









网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
yarn.nodemanager.aux-services mapreduce_shuffle(2)启动 ResourceManager 守护进程和 NodeManager 守护进程
$ sbin/start-yarn.sh
(3)浏览 ResourceManager 的网络接口,它们的地址默认为:
ResourceManager - http://localhost:8088/
(4)运行 MapReduce job
(5)完成全部操作后,停止守护进程:
$ sbin/stop-yarn.sh
6. 完全分布式模式的操作方法
关于搭建完全分布式模式的,请参阅下文《Apache Hadoop 集群上的安装配置》小节内容。
Apache Hadoop 集群上的安装配置
本节将描述如何安装、配置和管理 Hadoop 集群,其规模可从几个节点的小集群到几千个节点的超大集群。
1. 先决条件
确保在你集群中的每个节点上都安装了所有必需软件,安装 Hadoop 集群通常要将安装软件解压到集群内的所有机器上,参考上节内容《Apache Hadoop 单节点上的安装配置》。
通常情况下,集群中的一台机器被指定为 NameNode 和另一台机器作为 ResourceManager。这些都是 master。其他服务(例如,Web 应用程序代理服务器和 MapReduce Job History 服务器)是在专用的硬件还是共享基础设施上运行,这取决于负载。
在群集里剩余的机器充当 DataNode 和 NodeManager。这些都是 slave。
2. 在 Non-Secure Mode(非安全模式)下的配置
Hadoop 配置有两种类型的重要配置文件:
- 默认只读,包括
core-default.xml、hdfs-default.xml、yarn-default.xml和mapred-default.xml; - 针对站点配置,包括
etc/hadoop/core-site.xml、etc/hadoop/hdfs-site.xml、etc/hadoop/yarn-site.xml和etc/hadoop/mapred-site.xml。
另外,你能够配置 bin 目录下的 etc/hadoop/hadoop-env.sh 和 etc/hadoop/yarn-env.sh 脚本文件的值来控制 Hadoop 的脚本。
为了配置 Hadoop 集群,你需要配置 Hadoop 守护进程的执行环境和Hadoop 守护进程的配置参数。
HDFS 的守护进程有 NameNode、econdaryNameNode 和 DataNode。YARN 的守护进程有 ResourceManager、NodeManager 和 WebAppProxy。若 MapReduce 在使用,那么 MapReduce Job History Server 也是在运行的。在大型的集群中,这些一般都是在不同的主机上运行。
配置 Hadoop 守护进程的运行环境
管理员应该利用etc/hadoop/hadoop-env.sh、etc/hadoop/mapred-env.sh 和 etc/hadoop/yarn-env.sh 脚本来对 Hadoop 守护进程的环境做一些自定义的配置。
至少你应该在每个远程节点上正确配置 JAVA_HOME。
管理员能够使用下面的表格当中的配置选项来配置独立的守护进程:
| 守护进程 | 环境变量 |
|---|---|
| NameNode | HADOOP_NAMENODE_OPTS |
| DataNode | HADOOP_DATANODE_OPTS |
| SecondaryNamenode | HADOOP_SECONDARYNAMENODE_OPTS |
| ResourceManager | YARN_RESOURCEMANAGER_OPTS |
| NodeManager | YARN_NODEMANAGER_OPTS |
| WebAppProxy | YARN_PROXYSERVER_OPTS |
| Map Reduce Job History Server | HADOOP_JOB_HISTORYSERVER_OPTS |
例如,配置 Namenode 时,为了使其能够 parallelGC(并行回收垃圾), 要把下面的代码加入到etc/hadoop/hadoop-env.sh:
export HADOOP_NAMENODE_OPTS=“-XX:+UseParallelGC”
其它可定制的常用参数还包括:
- HADOOP_PID_DIR——守护进程的进程 id 存放目录;
- HADOOP_LOG_DIR——守护进程的日志文件存放目录。如果不存在会被自动创建;
- HADOOP_HEAPSIZE/YARN_HEAPSIZE——最大可用的堆大小,单位为MB。比如,1000MB。这个参数用于设置守护进程的堆大小。缺省大小是1000。可以为每个守护进程单独设置这个值。
在大多数情况下,你应该指定 HADOOP_PID_DIR 和 HADOOP_LOG_DIR 目录,这样它们只能由要运行 hadoop 守护进程的用户写入。否则会受到符号链接攻击的可能。
这也是在 shell 环境配置里配置 HADOOP_PREFIX 的传统方式。例如,在/etc/profile.d中一个简单的脚本的配置如下:
HADOOP_PREFIX=/path/to/hadoop
export HADOOP_PREFIX
| 守护进程 | 环境变量 |
|---|---|
| ResourceManager | YARN_RESOURCEMANAGER_HEAPSIZE |
| NodeManager | YARN_NODEMANAGER_HEAPSIZE |
| WebAppProxy | YARN_PROXYSERVER_HEAPSIZE |
| Map Reduce Job History Server | HADOOP_JOB_HISTORYSERVER_HEAPSIZE |
配置 Hadoop 守护进程
这部分涉及 Hadoop 集群的重要参数的配置
etc/hadoop/core-site.xml
| 参数 | 取值 | 备注 |
|---|---|---|
| fs.defaultFS | NameNode URI | hdfs://host:port/ |
| io.file.buffer.size | 131072 | SequenceFiles 中读写缓冲的大小 |
* etc/hadoop/hdfs-site.xml
用于配置 NameNode:
| 参数 | 取值 | 备注 |
|---|---|---|
| dfs.namenode.name.dir | NameNode 持久存储命名空间及事务日志的本地文件系统路径。 | 当这个值是一个逗号分割的目录列表时,name table 数据将会被复制到所有目录中做冗余备份。 |
| dfs.hosts / dfs.hosts.exclude | 允许/排除的 DataNodes 列表。 | 如果有必要,使用这些文件,以控制允许的 datanodes 的列表。 |
| dfs.blocksize | 268435456 | 在大型文件系统里面设置 HDFS 块大小为 256MB |
| dfs.namenode.handler.count | 100 | 在大数量的 DataNodes 里面用更多的 NameNode 服务器线程来控制 RPC |
用于配置 DataNode:
| 参数 | 取值 | 备注 |
|---|---|---|
| dfs.datanode.data.dir | DataNode存放块数据的本地文件系统路径,逗号分割的列表。 | 当这个值是逗号分割的目录列表时,数据将被存储在所有目录下,通常分布在不同设备上。 |
* etc/hadoop/yarn-site.xml
用于配置 ResourceManager 和 NodeManager:
| 参数 | 取值 | 备注 |
|---|---|---|
| yarn.acl.enable | true / false | 是否启用 ACLs。默认是 false |
| yarn.admin.acl | Admin ACL | ACL 集群上设置管理员。 ACLs 是用逗号分隔的。默认为 * 意味着任何人。特殊值空格,意味着没有人可以进入。 |
| yarn.log-aggregation-enable | false | 配置算法启用日志聚合 |
用于配置 ResourceManager :
| 参数 | 取值 | 备注 |
|---|---|---|
| yarn.resourcemanager.address | ResourceManager host:port ,用于给客户端提交 jobs | 若 host:port 设置,则覆盖 yarn.resourcemanager.hostname 中的 hostname |
| yarn.resourcemanager.scheduler.address | ResourceManager host:port,用于 ApplicationMasters (主节点)和 Scheduler(调度器)通信来取得资源 | 若 host:port 设置,则覆盖 yarn.resourcemanager.hostname 中的 hostname |
| yarn.resourcemanager.resource-tracker.address | ResourceManager host:port ,用于 NodeManagers | 若 host:port 设置,则覆盖 yarn.resourcemanager.hostname 中的 hostname |
| yarn.resourcemanager.admin.address | ResourceManager host:port ,用于管理命令 | 若 host:port 设置,则覆盖 yarn.resourcemanager.hostname 中的 hostname |
| yarn.resourcemanager.webapp.address | ResourceManager web-ui host:port,用于 web 管理 | 若 host:port 设置,则覆盖 yarn.resourcemanager.hostname 中的 hostname |
| yarn.resourcemanager.scheduler.class | ResourceManager Scheduler 类 | CapacityScheduler (推荐)、FairScheduler(也推荐)或 FifoScheduler |
| yarn.scheduler.minimum-allocation-mb | 分配给每个容器请求Resource Manager 的最小内存 | 单位为 MB |
| yarn.scheduler.maximum-allocation-mb | 分配给每个容器请求Resource Manager 的最大内存 | 单位为 MB |
| yarn.resourcemanager.nodes.include-path / yarn.resourcemanager.nodes.exclude-path | 允许/拒绝的NodeManager 的列表 | 如果有必要,用这些文件来控制列出的允许的 NodeManager |
用于配置 NodeManager :
| 参数 | 取值 | 备注 |
|---|---|---|
| yarn.nodemanager.resource.memory-mb | NodeManager 可用的物理内存 | 定义在 NodeManager 上的全部资源,用来运行容器。 |
| yarn.nodemanager.vmem-pmem-ratio | task 使用虚拟内存的最大比例,可能超过物理内存 | 每个 task 使用的虚拟内存可能超过它的物理内存, 虚拟内存靠这个比率来进行限制。这个比率限制的在 NodeManager 上task 使用的虚拟内存总数,可能会超过它的物理内存。 |
| yarn.nodemanager.local-dirs | 在本地文件系统里,写入中间数据的地方的路径。多个路径就用逗号进行隔开。 | 多个路径有助于分散磁盘I/O |
| yarn.nodemanager.log-dirs | 在本地文件系统里,写入日志的地方的路径。多个路径就用逗号进行隔开。 | 多个路径有助于分散磁盘I/O |
| yarn.nodemanager.log.retain-seconds | 10800 | 日志文件在NodeManager 上保存的默认时间(单位为秒),仅仅适合在日志聚合关闭的时候使用。 |
| yarn.nodemanager.remote-app-log-dir | /logs | 在应用程序完成的时候,应用程序的日志将移到这个HDFS目录。需要设置适当的权限。 仅仅适合在日志聚合开启的时候使用。 |
| yarn.nodemanager.remote-app-log-dir-suffix | logs | 追加到远程日志目录 |
| yarn.nodemanager.aux-services 、 mapreduce.shuffle | 给 Map Reduce 应用程序设置 Shuffle 服务。 |
用于配置 History Server (需搬移到其它地方):
| 参数 | 取值 | 备注 |
|---|---|---|
| yarn.log-aggregation.retain-seconds | -1 | 保留聚合日志的时间, -1 表示不启用。需要注意的是,该值不能设置的太小 |
| yarn.log-aggregation.retain-check-interval-seconds | -1 | 检查聚合日志保留的时间间隔,-1 表示不启用。需要注意的是,该值不能设置的太小 |
* etc/hadoop/mapred-site.xml
用于配置 MapReduce 应用:
| 参数 | 取值 | 备注 |
|---|---|---|
| mapreduce.framework.name | yarn | 运行框架设置为 Hadoop YARN. |
| mapreduce.map.memory.mb | 1536 | maps 的最大资源. |
| mapreduce.map.java.opts | -Xmx1024M | maps 子虚拟机的堆大小 |
| mapreduce.reduce.memory.mb | 3072 | reduces 的最大资源. |
| mapreduce.reduce.java.opts | -Xmx2560M | reduces 子虚拟机的堆大小 |
| mapreduce.task.io.sort.mb | 512 | 任务内部排序缓冲区大小 |
| mapreduce.task.io.sort.factor | 100 | 在整理文件时一次性合并的流数量 |
| mapreduce.reduce.shuffle.parallelcopies | 50 | reduces 运行的最大并行复制的数量,用于获取大量的 maps 的输出 |
用于配置 MapReduce JobHistory Server:
| 参数 | 取值 | 备注 |
|---|---|---|
| mapreduce.jobhistory.address | MapReduce JobHistory Server host:port | 默认端口是 10020. |
| mapreduce.jobhistory.webapp.address | MapReduce JobHistory Server Web 界面 host:port | 默认端口是 19888. |
| mapreduce.jobhistory.intermediate-done-dir | /mr-history/tmp | MapReduce jobs 写入历史文件的目录 |
| mapreduce.jobhistory.done-dir | /mr-history/done | MR JobHistory Server 管理的历史文件目录 |
3. 监控 NodeManager 的健康状况
Hadoop 提供了一种机制,管理员可以配置 NodeManager 来运行提供脚本定期确认一个节点是否健康。
管理员可以通过在脚本中执行检查来判断该节点是否处于健康状态。如果脚本检查到节点不健康,可以打印一个标准的 ERROR(错误)输出。NodeManager 通过一些脚本定期检查他的输出,如果脚本输出有 ERROR信息,如上所述,该节点将报告为不健康,就将节点加入到 ResourceManager 的黑名单列表中,则任务不会分配到该节点中。然后 NodeManager 继续跑这个脚本,所以如果 Node 节点变为健康了,将自动的从 ResourceManager 的黑名单列表删除,节点的健康状况随着脚本的输出,如果变为不健康,在 ResourceManager web 接口上对管理员来说是可用的。这个时候节点的健康状况不会显示在web接口上。
在etc/hadoop/yarn-site.xml下,可以控制节点的健康检查脚本:
| 参数 | 取值 | 备注 |
|---|---|---|
| yarn.nodemanager.health-checker.script.path | Node health script | 这个脚本检查节点的健康状态。 |
| yarn.nodemanager.health-checker.script.opts | Node health script options | 检查节点的健康状态脚本选项 |
| yarn.nodemanager.health-checker.script.interval-ms | Node health script interval | 运行健康脚本的时间间隔 |
| yarn.nodemanager.health-checker.script.timeout-ms | Node health script timeout interval | 健康脚本的执行超时时间 |
如果只是本地硬盘坏了,健康检查脚本将不会设置该节点为 ERROR。但是NodeManager 有能力来定期检查本地磁盘的健康(检查 nodemanager-local-dirs 和 nodemanager-log-dirs 两个目录),当达到yarn.nodemanager.disk-health-checker.min-healthy-disks 设置的阀值,则整个节点将标记为不健康。
4. Slaves File
所有 slave 的 hostname 或者 IP 都保存在etc/hadoop/slaves文件中,每行一个。脚本可以通过etc/hadoop/slaves文件去运行多台机器的命令。他不使用任何基于 Java 的 Hadoop 配置。为了使用这个功能,ssh 必须建立好使用账户才能运行 Hadoop。所以在安装 Hadoop 的时候,需要配置 ssh 登陆。
5. Hadoop Rack Awareness(机架感知)
很多 Hadoop 组件得益于机架感知,给性能和安全性带来了很大的提升,Hadoop 的守护进程调用管理配置的模块,获取到集群 slave 的机架信息,更多的机架感知信息,查看这里 http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/RackAwareness.html。
使用 HDFS 时,强烈推荐使用机架感知。
6. 日志
Hadoop 使用 Apache log4j 作为日志框架,编辑etc/hadoop/log4j.properties文件来自定义日志的配置。
7. 操纵 Hadoop 集群
所有必备的配置都完成了,分发 HADOOP_CONF_DIR 配置文件到所有机器,所有机器安装 Hadoop 目录的路径应该是一样的。
在一般情况下,建议 HDFS 和 YARN 作为单独的用户运行。在大多数安装中,HDFS 执行 “hdfs”。YARN 通常使用“yarn”帐户。
Hadoop 启动
为了启动 Hadoop 集群,你需要启动 HDFS 和 YARN 集群。
第一次使用 HDFS 需要格式化。 作为 hdfs 格式化新分发的文件系统:
[hdfs]$ $HADOOP_PREFIX/bin/hdfs namenode -format <cluster_name>
作为 hdfs,通过如下命令启动 HDFS NameNode 到指定的节点 :
[hdfs]$ $HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode
作为 hdfs,通过如下命令启动 HDFS DataNode 到每个指定的节点 :
[hdfs]$ $HADOOP_PREFIX/sbin/hadoop-daemons.sh --config $HADOOP_CONF_DIR --script hdfs start datanode
作为 hdfs,如果 etc/hadoop/slaves 和 ssh 可信任访问已经配置,那么所有的 HDFS 进程都可以通过脚本工具来启动:
[hdfs]$ $HADOOP_PREFIX/sbin/start-dfs.sh
作为 yarn,通过下面的命令启动 YARN,运行指定的 ResourceManager :
[yarn]$ $HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start resourcemanager
作为 yarn,运行脚本来启动从机上的所有 NodeManager:
[yarn]$ $HADOOP_YARN_HOME/sbin/yarn-daemons.sh --config $HADOOP_CONF_DIR start nodemanager
作为 yarn,启动本地化的 WebAppProxy 服务器。如果想使用大量的服务器来实现负载均衡,那么它就应该运行在它们各自机器之上:
[yarn]$ $HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR start proxyserver
作为 yarn,如果 etc/hadoop/slaves 和 ssh 可信任访问已经配置,那么所有的 YARN 进程都可以通过脚本工具来启动:
[yarn]$ $HADOOP_PREFIX/sbin/start-yarn.sh
作为 mapred,根据下面的命令启动 MapReduce JobHistory Server :
[mapred]$ $HADOOP_PREFIX/sbin/mr-jobhistory-daemon.sh --config $HADOOP_CONF_DIR start historyserver
Hadoop 关闭
作为 hdfs,通过以下命令停止 NameNode:
[hdfs]$ $HADOOP_PREFIX/sbin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs stop namenode
作为 hdfs,运行脚本停止在所有从机上的所有 DataNode:
[hdfs]$ $HADOOP_PREFIX/sbin/hadoop-daemons.sh --config $HADOOP_CONF_DIR --script hdfs stop datanode
作为 hdfs,如果 etc/hadoop/slaves 和 ssh 可信任访问已经配置,那么所有的 HDFS 进程都可以通过脚本工具来关闭:
[hdfs]$ $HADOOP_PREFIX/sbin/stop-dfs.sh
作为 yarn,通过以下命令停止 ResourceManager:
[yarn]$ $HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop resourcemanager
作为 yarn,运行一下脚本停止 slave 机器上的 NodeManager :
[yarn]$ $HADOOP_YARN_HOME/sbin/yarn-daemons.sh --config $HADOOP_CONF_DIR stop nodemanager
作为 yarn,如果 etc/hadoop/slaves 和 ssh 可信任访问已经配置,那么所有的 YARN 进程都可以通过脚本工具来关闭
[yarn]$ $HADOOP_PREFIX/sbin/stop-yarn.sh
作为 yarn,停止 WebAppProxy 服务器。由于负载均衡有可能设置了多个:
[yarn]$ $HADOOP_YARN_HOME/sbin/yarn-daemon.sh --config $HADOOP_CONF_DIR stop proxyserver
作为 mapred,通过以下命令停止 MapReduce JobHistory Server :
[mapred]$ $HADOOP_PREFIX/sbin/mr-jobhistory-daemon.sh --config $HADOOP_CONF_DIR stop historyserver
8. Web 界面
当 Hadoop 启动后,可以查看如下 Web 界面:
| 守护进行 | Web 界面 | 备注 |
|---|---|---|
| NameNode | http://nn_host:port/ | 默认 HTTP 端口为 50070. |
| ResourceManager | http://rm_host:port/ | 默认 HTTP端口为 8088 |
| MapReduce JobHistory Server | http://jhs_host:port/ | 默认 HTTP 端口为 19888 |
例子:词频统计 WordCount 程序
下面是 Hadoop 提供的词频统计 WordCount 程序 示例。运行运行改程序之前,请确保 HDFS 已经启动。
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.StringUtils;
public class WordCount2 {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
static enum CountersEnum { INPUT_WORDS }
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private boolean caseSensitive;
private Set patternsToSkip = new HashSet();
private Configuration conf;
private BufferedReader fis;
@Override
public void setup(Context context) throws IOException,
InterruptedException {
conf = context.getConfiguration();
caseSensitive = conf.getBoolean(“wordcount.case.sensitive”, true);
if (conf.getBoolean(“wordcount.skip.patterns”, true)) {
URI[] patternsURIs = Job.getInstance(conf).getCacheFiles();
for (URI patternsURI : patternsURIs) {
Path patternsPath = new Path(patternsURI.getPath());
String patternsFileName = patternsPath.getName().toString();
parseSkipFile(patternsFileName);
}
}
}
private void parseSkipFile(String fileName) {
try {
fis = new BufferedReader(new FileReader(fileName));
String pattern = null;
while ((pattern = fis.readLine()) != null) {
patternsToSkip.add(pattern);
}
} catch (IOException ioe) {
System.err.println(“Caught exception while parsing the cached file '”
- StringUtils.stringifyException(ioe));
}
}
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String line = (caseSensitive) ?
value.toString() : value.toString().toLowerCase();
for (String pattern : patternsToSkip) {
line = line.replaceAll(pattern, “”);
}
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
Counter counter = context.getCounter(CountersEnum.class.getName(),
CountersEnum.INPUT_WORDS.toString());
counter.increment(1);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
GenericOptionsParser optionParser = new GenericOptionsParser(conf, args);
String[] remainingArgs = optionParser.getRemainingArgs();
if (!(remainingArgs.length != 2 | | remainingArgs.length != 4)) {
System.err.println(“Usage: wordcount [-skip skipPatternFile]”);
System.exit(2);
}
Job job = Job.getInstance(conf, “word count”);
job.setJarByClass(WordCount2.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
List otherArgs = new ArrayList();
for (int i=0; i < remainingArgs.length; ++i) {
if (“-skip”.equals(remainingArgs[i])) {
job.addCacheFile(new Path(remainingArgs[++i]).toUri());
job.getConfiguration().setBoolean(“wordcount.skip.patterns”, true);
} else {
otherArgs.add(remainingArgs[i]);
}
}
FileInputFormat.addInputPath(job, new Path(otherArgs.get(0)));
FileOutputFormat.setOutputPath(job, new Path(otherArgs.get(1)));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
待输入的样本文件如下:
$ bin/hadoop fs -ls /user/joe/wordcount/input/
/user/joe/wordcount/input/file01
/user/joe/wordcount/input/file02
$ bin/hadoop fs -cat /user/joe/wordcount/input/file01
Hello World, Bye World!
$ bin/hadoop fs -cat /user/joe/wordcount/input/file02
Hello Hadoop, Goodbye to hadoop.
运行程序:
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
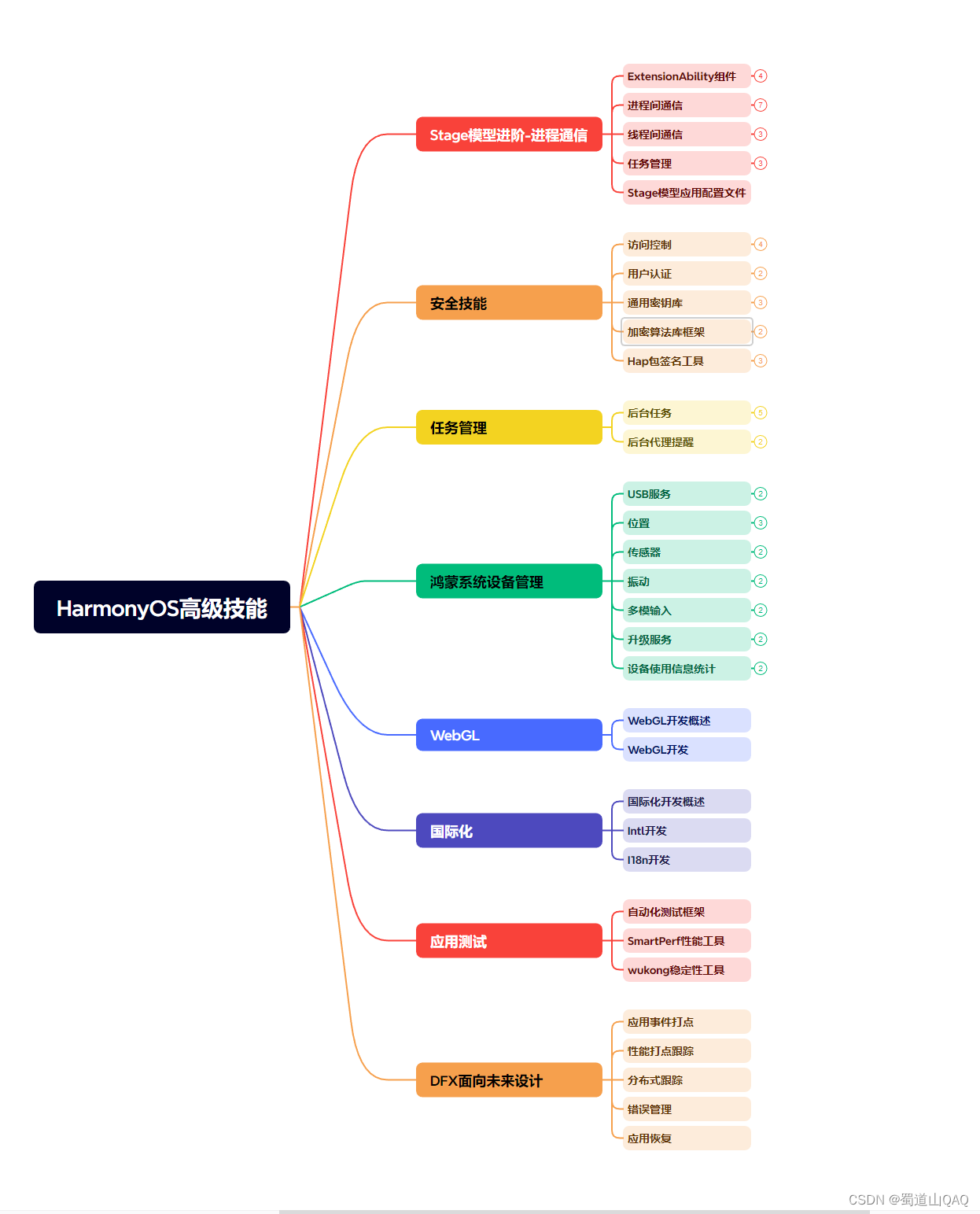


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
t/file01
/user/joe/wordcount/input/file02
$ bin/hadoop fs -cat /user/joe/wordcount/input/file01
Hello World, Bye World!
$ bin/hadoop fs -cat /user/joe/wordcount/input/file02
Hello Hadoop, Goodbye to hadoop.
运行程序:
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
[外链图片转存中…(img-pDs0Zk9a-1715738458714)]
[外链图片转存中…(img-DNpCpdoJ-1715738458714)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









