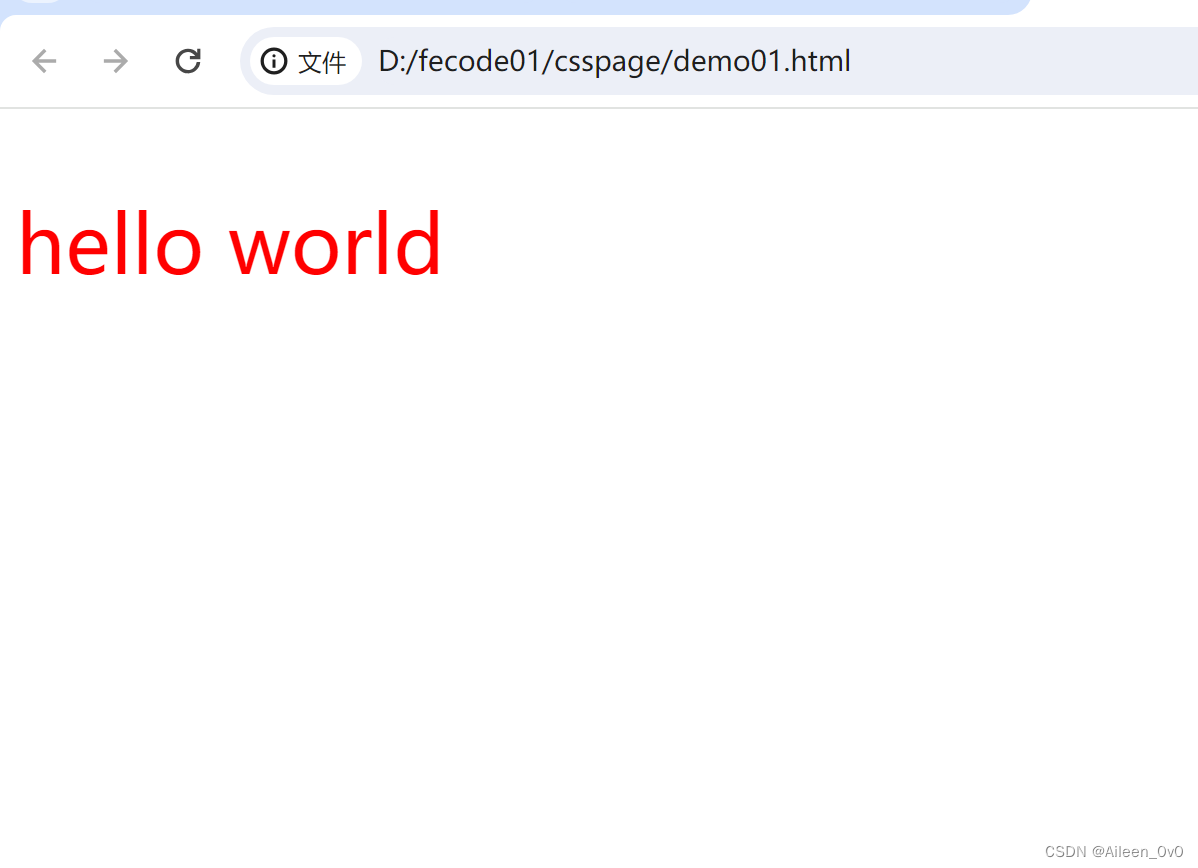
hello world
Aileen
你好

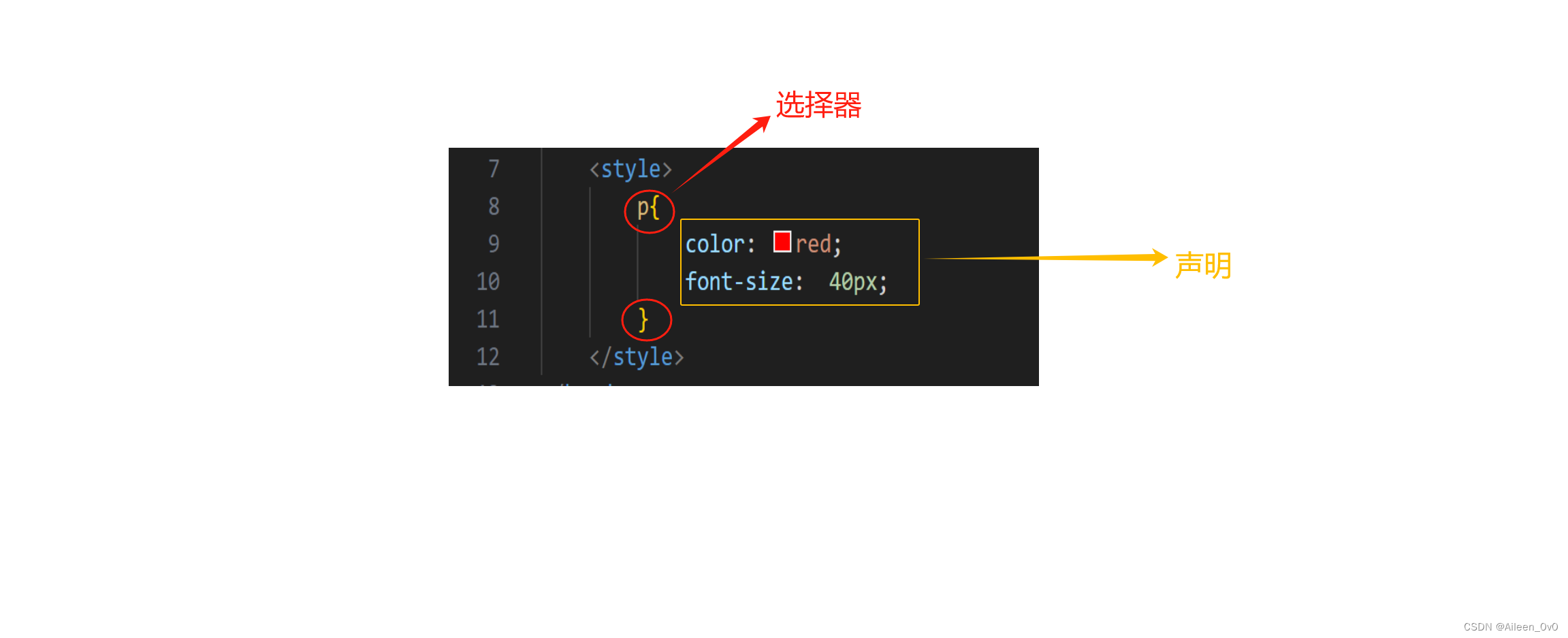
选择器+{一条/N条声明}
- 选择器(selector)决定针对谁修改使用:区分键值对,使用:区分键(property)和值(value)
- 声明决定修改啥
- 声明的属性是键值对,
selector{ property:value }
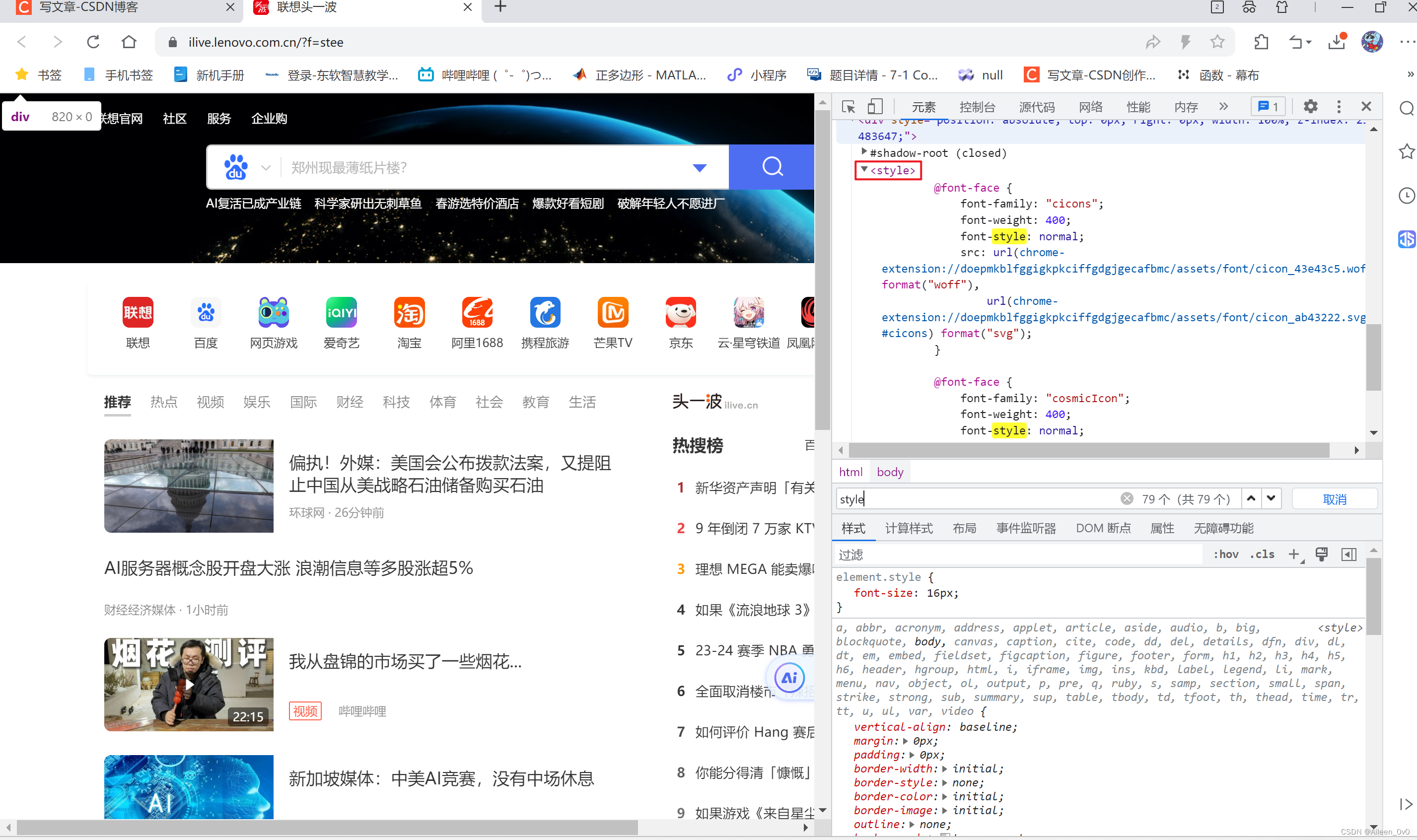
CSS引入方式
内部样式表
- 将css嵌套到html中 (通过style)标签嵌套
行内样式表
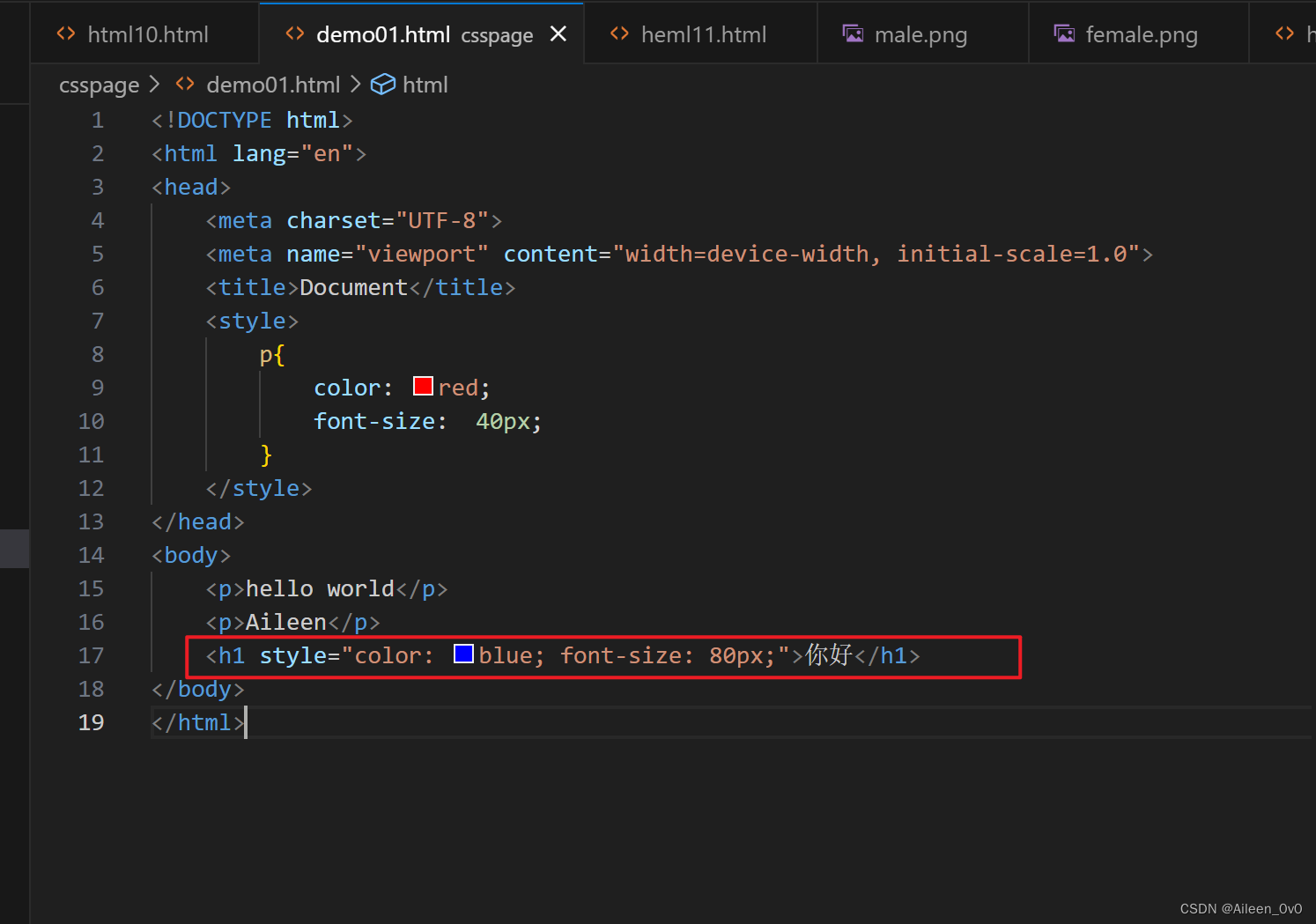
| ⚠ 行内样式表的优先级比内部样式表优先级高. |
外部样式表
- 1.创建一个css文件
- 2.使用 link 标签引入 css
<link rel="stylesheet" href="/path/example.css">
hello css
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
蒙开发知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1776
1776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









